Modèles de traitement de documents
Ce contenu s’applique à : ![]() v3.1 (GA) | Dernière version :
v3.1 (GA) | Dernière version : ![]() v4.0 (GA) | Versions précédentes :
v4.0 (GA) | Versions précédentes : ![]() v3.0
v3.0 ![]() v2.1
v2.1
Ce contenu s’applique à : ![]() v3.0 (GA) | Dernières versions :
v3.0 (GA) | Dernières versions : ![]() v4.0 (GA)
v4.0 (GA) ![]() v3.1 | Version précédente :
v3.1 | Version précédente : ![]() v2.1
v2.1
Ce contenu s’applique à : ![]() v2.1 | Dernière version :
v2.1 | Dernière version : ![]() v4.0 (GA)
v4.0 (GA)
Azure AI Intelligence documentaire prend en charge un large éventail de modèles qui vous permettent d’ajouter un traitement de documents intelligent à vos applications et flux. Vous pouvez utiliser un modèle spécifique au domaine prédéfini ou former un modèle personnalisé adapté à vos besoins métier et cas d’usage spécifiques. Le service Intelligence documentaire peut être utilisé avec l’API REST ou les bibliothèques de client Python, C#, Java et JavaScript.
Remarque
- Les projets de traitement de documents qui impliquent des données financières, des données de santé protégées, des données personnelles ou des données hautement sensibles nécessitent une attention particulière.
- Veillez à respecter toutes les exigences nationales, régionales et sectorielles.
Vue d’ensemble des modèles
Le tableau suivant présente les modèles disponibles pour chaque API stable :
| Type de modèle | Modèle | • 2024-11-30 (GA) | 31-07-2023 (GA) | 2022-08-31 (GA) | v2.1 (GA) |
|---|---|---|---|---|---|
| Modèles d’analyse de documents | Lire | ✔️ | ✔️ | ✔️ | n/a |
| Modèles d’analyse de documents | Disposition | ✔️ | ✔️ | ✔️ | ✔️ |
| Modèles d’analyse de documents | Document général | déplacé vers le layout** | ✔️ | ✔️ | n/a |
| Modèles prédéfinis | Chèque bancaire | ✔️ | n/a | n/a | n/a |
| Modèles prédéfinis | Relevé de compte | ✔️ | n/a | n/a | n/a |
| Modèles prédéfinis | Paystub | ✔️ | n/a | n/a | n/a |
| Modèles prédéfinis | Contrat | ✔️ | ✔️ | n/a | n/a |
| Modèles prédéfinis | Carte d’assurance maladie | ✔️ | ✔️ | ✔️ | n/a |
| Modèles prédéfinis | Document d’identité | ✔️ | ✔️ | ✔️ | ✔️ |
| Modèles prédéfinis | Facture | ✔️ | ✔️ | ✔️ | ✔️ |
| Modèles prédéfinis | Réception | ✔️ | ✔️ | ✔️ | ✔️ |
| Modèles prédéfinis | Modèle fiscal américain unifié | ✔️ | n/a | n/a | n/a |
| Modèles prédéfinis | Taxe américaine 1040* | ✔️ | ✔️ | n/a | n/a |
| Modèles prédéfinis | Taxe américaine 1095* | ✔️ | n/a | n/a | n/a |
| Modèles prédéfinis | Taxe américaine 1098* | ✔️ | n/a | n/a | n/a |
| Modèles prédéfinis | Taxe américaine 1099* | ✔️ | n/a | n/a | n/a |
| Modèles prédéfinis | Taxe américaine W2 | ✔️ | ✔️ | ✔️ | n/a |
| Modèles prédéfinis | Taxe américaine W4 | ✔️ | n/a | n/a | n/a |
| Modèles prédéfinis | Hypothèque américaine 1003 URLA | ✔️ | n/a | n/a | n/a |
| Modèles prédéfinis | Prêt hypothécaire américain 1004 URAR | ✔️ | n/a | n/a | n/a |
| Modèles prédéfinis | US Mortgage 1005 | ✔️ | n/a | n/a | n/a |
| Modèles prédéfinis | Hypothèque américaine 1008 – Résumé | ✔️ | n/a | n/a | n/a |
| Modèles prédéfinis | Déclaration de clôture d’un prêt hypothécaire américain | ✔️ | n/a | n/a | n/a |
| Modèles prédéfinis | Certificat de mariage | ✔️ | n/a | n/a | n/a |
| Modèles prédéfinis | Carte de crédit | ✔️ | n/a | n/a | n/a |
| Modèles prédéfinis | Carte de visite | déconseillé | ✔️ | ✔️ | ✔️ |
| Modèle de classification personnalisé | Classifieur personnalisé | ✔️ | ✔️ | n/a | n/a |
| Modèle d’extraction personnalisé | Neural personnalisé | ✔️ | ✔️ | ✔️ | n/a |
| Modèle d’extraction personnalisé | Modèle personnalisé | ✔️ | ✔️ | ✔️ | ✔️ |
| Modèle d’extraction personnalisé | Composé sur mesure | ✔️ | ✔️ | ✔️ | ✔️ |
| Tous les modèles | Fonctionnalités du module complémentaire | ✔️ | ✔️ | n/a | n/a |
* - Contient des sous-modèles. Consultez les informations spécifiques au modèle pour connaître les variantes et sous-types pris en charge.
** Toutes les fonctionnalités du modèle de document général sont disponibles dans le modèle de disposition. Le modèle général n’est plus pris en charge.
Latence
La latence est le délai nécessaire à un serveur d’API pour gérer et traiter une requête entrante et remettre la réponse sortante au client. La durée d’analyse d’un document dépend de la taille (par exemple le nombre de pages) et du contenu associé sur chaque page. Intelligence documentaire est un service multilocataire où la latence des documents similaires est comparable, mais pas toujours identique. Une variabilité occasionnelle de la latence et des performances est inhérente à tout service asynchrone basé sur les micro-services et sans état qui traite les images et les documents volumineux à grande échelle. Bien que nous puissions mettre à l’échelle en permanence le matériel, les fonctionnalités et les capacités de mise à l’échelle, il est toujours possible que vous rencontriez des problèmes de latence au moment de l’exécution.
Capacité du module complémentaire
Vous trouverez ci-dessous les fonctionnalités supplémentaires disponibles dans Intelligence documentaire. Pour tous les modèles, à l’exception du modèle Carte de visite, Intelligence documentaire prend désormais en charge les fonctionnalités de module complémentaire pour permettre une analyse plus sophistiquée. Ces fonctionnalités facultatives peuvent être activées et désactivées selon le scénario d’extraction de documents. Sept fonctionnalités de module complémentaire sont disponibles pour 2023-07-31 (GA) et la version ultérieure de l’API :
ocrHighResolutionformulasstyleFontbarcodeslanguageskeyValuePairsqueryFieldsNot available with the US.Tax modelssearchablePDFOnly available for Read Model
| Capacité du module complémentaire | Module complémentaire/gratuit | • 2024-11-30 (GA) | 2023-07-31 (GA) |
2022-08-31 (GA) |
v2.1 (GA) |
|---|---|---|---|---|---|
| Extraction des propriétés de la police | Module complémentaire | ✔️ | ✔️ | n/a | n/a |
| Extraction de formules | Module complémentaire | ✔️ | ✔️ | n/a | n/a |
| Extraction à haute résolution | Module complémentaire | ✔️ | ✔️ | n/a | n/a |
| Extraction de codes-barres | Gratuit | ✔️ | ✔️ | n/a | n/a |
| Détection de langue | Gratuit | ✔️ | ✔️ | n/a | n/a |
| Paires clé-valeur | Gratuit | ✔️ | n/a | n/a | n/a |
| Champs de requête | Module complémentaire* | ✔️ | n/a | n/a | n/a |
| PDF pouvant faire l’objet d’une recherche | Module complémentaire* | ✔️ | n/a | n/a | n/a |
Fonctionnalités d'Analyse du modèle
| ID de modèle | Extraction de contenu | Champs de requête | Paragraphes | Rôles de paragraphe | Marques de sélection | Tables | Paires clé-valeur | Langages | Codes-barres | Analyse de documents | Formules* | Police de style* | Haute résolution* | PDF pouvant faire l’objet d’une recherche |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| prebuilt-read | ✓ | ✓ | O | O | O | O | O | O | ||||||
| prebuilt-layout | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | O | O | O | O | ||
| prebuilt-contract | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | ||||
| prebuilt-healthInsuranceCard.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-idDocument | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| Facture prédéfinie | ✓ | ✓ | ✓ | ✓ | O | O | O | ✓ | O | O | O | |||
| prebuilt-receipt | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-marriageCertificate.us | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-creditCard | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-check.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-payStub.us | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-bankStatement | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-mortgage.us.1003 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.1004 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.1005 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.1008 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-mortgage.us.closingDisclosure | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.w2 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.w4 | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-tax.us.1040 (variations) | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1095A | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-tax.us.1095C | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| prebuilt-tax.us.1098 | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098E | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1098T | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1099 (variations) | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O | |||||
| prebuilt-tax.us.1099SSA | ✓ | ✓ | O | O | ✓ | O | O | O | ||||||
| { customModelName } | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | O | O | ✓ | O | O | O |
✓ - Activé
O - Facultatif
* - Les fonctionnalités Premium entraînent des coûts supplémentaires
Module complémentaire* : les champs de requête sont facturés différemment des autres fonctionnalités du module complémentaire. Pour en savoir plus, voir les tarifs.
Coordonnées de rectangle englobant et de polygone
Un rectangle englobant (polygon dans v3.0 et les versions ultérieures) est un rectangle abstrait qui entoure des éléments de texte d’un document et qui est utilisé comme point de référence pour la détection d’objets.
Le cadre englobant spécifie la position à l’aide d’un plan de coordonnées x et y présenté dans un tableau de quatre paires numériques. Chaque paire représente un coin de la zone dans l’ordre suivant : supérieur gauche, supérieur droit, inférieur droit, inférieur gauche.
Les coordonnées d’image sont présentées en pixels. Pour un fichier PDF, les coordonnées sont présentées en pouces.
Support multilingue
Les modèles universels basés sur le Deep Learning dans Intelligence documentaire prennent en charge de nombreuses langues pour extraire du texte multilingue de vos images et documents, y compris des lignes de texte mêlant plusieurs langues. La prise en charge des langues varie selon les fonctionnalités du service Intelligence documentaire. Pour obtenir une liste complète, consultez les articles suivants :
- Prise en charge linguistique : modèles analyse de documents
- Prise en charge de la langue : modèles prédéfinis
- Prise en charge linguistique : modèles personnalisés
Disponibilité régionale
Intelligence documentaire est en disponibilité générale dans un grand nombre des plus de 60 régions d’infrastructure globale Azure.
Pour plus d’informations, consultez notre page zones géographiques Azure pour vous aider à choisir la région qui vous convient le mieux et vos clients.
Détails du modèle
Cette section décrit la sortie que vous pouvez attendre de chaque modèle. Vous pouvez étendre la sortie de la plupart des modèles avec des fonctionnalités de module complémentaire.
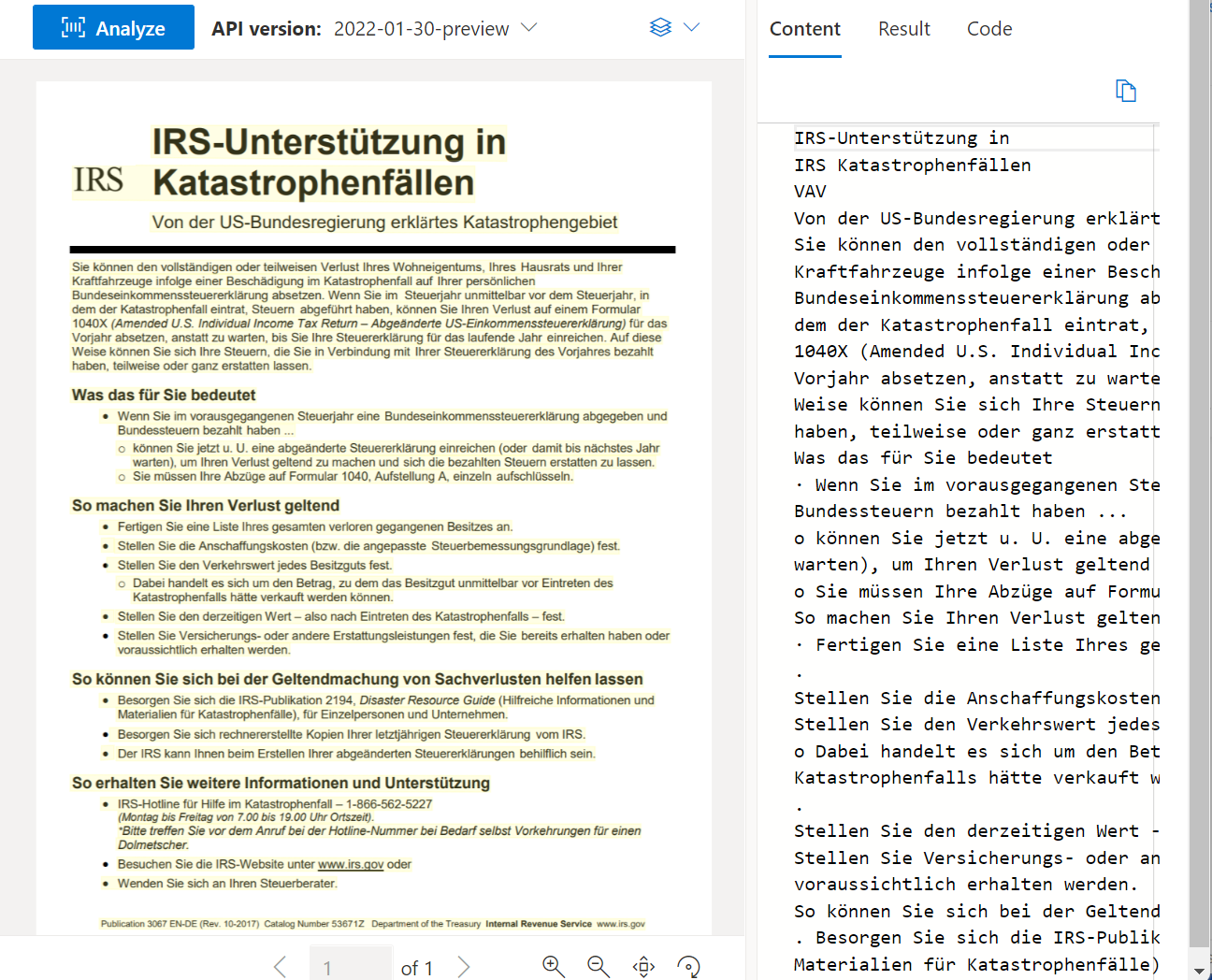
Lire OCR

