Tester la qualité de reconnaissance d’un modèle vocal personnalisé
Vous pouvez inspecter visuellement la qualité de la reconnaissance d’un modèle vocal personnalisé dans Speech Studio. Vous pouvez lire le contenu audio chargé pour déterminer si le résultat proposé de la reconnaissance est correct. Une fois qu’un test a été créé avec succès, vous pouvez voir comment un modèle transcrit le jeu de données audio ou comparer les résultats de deux modèles côte à côte.
Le test de modèles côte à côte est utile pour valider le modèle de reconnaissance vocale le mieux adapté à une application. Pour obtenir une mesure objective de la précision, qui nécessite une entrée de jeu de données de transcription, consultez le Modèle de test quantitativement.
Important
Lors des tests, le système effectue une transcription. Il est important de garder à l’esprit que les tarifs varient en fonction de l’offre de service et du niveau d’abonnement. Pour obtenir les informations les plus récentes, reportez-vous toujours aux tarifs officiels d’Azure AI services.
Créer un test
Pour créer un test, suivez ces instructions :
Connectez-vous à Speech Studio.
Accédez à Speech Studio>Vocal personnalisé et sélectionnez le nom de votre projet dans la liste.
Sélectionnez Tester des modèles>Créer un test.
Sélectionnez Inspect quality (Audio-only data) [Inspecter la qualité (données audio uniquement)]>Suivant.
Choisissez un jeu de données audio que vous souhaitez utiliser pour le test, puis sélectionnez Suivant. Si aucun jeu de données n’est disponible, annulez la configuration, puis accédez au menu Jeux de données Speech pour charger des jeux de données.
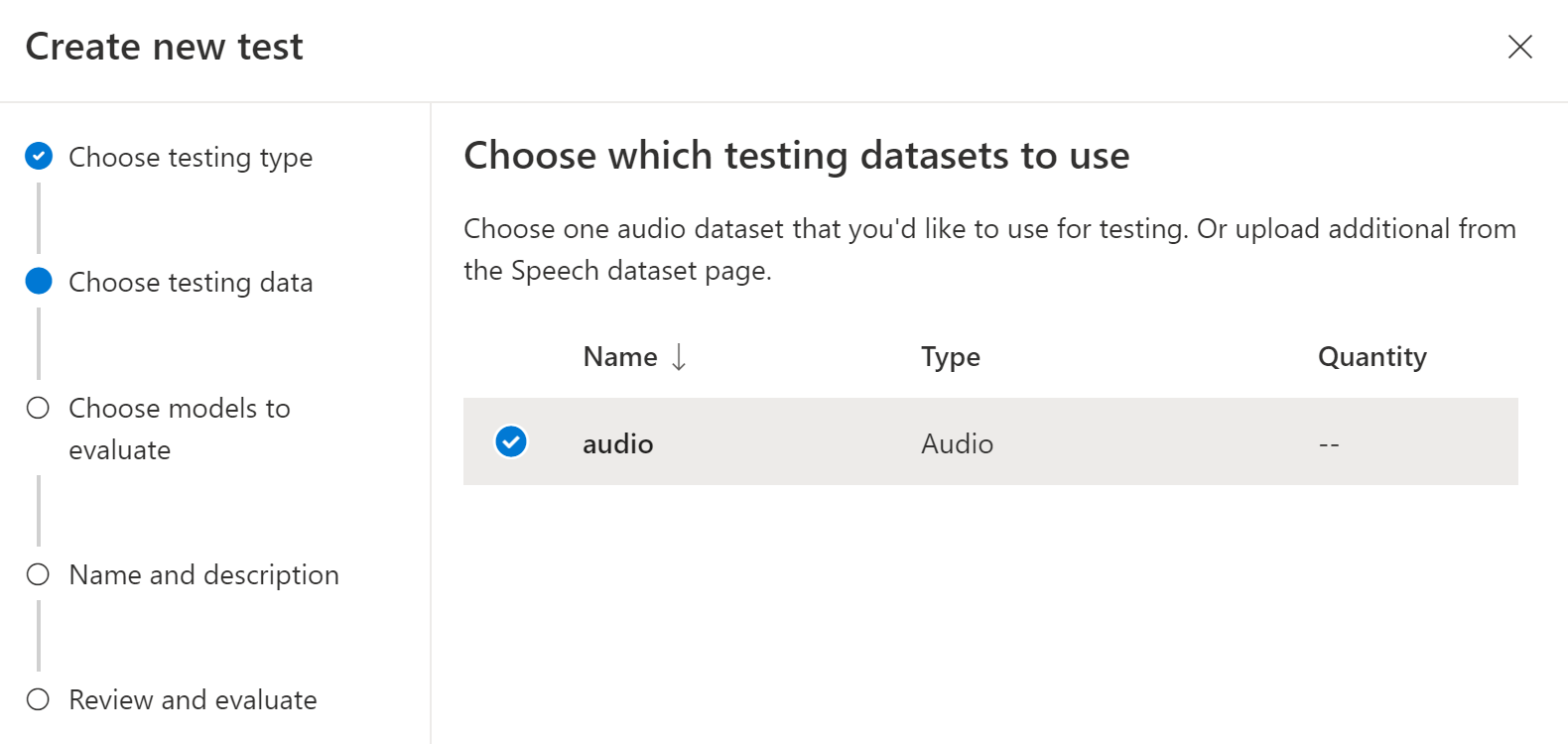
Choisissez un ou deux modèles pour évaluer et comparer la précision.
Entrez le nom et la description du test, puis sélectionnez Suivant.
Passez en revue vos paramètres, puis sélectionnez Enregistrer et fermer.
