Démarrage rapide : classification de texte personnalisée
Utilisez cet article pour commencer à créer un projet de classification de texte personnalisée dans lequel vous pouvez effectuer l’apprentissage de modèles personnalisés pour la classification de texte. Un modèle est un logiciel d’intelligence artificielle qui est entraîné pour effectuer une tâche donnée. Pour ce système, les modèles classifient le texte et sont entraînés en apprenant à partir de données balisées.
La classification de texte personnalisée prend en charge deux types de projets :
- Classification avec une seule étiquette : vous pouvez attribuer une seule classe à chaque document de votre jeu de données. Par exemple, un script de film peut uniquement être classé comme « Romance » ou « Comedy ».
- Classification avec plusieurs étiquettes : vous pouvez attribuer plusieurs classes à chaque document de votre jeu de données. Par exemple, un script de film peut être classé comme « Comedy » ou « Romance » et « Comedy ».
Dans ce guide de démarrage rapide, vous pouvez utiliser les exemples de jeux de données fournis pour créer une classification multi-étiquette où vous pouvez classifier des scripts vidéo dans une ou plusieurs catégories, ou utiliser un jeu de données de classification d’étiquette unique où vous pouvez classifier des résumés de documents scientifiques dans l’un des domaines définis.
Prérequis
- Abonnement Azure : créez-en un gratuitement.
Créer une ressource Azure AI Language et un compte de stockage Azure
Avant de pouvoir utiliser la classification de texte personnalisée, vous devez créer une ressource Azure AI Language qui vous permettra de disposer des informations d’identification nécessaires pour créer un projet et commencer à entraîner un modèle. Vous aurez également besoin d’un compte de stockage Azure, où vous pourrez charger le jeu de données à utiliser pour générer votre modèle.
Important
Pour bien démarrer rapidement, nous vous recommandons de créer une ressource Azure AI Language en suivant les étapes fournies dans cet article. En suivant les étapes dans cet article, vous pourrez créer la ressource Language et le compte de stockage simultanément, ce qui s’avère être plus simple que si vous le faisiez ultérieurement.
Si vous disposez d’une ressource préexistante à utiliser, vous devez la connecter au compte de stockage.
Créer une ressource à partir du portail Azure
Accédez au Portail Azure pour créer une ressource Azure AI Language.
Dans la fenêtre qui s’affiche, sélectionnez Classification de texte personnalisée et reconnaissance d’entités nommées personnalisées dans les fonctionnalités personnalisées. Sélectionnez Continuer pour créer votre ressource en bas de l’écran.

Créez une ressource de langue avec les détails suivants.
Nom Valeur requise Abonnement Votre abonnement Azure. Resource group Un groupe de ressources comprenant votre ressource. Vous pouvez utiliser un groupe de resources existant ou en créer un. Région Une des régions prises en charge. Par exemple, « USA Ouest 2 ». Nom Nom de votre ressource. Niveau tarifaire Un des niveaux tarifaires pris en charge. Vous pouvez utiliser le niveau tarifaire gratuit (F0) pour tester le service. Si vous recevez un message indiquant « votre compte de connexion n’est pas propriétaire du groupe de ressources du compte de stockage sélectionné », votre compte doit avoir un rôle de propriétaire affecté sur le groupe de ressources avant de pouvoir créer une ressource Language. Pour obtenir de l’aide, contactez le propriétaire de votre abonnement Azure.
Vous pouvez déterminer le propriétaire de votre abonnement Azure en recherchant votre groupe de ressources et en suivant le lien vers l’abonnement associé. Ensuite :
- Sélectionnez l’onglet Contrôle d’accès (IAM).
- Sélectionnez Attributions de rôle.
- Filtrez par Rôle : Propriétaire.
Dans la section Classification de texte personnalisée et reconnaissance d’entités nommées personnalisées, sélectionnez un compte de stockage existant ou Nouveau compte de stockage. Notez que ces valeurs vous aident dans le cadre d’un démarrage rapide. Il ne s’agit pas des valeurs du compte de stockage à utiliser dans les environnements de production. Pour éviter la latence lors de la création de votre projet, connectez-vous à des comptes de stockage dans la même région que votre ressource de langue.
Valeur du compte de stockage Valeur recommandée Nom du compte de stockage Nom quelconque Type de compte de stockage LRS standard Vérifiez qu’Avis d’IA responsable est coché. Au bas de la page, sélectionnez Examiner et créer.