L’API Read analyse et extrait les lignes, les mots, leur emplacement, les langues détectées et le style manuscrit s’il est détecté.
Exemple de document traité à l’aide du studio Intelligence documentaire :
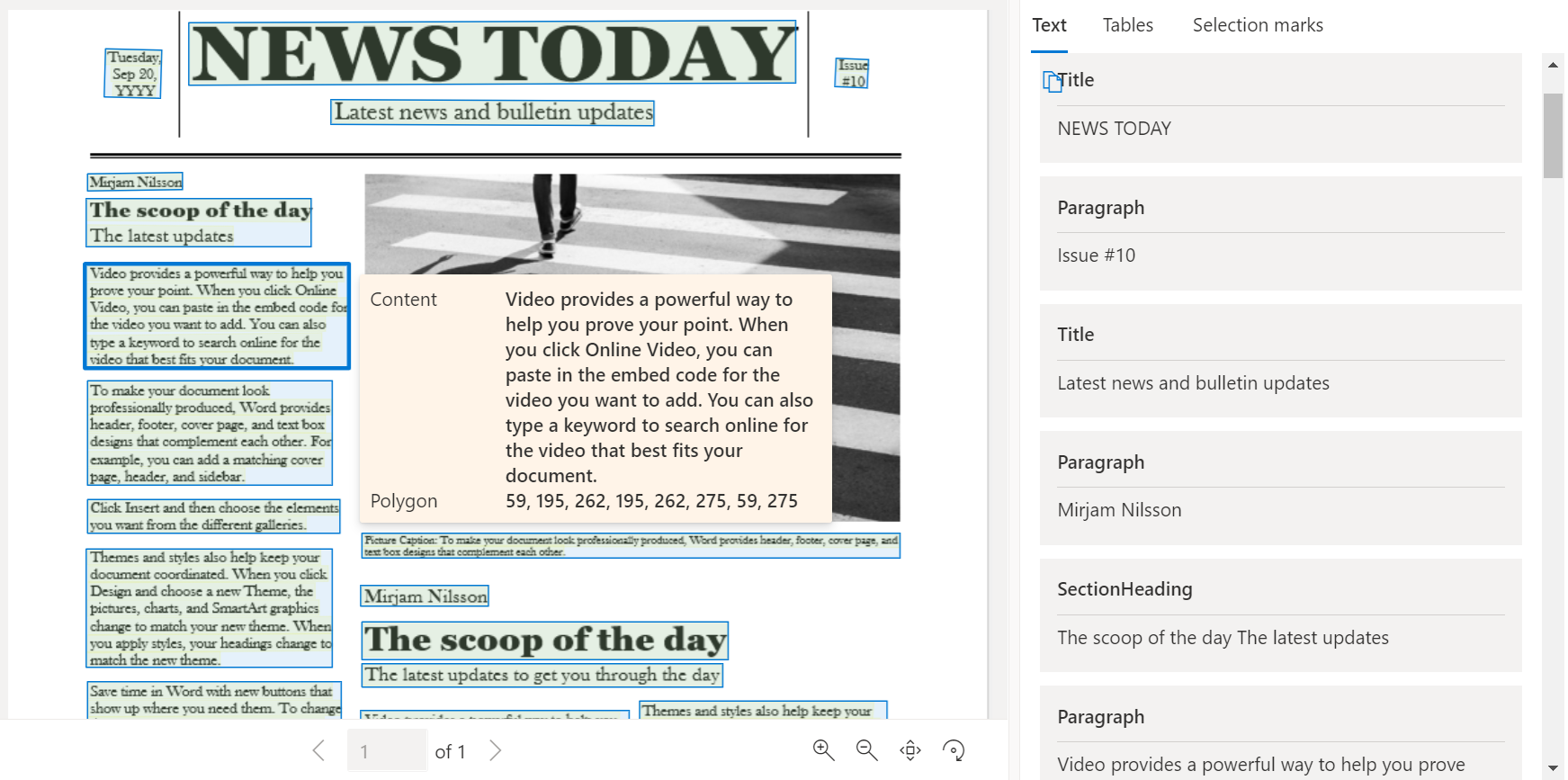
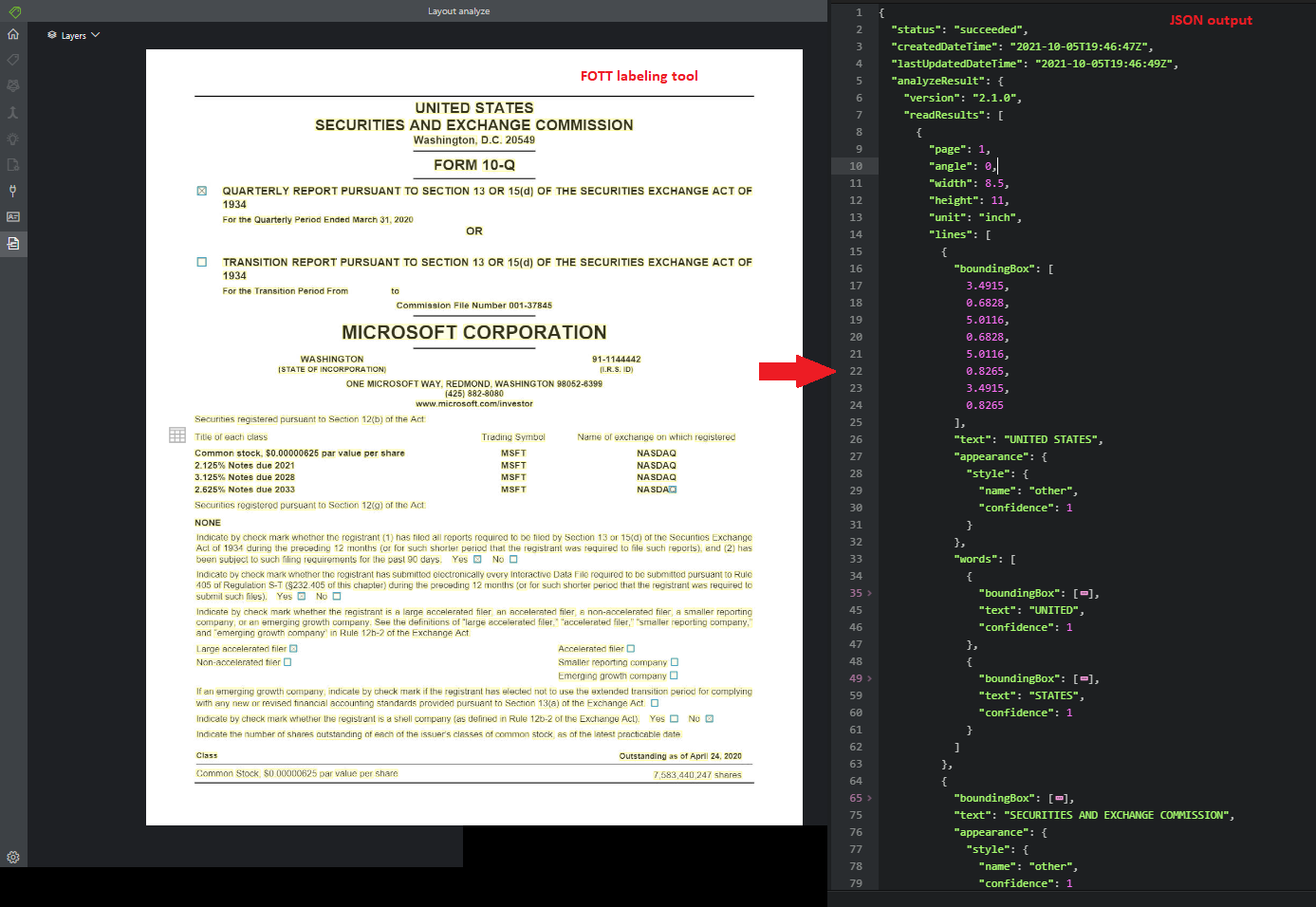
Analyse de disposition