Pour créer un test, utilisez la commande spx csr evaluation create. Construisez les paramètres de la requête conformément aux instructions suivantes :
- Définissez le paramètre
projectsur l’ID d’un projet existant. Ce paramètre est recommandé afin que vous puissiez également voir le test dans Speech Studio. Vous pouvez exécuter la commandespx csr project listpour obtenir les projets disponibles. - Définissez le paramètre requis
model1sur l’ID d’un modèle que vous souhaitez tester. - Définissez le paramètre requis
model2sur l’ID d’un autre modèle que vous souhaitez tester. Si vous ne souhaitez pas comparer deux modèles, utilisez le même modèle pourmodel1etmodel2. - Définissez le paramètre requis
datasetsur l’ID d’un jeu de données que vous souhaitez utiliser pour le test. - Définissez le paramètre
language, sinon l’interface CLI Speech définit « en-US » par défaut. Ce paramètre doit être les paramètres régionaux du contenu du jeu de données. Vous ne pourrez plus changer de paramètres régionaux. Le paramètrelanguageCLI Speech correspond à la propriétélocaledans la requête et la réponse JSON. - Définissez le paramètre requis
name. Ce paramètre est le nom qui est affiché dans Speech Studio. Le paramètrenameCLI Speech correspond à la propriétédisplayNamedans la requête et la réponse JSON.
Voici un exemple de commande CLI Speech qui crée un test :
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 13fb305e-09ad-4bce-b3a1-938c9124dda3 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Inspection" --description "My Inspection Description"
Vous devriez recevoir un corps de réponse au format suivant :
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
La propriété self de niveau supérieur dans le corps de la réponse est l’URI de l’évaluation de données. Utilisez cet URI pour obtenir des détails sur les résultats du projet et des tests. Vous utilisez également cet URI pour mettre à jour ou supprimer l’évaluation.