Charger les exemples de données dans un conteneur d’objets blob
Après avoir créé un compte de stockage Azure et l’avoir connecté à votre ressource de langue, vous devez charger les documents de l’exemple de jeu de données dans le répertoire racine de votre conteneur. Ces documents seront utilisés ultérieurement pour effectuer l’apprentissage de votre modèle.
Téléchargez l’exemple de jeu de données pour les projets de classification avec plusieurs étiquettes.
Ouvrez le fichier .zip et extrayez le dossier contenant les documents.
L’exemple de jeu de données fourni contient environ 200 documents, chacun étant le résumé d’un film. Chaque document appartient à une ou plusieurs des classes suivantes :
- « Mystère »
- « Drame »
- « Thriller »
- « Comédie »
- « Action »
Dans le Portail Azure, accédez au compte de stockage que vous avez créé et sélectionnez-le. Pour cela, cliquez sur Comptes de stockage et tapez le nom de votre compte de stockage dans Filtrer un champ.
Si votre groupe de ressources n’apparaît pas, vérifiez que le filtre Abonnement égal à est défini sur Tous.
Dans votre compte de stockage, sélectionnez Conteneurs dans le menu de gauche, situé sous Stockage de données. Dans l’écran qui s’affiche, sélectionnez + Conteneur. Donnez au conteneur le nom exemple de données et laissez le Niveau d’accès public par défaut.
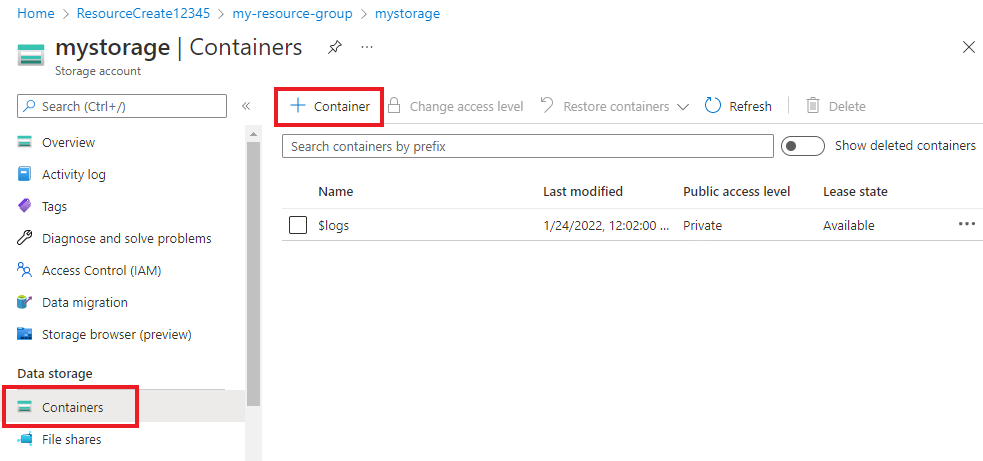
Une fois votre conteneur créé, sélectionnez-le. Sélectionnez ensuite le bouton Charger pour sélectionner les fichiers
.txtet.jsonque vous avez téléchargés précédemment.


Créer un projet de classification de texte personnalisée
Une fois votre ressource et votre conteneur de stockage configurés, créez un projet de classification de texte personnalisé. Un projet est une zone de travail qui vous permet de créer des modèles ML personnalisés en fonction de vos données. Seuls les utilisateurs qui disposent d’un accès à la ressource de langue utilisée peuvent accéder à votre projet.
Connectez-vous à Language Studio. Une fenêtre apparaît pour vous permettre de sélectionner votre abonnement et votre ressource Language. Sélectionnez votre ressource Language.
Dans la section Classifier du texte de Language Studio, sélectionnez Classification de texte personnalisée.

Sélectionnez Créer un projet dans le menu supérieur de la page des projets. La création d’un projet vous permet d’étiqueter les données, et d’entraîner, évaluer, améliorer et déployer vos modèles.

Une fois que vous avez cliqué sur Créer un projet, une fenêtre apparaît pour vous permettre de connecter votre compte de stockage. Si vous avez déjà connecté un compte de stockage, celui-ci s’affiche. Si ce n’est pas le cas, choisissez votre compte de stockage dans la liste déroulante qui s’affiche, puis sélectionnez Connecter le compte de stockage. Cette opération définit les rôles nécessaires pour votre compte de stockage. Cette étape peut retourner une erreur si le rôle propriétaire ne vous est pas attribué sur le compte de stockage.
Notes
- Vous ne devez effectuer cette étape qu’une seule fois pour chaque nouvelle ressource de langue utilisée.
- Ce processus est irréversible. Si vous connectez un compte de stockage à votre ressource de langue, il n’est pas possible de le déconnecter ultérieurement.
- Vous pouvez connecter votre ressource de langue à un seul compte de stockage.

