Interpréter et améliorer la précision du modèle et les scores de confiance d’analyse
Un score de confiance indique la probabilité, en mesurant le degré de certitude statistique, que le résultat extrait soit détecté correctement. La précision estimée est calculée en exécutant quelques combinaisons différentes des données d’apprentissage pour prédire les valeurs étiquetées. Dans cet article, découvrez comment interpréter les scores de précision et de confiance, et les meilleures pratiques pour utiliser de ces scores afin d’améliorer les résultats de précision et de confiance.
Scores de confiance
Remarque
- La confiance au niveau du champ inclut les scores de confiance des mots avec la version de l’API 2024-11-30 (GA) pour modèles personnalisés.
- Les scores de confiance pour les tables, les lignes de table et les cellules de table sont disponibles à partir de la version d’API 2024-11-30 (GA) pour les modèles personnalisés.
Les résultats de l’analyse Document Intelligence renvoient une confiance estimée pour les mots, les paires clé-valeur, les marques de sélection, les régions et les signatures de la prédiction. Actuellement, tous les champs de document ne retournent pas un score de confiance.
La confiance sur le champ indique que la prédiction est correcte avec une probabilité estimée entre 0 et 1. Par exemple, une valeur de confiance de 0,95 (95 %) indique que la prédiction est probablement correcte 19 fois sur 20. Pour les scénarios où l’exactitude est essentielle, la confiance peut être utilisée pour déterminer s’il faut accepter automatiquement la prédiction ou demander une vérification humaine.
Document Intelligence Studio
Modèle de facture prédéfini analysé
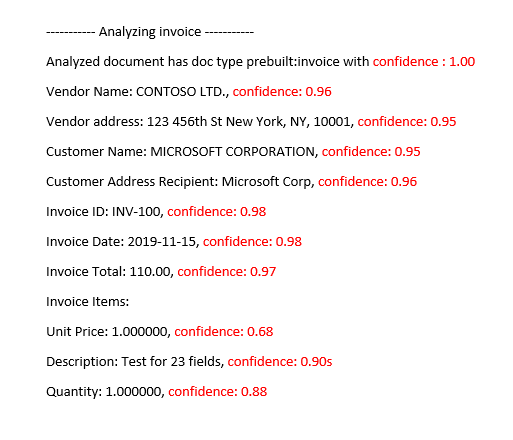
Améliorer les scores de confiance
Après une opération d’analyse, examinez la sortie JSON. Examinez les valeurs confidence pour chaque résultat de clé/valeur sous le nœud pageResults. Vous devez également regarder les scores de confiance dans le nœud readResults, qui correspond à l’opération de lecture de texte. La confiance des résultats de la lecture n’affecte pas la confiance des résultats de l’extraction des clés/valeurs : vous devez donc vérifier les deux. Voici quelques conseils :
Si le score de confiance associé à l’objet
readResultsest faible, améliorez la qualité de vos documents d’entrée.Si le score de confiance associé à l’objet
pageResultsest faible, assurez-vous que les documents que vous analysez sont du même type.Envisagez d’incorporer une révision humaine dans vos workflows.
Utilisez des formulaires ayant des valeurs différentes dans chaque champ.
Pour les modèles personnalisés, utilisez un plus grand ensemble de documents d’apprentissage. Un jeu d’apprentissage plus volumineux apprend à votre modèle à reconnaître les champs avec une plus grande précision.
Scores de précision des modèles personnalisés
Remarque
- Les modèles neuronaux et les modèles génératifs ne fournissent pas de scores de précision pendant l’apprentissage.
La sortie d’une opération de modèle personnalisé build (v3.0 ou ultérieure) ou train (v2.1) comprend le score de précision estimé. Ce score représente la capacité du modèle à prédire avec précision la valeur étiquetée sur un document visuellement similaire. La précision est mesurée dans une plage de valeurs de pourcentage allant de 0 % (faible) à 100 % (élevée). Il est préférable de viser un score d’au moins 80 %. Pour les cas plus sensibles, comme les dossiers financiers et médicaux, un score proche de 100 % est recommandé. Vous pouvez également ajouter une phase de révision humaine pour valider d’autres workflows d’automatisation critiques.