Pour l’aide de l’interface CLI Speech avec les évaluations, exécutez la commande suivante :
spx help csr evaluation
Pour créer un test, utilisez l’opération Evaluations_Create de l’API REST de reconnaissance vocale. Construisez le corps de la requête conformément aux instructions suivantes :
- Définissez la propriété
projectsur l’URI d’un projet existant. Cette propriété est recommandée afin que vous puissiez également voir le test dans Speech Studio. Vous pouvez effectuer une requête Projects_List pour obtenir les projets disponibles. - Définissez la propriété requise
model1sur l’URI d’un modèle que vous souhaitez tester. - Définissez la propriété requise
model2sur l’URI d’un autre modèle que vous souhaitez tester. Si vous ne souhaitez pas comparer deux modèles, utilisez le même modèle pourmodel1etmodel2. - Définissez la propriété requise
datasetsur l’URI d’un jeu de données que vous souhaitez utiliser pour le test. - Définissez la propriété requise
locale. Cette propriété doit être les paramètres régionaux du contenu du jeu de données. Vous ne pourrez plus changer de paramètres régionaux. - Définissez la propriété requise
displayName. Cette propriété est le nom qui est affiché dans Speech Studio.
Effectuez une requête HTTP POST à l’aide de l’URI, comme illustré dans l’exemple suivant. Remplacez YourSubscriptionKey par votre clé de ressource Speech, remplacez YourServiceRegion par votre région de ressource Speech et définissez les propriétés du corps de la requête comme décrit précédemment.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Inspection",
"description": "My Inspection Description",
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
Vous devriez recevoir un corps de réponse au format suivant :
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:21:39Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
La propriété self de niveau supérieur dans le corps de la réponse est l’URI de l’évaluation de données. Utilisez cet URI pour obtenir des détails sur le projet d’évaluation et les résultats du test. Vous utilisez également cet URI pour mettre à jour ou supprimer l’évaluation.
Obtenir des résultats des tests
Vous devez obtenir les résultats des tests et inspecter les jeux de données audio par rapport aux résultats de transcription pour chaque modèle.
Suivez ces étapes pour obtenir les résultats des tests :
- Connectez-vous à Speech Studio.
- Sélectionnez Reconnaissance vocale personnalisée> Votre nom de projet >Tester des modèles.
- Sélectionnez le lien par nom de test.
- Une fois le test terminé, comme indiqué par l’état défini sur Réussite, vous devez voir les résultats qui incluent le numéro WER pour chaque modèle testé.
Cette page liste tous les énoncés de votre jeu de données et les résultats de la reconnaissance avec la transcription du jeu de données soumis. Vous pouvez voir les différents types d’erreurs (insertion, suppression et substitution). En écoutant l’audio et en comparant les résultats de la reconnaissance dans chaque colonne, vous pouvez identifier le modèle qui répond à vos besoins et déterminer où davantage d’entraînement et des améliorations s’imposent.
Pour obtenir les résultats des tests, utilisez la commande spx csr evaluation status. Construisez les paramètres de la requête conformément aux instructions suivantes :
- Définissez le paramètre requis
evaluationsur l’ID de l’évaluation que vous souhaitez obtenir les résultats des tests.
Voici un exemple de commande CLI Speech qui obtient les résultats des tests :
spx csr evaluation status --api-version v3.2 --evaluation 9c06d5b1-213f-4a16-9069-bc86efacdaac
Les modèles, le jeu de données audio, les transcriptions et plus de détails sont retournés dans le corps de la réponse.
Vous devriez recevoir un corps de réponse au format suivant :
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Pour l’aide de l’interface CLI Speech avec les évaluations, exécutez la commande suivante :
spx help csr evaluation
Pour obtenir les résultats des tests, commencez par utiliser l’opération Evaluations_Get de l’API REST de reconnaissance vocale.
Effectuez une requête HTTP GET à l’aide de l’URI, comme illustré dans l’exemple suivant. Remplacez YourEvaluationId par votre ID d’évaluation, remplacez YourSubscriptionKey par votre clé de ressource Speech et remplacez YourServiceRegion par votre région de ressource Speech.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey"
Les modèles, le jeu de données audio, les transcriptions et plus de détails sont retournés dans le corps de la réponse.