Sélectionnez le type de projet. Vous pouvez créer un projet de Classification multi-étiquettes où chaque document peut appartenir à une ou plusieurs classes ou un projet de Classification avec une seule étiquette où chaque document peut appartenir à une classe uniquement. Le type sélectionné ne peut pas être modifié ultérieurement. En savoir plus sur les types de projets

Entrez les informations du projet, y compris un nom, une description et la langue des documents du projet. Si vous utilisez l’exemple de jeu de données, sélectionnez Anglais. Vous ne pourrez plus changer le nom de votre projet. Sélectionnez Suivant.
Conseil
Votre jeu de données n’a pas besoin d’être entièrement dans la même langue. Vous pouvez avoir plusieurs fichiers comportant des langues prises en charge différentes. Si votre jeu de données contient des documents en différentes langues ou si vous prévoyez des textes en d’autres langues au moment de l’exécution, sélectionnez l’option Activer un jeu de données multilingue quand vous entrez les informations de base de votre projet. Cette option peut être activée ultérieurement dans la page des Paramètres du projet.
Sélectionnez le conteneur dans lequel vous avez chargé votre jeu de données.
Notes
Si vous avez déjà étiqueté vos données, vérifiez qu’elles respectent le format pris en charge, sélectionnez Oui, mes documents comportent déjà des étiquettes et j’ai mis en forme le fichier d’étiquettes JSON, puis sélectionnez le fichier d’étiquettes dans le menu déroulant en dessous.
Si vous utilisez l’un des exemples de jeux de données, utilisez le fichier json
webOfScience_labelsFileoumovieLabelsinclus. Sélectionnez ensuite Suivant.Passez en revue les données entrées, puis sélectionnez Créer un projet.




Entraîner votre modèle
En règle générale, après avoir créé un projet, vous commencez par ajouter des étiquettes aux documents qui se trouvent dans le conteneur connecté à votre projet. Pour ce guide de démarrage rapide, vous avez importé un exemple de jeu de données étiqueté et vous avez initialisé votre projet avec l’exemple de fichier d’étiquettes JSON.
Pour commencer à effectuer l’apprentissage de votre modèle à partir de Language Studio :
Dans le menu de gauche, sélectionnez Travaux d’entraînement.
Sélectionnez Démarrer un travail de formation dans le menu supérieur.
Sélectionnez Effectuer l’apprentissage d’un nouveau modèle, puis tapez le nom du modèle dans la zone de texte. Vous pouvez également remplacer un modèle existant en sélectionnant cette option et le modèle de votre choix dans le menu déroulant. La remplacement d’un modèle entraîné est irréversible. Toutefois, cela n’affecte pas vos modèles déployés tant que vous ne déployez pas le nouveau modèle.

Sélectionnez la méthode de fractionnement des données. Vous pouvez choisir l’option Fractionnement automatique du jeu de test à partir des données d’apprentissage. Dans ce cas, le système fractionne vos données étiquetées en jeux d’apprentissage et de test, selon les pourcentages spécifiés. Vous pouvez également Utiliser un fractionnement manuel des données d’apprentissage et de test. Cette option est activée uniquement si vous avez ajouté des documents à votre jeu de tests lors de l’étiquetage des données. Pour plus d’informations sur le fractionnement des données, consultez Guide pratique pour effectuer l’apprentissage d’un modèle.
Sélectionner le bouton Train (Entraîner).
Si vous sélectionnez l’ID du travail d’apprentissage dans la liste, un volet latéral vous permet de vérifier la progression de la formation, l’état du travail et d’autres détails pour ce travail.
Notes
- Seuls les emplois de formation achevés avec succès génèrent des modèles.
- L’entraînement du modèle peut durer de quelques minutes à plusieurs heures selon la taille de vos données étiquetées.
- Vous ne pouvez avoir qu’un seul travail d’entraînement en cours d’exécution à la fois. Vous ne pouvez pas démarrer un autre travail d’apprentissage dans le même projet tant que le travail en cours d’exécution n’est pas terminé.

Déployer votre modèle
En règle générale, après l’apprentissage d’un modèle, vous passez en revue les détails de l’évaluation et vous apportez des améliorations, si nécessaire. Dans ce guide de démarrage rapide, vous allez simplement déployer votre modèle et le rendre disponible pour pouvoir l’essayer dans Language Studio. Vous pouvez également appeler l’API de prévision.
Pour déployer votre modèle à partir de Language Studio :
Dans le menu de gauche, sélectionnez Déploiement d’un modèle.
Sélectionnez Ajouter un déploiement pour démarrer un nouveau travail de déploiement.

