Tutoriel : Utiliser Personalizer dans Azure Notebook
Important
À compter du 20 septembre 2023, vous ne pourrez pas créer de ressources Personalizer. Le service Personalizer est mis hors service le 1er octobre 2026.
Ce tutoriel exécute une boucle Personalizer dans un notebook Azure, illustrant le cycle de vie de bout en bout d’une boucle Personalizer.
La boucle suggère le type de café qu’un client doit commander. Les utilisateurs et leurs préférences sont stockés dans un jeu de données d’utilisateurs. Des informations sur le café sont stockées dans un jeu de données de cafés.
Utilisateurs et café
Le notebook, qui simule l’interaction utilisateur avec un site web, sélectionne un utilisateur aléatoire, l’heure de la journée et le type de météo dans le jeu de données. Voici un résumé des informations sur les utilisateurs :
| Clients - caractéristiques de contexte | Heures de la journée | Types de météo |
|---|---|---|
| Alice Bob Cathy Dave |
Matin Après-midi Soir |
Ensoleillé Pluvieux Neige |
Pour aider Personalizer à apprendre, au fil du temps, le système connaît également les détails concernant la sélection de café de chaque personne.
| Café - caractéristiques d’action | Types d’entités temperature | Lieu d’origine | Type de torréfaction | Bio |
|---|---|---|---|---|
| Cappuccino | À chaud | Kenya | Foncé | Bio |
| Infusion à froid | Froid | Brésil | Léger | Bio |
| Moka frappée | Froid | Éthiopie | Léger | Non bio |
| Latte | À chaud | Brésil | Foncé | Non bio |
L’objectif de la boucle Personalizer est de trouver le plus souvent possible la meilleure correspondance entre les utilisateurs et le café.
Le code de ce tutoriel est disponible dans le dépôt GitHub d’exemples Personalizer.
Fonctionnement de la simulation
Au début, seules 20 à 30 % des suggestions de Personalizer sont correctes. Cette réussite est indiquée par la récompense renvoyée à l’API Reward de Personalizer, avec un score de 1. Après un certain nombre d’appels de classement et de récompense, le système s’améliore.
Après les requêtes initiales, exécutez une évaluation hors connexion. Cela permet à Personalizer d’examiner les données et de suggérer une meilleure stratégie d’apprentissage. Appliquez la nouvelle stratégie d’apprentissage et réexécutez le notebook avec 20 % du nombre de requêtes précédentes. La boucle sera plus performante avec la nouvelle stratégie d’apprentissage.
Appels de classement et de récompense
Pour chacun des quelques milliers d’appels au service Personalizer, le notebook Azure envoie la requête de classement à l’API REST :
- Un ID unique de l’événement de classement/requête
- Caractéristiques de contexte : un choix aléatoire d’utilisateur, de météo et d’heure de la journée, simulant un utilisateur sur un site web ou un appareil mobile
- Actions avec caractéristiques : toutes les données sur le café, à partir desquelles Personalizer fait une suggestion
Le système reçoit la demande, puis compare cette prédiction avec le choix connu de l’utilisateur pour la même heure de la journée et la même météo. Si le choix connu est le même que le choix prédit, la récompense de 1 est renvoyée à Personalizer. Sinon, la récompense renvoyée est 0.
Notes
S’agissant d’une simulation, l’algorithme de récompense est simple. Dans un scénario réel, l’algorithme doit utiliser une logique métier, éventuellement avec des pondérations pour différents aspects de l’expérience du client, afin de déterminer le score de récompense.
Prérequis
- Un compte Azure Notebook
- Une ressource Azure AI Personalizer.
- Si vous avez déjà utilisé la ressource Personalizer, veillez à effacer les données dans le portail Azure pour la ressource.
- Charger tous les fichiers de cet exemple dans un projet Azure Notebook
Descriptions des fichiers :
- Personalizer.ipynb est le notebook Jupyter pour ce tutoriel.
- Le jeu de données d’utilisateurs est stocké dans un objet JSON.
- Le jeu de données de cafés est stocké dans un objet JSON.
- L’exemple de requête JSON est le format attendu pour une requête POST à l’API de classement.
Configurer la ressource Personalizer
Dans le portail Azure, configurez votre ressource Personalizer avec la fréquence de mise à jour du modèle définie sur 15 secondes et une durée d’attente de la récompense de 10 minutes. Ces valeurs figurent dans la page Configuration .
| Paramètre | Valeur |
|---|---|
| Fréquence de mise à jour du modèle | 15 secondes |
| Durée d’attente de la récompense | 10 minutes |
Ces valeurs sont très brèves afin de pouvoir observer les changements dans ce tutoriel. Vous ne devez pas les utiliser dans un scénario de production sans avoir vérifié qu’elles vous permettent d’atteindre votre objectif avec votre boucle Personalizer.