Vous devriez recevoir un corps de réponse au format suivant :
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/9c06d5b1-213f-4a16-9069-bc86efacdaac/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:22:45Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:21:39Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
Comparer la transcription avec l’audio
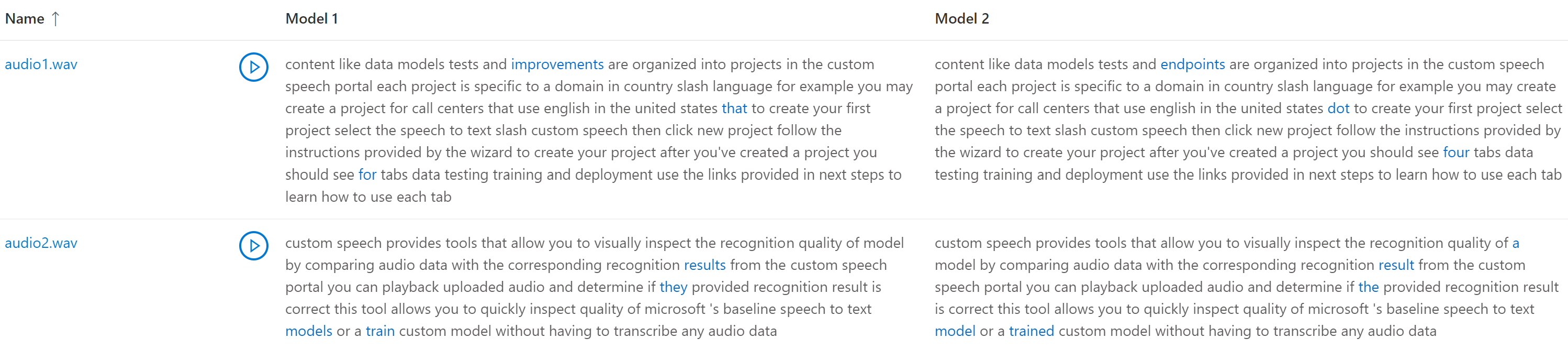
Vous pouvez inspecter la sortie de transcription par chaque modèle testé, par rapport au jeu de données d’entrée audio. Si vous avez inclus deux modèles dans le test, vous pouvez comparer leur qualité de transcription côte à côte.
Pour évaluer la qualité des transcriptions :
- Connectez-vous à Speech Studio.
- Sélectionnez Reconnaissance vocale personnalisée> Votre nom de projet >Tester des modèles.
- Sélectionnez le lien par nom de test.
- Lire un fichier audio pendant la lecture de la transcription correspondante par un modèle.
Si le jeu de données de test inclut plusieurs fichiers audio, vous allez voir plusieurs lignes dans le tableau. Si vous avez inclus deux modèles dans le test, les transcriptions sont affichées dans des colonnes côte à côte. Les différences de transcription entre les modèles sont affichées dans la police de texte bleu.
Le jeu de données de test audio, les transcriptions et les modèles testés sont retournés dans les résultats du test. Si un seul modèle a été testé, la valeur model1 correspond à model2et la valeur transcription1 correspond à transcription2.
Pour évaluer la qualité des transcriptions :
- Téléchargez le jeu de données de test audio, sauf si vous avez déjà une copie.
- Téléchargez les transcriptions de sortie.
- Lire un fichier audio pendant la lecture de la transcription correspondante par un modèle.
Si vous comparez la qualité entre deux modèles, portez une attention particulière aux différences entre les transcriptions de chaque modèle.
Le jeu de données de test audio, les transcriptions et les modèles testés sont retournés dans les résultats du test. Si un seul modèle a été testé, la valeur model1 correspond à model2et la valeur transcription1 correspond à transcription2.
Pour évaluer la qualité des transcriptions :
- Téléchargez le jeu de données de test audio, sauf si vous avez déjà une copie.
- Téléchargez les transcriptions de sortie.
- Lire un fichier audio pendant la lecture de la transcription correspondante par un modèle.
Si vous comparez la qualité entre deux modèles, portez une attention particulière aux différences entre les transcriptions de chaque modèle.