Modèle de disposition d’Intelligence documentaire
Ce contenu s’applique à : ![]() v4.0 (GA) | Versions précédentes :
v4.0 (GA) | Versions précédentes : ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1 (GA)
v2.1 (GA)
Le modèle de disposition d’Intelligence documentaire est une API avancée d’analyse de documents basée sur le machine learning, qui est disponible dans le cloud Intelligence documentaire. Elle vous permet de prendre des documents dans différents formats et de retourner des représentations de données structurées des documents. Elle combine une version améliorée de nos puissantes capacités de reconnaissance optique de caractères (OCR) avec des modèles de deep learning (apprentissage approfondi) pour extraire du texte, des tableaux, des marques de sélection et la structure du document.
Analyse de la disposition de documents (v4)
L’analyse de la disposition structurelle d’un document est le processus consistant à analyser un document pour en extraire les parties intéressantes et leurs interrelations. L’objectif est d’extraire le texte et les éléments structurels de la page pour créer de meilleurs modèles de compréhension sémantique. Il existe deux types de rôles dans une mise en page de document :
- Rôles géométriques : Le texte, les tableaux, les figures et les marques de sélection sont des exemples de rôles géométriques.
- Rôles logiques : Les titres, les en-têtes et les pieds de page sont des exemples de rôles logiques des textes.
L’illustration suivante montre les composants typiques dans une image d’un exemple de page.

Options de développement (v4)
Intelligence documentaire v4.0 : 2024-11-30 (GA) prend en charge les outils, applications et bibliothèques suivants :
| Fonctionnalité | Ressources | ID de modèle |
|---|---|---|
| Modèle de disposition | • Document Intelligence Studio • API REST • Kit de développement logiciel (SDK) C# • Kit de développement logiciel (SDK) Python • Kit de développement logiciel (SDK) Java • Kit de développement logiciel (SDK) JavaScript |
prebuilt-layout |
Exigences relatives aux entrées (v4)
Formats de fichiers pris en charge :
Modèle PDF Image : JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office :
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLire ✔ ✔ ✔ Layout ✔ ✔ ✔ Document général ✔ ✔ Prédéfinie ✔ ✔ Extraction personnalisée ✔ ✔ Classification personnalisée ✔ ✔ ✔ Pour de meilleurs résultats, fournissez une photo nette ou une copie de qualité par document.
Pour les PDF et TIFF, jusqu'à 2 000 pages peuvent être traitées (avec un abonnement gratuit, seules les deux premières pages sont traitées).
La taille de fichier pour l’analyse de documents est de 500 Mo pour le niveau payant (S0) et de
4Mo pour le niveau gratuit (F0).Les dimensions de l’image doivent être comprises entre 50 pixels x 50 pixels et 10 000 pixels x 10 000 pixels.
Si vos fichiers PDF sont verrouillés par mot de passe, vous devez supprimer le verrou avant leur envoi.
La hauteur minimale du texte à extraire est de 12 pixels pour une image de 1024 x 768 pixels. Cette dimension correspond environ à un texte de
8points à 150 points par pouce (ppp).Pour la formation de modèles personnalisés, le nombre maximal de pages pour les données de formation est de 500 pour le modèle personnalisé et 50 000 pour le modèle neural personnalisé.
Pour l’apprentissage du modèle d’extraction personnalisé, la taille totale des données d’entraînement est de 50 Mo pour le modèle de gabarit et de
1Go pour le modèle neuronal.Pour l’apprentissage du modèle de classification personnalisé, la taille totale des données d’entraînement est de
1Go, avec un maximum de 10 000 pages. Pour 2024-11-30 (GA), la taille totale des données d’entraînement est de2Go avec un maximum de 10 000 pages.
Bien démarrer avec le modèle de disposition
Découvrez comment les données, y compris le texte, les tableaux, les en-têtes de tableau, les marques de sélection et les informations de structure, sont extraites des documents avec Intelligence documentaire. Vous avez besoin des ressources suivantes :
Un abonnement Azure. Vous pouvez en créer un gratuitement.
Instance Intelligence documentaire dans le Portail Azure. Vous pouvez utiliser le niveau tarifaire gratuit (
F0) pour tester le service. Une fois votre ressource déployée, sélectionnez Accéder à la ressource pour accéder à la clé et au point de terminaison.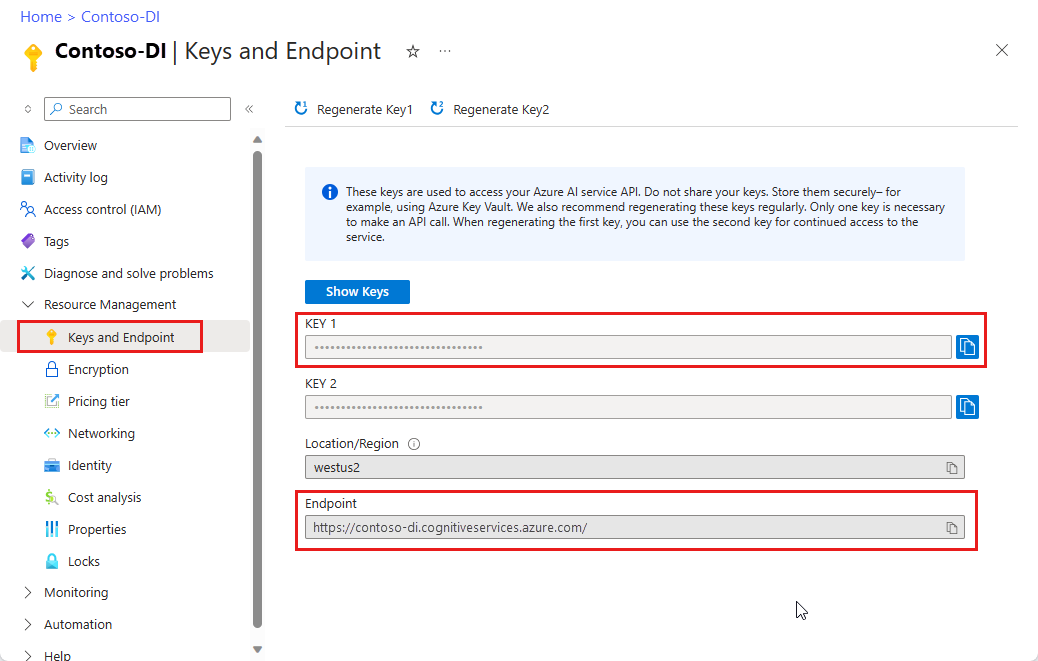
Remarque
Document Intelligence Studio est disponible avec les API v3.0 et versions ultérieures.
