Génération augmentée de récupération avec Azure AI Intelligence documentaire
Ce contenu s’applique à : ![]() v4.0 (GA)
v4.0 (GA)
Introduction
La génération augmentée de récupération (RAG) est un modèle de conception qui associe un modèle de langage étendu (LLM) pré-entraîné tel que ChatGPT à un système de recherche de données externe pour générer une réponse améliorée incorporant de nouvelles données en dehors des données d’entraînement d’origine. L’ajout d’un système de récupération d’informations à vos applications vous permet de converser avec vos documents, de générer du contenu captivant et d’accéder à la puissance des modèles Azure OpenAI pour vos données. Vous disposez également d’un contrôle accru sur les données utilisées par le LLM lors de la formulation d’une réponse.
Le modèle de disposition d’Intelligence documentaire est une API avancée d’analyse de documents basée sur le Machine Learning. Le modèle de disposition offre une solution complète pour des capacités avancées d’extraction de contenu et d’analyse de la structure des documents. Le modèle de disposition permet d’extraire facilement le texte et les éléments structurels de documents, divisant ainsi de grands corps de texte en blocs explicites plus petits en fonction de leur contenu sémantique et non de fractionnements arbitraires. Vous pouvez facilement enregistrer les informations extraites au format de sortie Markdown, ce qui vous permet de définir votre stratégie de segmentation sémantique selon les modules fournis.
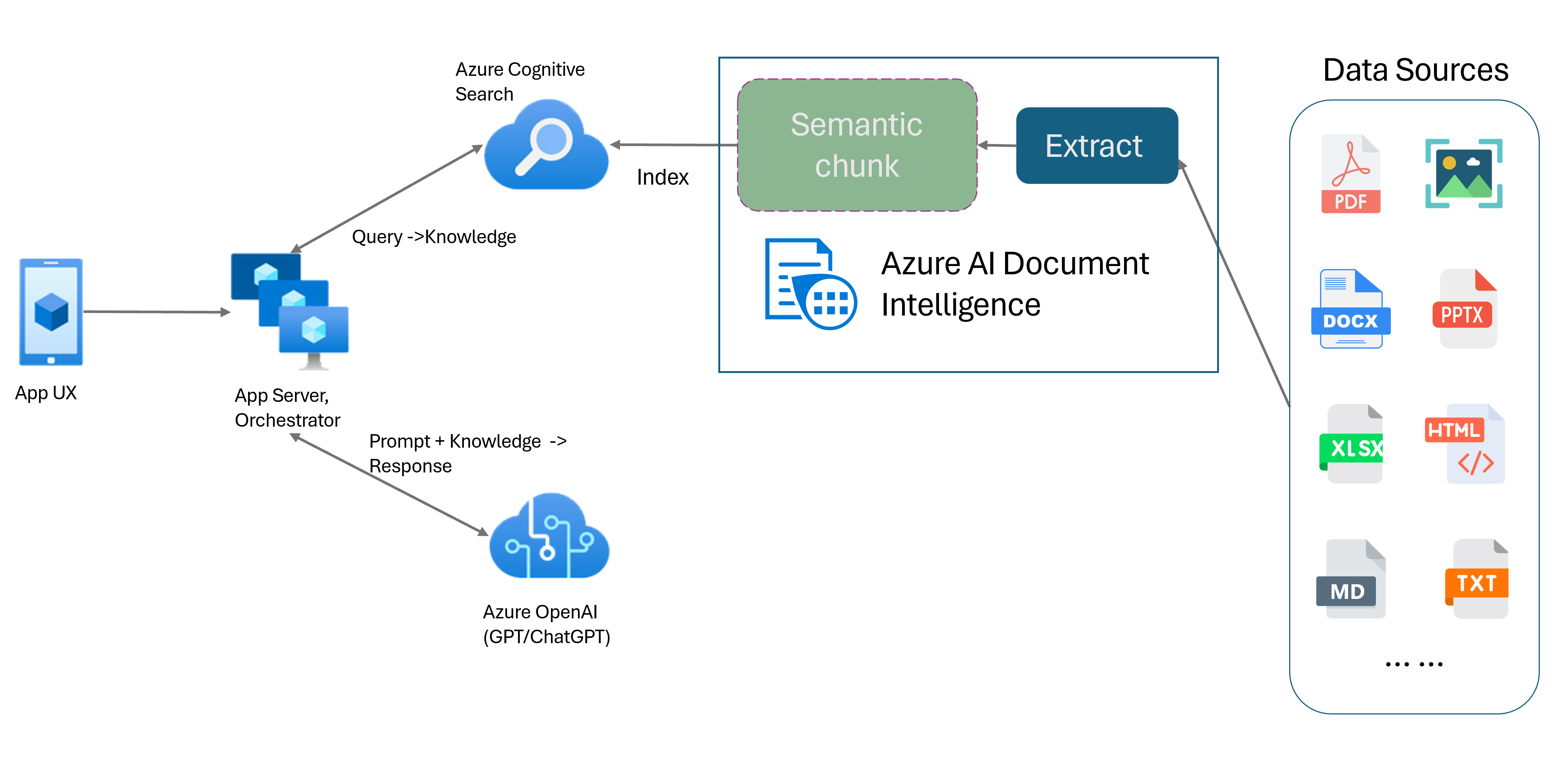
Segmentation sémantique
Les phrases longues sont problématiques pour les applications de traitement du langage naturel (NLP, Natural Language Processing). Cela est d’autant plus vrai lorsque ces phrases contiennent plusieurs clauses, des noms ou des verbes complexes, des clauses relatives et des regroupements entre parenthèses. À l’instar d’un observateur humain, un système NLP doit également suivre correctement toutes les dépendances présentées. L’objectif de la segmentation sémantique est de trouver les fragments sémantiquement cohérents d’une représentation de phrase. Ces fragments peuvent ensuite être traités indépendamment et recombinés en tant que représentations sémantiques sans aucune perte d’informations, erreur d’interprétation ou absence de pertinence sémantique. La signification inhérente du texte sert de guide au processus de segmentation.
