Nouveautés d’Azure AI Intelligence documentaire
Ce contenu s’applique à : ![]() v4.0 (GA)
v4.0 (GA) ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1 (GA)
v2.1 (GA)
Le service Intelligence documentaire est mis à jour régulièrement. Ajoutez cette page aux favoris pour vous tenir informé des notes de publication, des améliorations apportées aux fonctionnalités et de la plus récente documentation.
Important
Les versions d’API en préversion sont mises hors service une fois l’API de disponibilité générale publiée. La version d’API 2023-02-28-preview va être mise hors service. Si vous utilisez toujours l’API en préversion ou les versions de Kit de développement logiciel (SDK) associées, veuillez mettre à jour votre code pour cibler la dernière version d’API 2024-11-30 (disponibilité générale).
Décembre 2024
Kits de développement logiciel (SDK) de langage de programmation Intelligence documentaire v4.0 sont désormais en disponibilité générale (GA) !
Les kits de développement logiciel (SDK) clients les plus récents sont par défaut associées à la version du service 2024-11-30 API REST (disponibilité générale).
Pour plus d’informations, consultez les bibliothèques clientes pour les langages de programmation pris en charge suivants :
Novembre 2024
L’API REST Intelligence documentaire v4.0 : 2024-11-30 API REST (disponibilité générale) est désormais en disponibilité ! L’API REST v4.0 inclut les modifications suivantes :
-
- L’API Batch prend désormais en charge tous les modèles, y compris tous les verticaux de lecture, de disposition et prédéfinis, et tous les modèles personnalisés.
- L’API Batch prend en charge la fonction LIST pour permettre aux utilisateurs de répertorier les travaux par lots au cours des sept derniers jours.
- L’API Batch prend en charge la fonction DELETE pour supprimer explicitement le travail par lot pour la conformité à la RGPD et vis-à-vis de la confidentialité.
- GetAnalyzeBatchResult prend en charge resultId en réponse à LIST (répertorier) tous les resultIds.
🆕 PDF consultable. Le modèle prédéfini de lecture prend désormais en charge les formats d’images (JPEG/JPG, PNG, BMP, TIFF, HEIF) et l’extension de langue pour inclure le chinois, le japonais et le coréen pour la sortie PDF.
Modèle de classification personnalisé
- Le modèle de classification personnalisé prend en charge l’entraînement incrémentiel. Vous pouvez ajouter de nouveaux échantillons aux classes existantes ou ajouter de nouvelles classes en référençant un classificateur existant.
- Avec v4.0, le modèle de classification personnalisé ne fractionne pas les documents par défaut pendant l’analyse. Vous devez définir explicitement la propriété « splitMode » pour conserver automatiquement l’ancien comportement.
- Le modèle de classification personnalisé prend désormais en charge 25 000 pages comme nouvelle limite de page d’entraînement.
-
- Le modèle neural personnalisé prend désormais en charge la détection de signature.
-
- Le modèle de relevé bancaire US prend désormais en charge l’extraction de tables de vérification.
-
- Prend en charge l’extraction de signature du payeur
Modèle de documents hypothécaires
- Le modèle hypothécaire prend désormais en charge la détection des signatures des formulaires 1003, 1004, 1005 et la déclaration de clôture.
-
- Le modèle de reçu prend désormais en charge d’autres champs, notamment ReceiptType, Tax Rate, CountryRegion, montant net et description.
-
- Nouveaux modèles fiscaux prédéfinis ajoutés pour 1095A, 1095C, 1099SSA et W4.
L’API v4.0 inclut des mises à jour cumulatives des versions préliminaires, comme indiqué ci-dessous :
Août 2024
L'API REST de Document Intelligence 2024-07-31-preview est désormais disponible. L’API de préversion introduit de nouvelles fonctionnalités mises à jour :
La version préliminaire publique 2024-07-31-preview est actuellement disponible uniquement dans les régions Azure suivantes. Le nouveau modèle d’extraction de champs de document dans le portail Azure AI Foundry est disponible seulement dans la région USA Centre Nord :
USA Est
USA Ouest 2
Europe Ouest
USA Centre Nord
🆕 Composition de modèles avec des classificateurs personnalisés
- Document Intelligence ajoute désormais la prise en charge de la composition d'un modèle avec un modèle de classification personnalisé explicite. En savoir plus sur les avantages de l’utilisation de la nouvelle fonctionnalité de composition.
Modèle de classification personnalisé
- Le modèle de classification personnalisé prend désormais également en charge la mise à jour du modèle sur place.
- Le modèle de classification personnalisé ajoute la prise en charge de l'opération de copie de modèle pour permettre la sauvegarde et la reprise après sinistre.
- Le modèle de classification personnalisé prend désormais en charge la spécification explicite des pages à classer à partir d'un document d'entrée.
🆕 Modèle de documents hypothécaires
- Extraire les informations de l’évaluation (formulaire 1004).
- Extraire les informations de la validation de l'emploi (formulaire 1005).
-
- Extraire le bénéficiaire, le montant, la date et d'autres informations pertinentes des chèques.
-
- Nouveau pré-configuré pour traiter les talons de paie afin d'extraire les salaires, les heures, les déductions, le salaire net et plus encore.
-
- Nouveau pré-intégré pour extraire les informations de compte, y compris les soldes de début et de fin, les détails des transactions à partir des relevés bancaires.
-
- Nouveau modèle fiscal américain unifié qui peut extraire des formulaires tels que W-2, 1098, 1099 et 1040.
🆕 PDF consultable. Le modèle de lecture prédéfini prend désormais en charge la sortie PDF pour télécharger des PDF avec du texte intégré à partir des résultats d'extraction, ce qui permet d'utiliser le PDF dans des scénarios tels que la recherche de copie de contenu.
Le modèle de mise en page prend désormais en charge une détection des figures améliorée, où les figures des documents peuvent désormais être téléchargées sous forme de fichier image à utiliser pour une meilleure compréhension des figures. Le modèle de mise en page présente également des améliorations du modèle OCR pour le ciblage du texte numérisé pour les caractères uniques, le texte encadré et les documents texte denses.
-
- Document Intelligence ajoute désormais la prise en charge de l'opération d'analyse par lots pour prendre en charge l'analyse d'un ensemble de documents afin de simplifier l'expérience du développeur et d'améliorer l'efficacité.
Fonctionnalités du module complémentaire
- La qualité d'extraction des champs de requête de l'IA est améliorée avec le dernier modèle.
Mai 2024
Document Intelligence Studio ajoute la prise en charge de l’authentification Microsoft Entra (anciennement Azure Active Directory). Pour plus d’informations, consultez Authentification dans Studio Intelligence documentaire.
Février 2024
L'API REST de Document Intelligence 2024-07-31-preview est désormais disponible. L’API de préversion introduit de nouvelles fonctionnalités mises à jour :
La version préliminaire publique 2024-07-31-preview est actuellement disponible uniquement dans les régions Azure suivantes :
- USA Est
- USA Ouest 2
- Europe Ouest
Le modèle de disposition prend désormais en charge la détection de figure et l’analyse hiérarchique de la structure des documents (sections et sous-sections). La qualité de l’ordre de lecture et de la détection des rôles logiques par l’IA est également améliorée.
Modèles d’extraction personnalisés
- Les modèles d’extraction personnalisés prennent désormais en charge les scores de confiance de cellule, de ligne et de table. En savoir plus sur la confiance de table, de ligne et de cellule.
- Les modèles d’extraction personnalisés ont des améliorations de la qualité de l’IA pour l’extraction de champs.
- Le modèle d’extraction de modèle personnalisé prend désormais en charge l’extraction de champs qui se chevauchent. En savoir plus sur les champs qui se chevauchent et leur utilisation.
Modèle de classification personnalisé
- Le modèle de classification personnalisé prend désormais en charge la formation incrémentielle pour les scénarios dans lesquels vous devez mettre à jour le modèle classifieur avec des échantillons ou des classes supplémentaires. En savoir plus sur la formation incrémentielle.
- Le modèle de classification personnalisé ajoute la prise en charge des types de documents Office (.docx, .pptx et .xls). En savoir plus sur la prise en charge des types de documents développés.
-
- Prise en charge des nouveaux paramètres régionaux :
Paramètres régionaux Code Arabe ( ar)Bulgare ( bg)Grec ( el)Hébreu ( he)Macédonien ( mk)Russe ( ru)Serbe (cyrillique) ( sr-cyrl)Ukrainien ( uk)Thaï ( th)Turc ( tr)Vietnamien ( vi)- Prise en charge des nouveaux codes monétaires :
Devise Paramètres régionaux Code BAMMark convertible de Bosnie ( ba)BGNLev bulgare ( bg)ILSNouveau shekel israélien ( il)MKDDenar macédonien ( mk)RUBRouble russe ( ru)THBBaht thaïlandais ( th)TRYLivre turque ( tr)UAHHryvnia ukrainienne ( ua)VNDDong vietnamien ( vn)- Expansion des éléments fiscaux pris en charge pour l’Allemagne (
de), l’Espagne (es), le Portugal (pt) et le Canada anglais (en-CA).
-
- Prise en charge des champs développés pour les ID et permis de conduire de l’Union européenne.
-
- Extraire des informations du formulaire 1003 – Uniform Residential Loan Application.
- Extraire des informations du formulaire 1008 – Uniform Underwriting and Transmittal Summary.
- Extraire des informations à partir de la divulgation de clôture de l’hypothèque.
-
- Extraire des informations à partir de cartes bancaires.
-
- Nouveau prédéfini pour extraire des informations à partir des certificats de mariage.
Décembre 2023
Les bibliothèques de clients Intelligence documentaire ciblant l’API REST 2023-10-31-preview sont désormais disponibles.
Novembre 2023
L’API REST31-10-2023-préversiond’Intelligence documentaire est désormais disponible. L’API de préversion introduit de nouvelles fonctionnalités mises à jour :
La version préliminaire publique 2023-10-31-préversion est actuellement disponible uniquement dans les régions Azure suivantes :
- USA Est
- USA Ouest 2
- Europe Ouest
-
- Extension linguistique pour l’écriture manuscrite : russe (
ru), arabe (ar), thaï (th). - Conformité au Cyber Executive Order (EO).
- Extension linguistique pour l’écriture manuscrite : russe (
-
- Prise en charge des fichiers Office et HTML.
- Prise en charge de la sortie markdown.
- Améliorations de l’extraction de table, de l’ordre de lecture et de la détection des titres de section.
- Dans Intelligence documentaire 2023-10-31-preview, le modèle de document général (prebuilt-document) est déconseillé. À l’avenir, pour extraire des paires clé-valeur à partir de documents, utilisez le modèle
prebuilt-layoutavec le paramètre de chaîne de requêtefeatures=keyValuePairsfacultatif activé.
-
- Extrait maintenant la devise pour tous les champs liés aux prix.
Modèle de carte d’assurance maladie
- Prise en charge de nouveaux champs pour les informations de Medicare et Medicaid.
Modèles de documents fiscaux américains
- Nouveau modèle fiscal 1099. Prend en charge le formulaire de base 1099 et variantes suivantes : A, B, C, CAP, DIV, G, H, INT, K, LS, LTC, MISC, NEC, OID, PATR, Q, QA, R, S, SA, SB.
-
- Prise en charge du champ
KVK. - Prise en charge du champ
BPAY. - Nombreuses améliorations relatives aux champs.
- Prise en charge du champ
-
- Prise en charge de documents multilingues.
- Nouvelles options de fractionnement de page : fractionnement automatique, toujours fractionner par page, aucun fractionnement.
Fonctionnalités du module complémentaire
- Des champs de requête sont disponibles avec la version
2023-10-31-preview. - Les fonctionnalités de module complémentaire sont disponibles dans tous les modèles, à l’exception du modèle de lecture.