Le modèle d’analyse de la disposition analyse et extrait du texte, des tableaux, des marques de sélection et d’autres éléments de structure tels que les titres, les en-têtes de section, les en-têtes de page, les pieds de page, etc.
Exemple de document traité à l’aide du studio Intelligence documentaire :
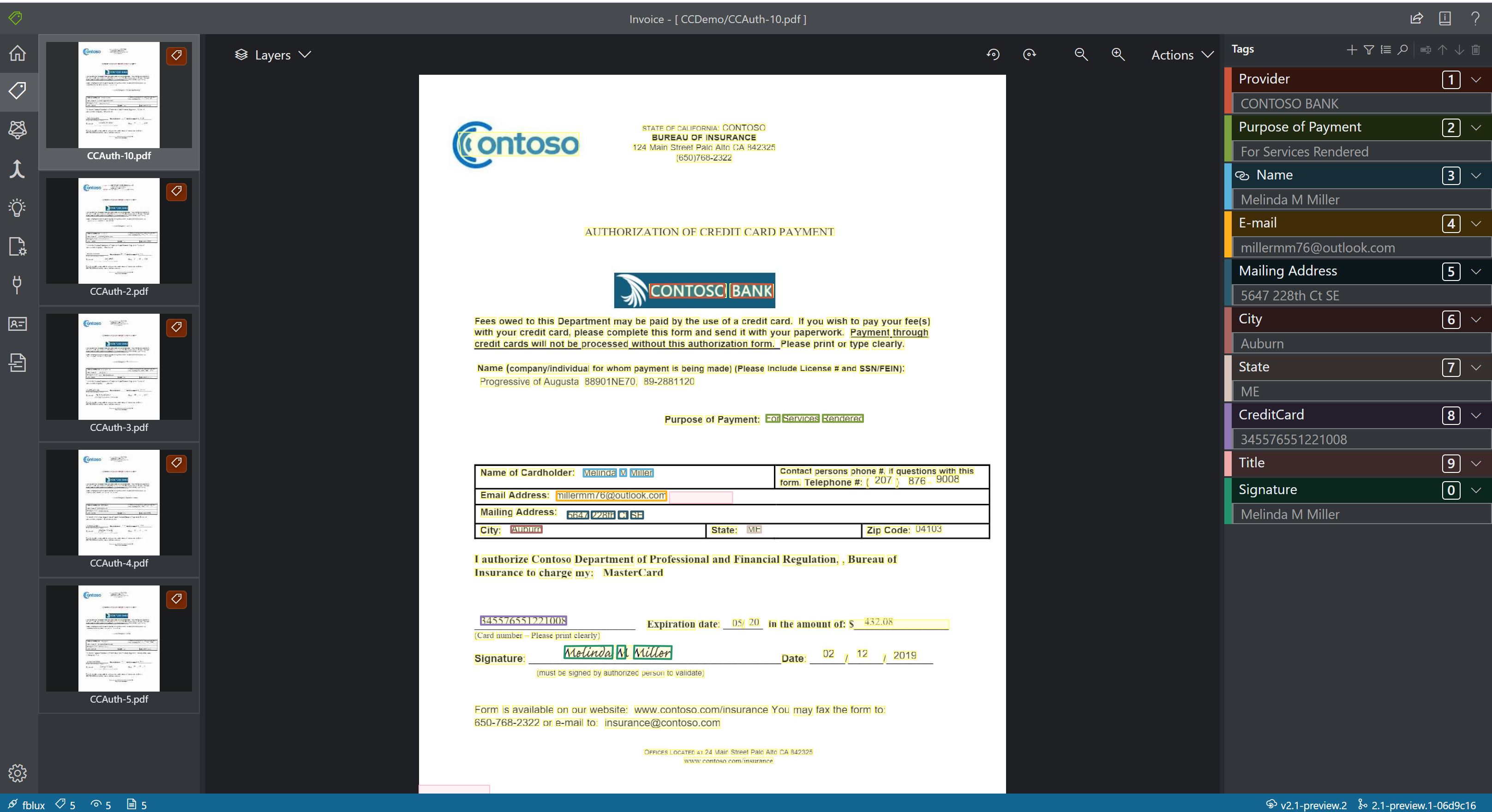
Carte d’assurance maladie
![]()
Le modèle de carte d’assurance maladie combine de puissantes capacités de reconnaissance optique de caractères (OCR) à des modèles Deep Learning pour analyser et extraire des informations clés depuis des images de cartes d’assurance maladie.
Exemple de carte d’assurance maladie américaine traitée à l’aide de Studio Intelligence documentaire :