Les stratégies de segmentation de données de texte jouent un rôle clé dans l’optimisation de la réponse et des performances de RAG. Il existe deux méthodes de segmentation distinctes qui sont la segmentation à taille fixe et la segmentation sémantique :
Segmentation à taille fixe. La plupart des stratégies de segmentation utilisées dans RAG aujourd’hui sont basées sur des segments de texte à taille fixe appelés blocs. Sur du texte dépourvu d’une structure sémantique forte, comme des journaux ou des données, la segmentation à taille fixe est rapide, facile et efficace. Toutefois, elle n’est pas recommandée si le texte nécessite une compréhension sémantique et un contexte précis. En effet, la taille fixe de la fenêtre peut entraîner la coupure de mots, de phrases ou de paragraphes, entravant la compréhension et perturbant le flux d’informations et la compréhension.
Segmentation sémantique. Cette méthode divise le texte en blocs en fonction de la compréhension sémantique. Les limites de la division sont axées sur le sujet de chaque phrase et utilisent des ressources de calcul complexes sur le plan algorithmique. Toutefois, cette segmentation présente l’avantage distinct de maintenir la cohérence sémantique au sein de chaque bloc. Elle est utile pour les tâches de résumé de texte, d’analyse des sentiments et de classification de documents.
Segmentation sémantique avec modèle de disposition Intelligence documentaire
Markdown est un langage de balisage structuré et mis en forme. Il est couramment utilisé en entrée pour permettre la segmentation sémantique dans RAG. Vous pouvez utiliser le contenu Markdown du modèle de disposition pour fractionner des documents en fonction des limites de paragraphe, créer des blocs spécifiques pour les tableaux et affiner votre stratégie de segmentation afin d’améliorer la qualité des réponses générées.
Avantages du modèle de disposition
Traitement simplifié. Vous pouvez analyser différents types de documents numériques et numérisés, notamment des fichiers PDF, des images, des fichiers Office (docx, xlsx, pptx) et des fichiers HTML, avec un seul appel d’API.
Scalabilité et qualité de l’IA. Le modèle de disposition est hautement scalable en matière de reconnaissance optique de caractères (OCR), d’extraction de tableaux et d’analyse de la structure de documents. Il prend en charge 309 langues imprimées et 12 langues manuscrites, ce qui garantit des résultats de très bonne qualité grâce aux capacités de l’IA.