Sélectionnez Créer un déploiement pour créer un déploiement et attribuer un modèle entraîné dans la liste déroulante ci-dessous. Vous pouvez également Remplacer un déploiement existant en sélectionnant cette option et en sélectionnant le modèle entraîné que vous souhaitez attribuer dans la liste déroulante ci-dessous.
Notes
Le remplacement d’un déploiement existant ne nécessite pas de modifier votre appel de l’API de prédiction. Toutefois, les résultats obtenus sont basés sur le modèle qui vient d’être attribué.

Sélectionnez Déployer pour démarrer le travail de déploiement.
Une fois le déploiement réussi, une date d’expiration s’affiche à côté de celui-ci. L’expiration du déploiement correspond au moment où votre modèle déployé n’est plus disponible pour la prédiction. Cela se produit généralement douze mois après l’expiration d’une configuration de l’apprentissage.


Tester votre modèle
Une fois votre modèle déployé, vous pouvez commencer à l’utiliser pour classifier votre texte via l’API de prédiction. Pour ce guide de démarrage rapide, vous utilisez Language Studio pour envoyer la tâche de classification de texte personnalisée et visualiser les résultats. Dans l’exemple de jeu de données que vous avez téléchargé précédemment, vous trouverez des documents de test que vous pouvez utiliser dans cette étape.
Pour tester vos modèles déployés dans Language Studio :
Sélectionnez Test des déploiements dans le menu situé à gauche de l’écran.
Sélectionnez le déploiement à tester. Vous pouvez uniquement tester les modèles qui sont attribués aux déploiements.
Pour les projets multilingues, sélectionnez la langue du texte que vous testez dans la liste déroulante de langue.
Sélectionnez le déploiement à interroger/tester dans la liste déroulante.
Entrez le texte que vous voulez soumettre dans la demande ou chargez un document
.txtà utiliser. Si vous utilisez l’un des exemples de jeux de données, vous pouvez utiliser l’un des fichiers .txt inclus.Sélectionnez Exécuter le test dans le menu supérieur.
Sous l’onglet Result, vous pouvez voir les classes prédites pour votre texte. Vous pouvez également afficher la réponse JSON sous l’onglet JSON. L’exemple suivant concerne un projet de classification mono-étiquette. Un projet de classification multi-étiquettes peut retourner plusieurs classes dans le résultat.