- Des champs de requête sont disponibles avec la version
Remarque
Avec la publication en disponibilité générale de l’API 2022-08-31, les API en préversion associées sont dépréciées. Si vous utilisez les versions de l’API 2021-09-30-preview, 2022-01-30-preview, ou 2022-06-30-preview, mettez à jour vos applications pour cibler la version d’API 2022-08-31. Pour plus d’informations, consultez le guide de migration.
Juillet 2023
Remarque
Form Recognizer est désormais Azure AI Intelligence Documentaire !
- Les services Azure AI Document englobent tout ce qui était auparavant connu sous le nom de Cognitive Services et Azure Applied AI Services.
- Il n’y a aucune modification de la tarification.
- Les noms Cognitive Services et Azure Applied AI continuent d’être utilisés dans la facturation Azure, l’analyse des coûts, la liste de prix et les API de prix.
- Aucun changement cassant ne concerne les interfaces de programmation d’applications (API) et les bibliothèques de clients.
- Certaines plateformes attendent toujours la mise à jour du changement de nom. Toutes les mention de Form Recognizer ou Intelligence documentaire dans notre documentation font référence au même service Azure.
Intelligence documentaire v3.1 (GA)
L’API Intelligence documentaire version 3.1 est désormais en disponibilité générale (GA) ! La version de l’API correspond à 2023-07-31.
L’API v3.1 introduit de nouvelles fonctionnalités mises à jour :
- Les API Intelligence documentaire sont désormais plus modulaires et prennent en charge des fonctionnalités facultatives. Vous pouvez désormais personnaliser la sortie pour inclure spécifiquement les fonctionnalités dont vous avez besoin. Découvrez-en davantage sur les paramètres facultatifs.
- API de classification de documents pour fractionner un fichier unique en documents individuels. Découvrez-en davantage sur la classification de documents.
- Modèle de contrat prédéfini.
- Modèle de formulaire fiscal américain 1098 prédéfini.
- Prise en charge des types de fichiers Office avec l’API Read.
- Reconnaissance de codes-barres dans les documents.
- Fonctionnalité de module complémentaire de reconnaissance de formule.
- Fonctionnalité de module complémentaire de reconnaissance de police.
- Prise en charge des documents haute résolution.
- Les modèles neuronaux personnalisés nécessitent désormais un seul exemple étiqueté pour l’apprentissage.
- Extension du langage des modèles neuronaux personnalisés. Entraîner un modèle neuronal pour des documents en 30 langues. Pour obtenir la liste complète des langues prises en charge, consultez Prise en charge linguistique.
- 🆕 Modèle prédéfini de carte d’assurance maladie.
- Extension des paramètres régionaux du modèle de facture prédéfini.
- Développement du langage et des paramètres régionaux du modèle de réception prédéfini avec plus de 100 langues prises en charge.
- Le modèle d’ID prédéfini prend désormais en charge les ID européens.
Mises à jour de l’expérience utilisateur du studio Intelligence documentaire
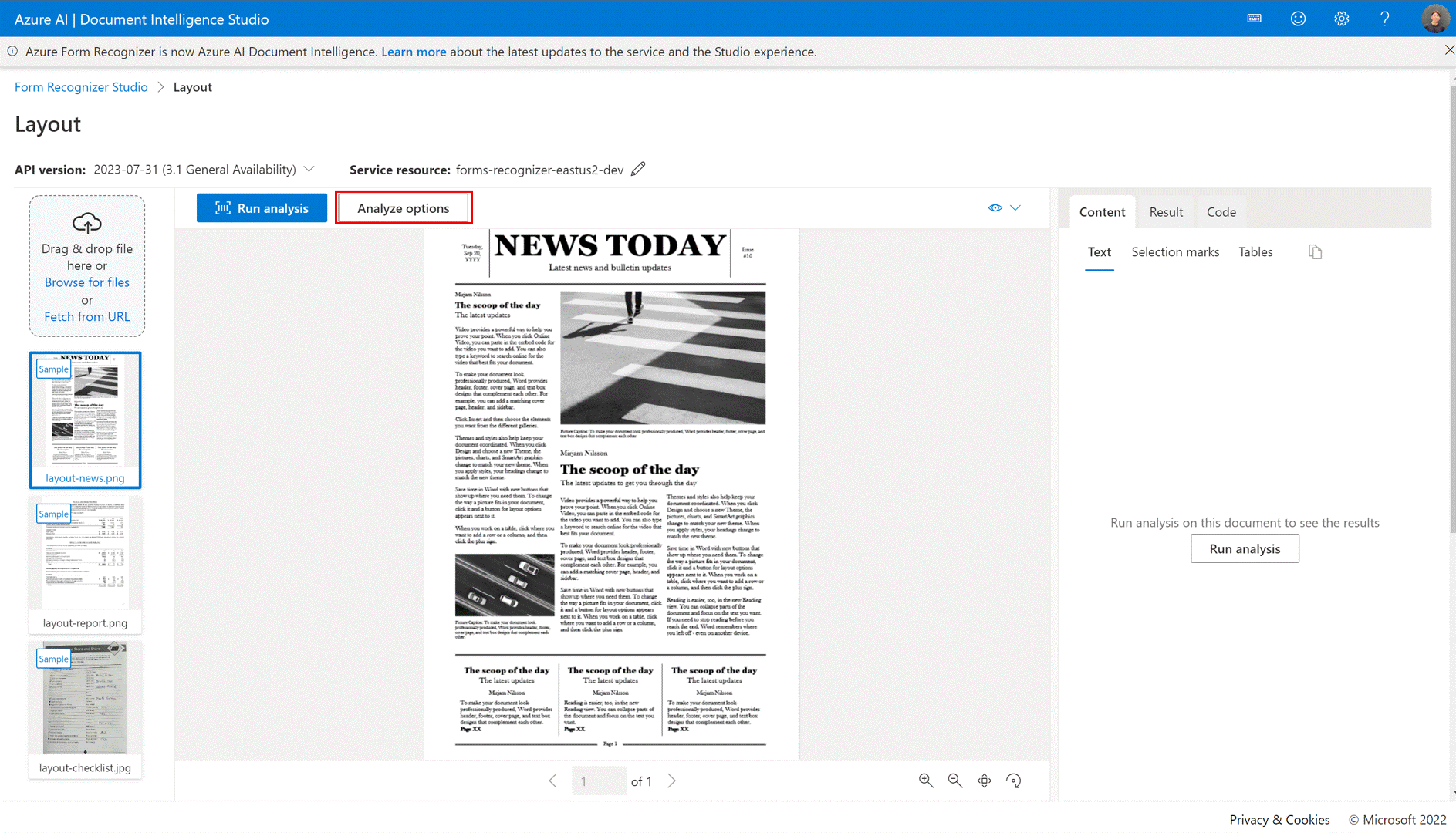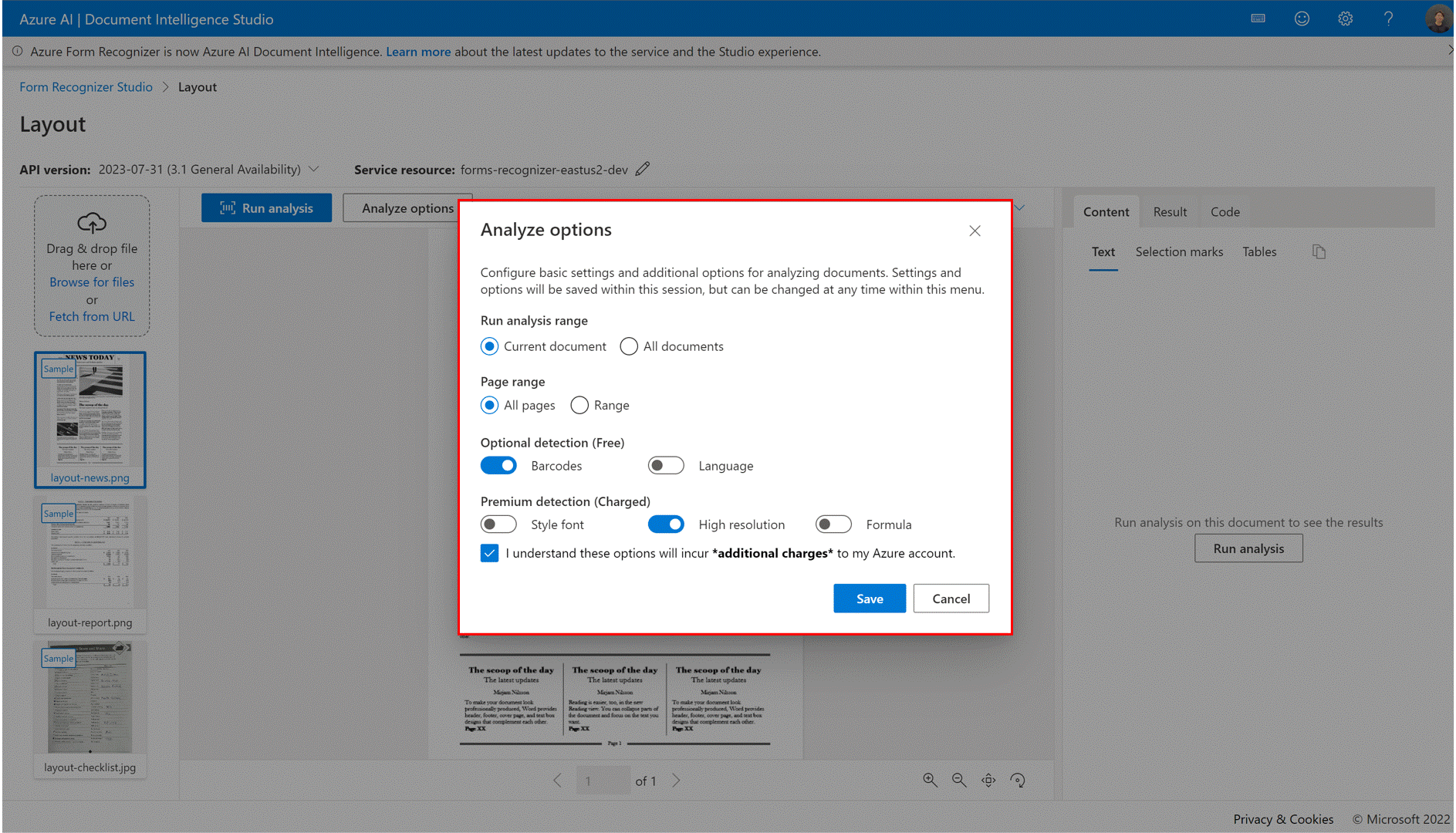
✔️ Options d’analyse
Document Intelligence prend désormais en charge des fonctionnalités d’analyse plus sophistiquées et Studio autorise un point d’entrée (bouton Options d’analyse) pour configurer facilement les fonctionnalités du module complémentaire.
En fonction du scénario d’extraction de document, configurez la plage d’analyse, la plage de pages de document, la détection facultative et les fonctionnalités de détection Premium.
Remarque
L’extraction de police n’est pas visualisées dans Document Intelligence Studio. Toutefois, vous pouvez vérifier la section de styles de la sortie JSON pour obtenir les résultats de la détection de police.
✔️ Étiquetage automatique des documents avec des modèles prédéfinis ou l’un de vos propres modèles
Dans la page d’étiquetage des modèles d’extraction personnalisés, vous pouvez désormais étiqueter automatiquement vos documents à l’aide de l’un des modèles prédéfinis du service Intelligence documentaire ou de modèles que vous avez précédemment entraînés.