Documents fiscaux américains
Les modèles de documents fiscaux américains analysent et extraient les champs clés et les éléments de ligne d’un groupe sélectionné de documents fiscaux. L’API prend en charge l’analyse des documents fiscaux américains en langue anglaise et de différents formats et différentes qualités, y compris les images capturées par téléphone, les documents numérisés et les fichiers PDF numériques. Les modèles suivants sont pris en charge :
| Modèle | Description | ModelID |
|---|---|---|
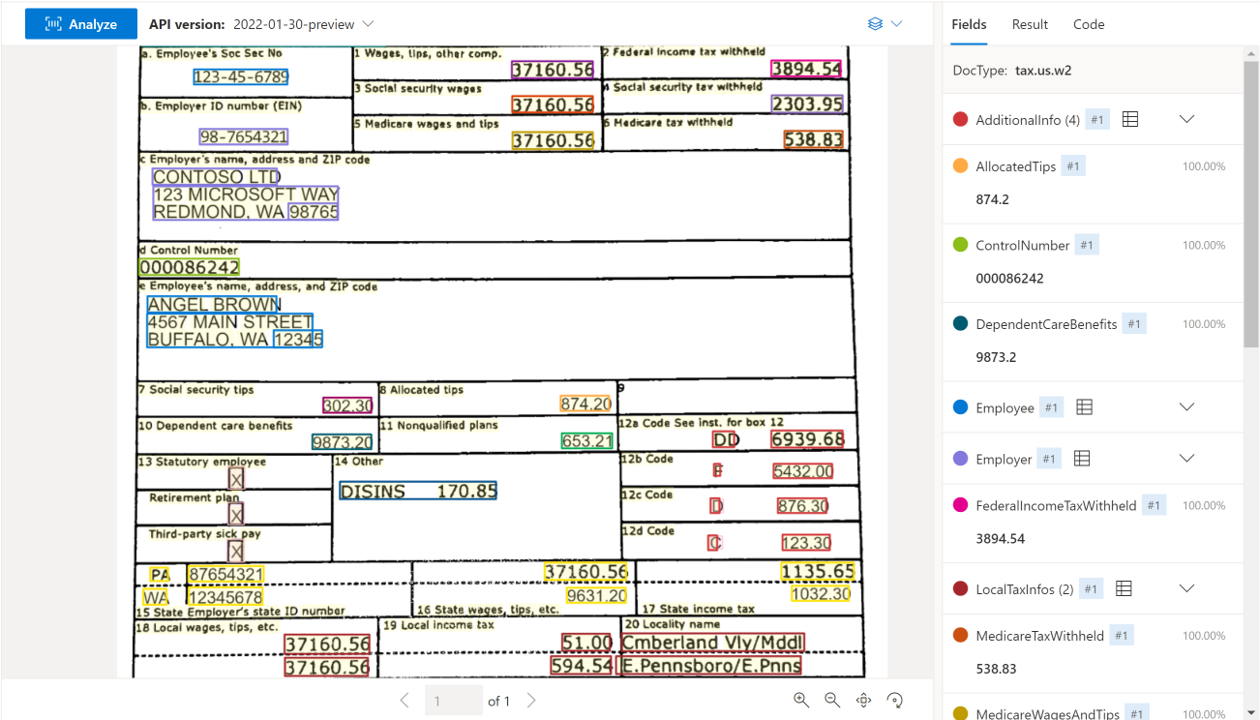
| US Tax W-2 | Extraire les détails de la rémunération imposable. | prebuilt-tax.us.w2 |
| Taxe américaine W-4 | Extraire les détails de la rémunération imposable. | prebuilt-tax.us.w4 |
| Taxe américaine 1040 | Extraire les détails des intérêts hypothécaires. | prebuilt-tax.us.1040(variations) |
| Taxe américaine 1095 | Extraire les détails de l’assurance maladie. | prebuilt-tax.us.1095(variantes) |
| US Tax 1098 | Extraire les détails des intérêts hypothécaires. | prebuilt-tax.us.1098(variations) |
| Taxe américaine 1099 | Extrayez les revenus provenant d’autres sources que l’employeur. | prebuilt-tax.us.1099(variations) |
Exemple de document W-2 traité à l’aide de Studio Intelligence documentaire :
Documents hypothécaires américains