Exemple de document traité avec Intelligence documentaire Studio

Dans la page d’accueil Document Intelligence Studio, sélectionnez disposition.
Vous pouvez analyser l’exemple de document ou charger vos propres fichiers.
Sélectionnez le bouton Exécuter l’analyse et, si nécessaire, configurez les Options d’analyse :

Langues prises en charge
Consultez notre page Support linguistique - modèles d'analyse documentaire pour une liste complète des langues prises en charge.
Extraction de données (v4)
Le modèle de disposition extrait du texte, des marques de sélection, des tableaux, des paragraphes et des types de paragraphes (roles) à partir de vos documents.
Remarque
Intelligence documentaire v4.0 (2024-11-30 (GA)) et ses versions ultérieures prennent en charge les fichiers Microsoft Office (DOCX, XLSX, PPTX) et HTML. Les fonctionnalités suivantes ne sont pas prises en charge :
- Il n’existe aucun angle, largeur/hauteur et unité avec chaque objet de page.
- Pour chaque objet détecté, il n’existe aucun polygone englobant ni région englobante.
- La plage de pages (
pages) n’est pas prise en charge en tant que paramètre. - Aucun objet
lines.
Pages
La collection de pages est une liste de pages dans le document. Chaque page est représentée séquentiellement dans le document et inclut l’angle d’orientation qui indique si la page est tournée ainsi que la largeur et la hauteur (dimensions en pixels). Les unités de page dans la sortie du modèle sont calculées comme indiqué :
| Format de fichier | Unité de page calculée | Nombre total de pages |
|---|---|---|
| Images (JPEG/JPG, PNG, BMP, HEIF) | Chaque image = 1 unité de page | Nombre total d'images |
| Chaque page du PDF = 1 unité de page | Nombre total de pages dans le fichier PDF | |
| TIFF | Chaque image dans le fichier TIFF = 1 unité de page | Nombre total d’images dans le fichier TIFF |
| Word (DOCX) | Jusqu’à 3 000 caractères = 1 unité de page, images incorporées ou liées non prises en charge | Nombre total de pages allant jusqu’à 3 000 caractères chacune |
| Excel (XLSX) | Chaque feuille de calcul = 1 unité de page, images incorporées ou liées non prises en charge | Nombre total de feuilles de calcul |
| PowerPoint (PPTX) | Chaque diapositive = 1 unité de page, images incorporées ou liées non prises en charge | Nombre total de diapositives |
| HTML | Jusqu’à 3 000 caractères = 1 unité de page, images incorporées ou liées non prises en charge | Nombre total de pages allant jusqu’à 3 000 caractères chacune |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Extraire les pages sélectionnées à partir de documents
Pour les documents volumineux comportant plusieurs pages, utilisez le paramètre de requête pages pour indiquer des numéros de page ou des plages de pages spécifiques pour l’extraction de texte.
Paragraphes
Le modèle de disposition extrait tous les blocs de texte identifiés dans la collection paragraphs en tant qu’objet de niveau supérieur sous analyzeResults. Chaque entrée de cette collection représente un bloc de texte et inclut le texte extrait en tant que content et les coordonnées polygon limitrophes. Les informations span pointent vers le fragment de texte dans la propriété content de niveau supérieur qui contient le texte intégral du document.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Rôles de paragraphe
La nouvelle détection d’objet de page basée sur l’apprentissage automatique extrait les rôles logiques tels que les titres, les en-têtes de section, les en-têtes de page, les pieds de page, etc. Le modèle de disposition d’Intelligence documentaire affecte certains blocs de texte de la collection paragraphs avec leur rôle ou type spécialisé prédit par le modèle. Il est préférable d’utiliser les rôles de paragraphe avec des documents non structurés pour mieux comprendre la disposition du contenu extrait pour une analyse sémantique plus riche. Les rôles de paragraphe suivants sont pris en charge :
| Rôle prédit | Description | Types de fichiers pris en charge |
|---|---|---|
title |
Les titres principaux de la page | pdf, image, docx, pptx, xlsx, html |
sectionHeading |
Un ou plusieurs sous-titres sur la page | pdf, image, docx, xlsx, html |
footnote |
Texte près du bas de la page | pdf, image |
pageHeader |
Texte près du bord supérieur de la page | pdf, image, docx |
pageFooter |
Texte près du bord inférieur de la page | pdf, image, docx, pptx, html |
pageNumber |
Nombre de pages | pdf, image |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Texte, lignes et mots
Le modèle de disposition de documents dans Intelligence documentaire extrait le texte de style imprimé et manuscrit en tant que lines et words. La collection styles inclut tout style manuscrit détecté pour les lignes ainsi que les étendues pointant vers le texte associé. Cette fonctionnalité s’applique aux langues manuscrites prises en charge.
Pour Microsoft Word, Excel, PowerPoint et HTML, Intelligence documentaire v4.0 2024-11-30 (GA), le modèle de disposition extrait tout le texte incorporé tel quel. Les textes sont extraits sous forme de mots et de paragraphes. Les images incorporées ne sont pas prises en charge.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Style manuscrit des lignes de texte
La réponse inclut le classement de chaque ligne de texte selon qu’elle est de style manuscrit ou non, avec un score de confiance. Pour plus d'informations, consultez Consultez Prise en charge des langues manuscrites. L’exemple suivant montre un exemple d’extrait JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Si vous activez la fonctionnalité de complément de police/style, vous obtenez également le résultat de police/style dans le cadre de l’objet styles.
Marques de sélection
Le modèle de disposition extrait aussi les marques de sélection des documents. Les marques de sélection extraites apparaissent dans la collection pages pour chaque page. Elles incluent le polygon limitrophe, confidence et la sélection state (selected/unselected). La représentation sous forme de texte (autrement dit, :selected: et :unselected) est également incluse comme index de départ (offset) et length qui référence la propriété content de niveau supérieur contenant le texte intégral du document.