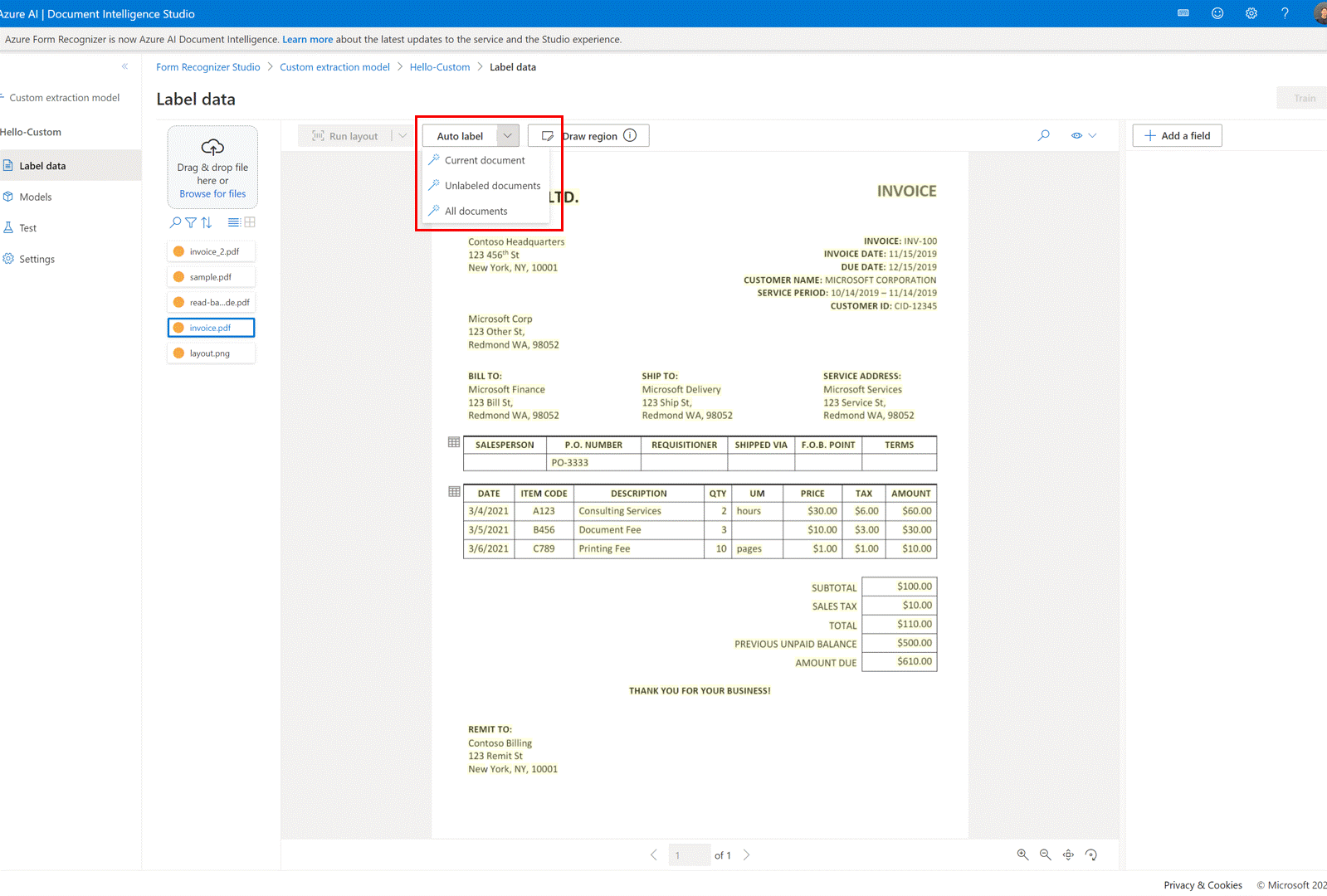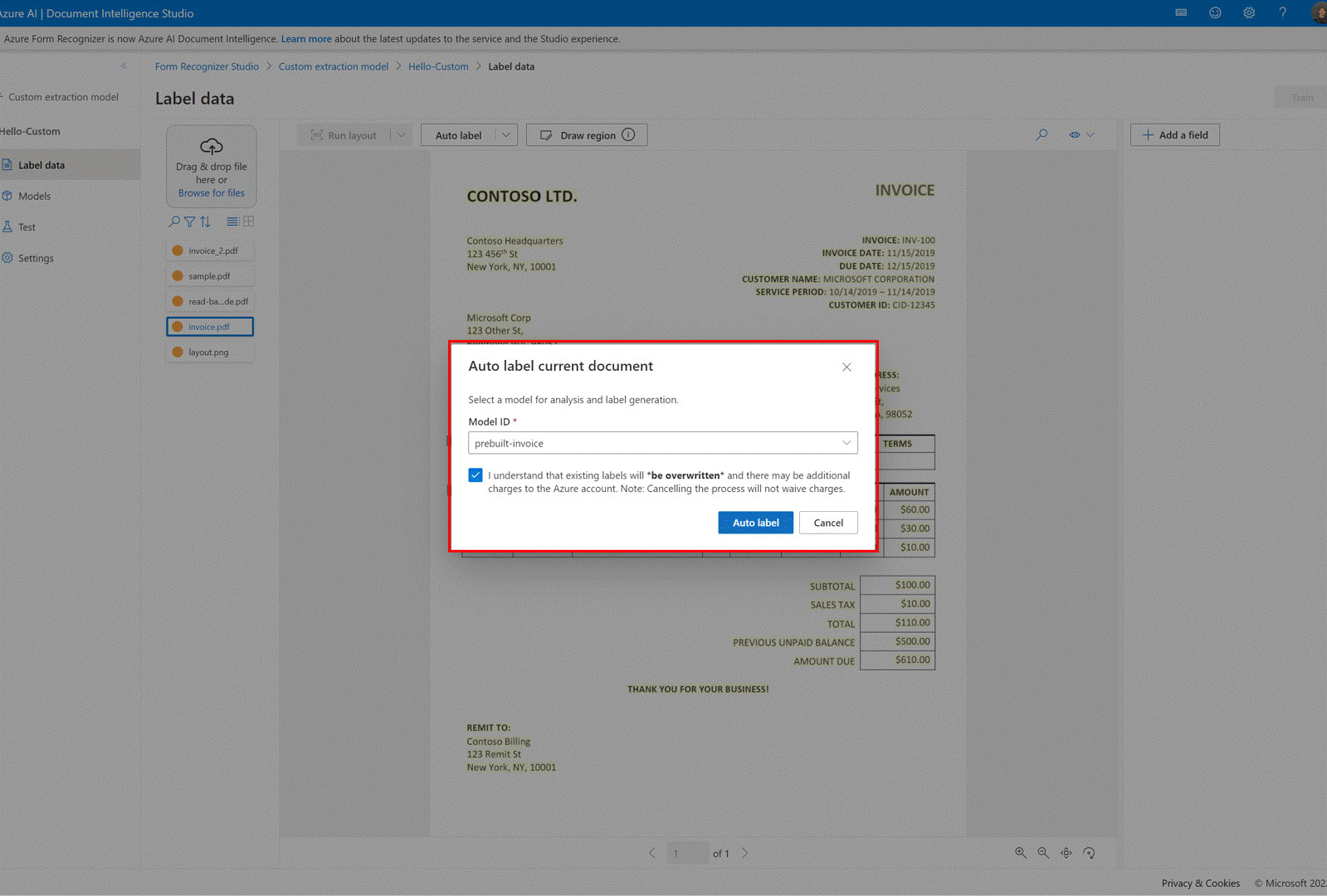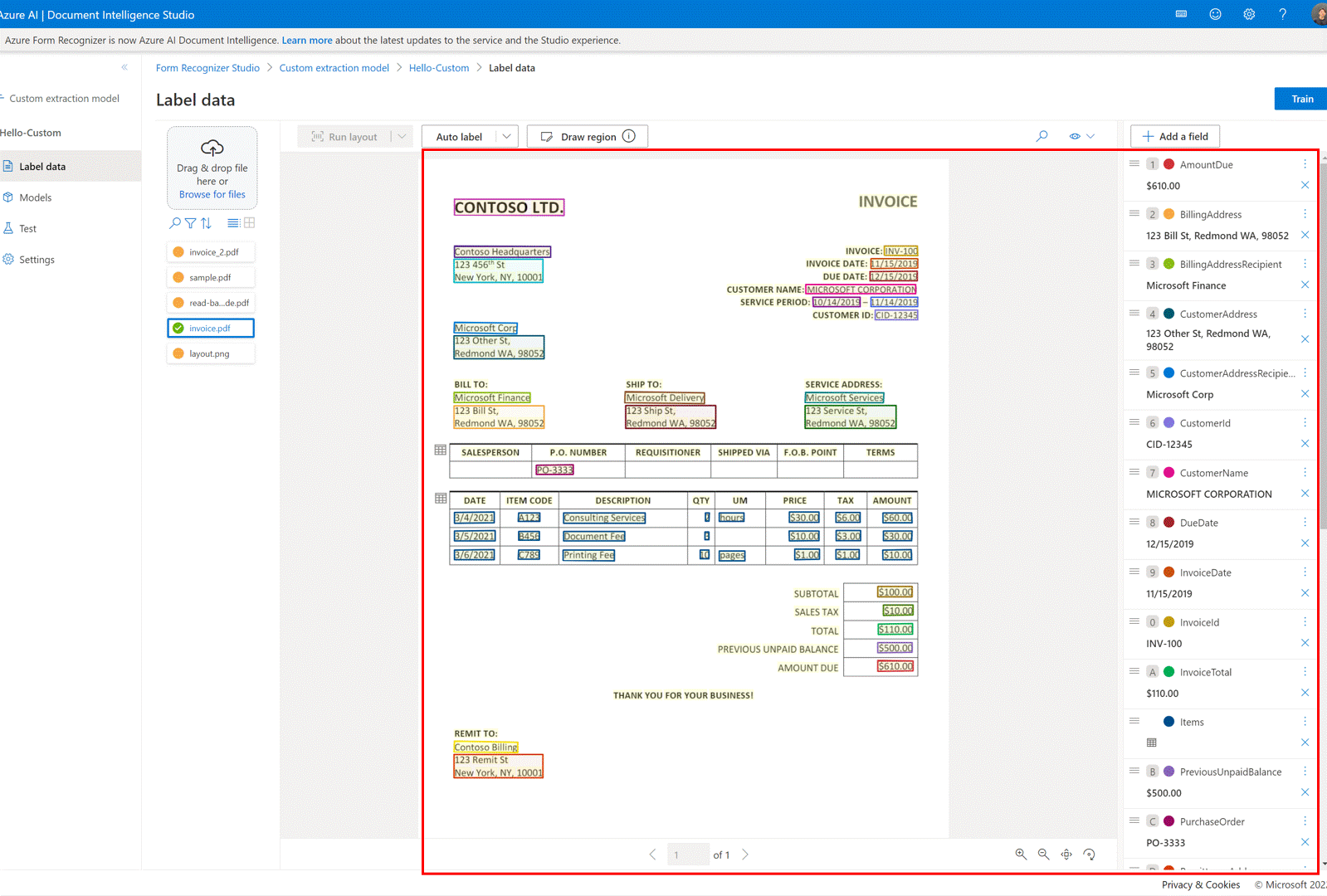
Pour certains documents, il peut y avoir des étiquettes en double après l’exécution de l’étiquette automatique. Veillez à modifier les étiquettes afin qu’il n’y ait pas d’étiquettes en double dans la page d’étiquetage par la suite.