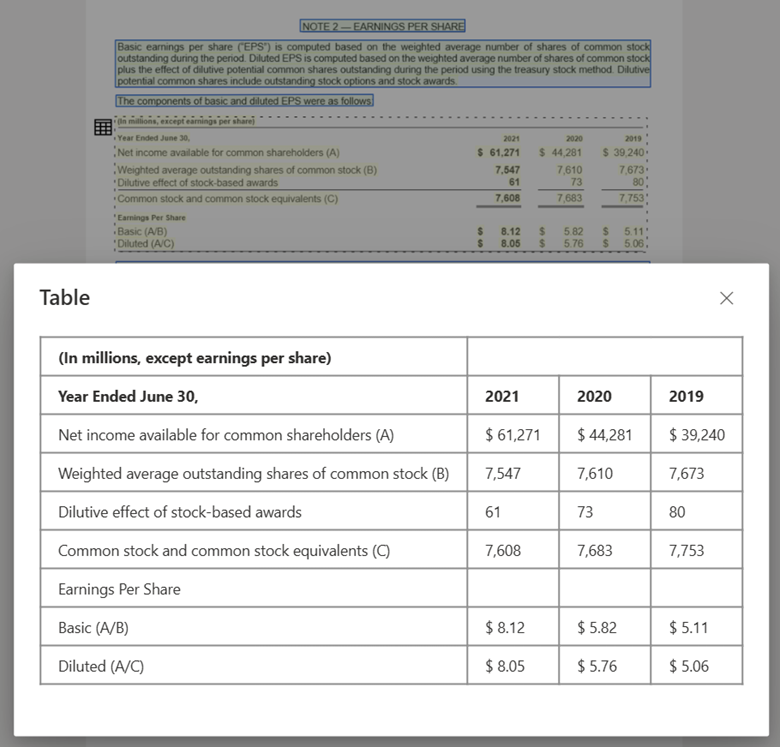
Compatibilité du grand modèle de langage (LLM). La sortie au format Markdown du modèle de disposition est compatible avec les LLM et facilite une intégration transparente dans vos workflows. Vous pouvez convertir n’importe quel tableau contenu dans un document au format Markdown et éviter le travail considérable lié à l’analyse des documents pour améliorer la compréhension des LLM.
Image de texte traitée avec Document Intelligence Studio et enregistrée au format de sortie Markdown à l’aide du modèle de disposition

Image de tableau traitée avec Document Intelligence Studio à l’aide du modèle de disposition
Démarrage
Le modèle de disposition Intelligence documentaire 2024-11-30 (GA) prend en charge les options de développement suivantes :
Prêt à commencer ?
Document Intelligence Studio
Vous pouvez suivre le guide de démarrage rapide de Document Intelligence Studio pour démarrer. Ensuite, vous pouvez intégrer des fonctionnalités d’Intelligence documentaire à votre propre application à l’aide de l’exemple de code fourni.
Commencez par le modèle de disposition. Vous devez sélectionner les options d’analyse suivantes pour utiliser RAG dans le studio :
**Required**- Plage d’exécution de l’analyse → Document actuel.
- Plage de pages → Toutes les pages.
- Style du format de sortie → Markdown.
**Optional**- Choisissez d’autres paramètres de détection si vous le souhaitez.
Cliquez sur Enregistrer.
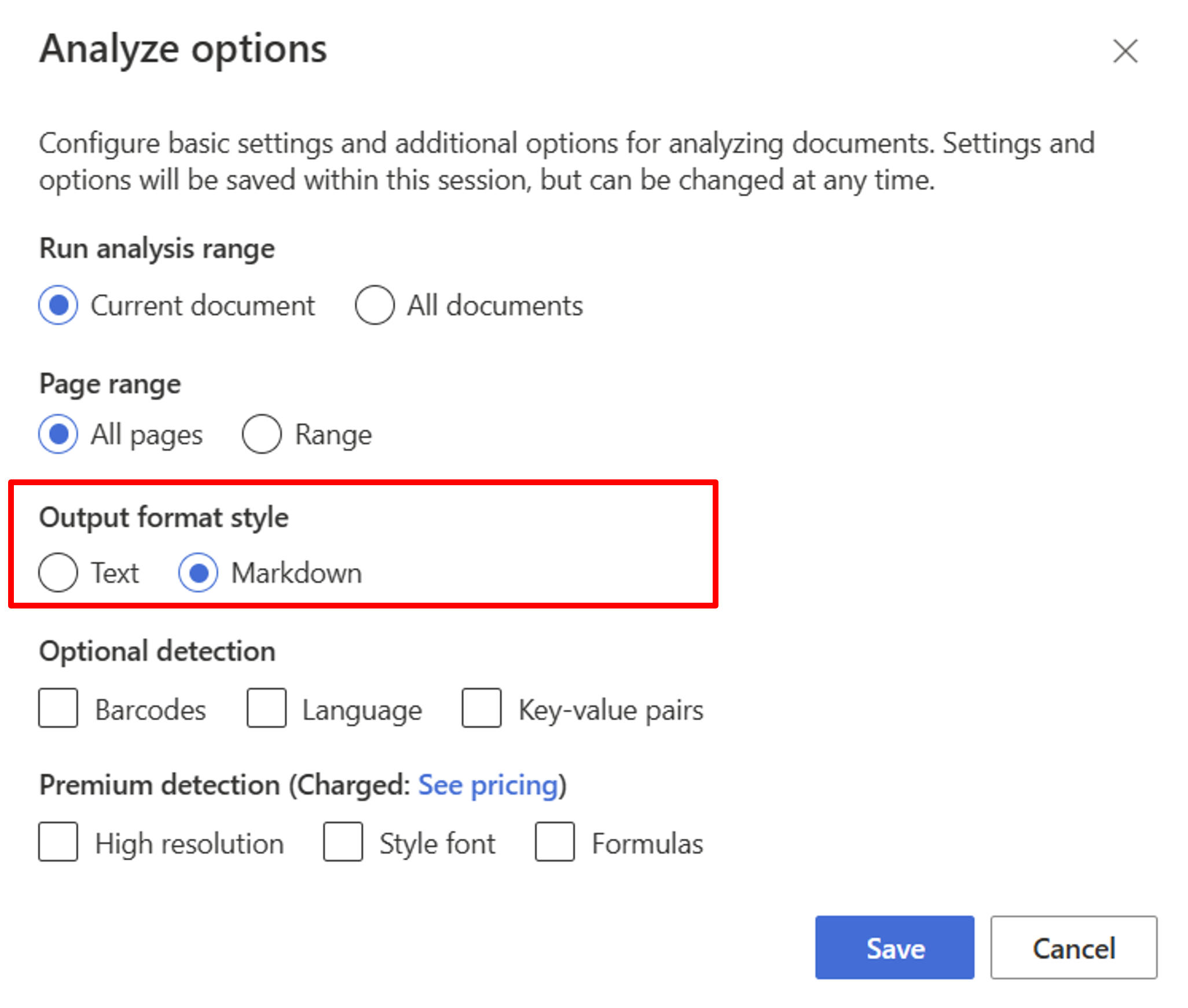
Sélectionnez le bouton Exécuter l’analyse pour afficher la sortie.

SDK ou API REST
Vous pouvez suivre le démarrage rapide d’Intelligence documentaire pour l’API REST ou le kit de développement logiciel (SDK) de votre langage de programmation préféré. Utilisez le modèle de disposition pour extraire le contenu et la structure de vos documents.
Vous pouvez également consulter les référentiels GitHub pour obtenir des exemples de code et des conseils relatifs à l’analyse d’un document au format de sortie Markdown.
Créer une conversation sur des documents avec la segmentation sémantique
Azure OpenAI sur vos données vous permet d’exécuter une conversation prise en charge sur vos documents. Azure OpenAI sur vos données applique le modèle de disposition Intelligence documentaire pour extraire et analyser les données des documents en découpant le texte long en fonction des tableaux et des paragraphes. Vous pouvez également personnaliser votre stratégie de segmentation à l’aide d’ exemples de scripts Azure OpenAI proposés dans notre référentiel GitHub.