Configurer le notebook Azure
- Remplacez le noyau par
Python 3.6. - Ouvrez le fichier
Personalizer.ipynb.
Exécuter les cellules du notebook
Exécutez chaque cellule exécutable et attendez qu’elle retourne. Vous savez qu’elle est terminée quand les crochets à côté de la cellule affichent un nombre au lieu de *. Les sections suivantes expliquent ce que fait chaque cellule programmatiquement et ce qui est attendu pour la sortie.
Inclure les modules Python
Incluez les modules Python requis. La cellule n’a pas de sortie.
import json
import matplotlib.pyplot as plt
import random
import requests
import time
import uuid
Définir le nom et la clé de ressource Personalizer
À partir du portail Azure, recherchez votre clé et votre point de terminaison dans la page Démarrage rapide de votre ressource Personalizer. Remplacez la valeur de <your-resource-name> par le nom de votre ressource Personalizer. Remplacez la valeur de <your-resource-key> par votre clé Personalizer.
# Replace 'personalization_base_url' and 'resource_key' with your valid endpoint values.
personalization_base_url = "https://<your-resource-name>.cognitiveservices.azure.com/"
resource_key = "<your-resource-key>"
Imprimer la date et l’heure actuelles
Utilisez cette fonction pour noter les heures de début et de fin de la fonction itérative.
Ces cellules n’ont pas de sortie. La fonction génère la date et l’heure actuelles quand elle est appelée.
# Print out current datetime
def currentDateTime():
currentDT = datetime.datetime.now()
print (str(currentDT))
Obtenir l’heure de la dernière mise à jour du modèle
Quand la fonction get_last_updated est appelée, elle imprime la date et l’heure de la dernière modification du modèle.
Ces cellules n’ont pas de sortie. La fonction génère la date du dernier entraînement du modèle quand elle est appelée.
La fonction utilise une API REST pour obtenir les propriétés du modèle.
# ititialize variable for model's last modified date
modelLastModified = ""
def get_last_updated(currentModifiedDate):
print('-----checking model')
# get model properties
response = requests.get(personalization_model_properties_url, headers = headers, params = None)
print(response)
print(response.json())
# get lastModifiedTime
lastModifiedTime = json.dumps(response.json()["lastModifiedTime"])
if (currentModifiedDate != lastModifiedTime):
currentModifiedDate = lastModifiedTime
print(f'-----model updated: {lastModifiedTime}')
Obtenir la configuration du service et de la stratégie
Validez l’état du service à l’aide de ces deux appels REST.
Ces cellules n’ont pas de sortie. La fonction génère les valeurs du service quand elle est appelée.
def get_service_settings():
print('-----checking service settings')
# get learning policy
response = requests.get(personalization_model_policy_url, headers = headers, params = None)
print(response)
print(response.json())
# get service settings
response = requests.get(personalization_service_configuration_url, headers = headers, params = None)
print(response)
print(response.json())
Construire des URL et lire des fichiers de données JSON
Cette cellule
- Génère les URL utilisées dans les appels REST.
- Définit l’en-tête de sécurité à l’aide de votre clé de ressource Personalizer.
- Définit la valeur de départ aléatoire pour l’ID d’événement de classement.
- Lit les fichiers de données JSON.
- Appelle la méthode
get_last_updated(la stratégie d’apprentissage a été supprimée dans l’exemple de sortie). - Appelle la méthode
get_service_settings.
La cellule contient la sortie de l’appel aux fonctions get_last_updated et get_service_settings.
