Comment afficher les résultats d’une évaluation dans le portail Azure AI Foundry
La page d’évaluation du portail Azure AI Foundry est un hub polyvalent qui vous permet non seulement de visualiser et d’évaluer vos résultats, mais qui sert également de centre de contrôle pour l’optimisation, la résolution des problèmes et la sélection du modèle d’IA idéal pour vos besoins de déploiement. Elle constitue une solution unique pour la prise de décision fondée sur les données et l’amélioration des performances de vos projets Azure AI Foundry. Vous pouvez aisément accéder aux résultats, puis les interpréter depuis diverses sources, notamment votre flux, la session de test rapide du terrain de jeu, l’interface utilisateur des demandes d’évaluation et le kit de développement logiciel (SDK). Cette flexibilité vous permet d’interagir avec vos résultats de la manière qui convient le mieux à votre flux de travail et à vos préférences.
Une fois que vous avez visualisé les résultats de votre évaluation, vous pouvez vous plonger dans un examen approfondi. Cela inclut la possibilité de visualiser non seulement les résultats individuels, mais aussi de les comparer entre plusieurs exécutions d’évaluation. Cela inclut la possibilité non seulement de visualiser les résultats individuels, mais aussi de les comparer entre plusieurs évaluations. Vous pouvez ainsi identifier les tendances, les modèles et les disparités, et obtenir des informations précieuses sur les performances de votre système d’IA dans diverses conditions.
Dans cet article, vous apprenez à :
- Afficher les résultats et les métriques de l’évaluation.
- Comparer les résultats de l’évaluation.
- Comprendre les métriques d’évaluation intégrées.
- Améliorer les performances.
- Afficher les résultats et les métriques de l’évaluation.
Rechercher les résultats de votre évaluation
Une fois la demande d’évaluation soumise, vous pouvez localiser l’exécution d’évaluation soumise dans la liste des exécutions en accédant à l’onglet Évaluation.
Vous pouvez superviser et gérer vos exécutions d’évaluation dans la liste des exécutions. Vous pouvez modifier les colonnes à l’aide de l’éditeur de colonnes et appliquer des filtres, ce qui vous permet de personnaliser et de créer votre propre version de la liste des exécutions. Vous pouvez également passer rapidement en revue les métriques d’évaluation agrégées pour l’ensemble des exécutions, ce qui vous permet d’effectuer des comparaisons rapides.

Conseil
Pour afficher les évaluations exécutées avec n'importe quelle version du Kit de développement logiciel (SDK) promptflow-evals ou avec les versions 1.0.0b1, 1.0.0b2, 1.0.0b3 de azure-ai-evaluation, cochez la case« Afficher toutes les évaluations » pour localiser l'évaluation.
Pour mieux comprendre comment les métriques d’évaluation sont calculées, vous pouvez obtenir une explication détaillée en sélectionnant l’option « En savoir plus sur les métriques ». Cette ressource détaillée fournit des informations précieuses sur le calcul et l’interprétation des métriques utilisées dans le processus d’évaluation.