# Analyze selection marks.
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
Tables
L’extraction de tableaux est une condition essentielle pour le traitement de documents contenant de grands volumes de données généralement mis en forme en tant que tableaux. Le modèle de disposition extrait des tableaux dans la section pageResults de la sortie JSON. Les informations extraites d’un tableau comprennent le nombre de colonnes et de lignes, l’étendue des lignes et l’étendue des colonnes. Chaque cellule avec son polygone limitrophe est une sortie avec des informations que la zone soit reconnue comme un columnHeader ou non. Le modèle prend en charge l’extraction de tableaux pivotés. Chaque cellule de tableau contient l’index de ligne et de colonne et les coordonnées du polygone limitrophe. Pour le texte de cellule, le modèle génère les informations span contenant l’index de démarrage (offset). Le modèle génère également la length du contenu supérieur qui contient le texte intégral du document.
Voici quelques facteurs à prendre en compte lors de l’utilisation de la fonctionnalité d’extraction de balles Intelligence documentaire :
Les données que vous voulez extraire sont-elles présentées sous forme de tableau ? La structure du tableau est-elle significative ?
Si les données ne sont pas au format tableau, peuvent-elles être contenues dans une grille à deux dimensions ?
Vos tableaux s’étendent-ils sur plusieurs pages ? Si tel est le cas, pour éviter d’avoir à étiqueter toutes les pages, divisez le PDF en pages avant de l’envoyer à Intelligence documentaire. Après l’analyse, effectuez un post-traitement des pages dans un tableau unique.
Reportez-vous à champs tabulaires si vous créez des modèles personnalisés. Les tableaux dynamiques contiennent un nombre variable de lignes pour chaque colonne. Les tableaux fixes, eux, contiennent un nombre constant de lignes pour chaque colonne.
Remarque
- L’analyse de table n’est pas prise en charge si le fichier d’entrée est XLSX.
- Pour 2024-11-30 (GA), les zones englobantes pour les figures et les tableaux couvrent seulement le contenu principal, et excluent les légendes et les notes de bas de page associées.
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
# Analyze cells.
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
Sortie au format markdown
L’API Layout peut générer le texte extrait au format Markdown. Utilisez le outputContentFormat=markdown pour spécifier le format de sortie en Markdown. Le contenu markdown est généré dans le cadre de la section content.
Remarque
Pour v4.0 2024-11-30 (GA), la représentation des tableaux est changée en tableaux HTML pour permettre le rendu des cellules fusionnées, des en-têtes multilignes, etc. Une autre modification associée consiste à utiliser des caractères ☒ de case à cocher Unicode et ☐ à des marques de sélection au lieu de :selected : et :unselected :. Notez que cela signifie que le contenu des champs de marque de sélection contient :selected: même si leurs étendues font référence aux caractères Unicode dans l’étendue de niveau supérieur.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
Figures
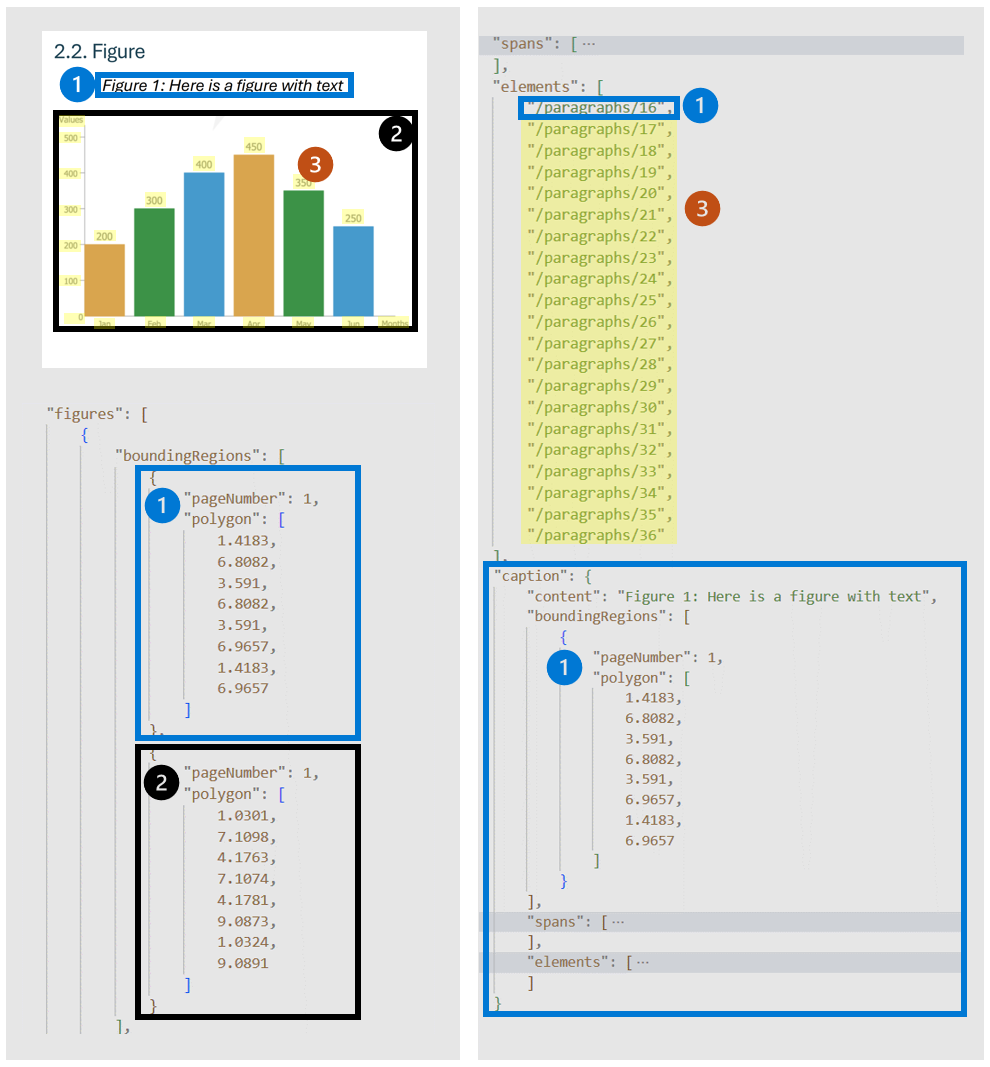
Les figures (graphiques, images) dans les documents jouent un rôle crucial dans le complément et l’amélioration du contenu textuel, fournissant des représentations visuelles qui aident à comprendre les informations complexes. L’objet figures détecté par le Modèle de disposition possède des propriétés clés telles que boundingRegions (les emplacements spatiaux de la figure sur les pages du document, y compris le numéro de page et les coordonnées de polygone qui définissent les limites de la figure), spans (détaille les étendues de texte liées à la figure, en spécifiant leurs décalages et longueurs dans le texte du document. Cette connexion permet d’associer la figure à son contexte textuel pertinent), elements (identificateurs pour les éléments de texte ou les paragraphes du document qui sont liés ou décrivent la figure) et caption le cas échéant.