Les modèles de documents hypothécaires américains analysent et extraient les champs clés, y compris les informations sur l’emprunteur, le prêt et les biens d’un groupe sélectionné de documents hypothécaires. L’API prend en charge l’analyse des documents hypothécaires américains en langue anglaise et de différents formats et différentes qualités, y compris les images capturées par téléphone, les documents numérisés et les fichiers PDF numériques. Les modèles suivants sont pris en charge :
| Modèle | Description | ModelID |
|---|---|---|
| 1003 Contrat de licence utilisateur final (CLUF) | Extrayez les détails relatifs au prêt, à l’emprunteur et à la propriété. | prebuilt-mortgage.us.1003 |
| 1004 Formulaire URAR (Uniform Residential Appraisal Report) | Extrayez les détails relatifs au prêt, à l’emprunteur et à la propriété. | prebuilt-mortgage.us.1004 |
| 1005 Vérification de l’emploi | Extrayez les détails relatifs au prêt, à l’emprunteur et à la propriété. | prebuilt-mortgage.us.1005 |
| Document de synthèse 1008 | Extrayez les détails relatifs à l’emprunteur, au vendeur, à la propriété, à l’hypothèque et à la souscription. | prebuilt-mortgage.us.1008 |
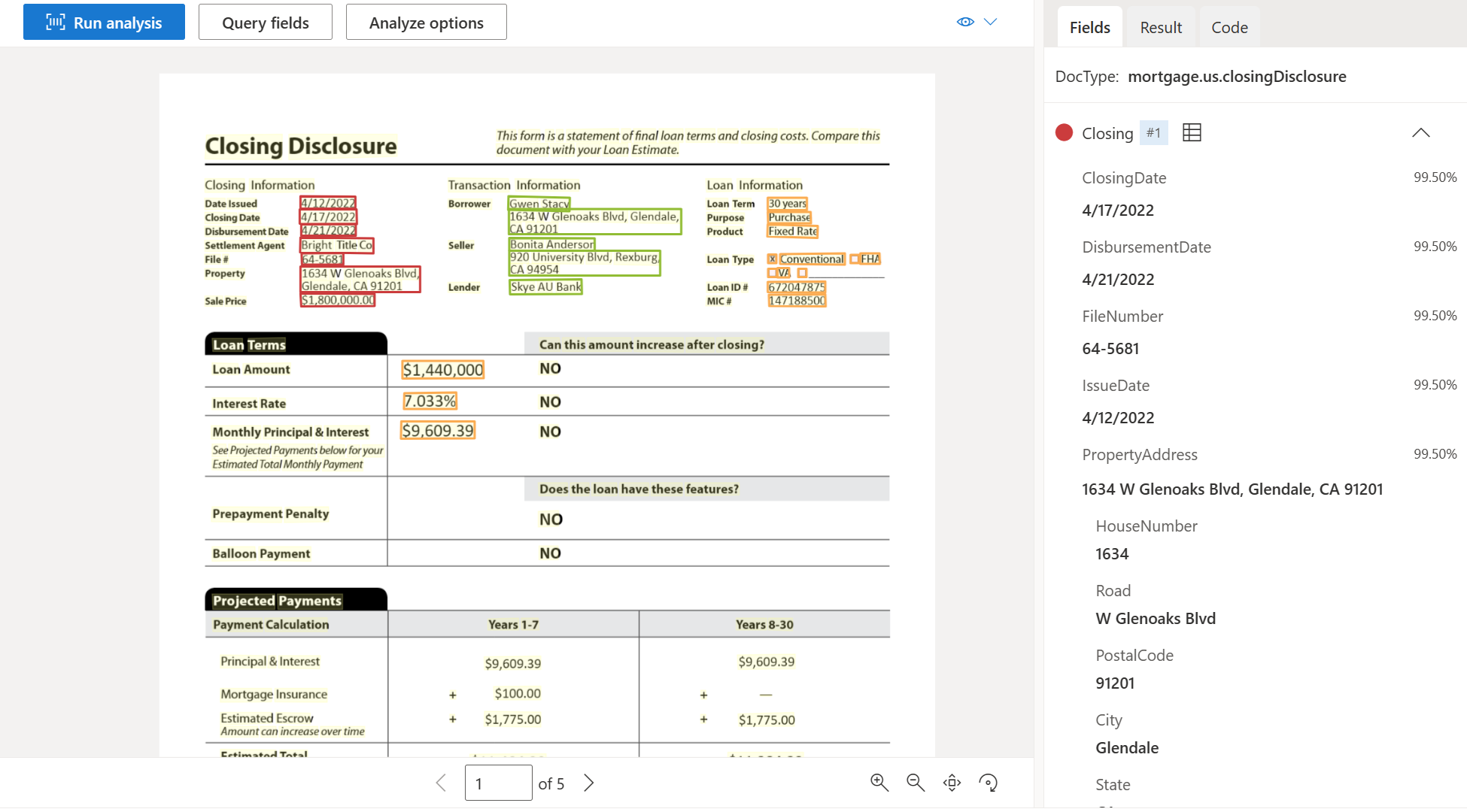
| Divulgation de clôture | Extrayez les détails relatifs à la clôture, aux coûts de transaction et au prêt. | prebuilt-mortgage.us.closingDisclosure |
Exemple de document de divulgation traité à l’aide de Document Intelligence Studio :
Contrat
![]()
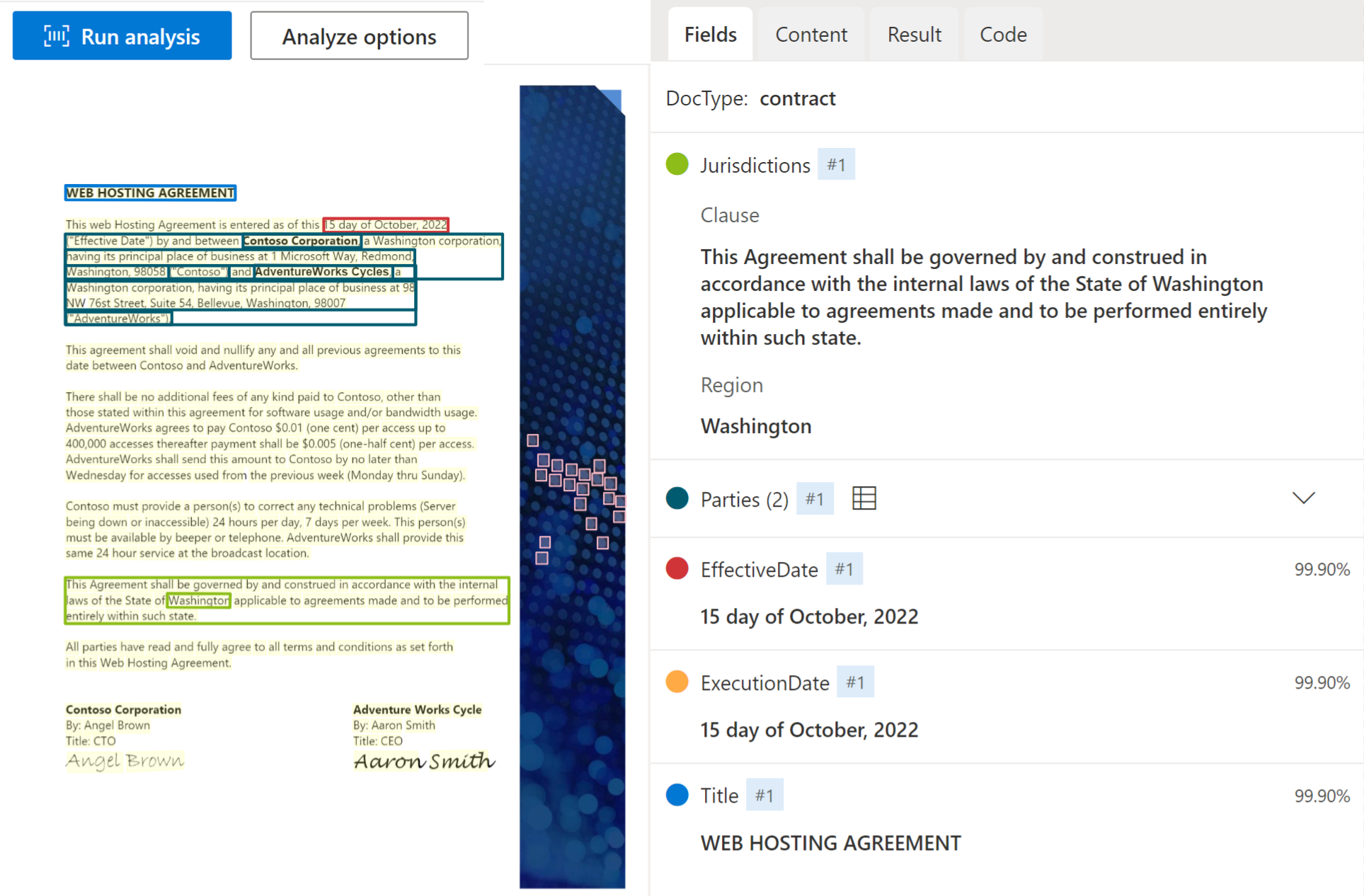
Le modèle de contrat analyse et extrait les champs clés et les éléments de ligne contractuels, y compris les parties, les juridictions, l’ID de contrat et le titre. Le modèle prend actuellement en charge les contrats de document en anglais.
Exemple de contrat traité à l’aide de Studio Intelligence documentaire :
Chèque bancaire américain
![]()
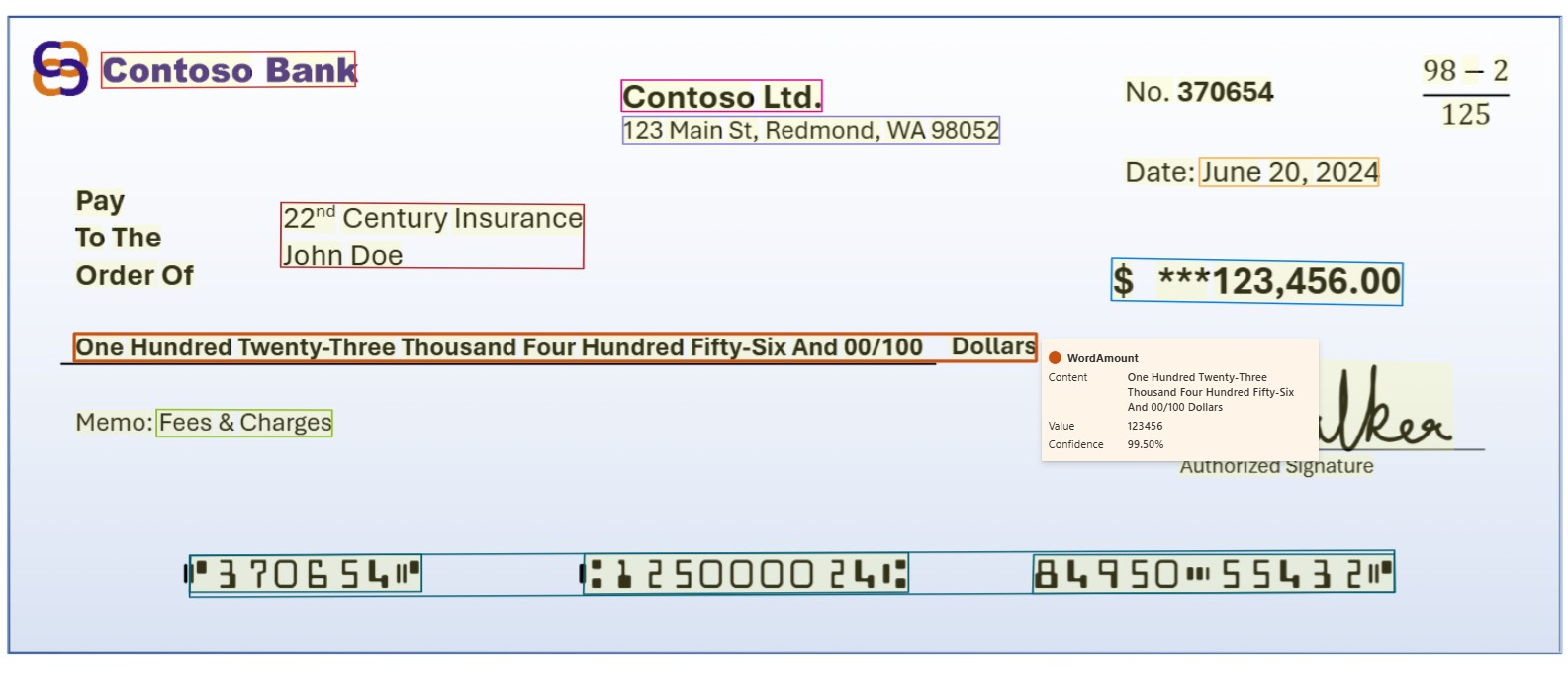
Le modèle de contrat analyse et extrait les champs clés du chèque. Les détails du chèque, les détails du compte, le montant, et le mémo notamment, sont extraits des chèques bancaires américains.
Exemple de chèque bancaire traité à l’aide de Document Intelligence Studio :
Relevé bancaire américain
![]()
Le modèle de relevé bancaire analyse et extrait les champs clés et les lignes des relevés bancaires américains : numéro de compte, coordonnées bancaires, détails du relevé et détails des transactions.
Exemple de relevé bancaire traité à l’aide de Document Intelligence Studio :

PayStub
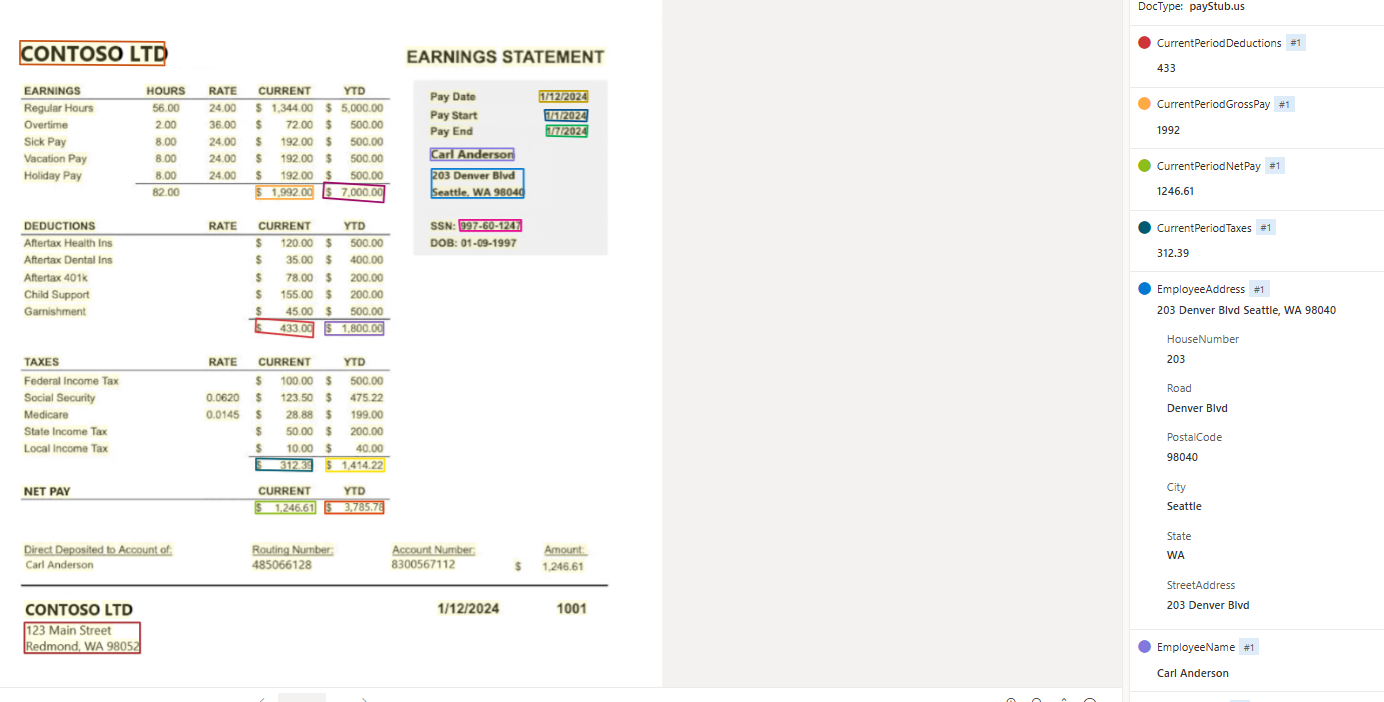
![]()
Le modèle paystub (bulletin de paie) analyse et extrait les champs clés et les lignes des documents et des fichiers contenant les informations relatives à la paie.
Exemple de bulletin de paie traité à l’aide de Document Intelligence Studio :
Facture
Le modèle de facture automatise le traitement des factures pour extraire le nom du client, l’adresse de facturation, la date d’échéance et le montant dû, les articles et autres données clés.
Exemple de facture traitée à l’aide de Studio Intelligence documentaire :