Nettoyer les projets
Une fois que vous n’avez plus besoin de votre projet, vous pouvez le supprimer à l’aide de Language Studio. Sélectionnez Classification de texte personnalisée en haut, et sélectionnez le projet à supprimer. Sélectionnez Supprimer dans le menu supérieur pour supprimer le projet.
Prérequis
- Abonnement Azure : créez-en un gratuitement.
Créer une ressource Azure AI Language et un compte de stockage Azure
Avant de pouvoir utiliser la classification de texte personnalisée, vous devez créer une ressource Azure AI Language qui vous permettra de disposer des informations d’identification nécessaires pour créer un projet et commencer à entraîner un modèle. Vous aurez également besoin d’un compte Stockage Azure, où vous pourrez charger le jeu de données à utiliser pour générer votre modèle.
Important
Pour démarrer rapidement, nous vous recommandons de créer une ressource Azure AI Language en procédant comme expliqué dans cet article. Vous pouvez ainsi créer la ressource Azure AI Language, puis créer et/ou connecter un compte de stockage simultanément, ce qui est plus simple que d’effectuer cette opération ultérieurement.
Si vous disposez d’une ressource préexistante à utiliser, vous devez la connecter au compte de stockage.
Créer une ressource à partir du portail Azure
Accédez au Portail Azure pour créer une ressource Azure AI Language.
Dans la fenêtre qui s’affiche, sélectionnez Classification de texte personnalisée et reconnaissance d’entités nommées personnalisées dans les fonctionnalités personnalisées. Sélectionnez Continuer pour créer votre ressource en bas de l’écran.
Créez une ressource de langue avec les détails suivants.
Nom Valeur requise Abonnement Votre abonnement Azure. Resource group Un groupe de ressources comprenant votre ressource. Vous pouvez utiliser un groupe de resources existant ou en créer un. Région Une des régions prises en charge. Par exemple, « USA Ouest 2 ». Nom Nom de votre ressource. Niveau tarifaire Un des niveaux tarifaires pris en charge. Vous pouvez utiliser le niveau tarifaire gratuit (F0) pour tester le service. Si vous recevez un message indiquant « votre compte de connexion n’est pas propriétaire du groupe de ressources du compte de stockage sélectionné », votre compte doit avoir un rôle de propriétaire affecté sur le groupe de ressources avant de pouvoir créer une ressource Language. Pour obtenir de l’aide, contactez le propriétaire de votre abonnement Azure.
Vous pouvez déterminer le propriétaire de votre abonnement Azure en recherchant votre groupe de ressources et en suivant le lien vers l’abonnement associé. Ensuite :
- Sélectionnez l’onglet Contrôle d’accès (IAM).
- Sélectionnez Attributions de rôle.
- Filtrez par Rôle : Propriétaire.
Dans la section Classification de texte personnalisée et reconnaissance d’entités nommées personnalisées, sélectionnez un compte de stockage existant ou Nouveau compte de stockage. Notez que ces valeurs vous aident dans le cadre d’un démarrage rapide. Il ne s’agit pas des valeurs du compte de stockage à utiliser dans les environnements de production. Pour éviter la latence lors de la création de votre projet, connectez-vous à des comptes de stockage dans la même région que votre ressource de langue.
Valeur du compte de stockage Valeur recommandée Nom du compte de stockage Nom quelconque Type de compte de stockage LRS standard Vérifiez qu’Avis d’IA responsable est coché. Au bas de la page, sélectionnez Examiner et créer.
Charger les exemples de données dans un conteneur d’objets blob
Après avoir créé un compte de stockage Azure et l’avoir connecté à votre ressource de langue, vous devez charger les documents de l’exemple de jeu de données dans le répertoire racine de votre conteneur. Ces documents seront utilisés ultérieurement pour effectuer l’apprentissage de votre modèle.
Téléchargez l’exemple de jeu de données pour les projets de classification avec plusieurs étiquettes.
Ouvrez le fichier .zip et extrayez le dossier contenant les documents.
L’exemple de jeu de données fourni contient environ 200 documents, chacun étant le résumé d’un film. Chaque document appartient à une ou plusieurs des classes suivantes :
- « Mystère »
- « Drame »
- « Thriller »
- « Comédie »
- « Action »
Dans le Portail Azure, accédez au compte de stockage que vous avez créé et sélectionnez-le. Pour cela, cliquez sur Comptes de stockage et tapez le nom de votre compte de stockage dans Filtrer un champ.
Si votre groupe de ressources n’apparaît pas, vérifiez que le filtre Abonnement égal à est défini sur Tous.
Dans votre compte de stockage, sélectionnez Conteneurs dans le menu de gauche, situé sous Stockage de données. Dans l’écran qui s’affiche, sélectionnez + Conteneur. Donnez au conteneur le nom exemple de données et laissez le Niveau d’accès public par défaut.
Une fois votre conteneur créé, sélectionnez-le. Sélectionnez ensuite le bouton Charger pour sélectionner les fichiers
.txtet.jsonque vous avez téléchargés précédemment.
Récupération des clés et du point de terminaison de la ressource
Accédez à la page de vue d’ensemble de votre ressource dans le portail Azure
Dans le menu de gauche, sélectionnez Clés et point de terminaison. Vous utilisez le point de terminaison et la clé pour les demandes d’API