Lorsque output=figures est spécifiée lors de l’opération d’analyse initiale, le service génère des images rognées pour toutes les figures détectées accessibles via /analyeResults/{resultId}/figures/{figureId}.
FigureId est inclus dans chaque objet figure, suivant une convention non documentée de {pageNumber}.{figureIndex} où figureIndex réinitialise à une par page.
Remarque
Pour v4.0 2024-11-30 (GA), les zones englobantes pour les figures et les tableaux couvrent seulement le contenu principal, et excluent les légendes et les notes de bas de page associées.
# Analyze figures.
if result.figures:
for figures_idx,figures in enumerate(result.figures):
print(f"Figure # {figures_idx} has the following spans:{figures.spans}")
for region in figures.bounding_regions:
print(f"Figure # {figures_idx} location on page:{region.page_number} is within bounding polygon '{region.polygon}'")
Sections
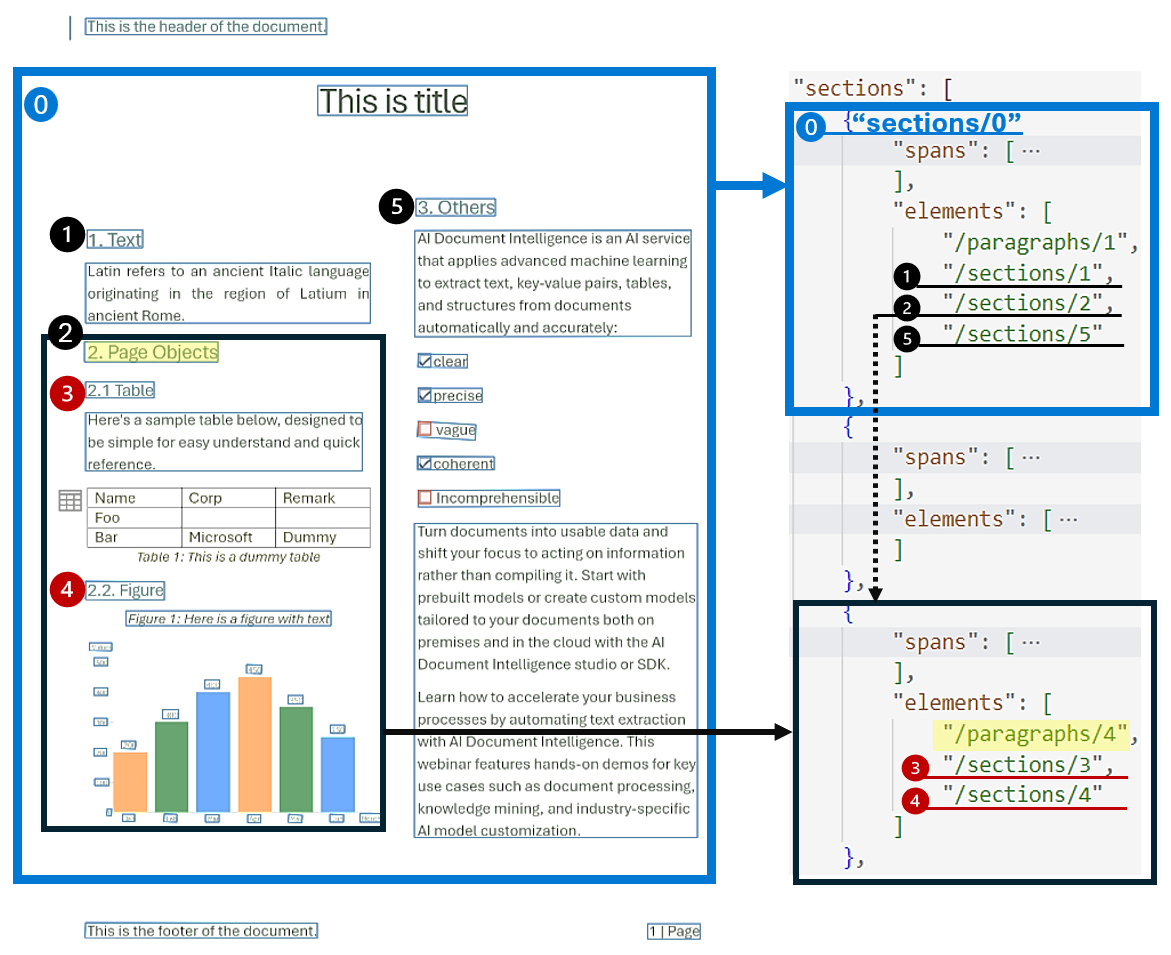
L’analyse hiérarchique de la structure des documents est essentielle pour organiser, comprendre et traiter des documents étendus. Cette approche est essentielle pour segmenter sémantiquement des documents longs afin d’améliorer la compréhension, de faciliter la navigation et d’améliorer la récupération des informations. L’avènement de la génération augmentée de récupération (RAG) dans l’IA générative de document souligne l’importance de l’analyse hiérarchique de la structure de document. Le Modèle de disposition prend en charge les sections et sous-sections de la sortie, qui identifie la relation des sections et des objets dans chaque section. La structure hiérarchique est conservée dans elements de chaque section. Vous pouvez utiliser la sortie au format markdown pour obtenir facilement les sections et sous-sections en markdown.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
Ce contenu s’applique à : ![]() v3.1 (GA) | Dernière version :
v3.1 (GA) | Dernière version : ![]() v4.0 (GA) | Versions précédentes :
v4.0 (GA) | Versions précédentes : ![]() v3.0
v3.0 ![]() v2.1
v2.1
Ce contenu s’applique à : ![]() v3.0 (GA) | Dernières versions :
v3.0 (GA) | Dernières versions : ![]() v4.0 (GA)
v4.0 (GA) ![]() v3.1 | Version précédente :
v3.1 | Version précédente : ![]() v2.1
v2.1
Ce contenu s’applique à : ![]() v2.1 | Dernière version :
v2.1 | Dernière version : ![]() v4.0 (GA)
v4.0 (GA)
Le modèle de disposition d’Intelligence documentaire est une API avancée d’analyse de documents basée sur le machine learning, qui est disponible dans le cloud Intelligence documentaire. Elle vous permet de prendre des documents dans différents formats et de retourner des représentations de données structurées des documents. Elle combine une version améliorée de nos puissantes capacités de reconnaissance optique de caractères (OCR) avec des modèles de deep learning (apprentissage approfondi) pour extraire du texte, des tableaux, des marques de sélection et la structure du document.