# build URLs
personalization_rank_url = personalization_base_url + "personalizer/v1.0/rank"
personalization_reward_url = personalization_base_url + "personalizer/v1.0/events/" #add "{eventId}/reward"
personalization_model_properties_url = personalization_base_url + "personalizer/v1.0/model/properties"
personalization_model_policy_url = personalization_base_url + "personalizer/v1.0/configurations/policy"
personalization_service_configuration_url = personalization_base_url + "personalizer/v1.0/configurations/service"
headers = {'Ocp-Apim-Subscription-Key' : resource_key, 'Content-Type': 'application/json'}
# context
users = "users.json"
# action features
coffee = "coffee.json"
# empty JSON for Rank request
requestpath = "example-rankrequest.json"
# initialize random
random.seed(time.time())
userpref = None
rankactionsjsonobj = None
actionfeaturesobj = None
with open(users) as handle:
userpref = json.loads(handle.read())
with open(coffee) as handle:
actionfeaturesobj = json.loads(handle.read())
with open(requestpath) as handle:
rankactionsjsonobj = json.loads(handle.read())
get_last_updated(modelLastModified)
get_service_settings()
print(f'User count {len(userpref)}')
print(f'Coffee count {len(actionfeaturesobj)}')
Vérifiez que la valeur rewardWaitTime de la sortie est définie sur 10 minutes et que la valeur modelExportFrequency est définie sur 15 secondes.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:10:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:00:15', 'logRetentionDays': -1}
User count 4
Coffee count 4
Résolution des problèmes liés au premier appel REST
Cette cellule précédente est la première cellule qui appelle Personalizer. Vérifiez que le code d’état REST dans la sortie est <Response [200]>. Si vous recevez une erreur, telle que 404, mais que vous êtes sûr que la clé de ressource et le nom sont corrects, rechargez le notebook.
Vérifiez qu’il y a bien quatre cafés et quatre utilisateurs. Si vous recevez une erreur, vérifiez que vous avez chargé les trois fichiers JSON.
Configurer le graphique de métriques dans le portail Azure
Plus loin dans ce tutoriel, le processus longue durée des 10 000 requêtes est visible à partir du navigateur avec une zone de texte mise à jour. Il peut être plus simple d’afficher un graphique ou une somme totale pour savoir quand le processus longue durée se termine. Pour voir ces informations, utilisez les métriques fournies avec la ressource. Vous pouvez créer le graphique maintenant que vous avez terminé une requête adressée au service, puis actualiser le graphique régulièrement pendant le processus longue durée.
Dans le portail Azure, sélectionnez votre ressource Personalizer.
Dans la barre de navigation des ressources, sélectionnez Métriques sous Supervision.
Dans le graphique, sélectionnez Ajouter une métrique.
Les espaces de noms de ressources et de métriques sont déjà définis. Il vous suffit de sélectionner la métrique des appels ayant abouti et l’agrégation de somme.
Modifiez le filtre de temps sur les quatre dernières heures.
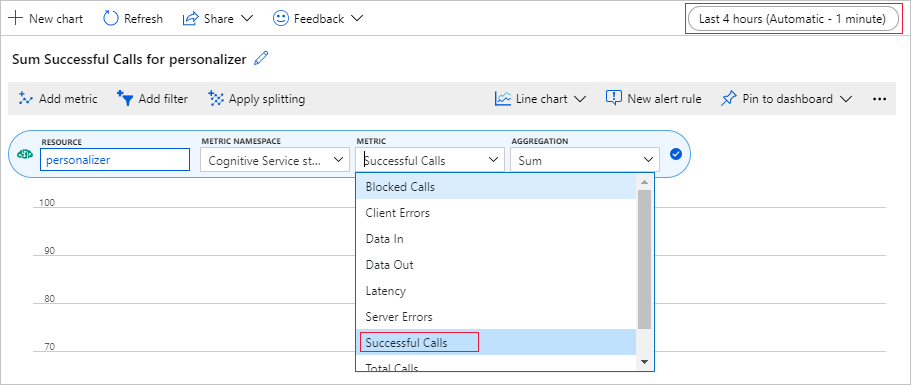
Vous devez voir trois appels ayant abouti dans le graphique.
Générer un ID d’événement unique
Cette fonction génère un ID unique pour chaque appel de classement. L’ID est utilisé pour identifier les informations d’appel de récompense et de classement. Cette valeur peut provenir d’un processus métier, tel qu’un ID de vue web ou un ID de transaction.
La cellule n’a pas de sortie. La fonction génère l’ID unique quand elle est appelée.
def add_event_id(rankjsonobj):
eventid = uuid.uuid4().hex
rankjsonobj["eventId"] = eventid
return eventid
Obtenir un utilisateur, une météo et une heure de la journée aléatoires
Cette fonction sélectionne un utilisateur, une météo et une heure de la journée, puis ajoute ces éléments à l’objet JSON à envoyer à la requête de classement.
La cellule n’a pas de sortie. Quand la fonction est appelée, elle retourne le nom de l’utilisateur aléatoire, la météo aléatoire et l’heure aléatoire de la journée.