Vous pouvez dès lors choisir une exécution spécifique, ce qui vous dirigera vers la page des détails de l’exécution. Ici, vous pouvez accéder à des informations complètes, notamment des détails d’évaluation tels que le jeu de données test, le type de tâche, l’invite, la température, etc. Vous pouvez également consulter les métriques associées à chaque échantillon de données. Les graphiques des scores de métriques fournissent une représentation visuelle de la manière dont les scores sont distribués pour chaque métrique dans votre jeu de données.
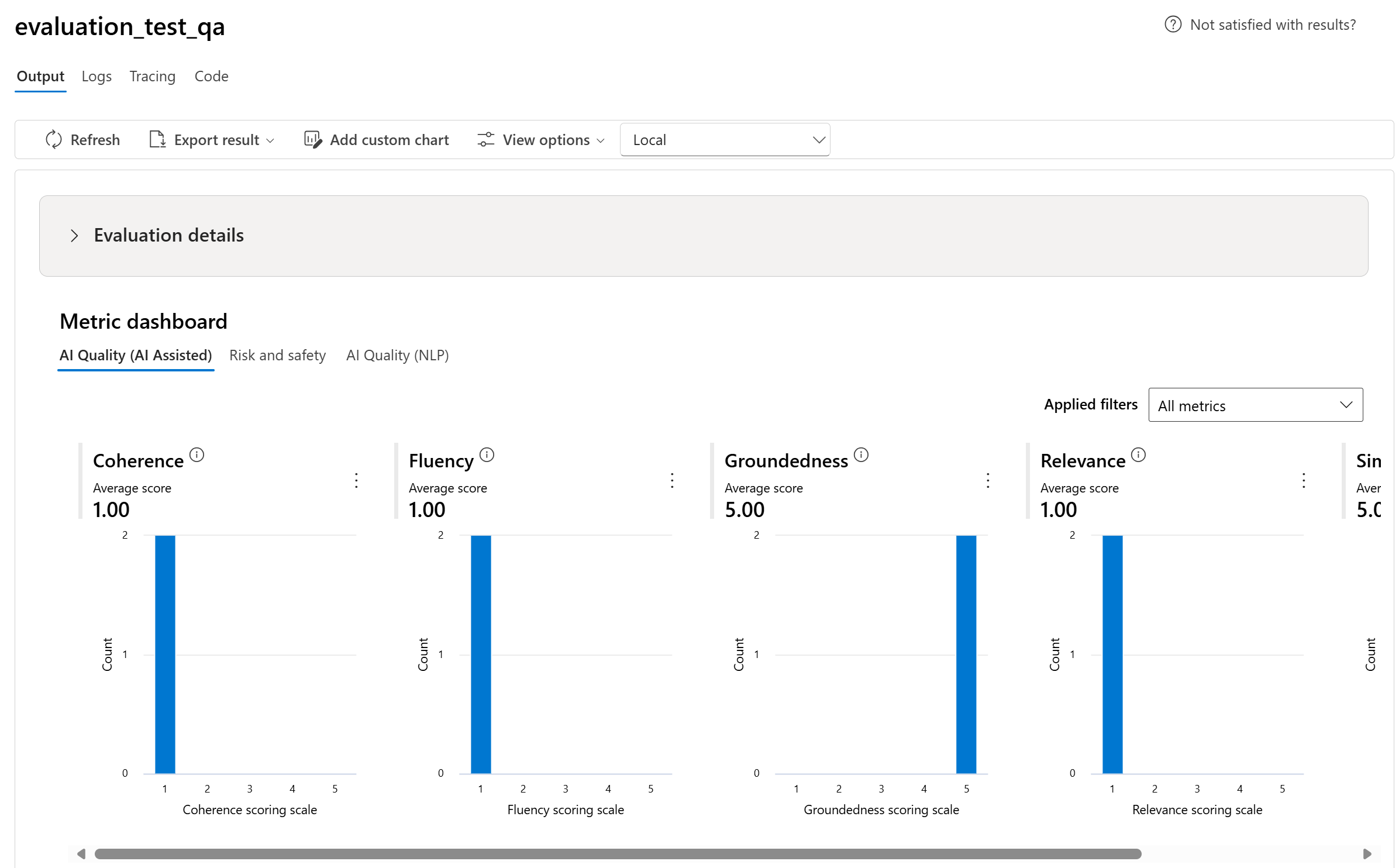
Graphiques de tableau de bord de métriques
Nous décomposons les vues globales avec différents types de mesures par Qualité de l'IA (assistée par l'IA), Risque et sécurité, Qualité de l'IA (NLP), et Personnalisée le cas échéant. Vous pouvez afficher la distribution des scores dans le jeu de données évalué, puis afficher les scores d’agrégation pour chaque métrique.
- Pour la Qualité de l’IA (assistée par l’IA), nous agrégeons en calculant une moyenne sur tous les scores pour chaque métrique. Si vous calculez Fondement Pro, la sortie est binaire et le score agrégé passe donc le taux, qui est calculé par (#trues/#instances) × 100.
- Pour les métriques de risque et de sécurité, nous agrégeons en calculant un taux de défauts pour chaque métrique.
- Pour les métriques de contenu dangereux, le taux de défauts est défini comme le pourcentage d’instances de votre jeu de données de test qui dépassent un seuil sur l’échelle de gravité sur toute la taille du jeu de données. Par défaut, le seuil est défini sur « Moyen ».
- Pour le matériel protégé et les attaques indirectes, le taux de défauts est calculé comme pourcentage d’instances où la sortie est « true » (Taux de défaut = (# true / # instances) × 100).