Réception
Utilisez le modèle de reçu pour analyser les reçus de vente afin d’extraire le nom du prestataire, les dates, les éléments de ligne, les quantités et les totaux de reçus imprimés et manuscrits. La version v3.0 prend également en charge le traitement de reçus d’hôtel monopages.
Exemple de reçu traité à l’aide de Studio Intelligence documentaire :

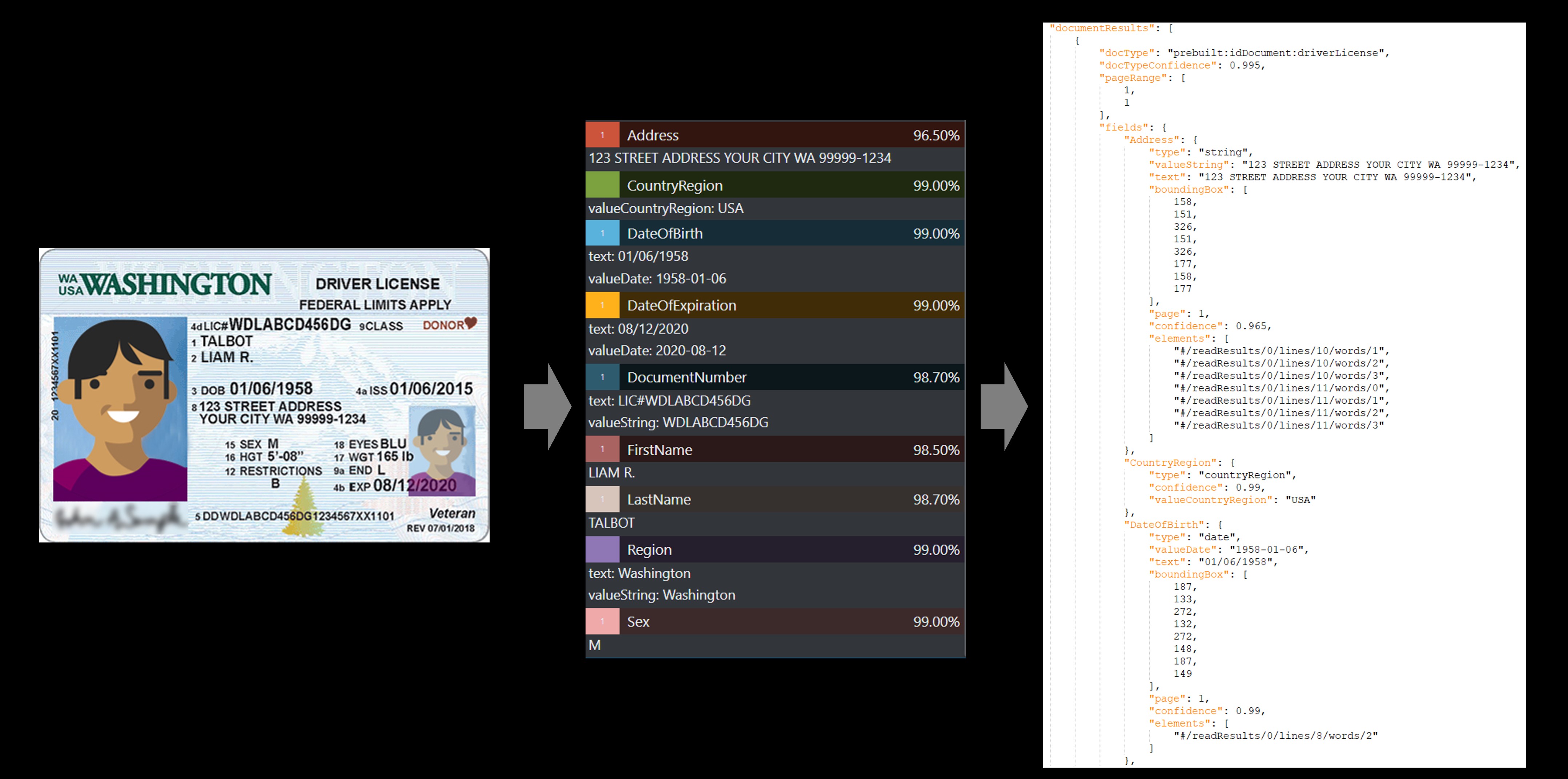
Document d’identité (ID)

Utilisez le modèle de document d’identité (ID) pour traiter des permis de conduire américains (50 États et District de Columbia) et des pages biographiques des passeports internationaux (à l’exclusion des visas et autres documents de voyage) afin d’extraire des champs clés.
Exemple de permis de conduire des États-Unis traité à l’aide de Studio Intelligence documentaire :

Certificat de mariage
![]()
Utilisez le modèle de certificat de mariage pour traiter les certificats de mariage américains pour extraire les champs clés, y compris les individus, la date et l’emplacement.
Exemple de certificat de mariage américain traité à l’aide de Document Intelligence Studio :

Carte de crédit
![]()
Utilisez le modèle de carte de crédit pour traiter les cartes de crédit et de débit pour extraire les champs clés.
Exemple d’une carte de crédit traitée à l’aide de Document Intelligence Studio :