La liste de quatre utilisateurs et leurs préférences (seules certaines préférences sont affichées par souci de concision) :
{
"Alice": {
"Sunny": {
"Morning": "Cold brew",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Bob": {
"Sunny": {
"Morning": "Cappucino",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Cathy": {
"Sunny": {
"Morning": "Latte",
"Afternoon": "Cold brew",
"Evening": "Cappucino"
}...
},
"Dave": {
"Sunny": {
"Morning": "Iced mocha",
"Afternoon": "Iced mocha",
"Evening": "Iced mocha"
}...
}
}
def add_random_user_and_contextfeatures(namesoption, weatheropt, timeofdayopt, rankjsonobj):
name = namesoption[random.randint(0,3)]
weather = weatheropt[random.randint(0,2)]
timeofday = timeofdayopt[random.randint(0,2)]
rankjsonobj['contextFeatures'] = [{'timeofday': timeofday, 'weather': weather, 'name': name}]
return [name, weather, timeofday]
Ajouter toutes les données sur les cafés
Cette fonction ajoute la liste entière de cafés à l’objet JSON à envoyer à la requête de classement.
La cellule n’a pas de sortie. La fonction modifie rankjsonobj quand elle est appelée.
Voici un exemple des caractéristiques d’un café :
{
"id": "Cappucino",
"features": [
{
"type": "hot",
"origin": "kenya",
"organic": "yes",
"roast": "dark"
}
}
def add_action_features(rankjsonobj):
rankjsonobj["actions"] = actionfeaturesobj
Comparer la prédiction avec la préférence connue de l’utilisateur
Cette fonction est appelée après l’appel de l’API de classement, pour chaque itération.
Elle compare la préférence de l’utilisateur en terme de café, en fonction de la météo et de l’heure de la journée, avec la suggestion de Personalizer pour l’utilisateur et pour ces filtres. Si la suggestion correspond, un score de 1 est retourné ; sinon, le score est 0. La cellule n’a pas de sortie. La fonction génère le score quand elle est appelée.
def get_reward_from_simulated_data(name, weather, timeofday, prediction):
if(userpref[name][weather][timeofday] == str(prediction)):
return 1
return 0
Parcourir les appels de classement et de récompense en boucle
La cellule suivante correspond au travail principal du notebook : obtenir un utilisateur aléatoire, obtenir la liste des cafés, envoyer ces deux informations à l’API de classement, comparer la prédiction avec les préférences connues de l’utilisateur, puis renvoyer la récompense au service Personalizer.
La boucle s’exécute num_requests fois. Personalizer a besoin de quelques milliers d’appels de classement et de récompense pour créer un modèle.
Voici un exemple de code JSON envoyé à l’API de classement. La liste des cafés n’est pas complète, par souci de concision. Vous pouvez voir la totalité du JSON pour le café dans coffee.json.
JSON envoyé à l’API de classement :
{
'contextFeatures':[
{
'timeofday':'Evening',
'weather':'Snowy',
'name':'Alice'
}
],
'actions':[
{
'id':'Cappucino',
'features':[
{
'type':'hot',
'origin':'kenya',
'organic':'yes',
'roast':'dark'
}
]
}
...rest of coffee list
],
'excludedActions':[
],
'eventId':'b5c4ef3e8c434f358382b04be8963f62',
'deferActivation':False
}
Réponse JSON de l’API de classement :
{
'ranking': [
{'id': 'Latte', 'probability': 0.85 },
{'id': 'Iced mocha', 'probability': 0.05 },
{'id': 'Cappucino', 'probability': 0.05 },
{'id': 'Cold brew', 'probability': 0.05 }
],
'eventId': '5001bcfe3bb542a1a238e6d18d57f2d2',
'rewardActionId': 'Latte'
}
Pour finir, chaque boucle affiche la sélection aléatoire d’utilisateur, de météo et d’heure de la journée, ainsi que la récompense déterminée. La récompense 1 indique que la ressource Personalizer a sélectionné le bon type de café pour l’utilisateur, la météo et l’heure de la journée donnés.
1 Alice Rainy Morning Latte 1
La fonction utilise :
- Classement : une API REST POST pour obtenir le classement.