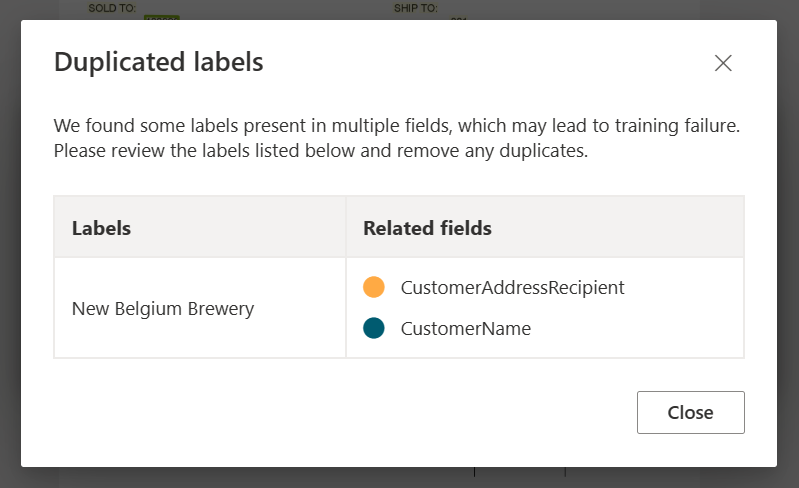
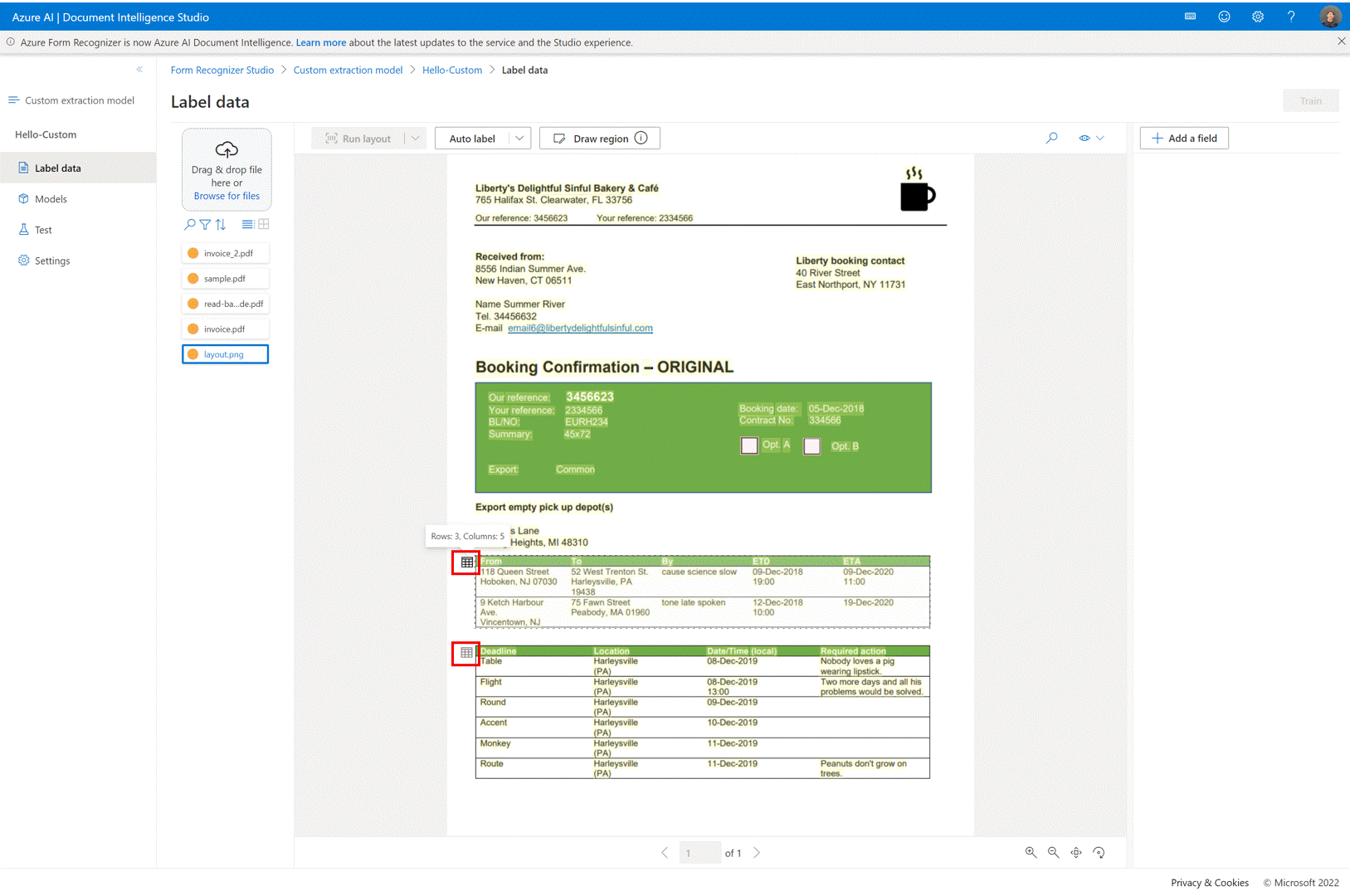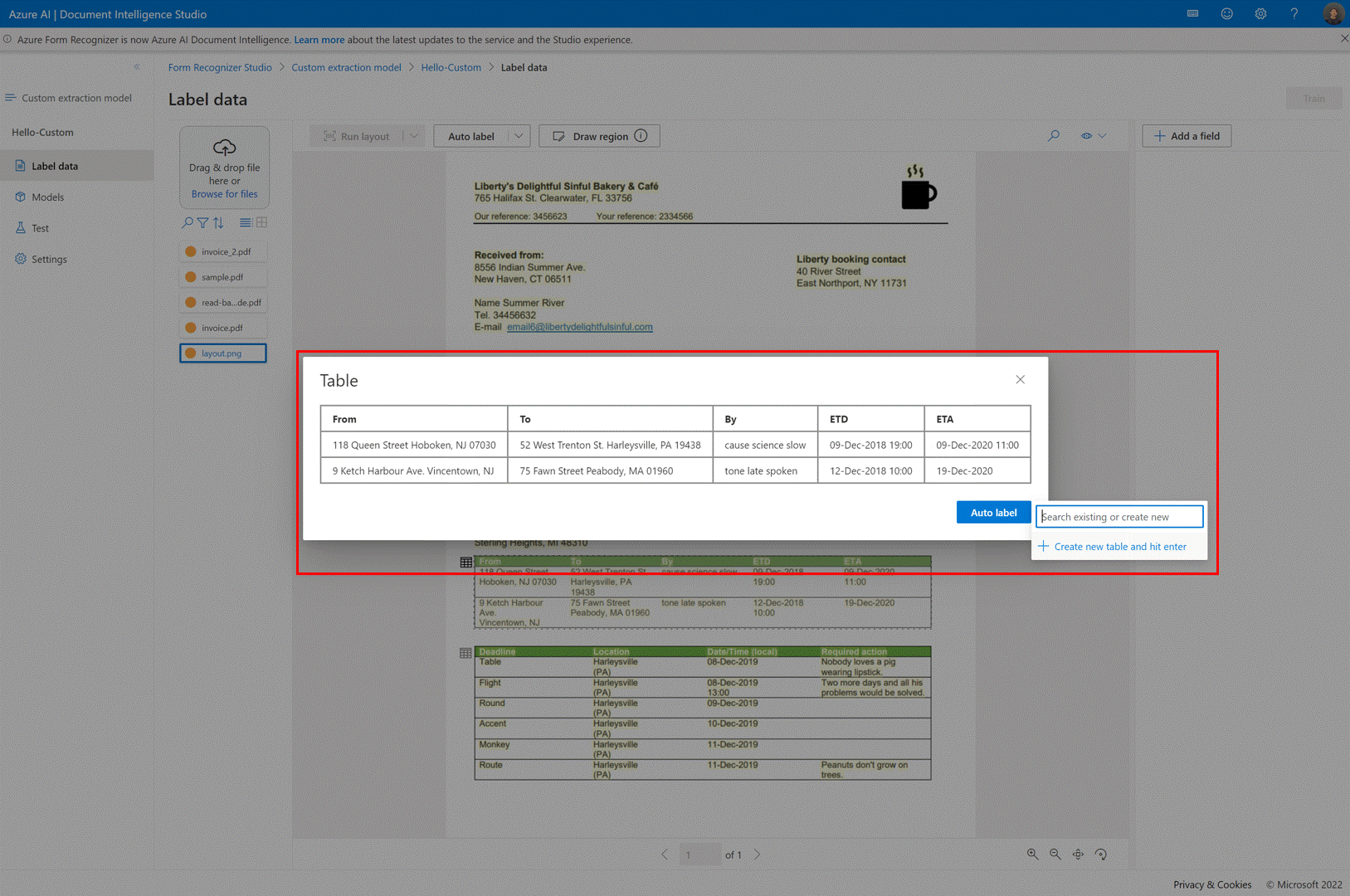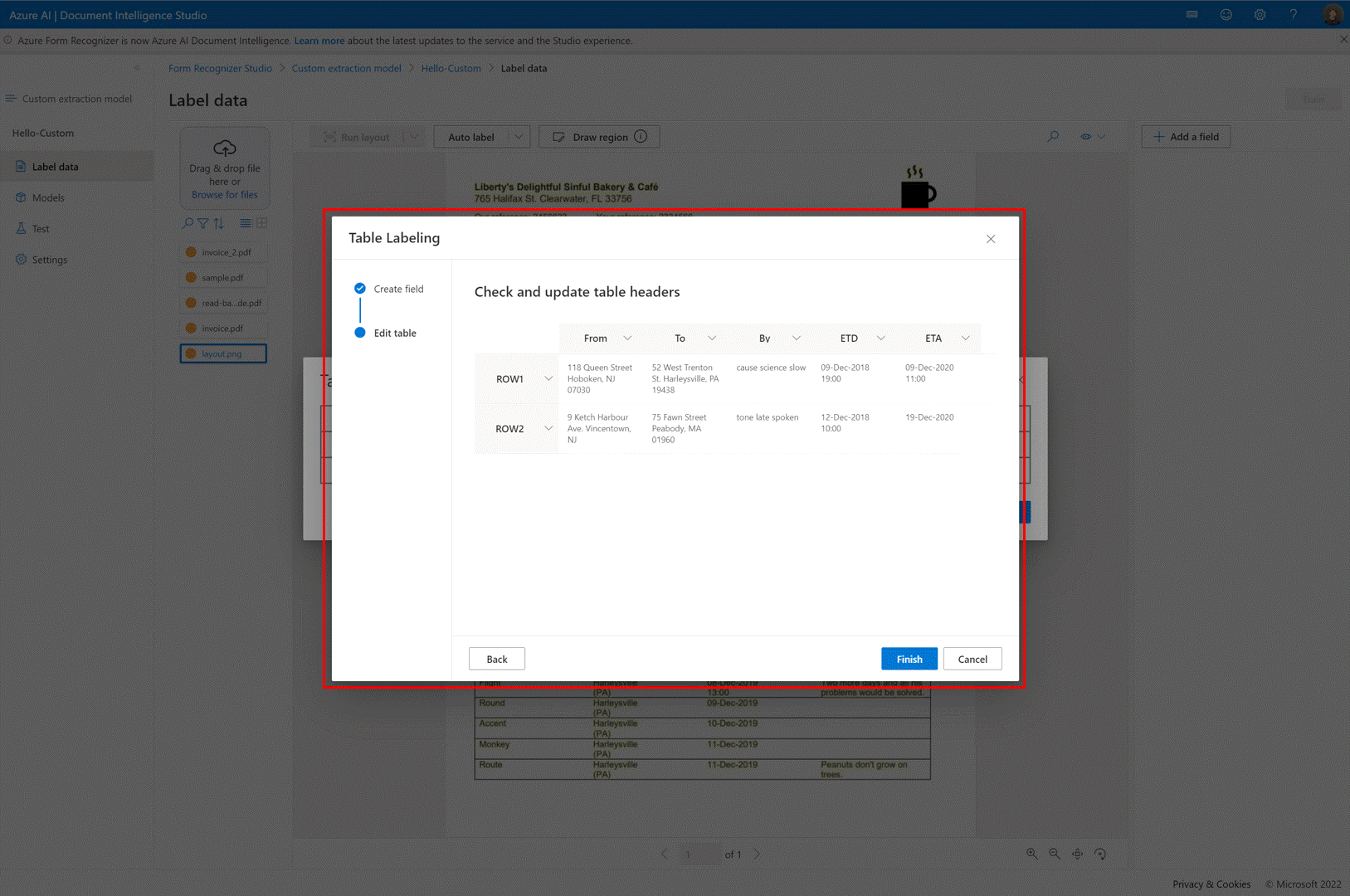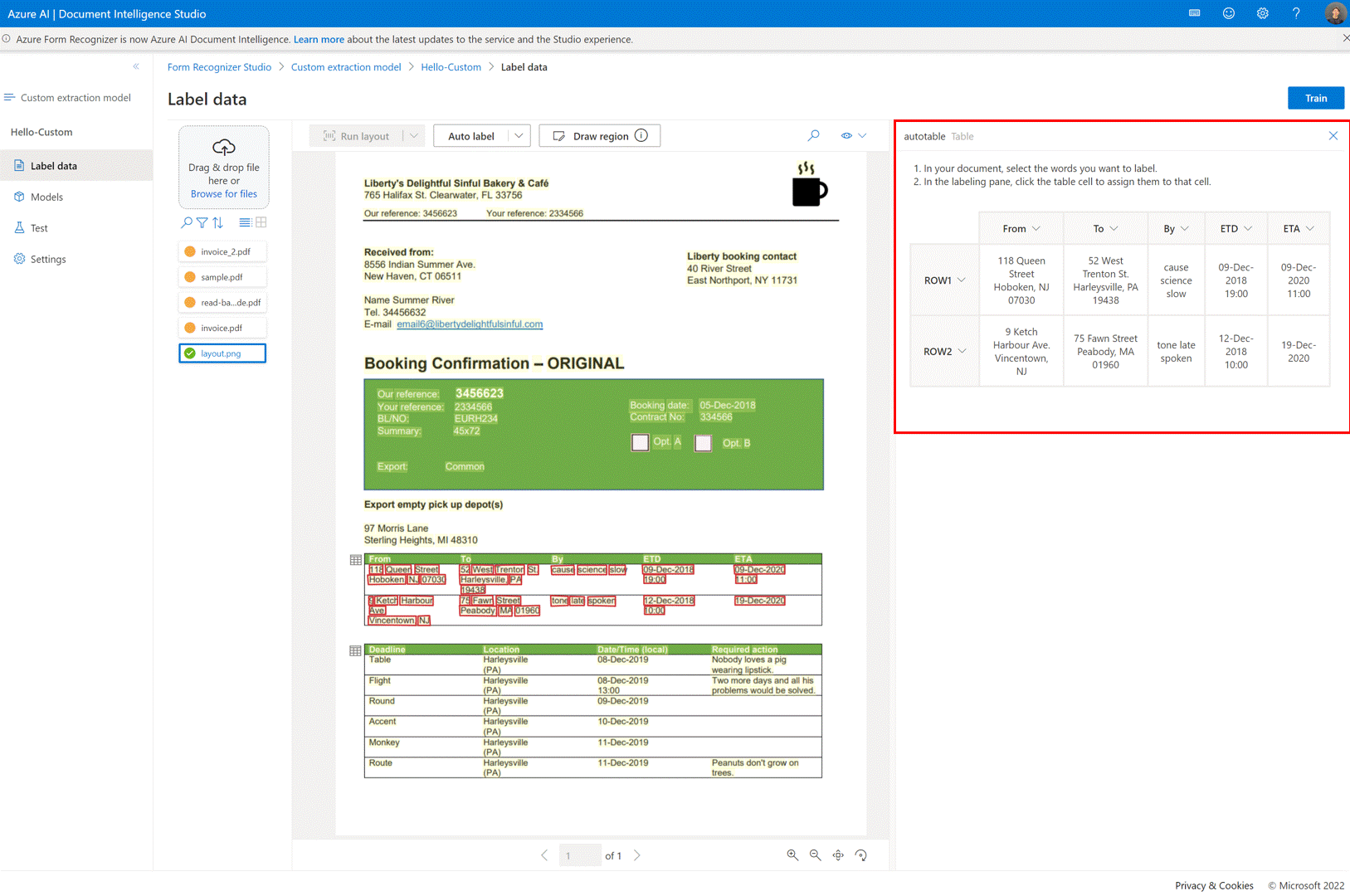
✔️ Tables d’étiquetage automatique
Dans la page d’étiquetage du modèle d’extraction personnalisée, vous pouvez désormais étiqueter automatiquement les tables du document sans avoir à étiqueter les tables manuellement.
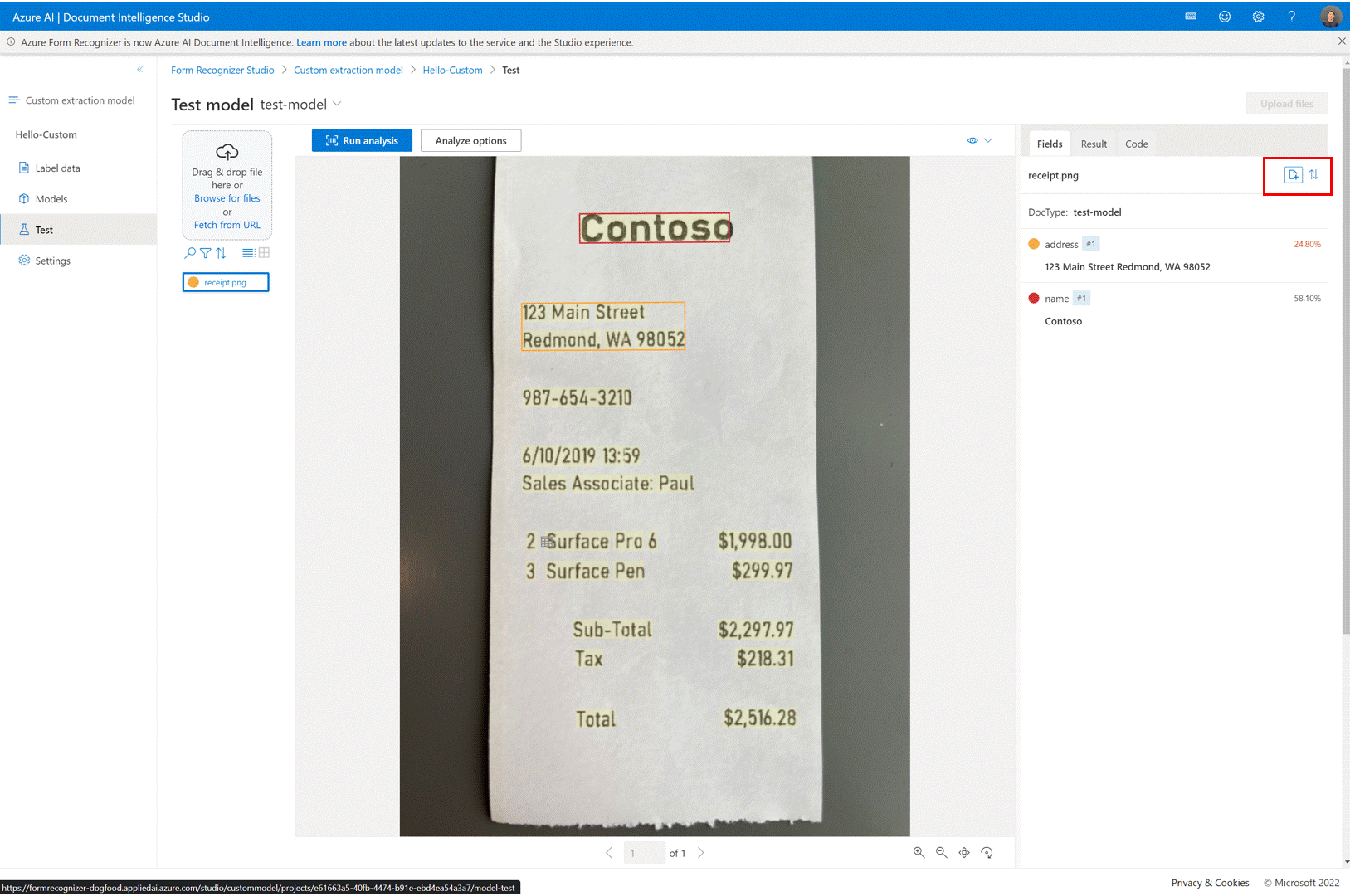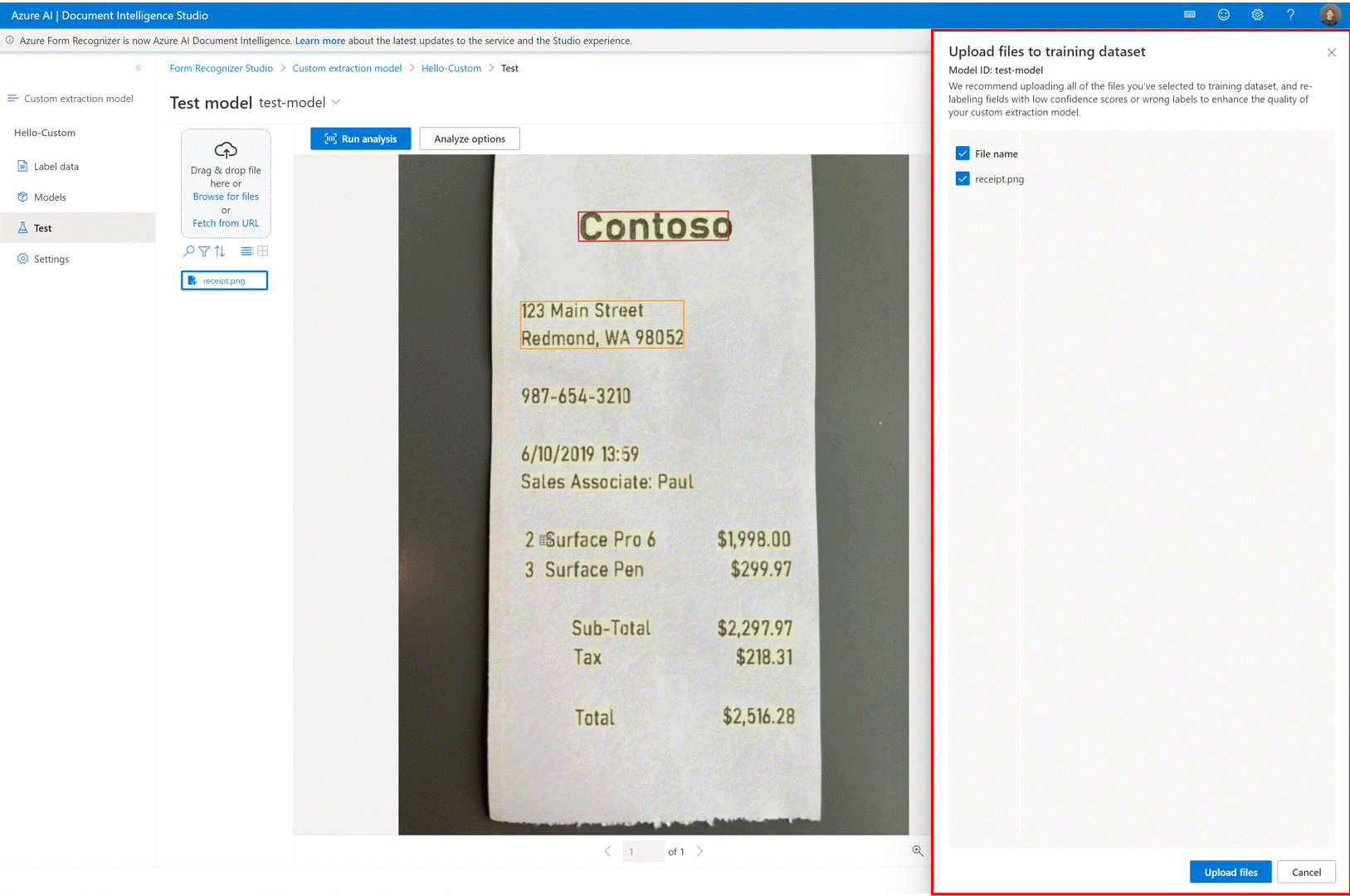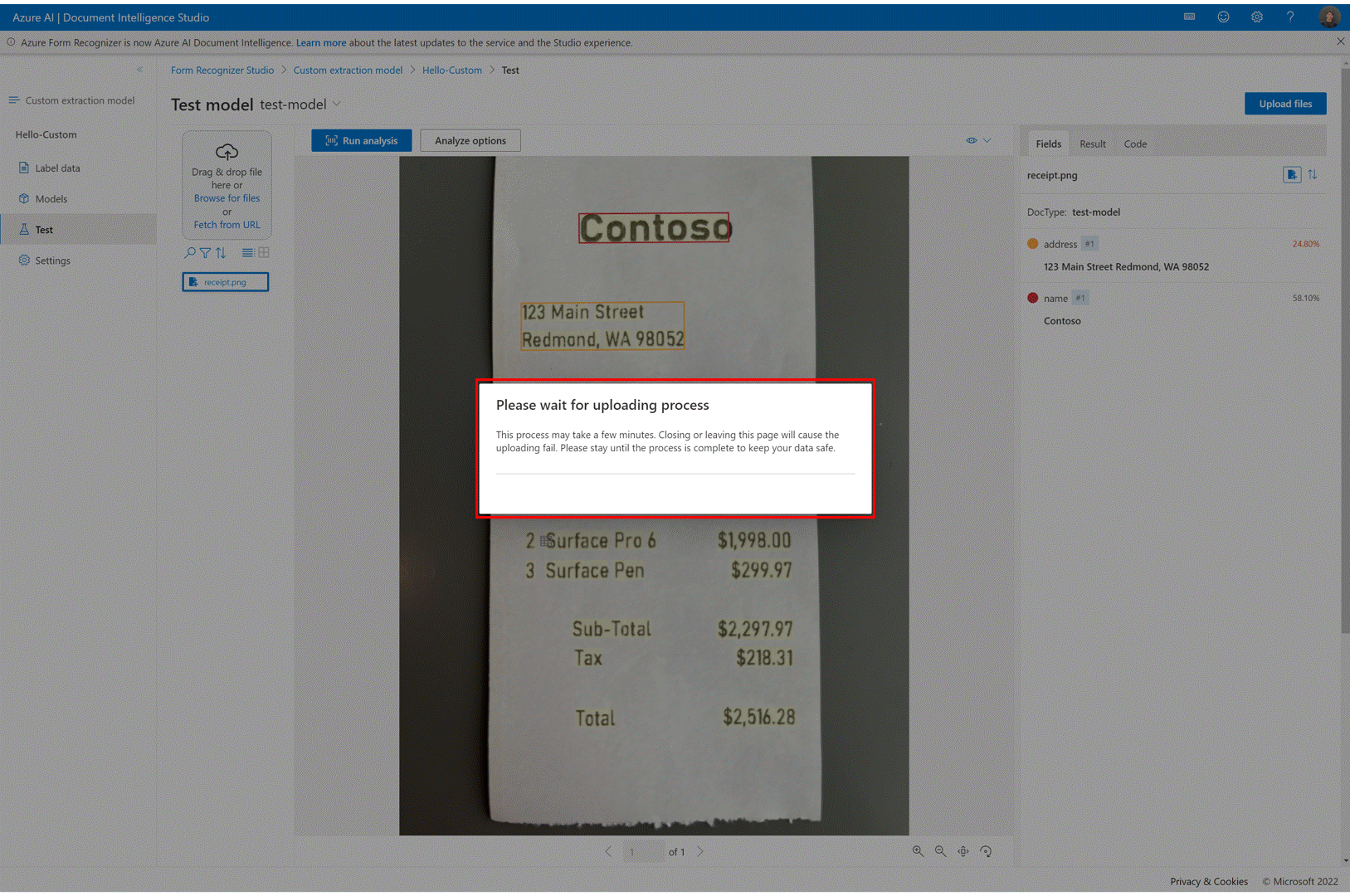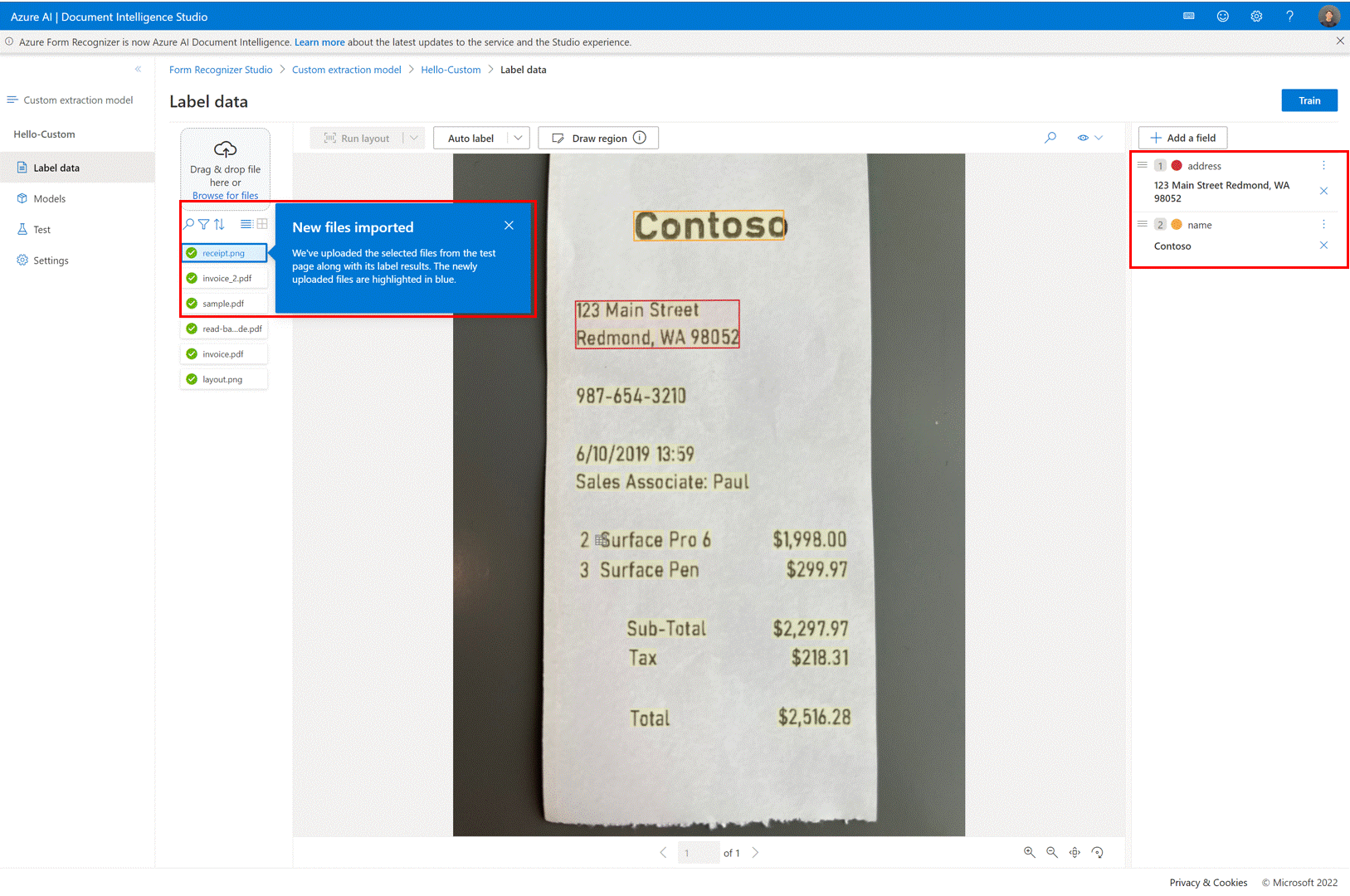