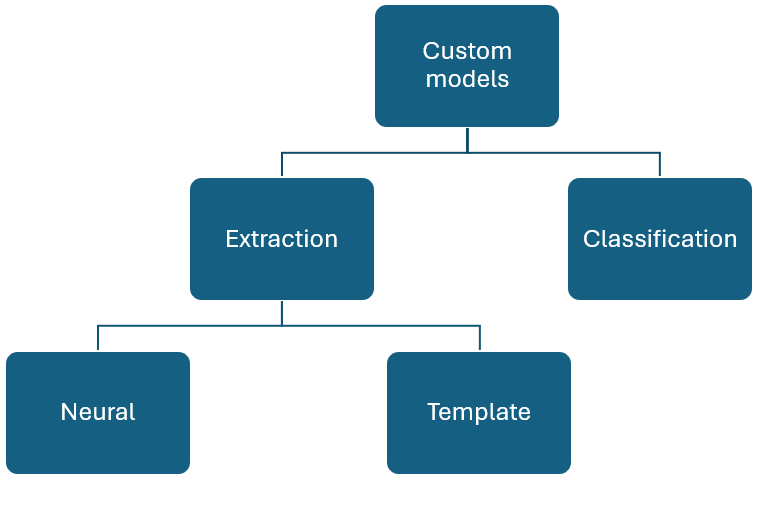
Modèles personnalisés

Les modèles personnalisés peuvent être largement classés en deux types. Modèles de classification personnalisés qui prennent en charge la classification d’un « type de document » et de modèles d’extraction personnalisés qui peuvent extraire un schéma défini à partir d’un type de document spécifique.
Les modèles de documents personnalisés analysent et extraient les données de formulaires et de documents spécifiques à votre entreprise. Ils reconnaissent les champs de formulaire dans votre contenu distinct et extraient des paires clé-valeur et des données de table. Vous n’avez besoin que d’un exemple de type de formulaire pour commencer.
Le modèle personnalisé de la version v3.0 et ultérieures prend en charge la détection des signatures dans les modèles personnalisés (formulaire) et les tables multipage dans les modèles et les modèles neuronaux. La détection de signature recherche la présence d’une signature, et non l’identité de la personne qui signe le document. Si le modèle retourne non signé pour la détection de signature, cela signifie qu’il n’a pas trouvé de signature dans le champ défini.
Exemple de modèle personnalisé traité à l’aide de Studio Intelligence documentaire :
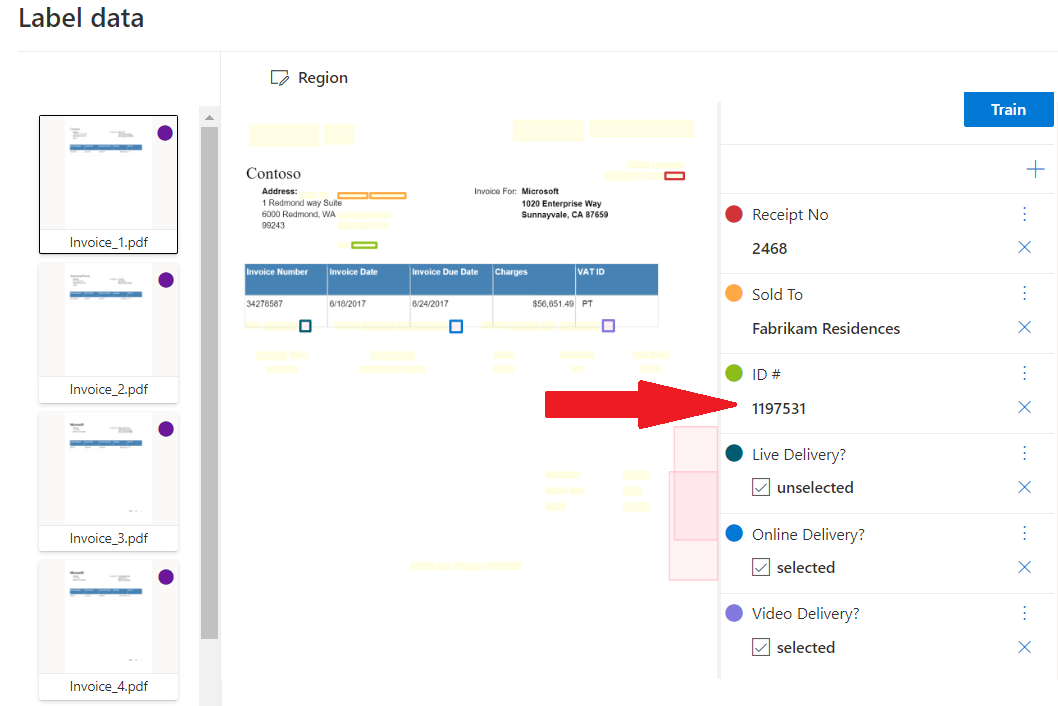
Extraction personnalisée

Le modèle d’extraction personnalisé peut être de deux types : modèle personnalisé et modèle neuronal personnalisé. Pour créer un modèle d’extraction personnalisé, étiquetez un jeu de données de documents avec les valeurs que vous souhaitez extraire et effectuer l’apprentissage du modèle sur le jeu de données étiqueté. Vous n’avez besoin pour commencer que de cinq exemples du même type de formulaire ou de document.
Exemple d’extraction personnalisée traitée à l’aide de Studio Intelligence documentaire :

Classifieur personnalisé

Le modèle de classification personnalisé vous permet d’identifier le type de document avant d’appeler le modèle d’extraction. Le modèle de classification est disponible à partir de l’API2023-07-31 (GA). L’apprentissage d’un modèle de classification personnalisé nécessite au moins deux classes distinctes et un minimum de cinq exemples par classe.
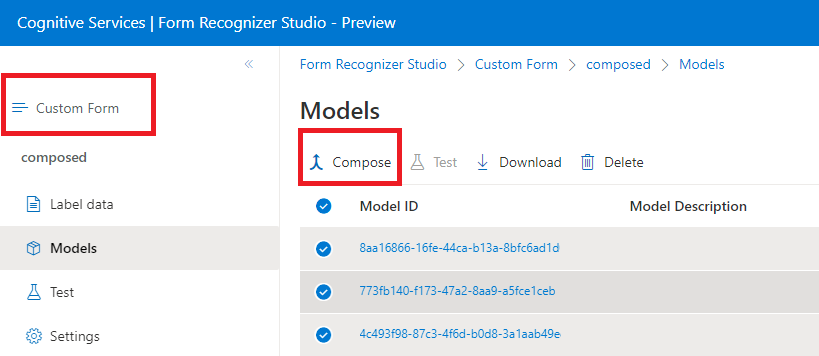
Modèles composés
Pour créer un modèle composé, vous associez une collection de modèles personnalisés à un modèle unique créé à partir de vos types de formulaire. Il est possible d’affecter plusieurs modèles personnalisés à un modèle composé qui est appelé avec un ID de modèle unique. Il est possible d’attribuer jusqu’à 200 modèles personnalisés entraînés à un même modèle composé.
Fenêtre de dialogue de modèle composé dans Studio Intelligence documentaire :
Critères des entrées
Formats de fichiers pris en charge :
Modèle PDF Image : JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office :
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLire ✔ ✔ ✔ Layout ✔ ✔ ✔ Document général ✔ ✔ Prédéfinie ✔ ✔ Extraction personnalisée ✔ ✔ Classification personnalisée ✔ ✔ ✔ Pour de meilleurs résultats, fournissez une photo nette ou une copie de qualité par document.
Pour les PDF et TIFF, jusqu'à 2 000 pages peuvent être traitées (avec un abonnement gratuit, seules les deux premières pages sont traitées).
La taille de fichier pour l’analyse de documents est de 500 Mo pour le niveau payant (S0) et de
4Mo pour le niveau gratuit (F0).Les dimensions de l’image doivent être comprises entre 50 pixels x 50 pixels et 10 000 pixels x 10 000 pixels.
Si vos fichiers PDF sont verrouillés par mot de passe, vous devez supprimer le verrou avant leur envoi.
La hauteur minimale du texte à extraire est de 12 pixels pour une image de 1024 x 768 pixels. Cette dimension correspond environ à un texte de
8points à 150 points par pouce (ppp).Pour la formation de modèles personnalisés, le nombre maximal de pages pour les données de formation est de 500 pour le modèle personnalisé et 50 000 pour le modèle neural personnalisé.
Pour l’apprentissage du modèle d’extraction personnalisé, la taille totale des données d’entraînement est de 50 Mo pour le modèle de gabarit et de
1Go pour le modèle neuronal.Pour l’apprentissage du modèle de classification personnalisé, la taille totale des données d’entraînement est de
1Go, avec un maximum de 10 000 pages. Pour 2024-11-30 (GA), la taille totale des données d’entraînement est de2Go, avec un maximum de 10 000 pages.
Remarque
L’outil d’étiquetage des exemples ne prend pas en charge le format de fichier BMP. Il s’agit d’une limite de l’outil et non du service d’Intelligence documentaire.
Migration de version
Découvrez comment utiliser Intelligence documentaire v3.0 dans vos applications en suivant notre guide de migration Intelligence documentaire v3.1
| Modèle | Description |
|---|---|
| Analyse de documents | |
| Disposition | Extrait des informations sur le texte et la disposition à partir de documents. |
| Prédéfinie | |
| Facture | Extrait des informations clés de factures en anglais et espagnol. |
| Réception | Extrait des informations clés de reçus en anglais. |
| Document d’identité | Extrait des informations clés de permis de conduire américains et de passeports internationaux. |
| Carte de visite | Extrait des informations clés de cartes de visite en anglais. |
| Personnalisée | |
| Personnalisée | Extrait des données de formulaires et de documents spécifiques à votre entreprise. Les modèles personnalisés sont entraînés pour vos données et cas d’usage spécifiques. |
| Composé | Composez une collection de modèles personnalisés et attribuez-les à un modèle unique généré à partir de vos types de formulaires. |
Layout
L’API de disposition analyse et extrait du texte, des tableaux, des en-têtes, des marques de sélection et des informations de structure à partir de documents.
Exemple de document traité avec l’outil d’étiquetage d’échantillon :
Facture
Le modèle de facture analyse et extrait les informations clés des factures. L’API analyse les factures dans différents formats et extrait les informations clés, telles que le nom du client, l’adresse de facturation, la date d’échéance et le montant dû.
Exemple de facture traitée avec l’outil d’étiquetage d’échantillon :