- Récompense : une API REST POST pour indiquer la récompense.
def iterations(n, modelCheck, jsonFormat):
i = 1
# default reward value - assumes failed prediction
reward = 0
# Print out dateTime
currentDateTime()
# collect results to aggregate in graph
total = 0
rewards = []
count = []
# default list of user, weather, time of day
namesopt = ['Alice', 'Bob', 'Cathy', 'Dave']
weatheropt = ['Sunny', 'Rainy', 'Snowy']
timeofdayopt = ['Morning', 'Afternoon', 'Evening']
while(i <= n):
# create unique id to associate with an event
eventid = add_event_id(jsonFormat)
# generate a random sample
[name, weather, timeofday] = add_random_user_and_contextfeatures(namesopt, weatheropt, timeofdayopt, jsonFormat)
# add action features to rank
add_action_features(jsonFormat)
# show JSON to send to Rank
print('To: ', jsonFormat)
# choose an action - get prediction from Personalizer
response = requests.post(personalization_rank_url, headers = headers, params = None, json = jsonFormat)
# show Rank prediction
print ('From: ',response.json())
# compare personalization service recommendation with the simulated data to generate a reward value
prediction = json.dumps(response.json()["rewardActionId"]).replace('"','')
reward = get_reward_from_simulated_data(name, weather, timeofday, prediction)
# show result for iteration
print(f' {i} {currentDateTime()} {name} {weather} {timeofday} {prediction} {reward}')
# send the reward to the service
response = requests.post(personalization_reward_url + eventid + "/reward", headers = headers, params= None, json = { "value" : reward })
# for every N rank requests, compute total correct total
total = total + reward
# every N iteration, get last updated model date and time
if(i % modelCheck == 0):
print("**** 10% of loop found")
get_last_updated(modelLastModified)
# aggregate so chart is easier to read
if(i % 10 == 0):
rewards.append( total)
count.append(i)
total = 0
i = i + 1
# Print out dateTime
currentDateTime()
return [count, rewards]
Exécuter pour 10 000 itérations
Exécutez la boucle Personalizer pour 10 000 itérations. Il s’agit d’un événement de longue durée. Ne fermez pas le navigateur qui exécute le notebook. Actualisez régulièrement le graphique des métriques dans le portail Azure pour voir le nombre total d’appels au service. Quand vous avez environ 20 000 appels, un appel de classement et de récompense pour chaque itération de la boucle, les itérations sont terminées.
# max iterations
num_requests = 200
# check last mod date N% of time - currently 10%
lastModCheck = int(num_requests * .10)
jsonTemplate = rankactionsjsonobj
# main iterations
[count, rewards] = iterations(num_requests, lastModCheck, jsonTemplate)
Afficher un graphique des résultats pour voir l’amélioration
Créez un graphique à partir de count et rewards.
def createChart(x, y):
plt.plot(x, y)
plt.xlabel("Batch of rank events")
plt.ylabel("Correct recommendations per batch")
plt.show()
Exécuter le graphique pour 10 000 requêtes de classement
Exécutez la fonction createChart.
createChart(count,rewards)
Lecture du graphique
Ce graphique montre la réussite du modèle pour la stratégie d’apprentissage par défaut actuelle.
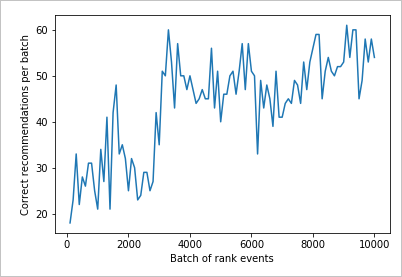
La cible idéale est qu’à la fin du test, la boucle obtienne un taux de réussite moyen proche de 100 % moins l’exploration. La valeur d’exploration par défaut est 20 %.
100-20=80
Cette valeur d’exploration figure dans le portail Azure pour la ressource Personalizer, dans la page Configuration.
Pour trouver une meilleure stratégie d’apprentissage, basée sur vos données envoyées à l’API de classement, exécutez une évaluation hors connexion dans le portail pour votre boucle Personalizer.
Exécuter une évaluation hors connexion
Dans le portail Azure, ouvrez la page Évaluations de la ressource Personalizer.
Sélectionnez Créer une évaluation.
Entrez les données requises (nom de l’évaluation et plage de dates pour l’évaluation de la boucle). La plage de dates doit inclure uniquement les jours sur lesquels vous vous concentrez pour votre évaluation.