Analyse de la disposition de documents
L’analyse de la disposition structurelle d’un document est le processus consistant à analyser un document pour en extraire les parties intéressantes et leurs interrelations. L’objectif est d’extraire le texte et les éléments structurels de la page pour créer de meilleurs modèles de compréhension sémantique. Il existe deux types de rôles dans une mise en page de document :
- Rôles géométriques : Le texte, les tableaux, les figures et les marques de sélection sont des exemples de rôles géométriques.
- Rôles logiques : Les titres, les en-têtes et les pieds de page sont des exemples de rôles logiques des textes.
L’illustration suivante montre les composants typiques dans une image d’un exemple de page.
Options de développement
Document Intelligence v3.1 prend en charge les outils, applications et bibliothèques suivants :
| Fonction | Ressources | ID de modèle |
|---|---|---|
| Modèle de disposition | • Document Intelligence Studio • API REST • Kit de développement logiciel (SDK) C# • Kit de développement logiciel (SDK) Python • Kit de développement logiciel (SDK) Java • Kit de développement logiciel (SDK) JavaScript |
prebuilt-layout |
Intelligence documentaire v3.0 prend en charge les outils, applications et bibliothèques suivants :
| Fonction | Ressources | ID de modèle |
|---|---|---|
| Modèle de disposition | • Document Intelligence Studio • API REST • Kit de développement logiciel (SDK) C# • Kit de développement logiciel (SDK) Python • Kit de développement logiciel (SDK) Java • Kit de développement logiciel (SDK) JavaScript |
prebuilt-layout |
Intelligence documentaire v2.1 prend en charge les outils, applications et bibliothèques suivants :
| Fonction | Ressources |
|---|---|
| Modèle de disposition | ● Outil d’étiquetage Intelligence Documentaire • API REST • Kit de développement logiciel (SDK) Bibliothèque client • Intelligence Documentaire Conteneur Docker |
Critères des entrées
Formats de fichiers pris en charge :
Modèle PDF Image : JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office :
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLire ✔ ✔ ✔ Layout ✔ ✔ ✔ Document général ✔ ✔ Prédéfinie ✔ ✔ Extraction personnalisée ✔ ✔ Classification personnalisée ✔ ✔ ✔ Pour de meilleurs résultats, fournissez une photo nette ou une copie de qualité par document.
Pour les PDF et TIFF, jusqu'à 2 000 pages peuvent être traitées (avec un abonnement gratuit, seules les deux premières pages sont traitées).
La taille de fichier pour l’analyse de documents est de 500 Mo pour le niveau payant (S0) et de
4Mo pour le niveau gratuit (F0).Les dimensions de l’image doivent être comprises entre 50 pixels x 50 pixels et 10 000 pixels x 10 000 pixels.
Si vos fichiers PDF sont verrouillés par mot de passe, vous devez supprimer le verrou avant leur envoi.
La hauteur minimale du texte à extraire est de 12 pixels pour une image de 1024 x 768 pixels. Cette dimension correspond environ à un texte de
8points à 150 points par pouce (ppp).Pour la formation de modèles personnalisés, le nombre maximal de pages pour les données de formation est de 500 pour le modèle personnalisé et 50 000 pour le modèle neural personnalisé.
Pour l’apprentissage du modèle d’extraction personnalisé, la taille totale des données d’entraînement est de 50 Mo pour le modèle de gabarit et de
1Go pour le modèle neuronal.Pour l’apprentissage du modèle de classification personnalisé, la taille totale des données d’entraînement est de
1Go, avec un maximum de 10 000 pages. Pour 2024-11-30 (GA), la taille totale des données d’entraînement est de2Go avec un maximum de 10 000 pages.
- Formats de fichiers pris en charge : JPEG, PNG, PDF et TIFF.
- Nombre de pages pris en charge : pour PDF et TIFF, jusqu’à 2 000 pages sont traitées. Abonnés du niveau Gratuit : seules les deux premières pages sont traitées.
- Taille de fichier prise en charge : La taille de fichier doit être inférieure à 50 Mo, et les dimensions comprises entre 50 × 50 pixels et 10 000 × 10 000 pixels.
Bien démarrer avec le modèle de disposition
Découvrez comment les données, y compris le texte, les tableaux, les en-têtes de tableau, les marques de sélection et les informations de structure, sont extraites des documents avec Intelligence documentaire. Vous avez besoin des ressources suivantes :
Un abonnement Azure. Vous pouvez en créer un gratuitement.
Instance Intelligence documentaire dans le Portail Azure. Vous pouvez utiliser le niveau tarifaire gratuit (
F0) pour tester le service. Une fois votre ressource déployée, sélectionnez Accéder à la ressource pour accéder à la clé et au point de terminaison.
Remarque
Document Intelligence Studio est disponible avec les API v3.0 et versions ultérieures.