Créer un projet de classification de texte personnalisée
Une fois votre ressource et votre conteneur de stockage configurés, créez un projet de classification de texte personnalisé. Un projet est une zone de travail qui vous permet de créer des modèles ML personnalisés en fonction de vos données. Seuls les utilisateurs qui disposent d’un accès à la ressource de langue utilisée peuvent accéder à votre projet.
Déclencher un travail d’importation de projet
Soumettez une demande POST en utilisant l’URL, les en-têtes et le corps JSON suivants pour importer votre fichier d’étiquettes. Vérifiez que votre fichier d’étiquettes respecte le format accepté.
Si un projet portant le même nom existe déjà, les données de ce projet sont remplacées.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | myProject |
{API-VERSION} |
Version de l’API que vous appelez. La valeur référencée ici concerne la dernière version publiée. En savoir plus sur les autres versions d’API disponibles | 2022-05-01 |
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé | Valeur |
|---|---|
Ocp-Apim-Subscription-Key |
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
body
Utilisez le code JSON suivant dans votre demande. Remplacez les valeurs d’espace réservé suivantes par vos valeurs :
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customMultiLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class2"
}
]
}
]
}
}
| Clé | Espace réservé | Valeur | Exemple |
|---|---|---|---|
| api-version | {API-VERSION} |
Version de l’API que vous appelez. La version utilisée ici doit être la même version d’API dans l’URL. En savoir plus sur les autres versions d’API disponibles | 2022-05-01 |
| projectName | {PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | myProject |
| projectKind | customMultiLabelClassification |
Type de projet. | customMultiLabelClassification |
| langage | {LANGUAGE-CODE} |
Chaîne spécifiant le code de langue des documents utilisés dans votre projet. Si votre projet est un projet multilingue, choisissez le code de langue de la majorité des documents. Consultez Prise en charge de la langue pour en savoir plus sur la prise en charge multilingue. | en-us |
| multilingue | true |
Valeur booléenne permettant à l’ensemble de données de contenir des documents dans plusieurs langues. Quand votre modèle est déployé, vous pouvez interroger le modèle dans n’importe quelle langue prise en charge (pas nécessairement incluse dans vos documents d’apprentissage). Consultez Prise en charge de la langue pour en savoir plus sur la prise en charge multilingue. | true |
| storageInputContainerName | {CONTAINER-NAME} |
Nom du conteneur de stockage Azure dans lequel vous avez chargé vos documents. | myContainer |
| Classes | [] | Tableau contenant l’ensemble des classes contenues dans le projet. Il s’agit des classes selon lesquelles vous souhaitez classifier vos documents. | [] |
| dans des documents | [] | Tableau contenant tous les documents de votre projet et les classes étiquetées pour ce document. | [] |
| location | {DOCUMENT-NAME} |
Emplacement des documents dans le conteneur de stockage. Étant donné que tous les documents se trouvent à la racine du conteneur, il doit s’agir du nom du document. | doc1.txt |
| dataset | {DATASET} |
Jeu de test où ce document va être placé lors du fractionnement avant l’entraînement. Pour plus d’informations, consultez Guide pratique pour effectuer l’apprentissage d’un modèle. Les valeurs possibles pour cette propriété sont Train et Test. |
Train |
Une fois que vous avez envoyé votre requête API, vous recevez une réponse 202 indiquant que le travail a été envoyé correctement. Dans les en-têtes de réponse, extrayez la valeur operation-location. Elle est au format suivant :
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} est utilisé pour identifier votre demande, car cette opération est asynchrone. Vous utilisez cette URL à l’étape suivante pour obtenir l’état du travail d’importation.
Scénarios d’erreur possibles pour cette requête :
- La ressource sélectionnée n’a pas les autorisations appropriées pour le compte de stockage.
- Le
storageInputContainerNamespécifié n’existe pas. - Le code de langue utilisé est non valide ou si le type de code de langue n’est pas une chaîne.
- La valeur
multilingualest une chaîne et non pas une valeur booléenne.
Obtient l’état du travail d’importation
Utilisez la requête GET suivante pour obtenir l’état de votre projet d’importation. Remplacez les valeurs d’espace réservé suivantes par vos valeurs :
URL de la demande
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | myProject |
{JOB-ID} |
ID de localisation de l’état d’entraînement de votre modèle. Il s’agit de la valeur d’en-tête location que vous avez reçue à l’étape précédente. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Version de l’API que vous appelez. La valeur référencée ici concerne la dernière version publiée. En savoir plus sur les autres versions d’API disponibles | 2022-05-01 |
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé | Valeur |
|---|---|
Ocp-Apim-Subscription-Key |
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
Entraîner votre modèle
En règle générale, après avoir créé un projet, vous commencez à ajouter des étiquettes aux documents qui se trouvent dans le conteneur connecté à votre projet. Pour ce guide de démarrage rapide, vous avez importé un exemple de jeu de données étiqueté et initialisé votre projet avec l’exemple de fichier de balises JSON.
Commencer l’entraînement de votre modèle
Une fois votre projet importé, vous pouvez commencer l’apprentissage de votre modèle.