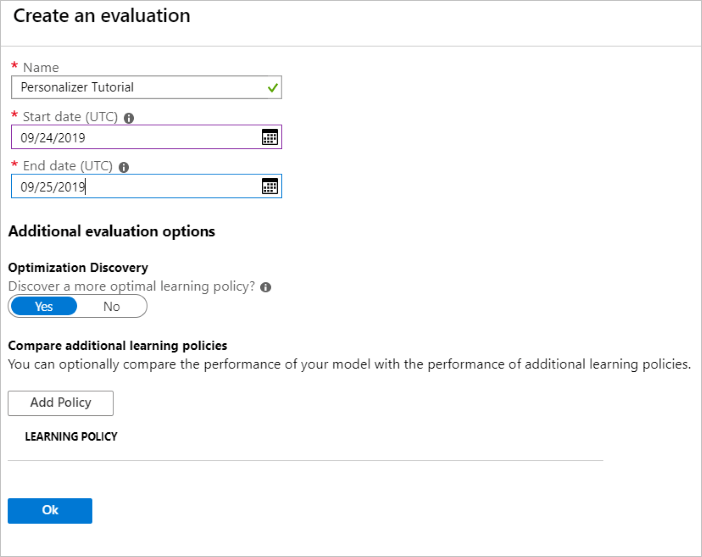
L’objectif de cette évaluation hors connexion est de déterminer s’il existe une meilleure stratégie d’apprentissage pour les caractéristiques et actions utilisées dans cette boucle. Pour trouver cette meilleure stratégie d’apprentissage, n’oubliez pas d’activer l’option Découverte d’optimisation.
Sélectionnez OK pour commencer l’évaluation.
Cette page Évaluations montre la nouvelle évaluation et son état actuel. En fonction de la quantité de données dont vous disposez, cette évaluation peut prendre un certain temps. Vous pouvez revenir à cette page après quelques minutes pour voir les résultats.
Une fois l’évaluation terminée, sélectionnez-la, puis sélectionnez Comparaison des différentes stratégies d’apprentissage. Cela montre les stratégies d’apprentissage disponibles et comment elles se comporteraient avec les données.
Sélectionnez la stratégie d’apprentissage qui figure en haut du tableau, puis sélectionnez Appliquer. La meilleure stratégie d’apprentissage est alors appliquée à votre modèle, et un nouvel entraînement est effectué.
Régler la fréquence de mise à jour du modèle sur cinq minutes
- Dans le portail Azure, toujours sur la ressource Personalizer, sélectionnez la page Configuration.
- Réglez la Fréquence de mise à jour du modèle et la Durée d’attente de la récompense sur cinq minutes et sélectionnez Enregistrer.
Apprenez-en davantage sur la durée d’attente de la récompense et sur la fréquence de mise à jour du modèle.
#Verify new learning policy and times
get_service_settings()
Vérifiez que les valeurs rewardWaitTime et modelExportFrequency de la sortie sont toutes deux définies sur cinq minutes.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:05:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:05:00', 'logRetentionDays': -1}
User count 4
Coffee count 4
Valider la nouvelle stratégie d’apprentissage
Revenez au fichier Azure Notebooks et continuez en exécutant la même boucle, mais seulement pendant 2000 itérations. Actualisez régulièrement le graphique des métriques dans le portail Azure pour voir le nombre total d’appels au service. Quand vous avez environ 4 000 appels, un appel de classement et de récompense pour chaque itération de la boucle, les itérations sont terminées.
# max iterations
num_requests = 2000
# check last mod date N% of time - currently 10%
lastModCheck2 = int(num_requests * .10)
jsonTemplate2 = rankactionsjsonobj
# main iterations
[count2, rewards2] = iterations(num_requests, lastModCheck2, jsonTemplate)
Exécuter le graphique pour 2 000 requêtes de classement
Exécutez la fonction createChart.
createChart(count2,rewards2)
Examiner le deuxième graphique
Le deuxième graphique doit montrer une augmentation visible de la correspondance entre les prédictions de classement et les préférences de l’utilisateur.
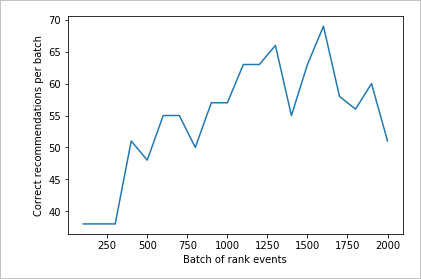
Nettoyer les ressources
Si vous n’envisagez pas de continuer la série de tutoriels, nettoyez les ressources suivantes :
- Supprimez votre projet Azure Notebook.
- Supprimez votre ressource Personalizer.
Étapes suivantes
Le notebook Jupyter et les fichiers de données utilisés dans cet exemple sont disponibles dans le dépôt GitHub pour Personalizer.