✔️ Ajouter des fichiers de test directement à votre jeu de données d’entraînement
Une fois que vous avez entraîné un modèle d’extraction personnalisé, utilisez la page de test pour améliorer la qualité de votre modèle en chargeant des documents de test dans un jeu de données d’entraînement si nécessaire.
Si un score de confiance faible est retourné pour certaines étiquettes, vérifiez que vos étiquettes sont correctes. Si ce n’est pas le cas, ajoutez-les au jeu de données d’entraînement et réétiquetez pour améliorer la qualité du modèle.
✔️ Utiliser les options de liste de documents et les filtres dans les projets personnalisés
Utilisez la page d’étiquetage du modèle d’extraction personnalisé. Vous pouvez désormais naviguer facilement dans vos documents de formation en utilisant la fonctionnalité de recherche, de filtrage et de tri.
Utilisez le mode grille pour afficher un aperçu des documents ou utilisez l’affichage liste pour faire défiler les documents plus facilement.
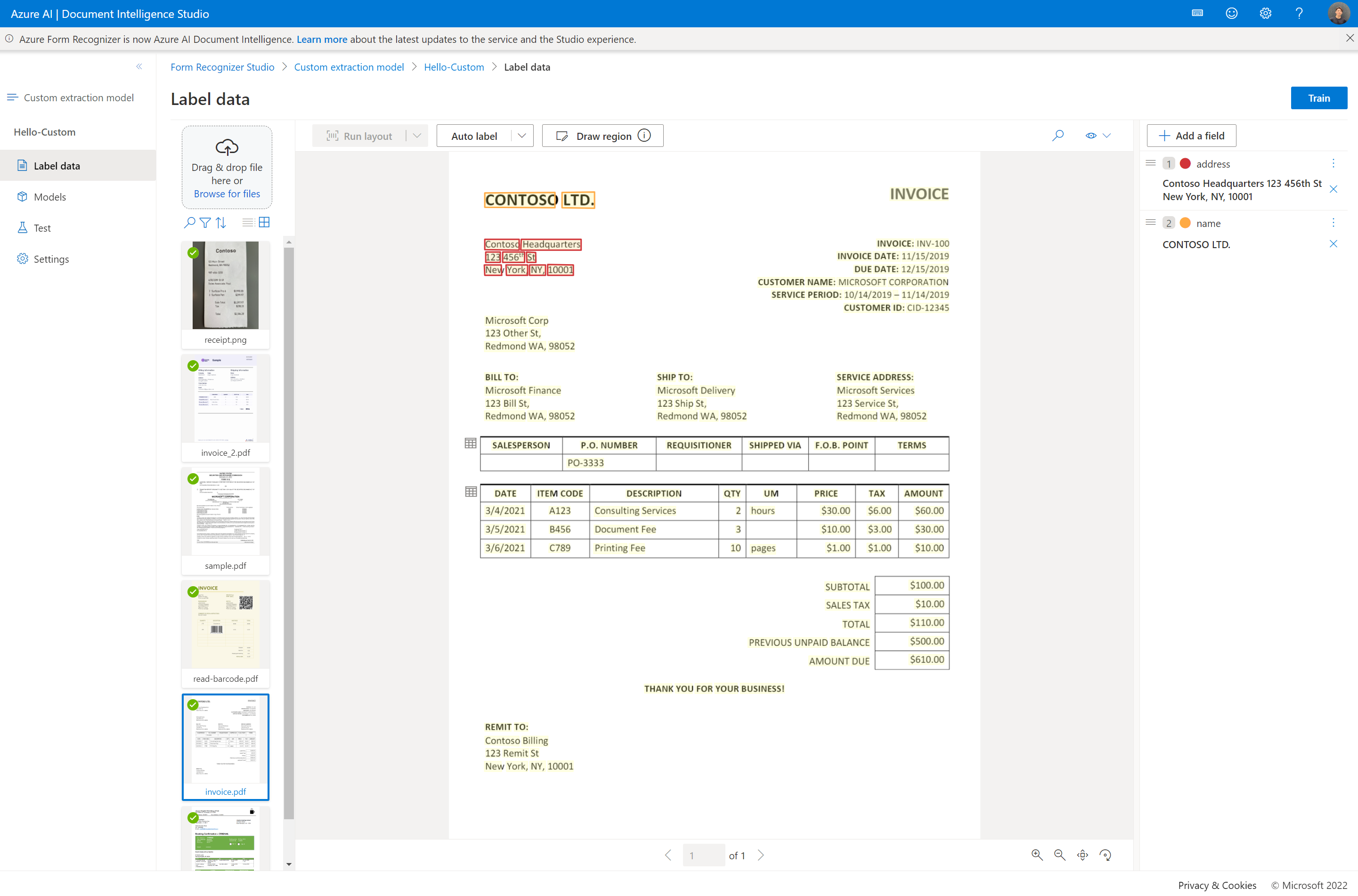
✔️ Partage de projet
- Partagez facilement des projets d’extraction personnalisés. Pour plus d’informations, consultez Partage de projet avec des modèles personnalisés.