Azure AI Intelligence documentaire est désormais intégré à LangChain et fait partie des chargeurs de documents disponibles. Vous pouvez l’utiliser pour charger facilement les données et les enregistrer au format de sortie Markdown. Pour plus d’informations, consultez notre exemple de code qui présente une démonstration simple du modèle RAG avec Azure AI Intelligence documentaire comme chargeur de documents et Azure Search comme outil de récupération dans LangChain.
La conversation avec l’accélérateur de votre solution de données exemple de code illustre un exemple de schéma de base RAG de bout en bout. Il utilise Recherche Azure AI comme outil de récupération et Azure AI Intelligence documentaire pour le chargement de documents et la segmentation sémantique.
Cas d’usage
Si vous recherchez une section spécifique dans un document, vous pouvez utiliser la segmentation sémantique pour diviser le document en blocs plus petits en fonction des en-têtes de section. Vous pourrez ainsi trouver la section qui vous intéresse plus rapidement et plus facilement :
# Using SDK targeting 2024-11-30 (GA), make sure your resource is in one of these regions: East US, West US2, West Europe
# pip install azure-ai-documentintelligence==1.0.0b1
# pip install langchain langchain-community azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
endpoint = "https://<my-custom-subdomain>.cognitiveservices.azure.com/"
key = "<api_key>"
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
loader = AzureAIDocumentIntelligenceLoader(file_path="<path to your file>", api_key = key, api_endpoint = endpoint, api_model="prebuilt-layout")
docs = loader.load()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = docs[0].page_content
splits = text_splitter.split_text(docs_string)
splits
Étapes suivantes
Apprenez-en davantage sur Azure AI Intelligence documentaire.
Découvrez comment traiter vos propres formulaires et documents avec Document Intelligence Studio.
Effectuez un démarrage rapide Intelligence Documentaire et commencez à créer une application de traitement de documents dans le langage de développement de votre choix.