Envoyez une requête POST en utilisant l’URL, les en-têtes et le corps JSON suivants pour envoyer un travail de formation. Remplacez les valeurs d’espace réservé suivantes par vos valeurs :
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | myProject |
{API-VERSION} |
Version de l’API que vous appelez. La valeur référencée ici concerne la dernière version publiée. En savoir plus sur les autres versions d’API disponibles | 2022-05-01 |
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé | Valeur |
|---|---|
Ocp-Apim-Subscription-Key |
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
Corps de la demande
Utilisez le code JSON suivant dans le corps de la demande. Le modèle reçoit le {MODEL-NAME} une fois l’apprentissage effectué. Seuls les travaux d’apprentissage réussis produisent des modèles.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Clé | Espace réservé | Valeur | Exemple |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Nom attribué à votre modèle une fois l’apprentissage réussi. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Il s’agit de la version du modèle utilisée pour effectuer l’apprentissage du modèle. | 2022-05-01 |
| evaluationOptions | Option permettant de fractionner vos données entre des jeux d’apprentissage et de test. | {} |
|
| kind | percentage |
Méthodes de fractionnement. Les valeurs possibles sont percentage ou manual. Pour plus d’informations, consultez Guide pratique pour effectuer l’apprentissage d’un modèle. |
percentage |
| trainingSplitPercentage | 80 |
Pourcentage de vos données étiquetées à inclure dans le jeu d’apprentissage. La valeur recommandée est 80. |
80 |
| testingSplitPercentage | 20 |
Pourcentage de vos données étiquetées à inclure dans le jeu de test. La valeur recommandée est 20. |
20 |
Notes
Les trainingSplitPercentage et testingSplitPercentage sont nécessaires uniquement si Kind est défini sur percentage. La somme des deux pourcentages doit être égale à 100.
Une fois que vous avez envoyé votre requête API, vous recevez une réponse 202 indiquant que le travail a été envoyé correctement. Dans les en-têtes de réponse, extrayez la valeur location. Elle est au format suivant :
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} sert à identifier votre demande, car cette opération est asynchrone. Vous pouvez utiliser cette URL pour obtenir l’état de l’apprentissage.
Obtenir l’état des travaux d’apprentissage
La formation peut prendre entre 10 et 30 minutes. Vous pouvez utiliser la requête suivante pour continuer à interroger l’état du travail d’apprentissage jusqu’à ce qu’il soit effectué avec succès.
Utilisez la requête GET suivante pour obtenir l’état de progression du processus d’apprentissage de votre modèle. Remplacez les valeurs d’espace réservé suivantes par vos valeurs :
URL de la demande
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | myProject |
{JOB-ID} |
ID de localisation de l’état d’entraînement de votre modèle. Il s’agit de la valeur d’en-tête location que vous avez reçue à l’étape précédente. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Version de l’API que vous appelez. La valeur référencée ici concerne la dernière version publiée. Pour plus d’informations sur les autres versions d’API disponibles, consultez Cycle de vie du modèle. | 2022-05-01 |
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé | Valeur |
|---|---|
Ocp-Apim-Subscription-Key |
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
Corps de la réponse
Une fois que vous avez envoyé la demande, vous recevez la réponse suivante.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Déployer votre modèle
En règle générale, après l’entraînement d’un modèle, vous passez en revue les détails de l’évaluation et vous apportez des améliorations si nécessaire. Dans ce guide de démarrage rapide, vous allez simplement déployer votre modèle et le rendre disponible pour pouvoir l’essayer dans Language Studio. Vous pouvez également appeler l’API de prévision.
Envoyer un travail de déploiement
Envoyez une requête PUT en utilisant l’URL, les en-têtes et le corps JSON suivants pour envoyer un travail de déploiement. Remplacez les valeurs d’espace réservé suivantes par vos valeurs :
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | myProject |
{DEPLOYMENT-NAME} |
Nom de votre déploiement. Cette valeur respecte la casse. | staging |
{API-VERSION} |
Version de l’API que vous appelez. La valeur référencée ici concerne la dernière version publiée. En savoir plus sur les autres versions d’API disponibles | 2022-05-01 |
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé | Valeur |
|---|---|
Ocp-Apim-Subscription-Key |
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
Corps de la demande
Utilisez le code JSON suivant dans le corps de la demande. Utilisez le nom du modèle que vous attribuez au déploiement.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Clé | Espace réservé | Valeur | Exemple |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Nom du modèle qui est attribué à votre déploiement. Vous pouvez uniquement attribuer des modèles entraînés avec succès. Cette valeur respecte la casse. | myModel |
Une fois que vous avez envoyé votre requête API, vous recevez une réponse 202 indiquant que le travail a été envoyé correctement. Dans les en-têtes de réponse, extrayez la valeur operation-location. Elle est au format suivant :
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} sert à identifier votre demande, car cette opération est asynchrone. Vous pouvez utiliser cette URL pour obtenir l’état du déploiement.
Obtenir l’état du travail de déploiement
Utilisez la requête GET suivante pour interroger l’état du processus de déploiement de votre modèle. Vous pouvez utiliser l’URL que vous avez reçue à l’étape précédente ou remplacer les valeurs d’espace réservé ci-dessous par vos propres valeurs.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | myProject |