Mai 2023
Présentation de la documentation actualisée pour la build 2023
🆕 Vue d’ensemble d’Intelligence documentaire : navigation améliorée, points d’accès structurés et images enrichies.
🆕 Choisir un modèle Intelligence documentaire fournit des conseils pour choisir la meilleure solution Intelligence documentaire pour vos projets et flux de travail.
Avril 2023
Annonce de la publication de préversion publique de bibliothèque client la plus récente d’Intelligence documentaire
L’API REST Intelligence documentaire version 2023-02-28-preview prend en charge les bibliothèques de clients de la préversion publique. Cette version inclut les nouvelles fonctionnalités et capacités suivantes disponibles pour les bibliothèques de clients .NET/C# (4.1.0-beta-1), Java (4.1.0-beta-1), JavaScript (4.1.0-beta-1) et Python (3.3.0b.1) :
Pour plus d’informations, consultez Kit de développement logiciel (SDK) Intelligence documentaire (préversion publique) et les Notes de publication de mars 2023
Mars 2023
Important
Les fonctionnalités 2023-02-28-preview sont actuellement disponibles uniquement dans les régions suivantes :
- Europe Ouest
- USA Ouest 2
- USA Est
- Modèle de classification personnalisée est une nouvelle capacité dans Intelligence documentaire à partir de l’API
2023-02-28-preview. - Les fonctionnalités Champs de requête ajoutées au modèle Document général utilisent les modèles Azure OpenAI pour extraire des champs spécifiques de documents. Essayez la fonctionnalité Documents généraux avec champs de requête à l’aide du studio Intelligence documentaire. Les champs de requête sont actuellement actifs uniquement pour les ressources de la région
East US. - Fonctionnalités de modules complémentaires :
- L’extraction de police est désormais reconnue avec l’API
2023-02-28-preview. - L’extraction de formule est désormais reconnue avec l’API
2023-02-28-preview. - L’extraction haute résolution est désormais reconnue avec l’API
2023-02-28-preview.
- L’extraction de police est désormais reconnue avec l’API
- Mises à jour des modèles d’extraction personnalisés :
- Les Modèles neuraux personnalisés prennent désormais en charge les langues ajoutées pour l’apprentissage et l’analyse. Effectuez l’apprentissage de modèles neuronaux pour le néerlandais, le français, l’allemand, l’italien et l’espagnol.
- Les Modèles personnalisés disposent désormais d’une fonctionnalité de détection de signature améliorée.
- Mises à jour de Document Intelligence Studio :
- En plus de la prise en charge de toutes les nouvelles fonctionnalités, comme la classification et les champs de requête, Studio permet désormais le partage de projet pour les projets de modèles personnalisés.
- Nouveaux modèles ajoutés dans la préversion contrôlée : Cartes de vaccination, Contrats, Formulaire fiscal US 1098, Formulaire fiscal US 1098-E et Formulaire fiscal US 1098-T. Pour demander un accès aux modèles de préversion contrôlés, remplissez et envoyez le Formulaire de demande de préversion privée Intelligence documentaire.
- Mises à jour du modèle de reçu :
- Le modèle de reçu prend désormais en charge les reçus thermiques.
- Le modèle de reçu prend désormais en charge 18 langues et trois langues régionales (anglais, français, portugais).
- Le modèle de reçu prend désormais en charge l’extraction
TaxDetails.
- Le modèle de disposition améliore désormais la reconnaissance des tables.
- Le modèle de lecture améliore désormais la reconnaissance des caractères à un chiffre.
Février 2023
Certains conteneurs Intelligence documentaire pour la version 3.0 sont désormais disponibles !
Actuellement, les conteneurs Read v3.0 et Layout v3.0 sont disponibles.
Pour plus d’informations, consultez Installer et exécuter des conteneurs Intelligence documentaire.
Janvier 2023
Modèle de reçu prédéfini : langues prises en charge ajoutées. Le modèle de reçu prend désormais en charge ces langues et paramètres régionaux ajoutés
- Japonais : Japon (ja-JP)
- Français : Canada (fr-CA)
- Néerlandais : Pays-Bas (nl-NL)
- Anglais : Émirats arabes unis (en-AE)
- Portugais : Brésil (pt-BR)
Modèle de facture prédéfini : langues prises en charge ajoutées. Le modèle de facture prend désormais en charge ces langues et paramètres régionaux ajoutés
- Anglais : États-Unis (en-US), Australie (en-AU), Canada (en-CA), Royaume-Uni (en-UK), Inde (en-IN)
- Espagnol - Espagne (es-ES)
- Français - France (fr-FR)
- Italien - Italie (it-IT)
- Portugais - Portugal (pt-PT)
- Néerlandais : Pays-Bas (nl-NL)
Modèle de facture prédéfini : champs reconnus ajoutés. Le modèle de facture reconnaît maintenant ces champs ajoutés
- Code devise
- Modes de paiement
- Remise totale
- Éléments fiscaux (en-IN uniquement)
Modèle d’ID prédéfini : ajout de types de documents pris en charge. Le modèle d’ID prend désormais en charge ces types de documents ajoutés
- ID militaire des États-Unis
Conseil
Toutes les mises à jour de janvier 2023 sont disponibles avec l’API REST version 2022-08-31 (disponibilité générale).
Modèle de réception prédéfini : prise en charge de langues supplémentaires :
Le modèle de reçu prédéfini prend désormais en charge les langues suivantes :
- Anglais : Émirats arabes unis (en-AE)
- Néerlandais : Pays-Bas (nl-NL)
- Français : Canada (fr-CA)
- Allemand (de-DE)
- Italien (it-IT)
- Japonais : Japon (ja-JP)
- Portugais : Brésil (pt-BR)
Modèle de facture prédéfini : prise en charge de langues supplémentaires et extractions de champs
Le modèle de facture prédéfini prend désormais en charge les langues suivantes :
- Anglais : Australie (en-AU), Canada (en-CA), Royaume-Uni (en-UK), Inde (en-IN)
- Portugais : Brésil (pt-BR)
Le modèle de facture prédéfini prend désormais en charge les extractions de champs suivantes :
- Code devise
- Modes de paiement
- Remise totale
- Éléments fiscaux (en-IN uniquement)
Modèle de document d’ID prédéfini : prise en charge de types de documents supplémentaires
Le modèle de document d’ID prédéfini prend désormais en charge les types de documents suivants :
- Expansion des permis de conduire prenant en charge l’Inde, le Canada, le Royaume-Uni et l’Australie
- Cartes d’identité et documents militaires américains
- Cartes d’identité et documents indiens (PAN et Aadhaar)
- Cartes d’identité et documents d’Australie (carte photo, pièce d’identité de passe-clé)
- Cartes d’identité et documents canadiens (carte d’identité, carte Maple)
- Cartes d’identité et documents au Royaume-Uni (carte d’identité nationale/régionale)
Décembre 2022
Mises à jour du studio Intelligence documentaire
La version de décembre de Studio Intelligence documentaire inclut les dernières mises à jour de Studio Intelligence documentaire. Il existe des améliorations significatives de l’expérience utilisateur, principalement avec la prise en charge de l’étiquetage de modèle personnalisé.
Étendue de pages. Studio prend désormais en charge l’analyse de pages spécifiées d’un document.
Étiquetage de modèle personnalisé :
Exécuter automatiquement l’API Disposition. Vous pouvez choisir d’exécuter automatiquement l’API Disposition pour tous les documents de votre stockage d’objets blob pendant le processus de configuration d’un modèle personnalisé.
Rechercher. Studio inclut désormais des fonctionnalités de recherche pour localiser des mots dans un document. Cette amélioration facilite la navigation lors de l’étiquetage.
Navigation. Vous pouvez sélectionner des étiquettes pour cibler des mots étiquetés dans un document.
Étiquetage automatique de table. Après la sélection de l’icône de table dans un document, vous pouvez choisir d’étiqueter automatiquement la table extraite dans la vue étiquetage.
Sous-types d’étiquettes et sous-types de deuxième niveau Studio prend désormais en charge les sous-types pour les colonnes de table, les lignes de table et les sous-types de deuxième niveau pour des types tels que les dates et les nombres.
La génération de modèles neuronaux personnalisés est désormais prise en charge dans la région US Gov Virginie.
Les versions d’API en préversion
2022-01-30-previewet2021-09-30-previewseront mis hors service le 31 janvier 2023. Effectuez une mise à jour vers la version d’API2022-08-31pour éviter toute interruption de service.
Novembre 2022
- Annonce de la dernière version stable des bibliothèques Azure AI Intelligence documentaire
- Cette version inclut des modifications et des mises à jour importantes pour les bibliothèques de clients .NET, Java, JavaScript et Python. Pour plus d’informations, consultez Azure SDK DevBlog.
- Les améliorations les plus significatives sont l’introduction de deux nouveaux clients, le
DocumentAnalysisClientet .DocumentModelAdministrationClient
Octobre 2022
Contenu versionné d’Intelligence documentaire
La documentation sur Intelligence documentaire est mise à jour pour présenter une expérience versionnée. À présent, vous pouvez choisir d’afficher le contenu ciblant l’expérience
v3.0 GAou l’expériencev2.1 GA. L’expérience v3.0 est la valeur par défaut.
Exemple de code Studio Intelligence documentaire
- L’exemple de code de l’expérience d’étiquetage Studio Intelligence documentaire est désormais disponible sur GitHub. Les clients peuvent développer et intégrer Intelligence documentaire dans leur propre expérience utilisateur ou générer leur propre expérience utilisateur à l’aide de l’exemple de code Studio Intelligence documentaire.
Extension linguistique
- Avec la dernière préversion, les modèles Read avec reconnaissance optique de caractères, de mise en page et de modèles personnalisés d’Intelligence documentaire prennent en charge 134 nouvelles langues. Ces ajouts linguistiques incluent le grec, le letton, le serbe, le thaï, l’ukrainien et le vietnamien, ainsi que plusieurs langues latines et cyrilliques. Intelligence documentaire offre désormais un total de 299 langues prises en charge dans les versions les plus récentes en disponibilité générale et en préversion. Reportez-vous aux pages des langues prises en charge pour afficher toutes les langues prises en charge.