Document Intelligence Studio
Modèle personnalisé entraîné (facture)
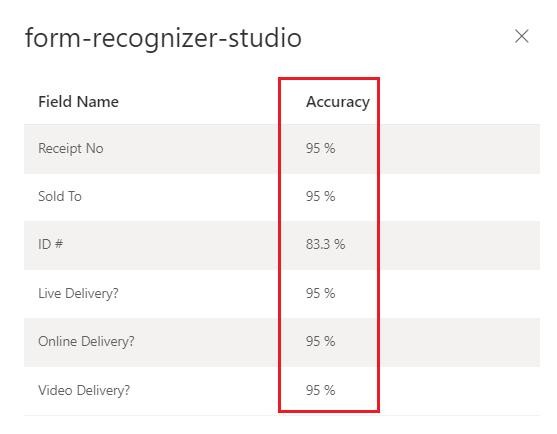
Interprétez les scores de justesse et de confiance pour les modèles personnalisés
Les modèles personnalisés génèrent un score de précision estimé lors de leur formation. Les documents analysés à l’aide d’un modèle personnalisé produisent un score de confiance pour les champs extraits. Lorsque vous interprétez le score de confiance d'un modèle personnalisé, vous devez prendre en compte tous les scores de confiance renvoyés par le modèle. Commençons par une liste de tous les scores de confiance.
- Score de confiance du type de document : la confiance du type de document est un indicateur de la ressemblance du document analysé avec les documents dans le jeu de données de formation. Lorsque la confiance dans le type de document est faible, cela indique des variations de modèle ou de structure dans le document analysé. Pour améliorer la confiance dans le type de document, étiquetez un document avec cette variation spécifique et ajoutez-le à votre ensemble de données de formation. Une fois le modèle ré-entraîné, il devrait être mieux équipé pour traiter cette catégorie de variations.
- Confiance au niveau du champ : chaque champ étiqueté extrait a un score de confiance associé. Ce score reflète la confiance du modèle dans la position de la valeur extraite. Lors de l’évaluation des scores de confiance, il convient également d’examiner la confiance de l’extraction sous-jacente afin de générer une confiance globale pour le résultat extrait. Évaluer les résultats
OCRpour l’extraction de texte ou les marques de sélection en fonction du type de champ afin de générer un score de confiance composite pour le champ. - Score de confiance du mot Chaque mot extrait dans le document a un score de confiance associé. Le score représente le degré de confiance de la transcription. Le tableau des pages contient un tableau de mots, et chaque mot est associé à une portée et à un score de confiance. Les portées des valeurs extraites des champs personnalisés correspondent aux portées des mots extraits.
- Score de confiance des marques de sélection : le tableau des pages contient également un tableau de marques de sélection. Chaque marque de sélection a un score de confiance représentant la confiance de la marque de sélection et de la détection de l’état de sélection. Lorsqu’un champ étiqueté contient une marque de sélection, la sélection du champ personnalisé combinée à la confiance dans la marque de sélection est une représentation précise de l’exactitude de la confiance globale.
Le tableau suivant montre comment interpréter les scores de précision et de confiance pour mesurer les performances de votre modèle personnalisé.
| Précision | Confiance | Résultats |
|---|---|---|
| Élevé | Élevé | • Le modèle s’exécute bien avec les clés et les formats de document étiquetés. • Vous avez un jeu de données d’entraînement équilibré. |
| Élevé | Faible | • Le document analysé est différent du jeu de données d’entraînement. • Le modèle peut tirer parti d’un nouvel entraînement avec au moins cinq documents étiquetés supplémentaires. • Ces résultats peuvent également indiquer une variation de format entre le jeu de données d’entraînement et le document analysé. Vous pouvez ajouter un nouveau modèle. |
| Faible | Élevé | • Ce résultat est très improbable. • Pour les scores avec une faible exactitude, ajoutez des données étiquetées ou fractionnez les documents visuellement distincts en plusieurs modèles. |
| Faible | Faible | • Ajoutez d’autres données étiquetées. • Fractionnez les documents visuellement distincts en plusieurs modèles. |
Veiller à une précision élevée de modèle pour des modèles personnalisés
La variance de structure visuelle de vos documents affecte la précision de votre modèle. Les scores de précision mesurés peuvent être incohérents lorsque les documents analysés diffèrent de ceux utilisés dans l’apprentissage. Gardez à l’esprit qu’un ensemble de documents peut paraître similaire lorsqu’il est affiché par des humains, mais paraître différent d’un modèle IA. Vous trouverez ci-dessous une liste des meilleures pratiques pour les modèles d’apprentissage affichant la plus grande précision. Suivez ces instructions pour produire un modèle avec des scores de précision et de confiance plus élevés lors de l’analyse et pour réduire le nombre de documents qui feront l’objet d’une révision humaine.
Veillez à ce que toutes les variantes d’un document soient incluses dans le jeu de données d’apprentissage, notamment les différents formats (par exemple des fichiers PDF numériques et numérisés).
Ajoutez au moins cinq échantillons de chaque type au jeu de données d’entraînement si vous voulez que le modèle analyse les deux types de documents PDF.
Séparez les types de documents visuellement distincts pour effectuer l’apprentissage de différents modèles pour des modèles neuronaux et des modèles personnalisés.