{DEPLOYMENT-NAME} |
Nom de votre déploiement. Cette valeur respecte la casse. | staging |
{JOB-ID} |
ID de localisation de l’état d’entraînement de votre modèle. Il s’agit de la valeur d’en-tête location que vous avez reçue à l’étape précédente. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Version de l’API que vous appelez. La valeur référencée ici concerne la dernière version publiée. En savoir plus sur les autres versions d’API disponibles | 2022-05-01 |
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé | Valeur |
|---|---|
Ocp-Apim-Subscription-Key |
Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
Corps de la réponse
Une fois que vous avez envoyé la demande, vous recevez la réponse suivante. Continuez à interroger ce point de terminaison jusqu’à ce que le paramètre status passe à « réussi ». Vous devez normalement obtenir un code 200 pour indiquer la réussite de la demande.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Classifier le texte
Une fois votre modèle déployé avec succès, vous pouvez commencer à l’utiliser pour classifier votre texte via l’API de prédiction. Dans l’exemple de jeu de données que vous avez téléchargé précédemment, vous trouverez des documents de test que vous pouvez utiliser dans cette étape.
Envoyer une tâche de classification de texte personnalisée
Utilisez cette requête POST pour démarrer une tâche de classification de texte.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Version de l’API que vous appelez. La valeur référencée ici concerne la dernière version publiée. Pour plus d’informations sur les autres versions d’API disponibles, consultez Cycle de vie du modèle. | 2022-05-01 |
headers
| Clé | active |
|---|---|
| Ocp-Apim-Subscription-Key | Clé qui fournit l’accès à cette API. |
body
{
"displayName": "Classifying documents",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Clé | Espace réservé | Valeur | Exemple |
|---|---|---|---|
displayName |
{JOB-NAME} |
Nom de votre travail. | MyJobName |
documents |
[{},{}] | Liste des documents sur lesquels exécuter des tâches. | [{},{}] |
id |
{DOC-ID} |
Nom ou ID du document. | doc1 |
language |
{LANGUAGE-CODE} |
Chaîne spécifiant le code de langue du document. Si cette clé n’est pas spécifiée, le service adoptera la langue par défaut du projet qui a été sélectionnée lors de la création du projet. Pour obtenir la liste des codes de langue pris en charge, consultez Prise en charge linguistique. | en-us |
text |
{DOC-TEXT} |
Tâche de document sur laquelle exécuter les tâches. | Lorem ipsum dolor sit amet |
tasks |
Liste des tâches à effectuer. | [] |
|
taskName |
CustomMultiLabelClassification | Nom de la tâche | CustomMultiLabelClassification |
parameters |
Liste de paramètres à passer à la tâche. | ||
project-name |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Nom de votre déploiement. Cette valeur respecte la casse. | prod |
response
Vous recevez une réponse 202 indiquant la réussite. Dans les en-têtes de réponse, extrayez operation-location.
operation-location est au format suivant :
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
Vous pouvez utiliser cette URL pour interroger l’état d’achèvement de la tâche et obtenir les résultats une fois la tâche terminée.
Obtenir les résultats de la tâche
Utilisez la requête GET suivante pour interroger l’état/les résultats de la tâche de classification de texte.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Version de l’API que vous appelez. La valeur référencée ici correspond à la dernière version du modèle publiée. | 2022-05-01 |
headers
| Clé | active |
|---|---|
| Ocp-Apim-Subscription-Key | Clé qui fournit l’accès à cette API. |
Response body
La réponse est un document JSON avec les paramètres suivants.
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxxxx-xxxxx-xxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "customMultiClassificationTasks",
"taskName": "Classify documents",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "{DOC-ID}",
"classes": [
{
"category": "Class_1",
"confidenceScore": 0.0551877357
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Nettoyer les ressources
Quand vous n’avez plus besoin de votre projet, vous pouvez le supprimer avec la demande DELETE suivante. Remplacez les valeurs d’espace réservé par vos propres valeurs.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Espace réservé | Valeur | Exemple |
|---|---|---|
{ENDPOINT} |
Point de terminaison pour l’authentification de votre demande d’API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nom de votre projet. Cette valeur respecte la casse. | myProject |
{API-VERSION} |
Version de l’API que vous appelez. La valeur référencée ici concerne la dernière version publiée. En savoir plus sur les autres versions d’API disponibles | 2022-05-01 |
headers
Utilisez l’en-tête suivant pour authentifier votre demande.
| Clé | active |
|---|---|
| Ocp-Apim-Subscription-Key | Clé de votre ressource. Utilisée pour authentifier vos demandes d’API. |
Une fois que vous avez envoyé votre requête API, vous recevez une réponse 202 indiquant la réussite, ce qui signifie que votre projet a été supprimé. Un appel réussi donne un en-tête Operation-Location utilisé pour vérifier l’état du travail.
Étapes suivantes
Une fois que vous avez créé un modèle de classification de texte personnalisée, vous pouvez :
Quand vous commencez à créer vos propres projets de classification de texte personnalisée, utilisez les guides pratiques pour en savoir plus sur le développement de votre modèle plus en détail :