- Utilisez le paramètre
api-version=2022-06-30-previewd’API REST lors de l’utilisation de l’API ou du Kit de développement logiciel (SDK) correspondant pour prendre en charge les nouvelles langues de vos applications.
Nouveau modèle de contrat prédéfini
- Nouveau modèle prédéfini qui extrait des informations des contrats comme les parties, le titre, l’ID de contrat, la date d’exécution et plus encore. Le modèle de contrats est actuellement en préversion, demandez l’accès ici.
Expansion régionale pour l’entraînement des modèles neuronaux personnalisés
- L’entraînement des modèles neuronaux personnalisés est désormais pris en charge dans des régions supplémentaires.
- USA Est
- USA Est 2
- Gouvernement des États-Unis – Arizona
- L’entraînement des modèles neuronaux personnalisés est désormais pris en charge dans des régions supplémentaires.
Septembre 2022
Remarque
À compter de la version 4.0.0, un nouveau jeu de clients a été introduit pour tirer parti des fonctionnalités les plus récentes du service Intelligence documentaire.
La version GA de la version SDK 4.0.0 inclut les mises à jour suivantes :
- Version 4.0.0 GA (2022-09-08)
- Prend en charge les clients API REST v3.0 et v2.0
L’extension de région pour l’apprentissage de modèles neuronaux personnalisés est désormais prise en charge dans six nouvelles régions
- Australie Est
- USA Centre
- Asie Est
- France Centre
- Sud du Royaume-Uni
- USA Ouest 2
Pour obtenir la liste complète des régions où l’entraînement est pris en charge, consultez Modèles neuronaux personnalisés.
Publication de la version
4.0.0 GAdu SDK Intelligence documentaire :- Les bibliothèques de clients Intelligence documentaire versions 4.0.0 (.NET/C#, Java, JavaScript) et 3.2.0 (Python) sont en disponibilité générale et prêtes à être utilisées dans les applications de production.
- Pour plus d’informations sur les bibliothèques de clients Intelligence documentaire, consultez la vue d’ensemble du SDK.
- Mettez à jour vos applications à l’aide du guide de migration de votre langage de programmation.
Août 2022
Version préliminaire d’août 2022 de la bêta du SDK Intelligence documentaire inclut les mises à jour suivantes :
Version 4.0.0-beta.5 (09/08/2022)
Intelligence documentaire v3.0 en disponibilité générale
- L’API REST Intelligence documentaire v3.0 est désormais en disponibilité générale, ce qui signifie qu’elle peut être utilisée dans les applications de production. Mettez à jour vos applications avec l’API REST version 2022-08-31.
Mises à jour du studio Intelligence documentaire
- Étapes suivantes. Sous chaque page de modèle, Studio comporte désormais une section Étapes suivantes. Les utilisateurs peuvent rapidement consulter des exemples de code, des instructions de résolution des problèmes et des informations tarifaires.
- Modèles personnalisés. Studio permet désormais de réorganiser les étiquettes dans les projets de modèles personnalisés afin d’améliorer l’efficacité de l’étiquetage.
- Copie des modèles Les modèles personnalisés peuvent être copiés dans les services Intelligence documentaire à partir de Studio. Cette opération permet de promouvoir un modèle formé dans d’autres environnements et régions.
- Suppression de documents. Studio prend désormais en charge la suppression de documents à partir de jeux de données étiquetés dans les projets personnalisés.
Mises à jour du service Intelligence documentaire
- prebuilt-read. Désormais, le modèle Read avec reconnaissance optique de caractères est également disponible dans Intelligence documentaire avec deux nouvelles fonctionnalités, la détection des paragraphes et de la langue. Read d’Intelligence documentaire cible des scénarios de documents avancés, alignés sur les grandes fonctionnalités d’analyse des documents d’Intelligence documentaire.
- prebuilt-layout. Le modèle Layout extrait les paragraphes et indique si le texte extrait est un paragraphe, un titre, un en-tête de section, une note de bas de page, un en-tête de page, un pied de page ou un numéro de page.
- prebuilt-invoice. Désormais, les champs TotalVAT et Line/VAT seront respectivement remplacés par les champs existants TotalTax et Line/Tax.
- prebuilt-idDocument. Prise en charge de l’extraction de données pour les cartes d’identité, les cartes de sécurité sociale et les cartes vertes américaines. Prise en charge des informations relatives aux visas de passeport.
- prebuilt-receipt. Prise en charge étendue des paramètres régionaux pour le français (fr-FR), l’espagnol (es-ES), le portugais (pt-PT), l’italien (it-IT) et l’allemand (de-DE).
- prebuilt-businessCard. Prise en charge de l’analyse des adresses pour extraire les sous-champs de composants d’adresses tels que l’adresse, la ville, l’état, le pays/la région et le code postal.
Amélioration de la qualité de l’IA
- prebuilt-read. La prise en charge des caractères uniques, des dates manuscrites, des montants, des noms et d’autres données importantes courantes dans les reçus et les factures a été améliorée, de même que le traitement des documents PDF numériques.
- prebuilt-layout. Meilleure détection des tableaux rognés et sans bordure, et meilleure reconnaissance des cellules longues.
- prebuilt-document. Amélioration de la détection des valeurs et des cases à cocher.
- custom-neural. Amélioration de la précision de la détection et de l’extraction des tables.
Juin 2022
- Version préliminaire de la bêta de juin 2022 du SDK Intelligence documentaire inclut les mises à jour suivantes :
Version 4.0.0-beta.4 (2022-06-08)
La version de juin de Studio Intelligence documentaire est la dernière mise à jour du studio Intelligence documentaire. Cette mise à jour apporte des améliorations considérables en matière d’expérience utilisateur et d’accessibilité :
- Exemple de code pour JavaScript et C#. L’onglet de code Studio comprend désormais des exemples de code JavaScript et C# en plus de l’exemple Python existant.
- Nouvelle interface utilisateur de chargement de document. Studio prend désormais en charge le chargement d’un document par glisser-déposer dans la nouvelle interface utilisateur de chargement.
- Nouvelle fonctionnalité pour les projets personnalisés. Les projets personnalisés prennent maintenant en charge la création de comptes de stockage et d’objets blob lors de la configuration du projet. En outre, le projet personnalisé prend maintenant en charge le chargement de fichiers d’entraînement directement dans Studio et la copie du modèle personnalisé existant.
La publication Intelligence documentaire v3.0 0 2022-06-30-preview présente d’importantes mises à jour des API de fonctionnalités :
- La disposition étend l’extraction de structure. La disposition inclut à présent des éléments de structure ajoutés, notamment des sections, des en-têtes de section et des paragraphes. Cette mise à jour permet des scénarios de segmentation de documents plus affinés. Pour obtenir la liste complète des éléments de structure identifiés, consultez structure améliorée.
- Prise en charge des champs tabulaires des modèles neuronaux personnalisés. Les modèles de document personnalisés prennent à présent en charge les champs tabulaires. Les champs tabulaires par défaut sont également multipage. Pour en savoir plus sur les champs tabulaires dans des modèles neuronaux personnalisés, consultez les champs tabulaires.
- Prise en charge des champs tabulaires des modèles personnalisés pour les tables de plusieurs pages. Les modèles de formulaire personnalisés prennent à présent en charge les champs tabulaires sur les pages. Pour en savoir plus sur les champs tabulaires dans des modèles personnalisés, consultez les champs tabulaires.
- La sortie du modèle de facture inclut désormais des paires clé-valeur de document général. Lorsque les factures contiennent des champs requis au-delà des champs inclus dans le modèle prédéfini, le modèle de document général complète la sortie avec des paires clé-valeur. Consultez paires clé-valeur.
- Extension des langues disponibles pour les factures. Le modèle de facture inclut la prise en charge étendu de langues. Consultez Langues prises en charge.
- La carte de visite prédéfinie inclut désormais la prise en charge de la langue japonaise. Consultez Langues prises en charge.
- Modèle de document d’ID prédéfini. Le modèle de document ID extrait à présent les éléments DateOfIssue, Height, Weight, EyeColor, HairColor et DocumentDiscriminator à partir des permis de conduire américains. Consultez extraction de champs.
- Le modèle de lecture prend désormais en charge les types de documents Microsoft Office courants. L’API Read prend désormais en charge les types de documents Word (docx), Excel (xlsx) et PowerPoint (pptx). Consultez Extraction de données avec Read.
Février 2022
Version 4.0.0-beta.3 (2022-02-10)
La préversion d’Intelligence documentaire v3.0 propose plusieurs nouvelles fonctionnalités et améliorations :
- Le Modèle neural personnalisé, ou modèle de document personnalisé, est un nouveau modèle personnalisé permettant d’extraire du texte et des marques de sélection de documents structurés, semi-structurés et non structurés.
- Le modèle prédéfini W-2 est un nouveau modèle prédéfini permettant d’extraire des champs des formulaires W-2 dans le cadre d’une déclaration fiscale et d’une vérification des revenus.
- L’API Read extrait les lignes de texte imprimé, les mots, les emplacements de texte, les langues détectées et le texte manuscrit, s’il détecté.
- Le modèle pré-entraîné Document général est maintenant mis à jour pour prendre en charge les marques de sélection, en plus du texte d’API, des tables, de la structure et des paires clé-valeur dans des formulaires et des documents.
- API de facture Le modèle prédéfini de facture étend la prise en charge aux factures en espagnol.
- Studio Intelligence documentaire ajoute de nouvelles démos pour Read, W2 et des exemples de reçus d’hôtel, ainsi que la prise en charge de l’entraînement de nouveaux modèles neuronaux personnalisés.
- Expansion de langues Les fonctionnalités Read, Disposition et Formulaire personnalisé de Intelligence documentaire prennent en charge 42 nouvelles langues, notamment l’arabe, l’hindi et d’autres langues utilisant des scripts arabes et dévanâgarîs, pour étendre la couverture à 164 langues. La prise en charge de la langue manuscrite s’étend au japonais et au coréen.
Prise en main de la nouvelle API de préversion v3.0.
Extraction de données avec les modèles Intelligence documentaire :
Modèle Extraction de texte Paires clé-valeur Marques de sélection Tables Signatures Lire ✓ Document général ✓ ✓ ✓ ✓ Layout ✓ ✓ ✓ Facture ✓ ✓ ✓ ✓ Réception ✓ ✓ ✓ Document d’identité ✓ ✓ Carte de visite ✓ ✓ Modèle personnalisé ✓ ✓ ✓ ✓ ✓ Modèle neuronal personnalisé ✓ ✓ ✓ ✓ Version préliminaire de la bêta du SDK Intelligence documentaire inclut les mises à jour suivantes :
Modes et modèles de document personnalisés :
- Modèle personnalisé (anciennement formulaire personnalisé).
- Modèle neuronal personnalisé.
- Modèle personnalisé : mode de génération.
Modèle prédéfini W-2 (prebuilt-tax.us.w2).
Modèle prédéfini de lecture (prebuilt-read).
Modèle prédéfini de facture (Espagnol) (prebuilt-invoice).
Étapes suivantes
Essayez de traiter vos propres formulaires et documents avec Document Intelligence Studio.
Effectuez un démarrage rapide Intelligence Documentaire et commencez à créer une application de traitement de documents dans le langage de développement de votre choix.
Essayez de traiter vos propres formulaires et documents avec l’outil d’étiquetage d’échantillons Intelligence Documentaire.
Effectuez un démarrage rapide Intelligence Documentaire et commencez à créer une application de traitement de documents dans le langage de développement de votre choix.