- En règle générale, si vous supprimez toutes les valeurs entrées par l’utilisateur et que les documents semblent similaires, vous devez ajouter d’autres données d’apprentissage au modèle existant.
- Si les documents sont différents, fractionnez vos données de formation dans différents dossiers et effectuez l’apprentissage d’un modèle pour chaque variation. Vous pouvez ensuite composer les différentes variations dans un modèle unique.
Vérifiez que vous n’avez pas d’étiquettes superflues.
Vérifiez que l’étiquetage de signature et de région n’inclue pas le texte environnant.
Confiance de table, de ligne et de cellule
Voici quelques questions courantes qui doivent vous aider à interpréter les scores de table, de ligne et de cellule :
Q : Est-il possible de voir un score de confiance élevé pour des cellules, mais un score de confiance faible pour la ligne ?
R : Oui. Les différents niveaux de confiance de table (cellule, ligne et table) sont destinés à capturer la justesse d’une prédiction à ce niveau spécifique. Une cellule prédite correctement qui appartient à une ligne avec d’autres échecs possibles a une confiance de cellule élevée, mais la confiance de la ligne est faible. De même, une ligne correcte dans une table présentant des difficultés avec d’autres lignes a une confiance de ligne élevée, mais la confiance globale de la table est faible.
Q : Quel est le score de confiance attendu quand les cellules sont fusionnées ? Puisqu’une fusion change le nombre de colonnes identifiées, comment les scores sont-ils affectés ?
R : Quel que soit le type de table, les cellules fusionnées sont censées avoir des valeurs de confiance inférieures. Par ailleurs, la cellule manquante (parce qu’elle a été fusionnée avec une cellule adjacente) doit avoir aussi une valeur NULL avec une confiance inférieure. L’écart de confiance de ces valeurs peut dépendre du jeu de données d’entraînement, mais la tendance générale est que les cellules fusionnées et manquantes ont des scores inférieurs.
Q : Quel est le score de confiance quand une valeur est facultative ? Va-t-on avoir une cellule avec une valeur NULL et un score de confiance élevé si la valeur est manquante ?
R : Si votre jeu de données d’entraînement est représentatif du fait que les cellules sont facultatives, cela permet au modèle de savoir à quelle fréquence une valeur tend à s’afficher dans le jeu d’entraînement, et donc ce à quoi s’attendre pendant l’inférence. Cette fonctionnalité est utilisée pendant le calcul de la confiance d’une prédiction ou quand il n’y a aucune prédiction (NULL). Vous devez vous attendre à un champ vide avec une confiance élevée pour les valeurs manquantes qui sont également principalement vides dans le jeu d’entraînement.
Q : Comment les scores de confiance sont-ils affectés si un champ est facultatif et n’est pas présent ou manqué ? Le score de confiance doit-il répondre à cette question ?
R : Quand une valeur est manquante dans une ligne, la cellule reçoit une valeur NULL et une confiance. Ici, un score de confiance élevé doit signifier que la prédiction du modèle (selon laquelle il n’y a pas de valeur) est plus susceptible d’être correcte. En revanche, un score faible doit signaler une plus grande incertitude du modèle (et donc la possibilité d’une erreur, comme une valeur manquée).
Q : Quelle doit être la confiance de cellule et de ligne pendant l’extraction d’une table multipage avec une ligne fractionnée sur plusieurs pages ?
R : La confiance de cellule doit être élevée et la confiance de ligne doit être potentiellement inférieure à celles des lignes qui ne sont pas fractionnées. La proportion de lignes fractionnées dans le jeu de données d’entraînement peut affecter le score de confiance. En général, une ligne fractionnée est différente des autres lignes de la table (par conséquent, le modèle a moins de certitude qu’elle soit correcte).
Q : Pour les tables sur plusieurs pages avec des lignes qui se terminent et commencent nettement aux limites de page, est-il correct de supposer que les scores de confiance sont cohérents entre les pages ?
R : Oui. Comme les lignes sont similaires quant à la forme et au contenu, quel que soit l’emplacement où elles se trouvent dans le document (ou la page), leurs scores de confiance respectifs doivent être cohérents.
Q : Quelle est la meilleure façon d’utiliser les nouveaux scores de confiance ?
R : Examinez tous les niveaux de confiance de table de haut en bas : commencez par vérifier la confiance d’une table dans son ensemble, puis examinez les lignes individuelles, enfin examinez la confiance au niveau des cellules. Selon le type de table, notez que :
Pour les tables fixes, la confiance au niveau des cellules capture déjà un peu d’informations sur la justesse. Cela signifie que le simple fait de vérifier la confiance de chaque cellule peut être suffisant pour aider à déterminer la qualité de la prédiction. Pour les tables dynamiques, les niveaux reposent les uns sur les autres, de sorte que l’approche de haut en bas est plus importante.