Réception
- Le modèle de reçu analyse et extrait les informations clés des reçus de vente imprimés et manuscrits.
Exemple de reçu traité avec l’outil d’étiquetage d’échantillon :
Document d’identité
Le modèle de document d’ID analyse et extrait les informations clés des documents suivants :
Permis de conduire des États-Unis (tous les 50 États et le district de Columbia)
Pages biographiques des passeports internationaux (à l’exclusion des visas et autres documents de voyage). L’API analyse les documents d’identité et les extraits
Exemple de permis de conduire américain traité avec l’outil d’étiquetage d’échantillon :
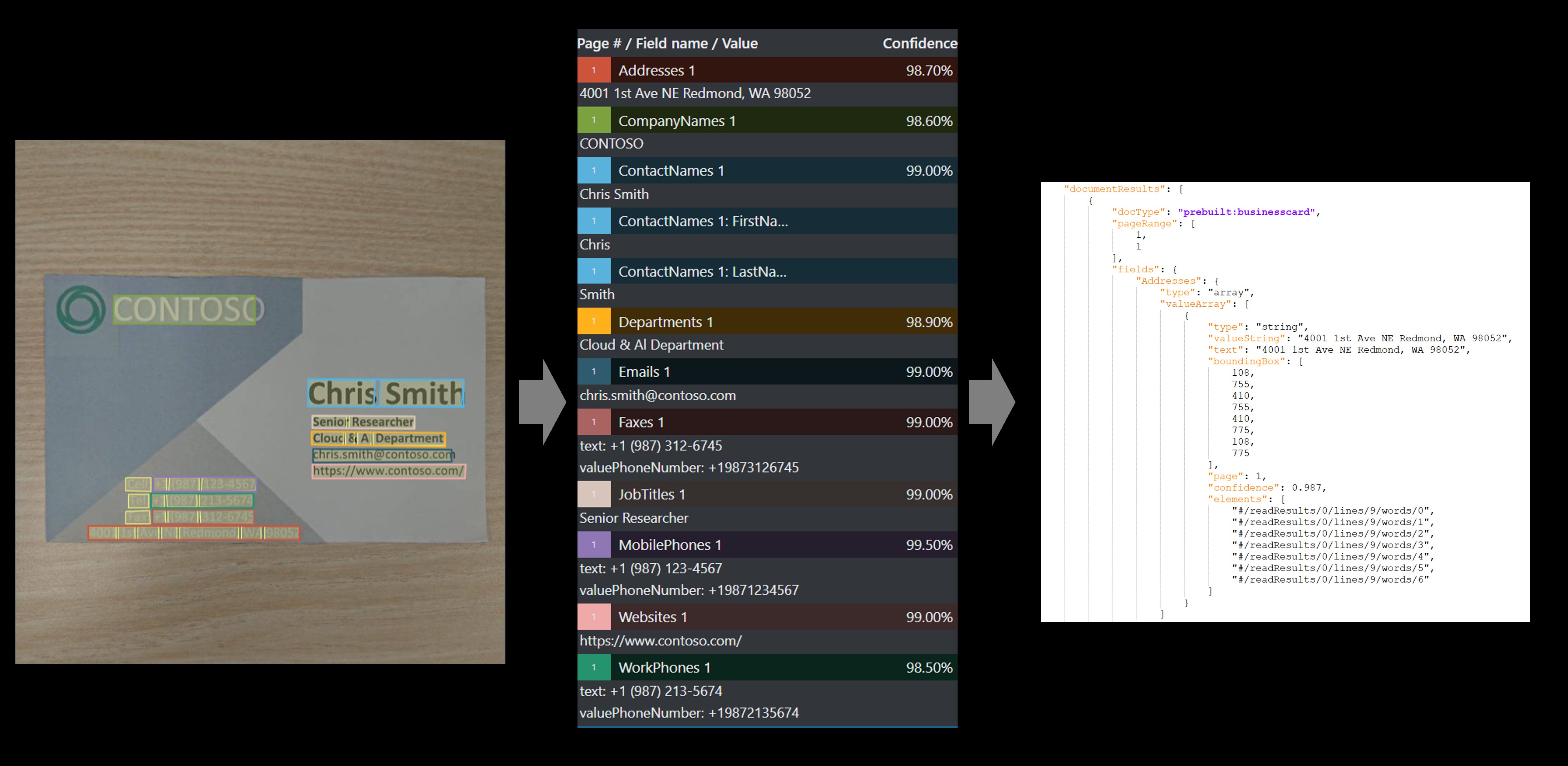
Carte de visite
Le modèle de carte de visite analyse et extrait des informations clés à partir d’images de carte de visite.
Exemple de carte de visite traitée avec l’outil d’étiquetage d’échantillon :
Custom
- Les modèles personnalisés analysent et extraient les données de formulaires et de documents spécifiques à votre entreprise. L’API est un programme de Machine Learning entraîné à reconnaître les champs de formulaire dans vos contenus spécifiques et à extraire des paires clé-valeur et des données de table. Vous avez seulement besoin de cinq exemples du même type de formulaire pour commencer. L’apprentissage de votre modèle personnalisé peut s’effectuer avec ou sans jeux de données étiquetés.
Exemple de modèle personnalisé traité avec l’outil d’étiquetage d’échantillon :
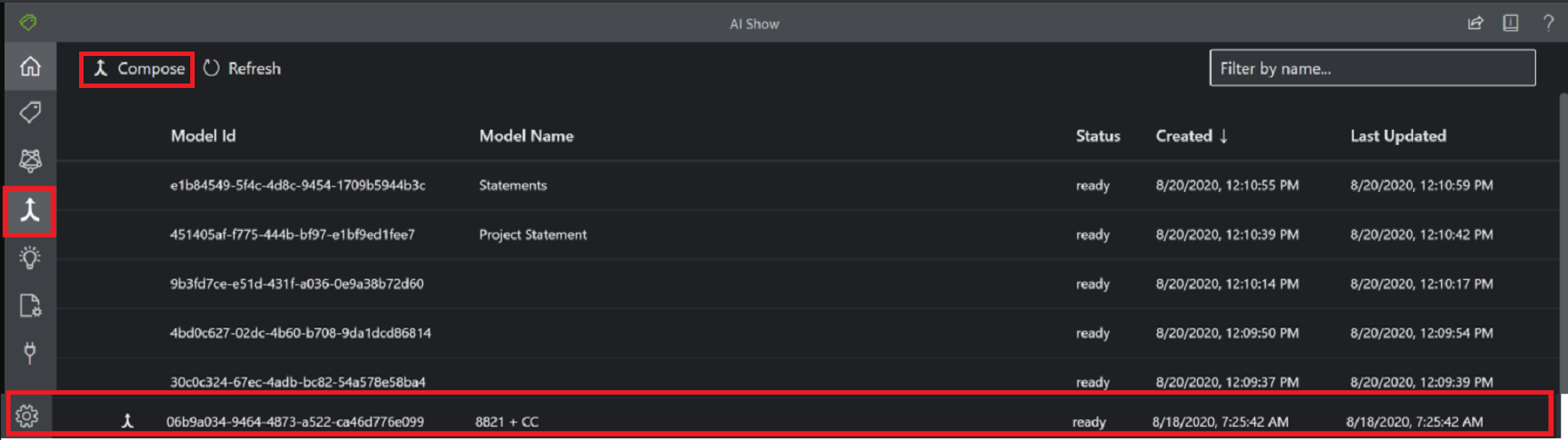
Modèle personnalisé composé
Pour créer un modèle composé, vous associez une collection de modèles personnalisés à un modèle unique créé à partir de vos types de formulaire. Il est possible d’affecter plusieurs modèles personnalisés à un modèle composé qui est appelé avec un ID de modèle unique. Il est possible d’attribuer jusqu’à 100 modèles personnalisés entraînés à un même modèle composé.
Fenêtre de boîte de dialogue de modèle composé avec l’outil d’étiquetage d’échantillon :
Extraction de données de modèle
| Modèle | Extraction de texte | Détection de la langue | Marques de sélection | Tables | Paragraphes | Rôles de paragraphe | Paires clé-valeur | Fields |
|---|---|---|---|---|---|---|---|---|
| Disposition | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Facture | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Réception | ✓ | ✓ | ✓ | |||||
| Document d’ID | ✓ | ✓ | ✓ | |||||
| Carte de visite | ✓ | ✓ | ✓ | |||||
| Formulaire personnalisé | ✓ | ✓ | ✓ | ✓ | ✓ |
Critères des entrées
Formats de fichiers pris en charge :
Modèle PDF Image : JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office :
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLire ✔ ✔ ✔ Layout ✔ ✔ ✔ Document général ✔ ✔ Prédéfinie ✔ ✔ Extraction personnalisée ✔ ✔ Classification personnalisée ✔ ✔ ✔ Pour de meilleurs résultats, fournissez une photo nette ou une copie de qualité par document.
Pour les PDF et TIFF, jusqu'à 2 000 pages peuvent être traitées (avec un abonnement gratuit, seules les deux premières pages sont traitées).
La taille de fichier pour l’analyse de documents est de 500 Mo pour le niveau payant (S0) et de
4Mo pour le niveau gratuit (F0).Les dimensions de l’image doivent être comprises entre 50 pixels x 50 pixels et 10 000 pixels x 10 000 pixels.
Si vos fichiers PDF sont verrouillés par mot de passe, vous devez supprimer le verrou avant leur envoi.
La hauteur minimale du texte à extraire est de 12 pixels pour une image de 1024 x 768 pixels. Cette dimension correspond environ à un texte de
8points à 150 points par pouce (ppp).Pour la formation de modèles personnalisés, le nombre maximal de pages pour les données de formation est de 500 pour le modèle personnalisé et 50 000 pour le modèle neural personnalisé.
Pour l’apprentissage du modèle d’extraction personnalisé, la taille totale des données d’entraînement est de 50 Mo pour le modèle de gabarit et de
1Go pour le modèle neuronal.Pour l’apprentissage du modèle de classification personnalisé, la taille totale des données d’entraînement est de
1Go, avec un maximum de 10 000 pages. Pour 2024-11-30 (GA), la taille totale des données d’entraînement est de2Go, avec un maximum de 10 000 pages.
Remarque
L’outil d’étiquetage des exemples ne prend pas en charge le format de fichier BMP. Il s’agit d’une limite de l’outil et non du service d’Intelligence documentaire.
Migration de version
Vous découvrirez comment utiliser Intelligence documentaire v3.0 dans vos applications en suivant notre guide de migration Intelligence documentaire v3.1
Étapes suivantes
Essayez de traiter vos propres formulaires et documents avec Document Intelligence Studio.
Effectuez un démarrage rapide Intelligence Documentaire et commencez à créer une application de traitement de documents dans le langage de développement de votre choix.
Essayez de traiter vos propres formulaires et documents avec l’outil d’étiquetage d’échantillons Intelligence Documentaire.
Effectuez un démarrage rapide Intelligence Documentaire et commencez à créer une application de traitement de documents dans le langage de développement de votre choix.