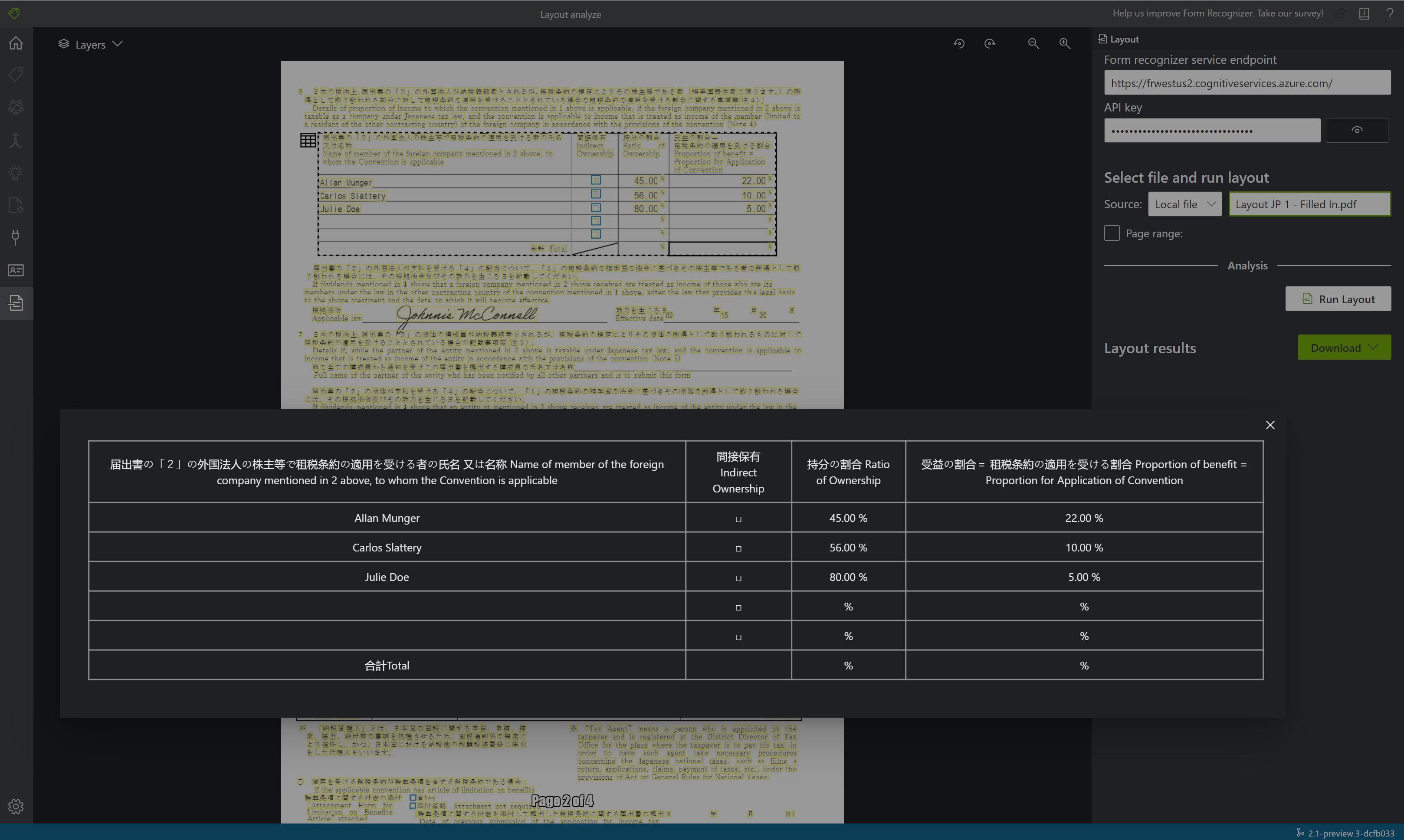
Exemple de document traité avec Intelligence documentaire Studio
Dans la page d’accueil Document Intelligence Studio, sélectionnez disposition.
Vous pouvez analyser l’exemple de document ou charger vos propres fichiers.
Sélectionnez le bouton Exécuter l’analyse et, si nécessaire, configurez les Options d’analyse :
Outil d’étiquetage d’exemples d’Intelligence documentaire
Dans la page d’accueil de l’outil d’étiquetage des exemples, sélectionnez Utiliser Disposition pour obtenir du texte, des tableaux et des marques de sélection.
Dans le champ Point de terminaison du service Document Intelligence, collez le point de terminaison que vous avez obtenu avec votre abonnement Document Intelligence.
Dans le champ Clé, collez la clé que vous avez obtenue de votre ressource Document Intelligence.
Dans le champ Source, sélectionnez URL dans le menu déroulant Vous pouvez utiliser notre exemple de document :
Sélectionnez le bouton Extraire.
Sélectionnez Exécuter la requête. L’Outil d’étiquetage des exemples d’Intelligence documentaire appelle l’API
Analyze Layoutet analyse le document.
Afficher les résultats : consultez le texte extrait mis en évidence, les marques de sélection détectées et les tableaux détectés.
{kind=link}
Langues et régions prises en charge
Consultez notre page Support linguistique - modèles d'analyse documentaire pour une liste complète des langues prises en charge.
Intelligence documentaire v2.1 prend en charge les outils, applications et bibliothèques suivants :
| Fonction | Ressources |
|---|---|
| API de disposition | ● Outil d’étiquetage Intelligence Documentaire • API REST • Kit de développement logiciel (SDK) Bibliothèque client • Intelligence Documentaire Conteneur Docker |
Extraction de données
Le modèle de disposition extrait du texte, des marques de sélection, des tableaux, des paragraphes et des types de paragraphes (roles) à partir de vos documents.
Remarque
Intelligence documentaire v4.0 2024-11-30 (GA) prend en charge les fichiers Microsoft Office (DOCX, XLSX, PPTX) et HTML. Les fonctionnalités suivantes ne sont pas prises en charge :
- Il n’existe aucun angle, largeur/hauteur et unité avec chaque objet de page.
- Pour chaque objet détecté, il n’existe aucun polygone englobant ni région englobante.
- La plage de pages (
pages) n’est pas prise en charge en tant que paramètre. - Aucun objet
lines.
Pages
La collection de pages est une liste de pages dans le document. Chaque page est représentée séquentiellement dans le document et inclut l’angle d’orientation qui indique si la page est tournée ainsi que la largeur et la hauteur (dimensions en pixels). Les unités de page dans la sortie du modèle sont calculées comme indiqué :
| Format de fichier | Unité de page calculée | Nombre total de pages |
|---|---|---|
| Images (JPEG/JPG, PNG, BMP, HEIF) | Chaque image = 1 unité de page | Nombre total d'images |
| Chaque page du PDF = 1 unité de page | Nombre total de pages dans le fichier PDF | |
| TIFF | Chaque image dans le fichier TIFF = 1 unité de page | Nombre total d’images dans le fichier TIFF |
| Word (DOCX) | Jusqu’à 3 000 caractères = 1 unité de page, images incorporées ou liées non prises en charge | Nombre total de pages allant jusqu’à 3 000 caractères chacune |
| Excel (XLSX) | Chaque feuille de calcul = 1 unité de page, images incorporées ou liées non prises en charge | Nombre total de feuilles de calcul |
| PowerPoint (PPTX) | Chaque diapositive = 1 unité de page, images incorporées ou liées non prises en charge | Nombre total de diapositives |
| HTML | Jusqu’à 3 000 caractères = 1 unité de page, images incorporées ou liées non prises en charge | Nombre total de pages allant jusqu’à 3 000 caractères chacune |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Extraire les pages sélectionnées à partir de documents
Pour les documents volumineux comportant plusieurs pages, utilisez le paramètre de requête pages pour indiquer des numéros de page ou des plages de pages spécifiques pour l’extraction de texte.
Paragraphes
Le modèle de disposition extrait tous les blocs de texte identifiés dans la collection paragraphs en tant qu’objet de niveau supérieur sous analyzeResults. Chaque entrée de cette collection représente un bloc de texte et inclut le texte extrait en tant que content et les coordonnées polygon limitrophes. Les informations span pointent vers le fragment de texte dans la propriété content de niveau supérieur qui contient le texte intégral du document.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Rôles de paragraphe
La nouvelle détection d’objet de page basée sur l’apprentissage automatique extrait les rôles logiques tels que les titres, les en-têtes de section, les en-têtes de page, les pieds de page, etc. Le modèle de disposition d’Intelligence documentaire affecte certains blocs de texte de la collection paragraphs avec leur rôle ou type spécialisé prédit par le modèle. Il est préférable d’utiliser les rôles de paragraphe avec des documents non structurés pour mieux comprendre la disposition du contenu extrait pour une analyse sémantique plus riche. Les rôles de paragraphe suivants sont pris en charge :
| Rôle prédit | Description | Types de fichiers pris en charge |
|---|---|---|
title |
Les titres principaux de la page | pdf, image, docx, pptx, xlsx, html |
sectionHeading |
Un ou plusieurs sous-titres sur la page | pdf, image, docx, xlsx, html |
footnote |
Texte près du bas de la page | pdf, image |
pageHeader |
Texte près du bord supérieur de la page | pdf, image, docx |
pageFooter |
Texte près du bord inférieur de la page | pdf, image, docx, pptx, html |
pageNumber |
Nombre de pages | pdf, image |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Texte, lignes et mots
Le modèle de disposition de documents dans Intelligence documentaire extrait le texte de style imprimé et manuscrit en tant que lines et words. La collection styles inclut tout style manuscrit détecté pour les lignes ainsi que les étendues pointant vers le texte associé. Cette fonctionnalité s’applique aux langues manuscrites prises en charge.
Pour Microsoft Word, Excel, PowerPoint et HTML, Intelligence documentaire v4.0 2024-11-30 (GA), le modèle de disposition extrait tout le texte incorporé tel quel. Les textes sont extraits sous forme de mots et de paragraphes. Les images incorporées ne sont pas prises en charge.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Style manuscrit des lignes de texte
La réponse inclut le classement de chaque ligne de texte selon qu’elle est de style manuscrit ou non, avec un score de confiance. Pour plus d'informations, consultez Consultez Prise en charge des langues manuscrites. L’exemple suivant montre un exemple d’extrait JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Si vous activez la fonctionnalité de complément de police/style, vous obtenez également le résultat de police/style dans le cadre de l’objet styles.
Marques de sélection
Le modèle de disposition extrait aussi les marques de sélection des documents. Les marques de sélection extraites apparaissent dans la collection pages pour chaque page. Elles incluent le polygon limitrophe, confidence et la sélection state (selected/unselected). La représentation sous forme de texte (autrement dit, :selected: et :unselected) est également incluse comme index de départ (offset) et length qui référence la propriété content de niveau supérieur contenant le texte intégral du document.
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
# Analyze selection marks.
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
Tables
L’extraction de tableaux est une condition essentielle pour le traitement de documents contenant de grands volumes de données généralement mis en forme en tant que tableaux. Le modèle de disposition extrait des tableaux dans la section pageResults de la sortie JSON. Les informations extraites d’un tableau comprennent le nombre de colonnes et de lignes, l’étendue des lignes et l’étendue des colonnes. Chaque cellule avec son polygone limitrophe est une sortie avec des informations que la zone soit reconnue comme un columnHeader ou non. Le modèle prend en charge l’extraction de tableaux pivotés. Chaque cellule de tableau contient l’index de ligne et de colonne et les coordonnées du polygone limitrophe. Pour le texte de cellule, le modèle génère les informations span contenant l’index de démarrage (offset). Le modèle génère également la length du contenu supérieur qui contient le texte intégral du document.
Voici quelques facteurs à prendre en compte lors de l’utilisation de la fonctionnalité d’extraction de balles Intelligence documentaire :
Les données que vous voulez extraire sont-elles présentées sous forme de tableau ? La structure du tableau est-elle significative ?
Si les données ne sont pas au format tableau, peuvent-elles être contenues dans une grille à deux dimensions ?
Vos tableaux s’étendent-ils sur plusieurs pages ? Si tel est le cas, pour éviter d’avoir à étiqueter toutes les pages, divisez le PDF en pages avant de l’envoyer à Intelligence documentaire. Après l’analyse, effectuez un post-traitement des pages dans un tableau unique.
Reportez-vous à champs tabulaires si vous créez des modèles personnalisés. Les tableaux dynamiques contiennent un nombre variable de lignes pour chaque colonne. Les tableaux fixes, eux, contiennent un nombre constant de lignes pour chaque colonne.
Remarque
- L’analyse de table n’est pas prise en charge si le fichier d’entrée est XLSX.
- Intelligence documentaire v4.0 2024-11-30 (GA) prend en charge les zones englobantes pour les figures et les tableaux qui couvrent seulement le contenu principal, et qui excluent les légendes et les notes de bas de page associées.
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
# Analyze tables.
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
Annotations (disponibles uniquement dans l’API 2023-02-28-preview.)
Le modèle de disposition extrait les annotations dans les documents, telles que les vérifications et les croisements. La réponse inclut le genre d’annotation ainsi qu’un score de confiance et un polygone englobant.
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
Sortie de l’ordre de lecture naturel (langues latines uniquement)
Vous pouvez spécifier l’ordre dans lequel les lignes de texte sont générées avec le paramètre de requête readingOrder. Utilisez natural pour une sortie d’ordre de lecture plus conviviale, comme illustré dans l’exemple suivant. Cette fonctionnalité est prise en charge uniquement pour les langues latines.

Sélectionner des numéros de page ou des plages de pages pour l’extraction de texte
Pour les documents volumineux comportant plusieurs pages, utilisez le paramètre de requête pages pour indiquer des numéros de page ou des plages de pages spécifiques pour l’extraction de texte. L’exemple suivant montre un document de 10 pages, avec le texte extrait pour les deux cas : toutes les pages (1 à 10) et certaines pages (3 à 6).

Opération d’obtention du résultat de l’analyse de la disposition
La seconde étape consiste à appeler l’opération d’obtention du résultat de l’analyse de la disposition. Cette opération prend en entrée l’identifiant de résultat créé par l’opération Analyze Layout. Elle retourne une réponse JSON qui contient un champ État avec les possibles valeurs suivantes.
| Champ | Type | Valeurs possibles |
|---|---|---|
| status | string | notStarted : l’opération d’analyse n’a pas commencé.running : l’opération d’analyse est en cours.failed : échec de l’opération d’analyse.succeeded : l’opération d’analyse a réussi. |
Appelez cette opération de façon itérative jusqu’à ce qu’elle renvoie la valeur succeeded. Pour éviter de dépasser le taux de requêtes par seconde (RPS), utilisez un intervalle de trois à cinq secondes.
Quand le champ status a la valeur succeeded, la réponse JSON inclut la disposition, le texte, les tableaux et les marques de sélection extraits. Les données extraites comprennent les lignes de texte et les mots extraits, les cadres englobants, l’aspect du texte avec indication d’écriture manuscrite, les tableaux et les marques de sélection avec indication de sélection/non-sélection.
Classification manuscrite pour les lignes de texte (Latin uniquement)
La réponse inclut le classement de chaque ligne de texte selon qu’elle est de style manuscrit ou non, avec un score de confiance. Cette fonctionnalité est prise en charge uniquement pour les langues latines. L’exemple suivant illustre la classification manuscrite pour le texte de l’image.

Exemple de sortir JSON
La réponse à l’opération Get Analyze Layout Result est une représentation structurée du document avec toutes les informations extraites. Reportez-vous à cet exemple de fichier de document et cet exemple de sortie de disposition structurée.
La sortie JSON comporte deux parties :
- Le nœud
readResultscontient tout le texte reconnu et toutes les marques de sélection. La hiérarchie de présentation de texte est page, ligne, puis mots individuels. - Le nœud
pageResultscontient les tables et les cellules extraites avec leurs cadres englobants, le niveau de confiance et une référence aux lignes et aux mots dans le champ « readResults ».
Exemple de sortie
Texte
L’API de disposition extrait du texte des documents et des images avec plusieurs angles et couleurs de texte. Elle accepte les photos de documents, les télécopies, les textes imprimés et/ou manuscrits (en anglais uniquement) et les modes mixtes. Le texte est extrait avec des informations fournies sur les lignes, les mots, les cadres englobants, les scores de confiance et le style (manuscrit ou autre). Toutes les informations textuelles sont incluses dans la section readResults de la sortie JSON.
Tableaux avec en-têtes
L’API de disposition extrait des tableaux dans la section pageResults de la sortie JSON. Les documents peuvent être scannés, photographiés ou numériques. Les tableaux peuvent être complexes avec des cellules ou des colonnes fusionnées, avec ou sans bordures et avec des angles irréguliers. Les informations extraites d’un tableau comprennent le nombre de colonnes et de lignes, l’étendue des lignes et l’étendue des colonnes. Chaque cellule avec son cadre englobant est une sortie avec la zone qui est reconnue comme faisant partie, ou non, d’un en-tête. Les cellules d’en-tête prédites du modèle peuvent s’étendre sur plusieurs lignes et ne sont pas nécessairement les premières lignes d’un tableau. Elles fonctionnent également avec les tableaux pivotés. Chaque cellule de tableau comprend également le texte complet avec des références aux mots individuels dans la section readResults.

Marques de sélection
L’API de disposition extrait aussi les marques de sélection des documents. Les marques de sélection extraites incluent le cadre englobant, la confiance et l’état (sélectionné/non sélectionné). Les informations sur les marques de sélection sont extraites dans la section readResults de la sortie JSON.
Guide de migration
- Suivez le guide de migration Intelligence documentaire v3.1 pour apprendre à utiliser la version 3.1 dans vos applications et workflows.
Étapes suivantes
Découvrez comment traiter vos propres formulaires et documents avec Document Intelligence Studio.
Effectuez un démarrage rapide Intelligence Documentaire et commencez à créer une application de traitement de documents dans le langage de développement de votre choix.
Découvrez comment traiter vos propres formulaires et documents avec l’Outil d’étiquetage des exemples d’Intelligence documentaire.
Effectuez un démarrage rapide Intelligence Documentaire et commencez à créer une application de traitement de documents dans le langage de développement de votre choix.