- Pour les métriques de Qualité de l’IA (NLP), nous affichons l’histogramme de la distribution des métriques comprise entre 0 et 1. Nous agrégeons en calculant une moyenne sur tous les scores pour chaque métrique.

- Pour les métriques personnalisées, vous pouvez sélectionner Ajouter un graphique personnalisé pour créer un graphique personnalisé avec vos métriques choisies ou afficher une métrique par rapport aux paramètres d’entrée sélectionnés.





Vous pouvez également personnaliser des graphiques existants pour les métriques intégrées en modifiant le type de graphique.

Tableau de résultats des métriques détaillées
Dans le tableau des détails des métriques, vous pouvez procéder à un examen complet et individuel de chaque échantillon de données. Ici, vous pouvez examiner le résultat généré et le score de la métrique d’évaluation correspondante. Ce niveau de détail vous permet de prendre des décisions fondées sur des données et d’entreprendre des actions spécifiques pour améliorer les performances de votre modèle.
Certains éléments d’action potentiels basés sur les métriques d’évaluation peuvent inclure :
- Reconnaissance de modèle : En filtrant les valeurs numériques et les métriques, vous pouvez explorer les échantillons avec des scores inférieurs. Examinez ces échantillons pour identifier les tendances ou les problèmes récurrents dans les réponses de votre modèle. Par exemple, vous pouvez remarquer que les scores sont souvent faibles lorsque le modèle génère du contenu sur un certain sujet.
- Perfectionnement du modèle : Utilisez les informations fournies par les échantillons ayant obtenu de moins bons résultats pour améliorer l’instruction rapide du système ou pour affiner votre modèle. Si vous observez des problèmes constants, par exemple en matière de cohérence ou de pertinence, vous pouvez également ajuster les données d’apprentissage ou les paramètres du modèle en conséquence.
- Personnalisation des colonnes : L’éditeur de colonnes vous permet de créer une vue personnalisée du tableau, en vous concentrant sur les métriques et les données les plus pertinentes pour vos objectifs d’évaluation. Cela peut simplifier votre analyse et vous aider à repérer les tendances plus efficacement.
- Recherche de mots clés : la zone de recherche vous permet de rechercher des mots ou expressions spécifiques dans les résultats générés. Cela peut s’avérer utile pour identifier les problèmes ou les modèles liés à des sujets ou à des mots clés particuliers et pour les traiter de manière spécifique.
Le tableau détaillé des métriques offre une multitude de données qui peuvent guider vos efforts d’amélioration du modèle, qu’il s’agisse d’identifier des modèles, de personnaliser votre vue pour une analyse efficace ou d’affiner votre modèle sur la base des problèmes identifiés.
Voici quelques exemples de résultats de métriques pour le scénario de réponse aux questions :

Et voici quelques exemples de résultats de métriques pour le scénario de conversation :

Pour le scénario de conversation à plusieurs tour, vous pouvez sélectionner « Afficher les résultats d’évaluation par tour » pour vérifier les métriques d’évaluation pour chaque tour dans une conversation.


Pour une évaluation de la sécurité dans un scénario multimodal (texte + images), vous pouvez passer en revue les images de l’entrée et de la sortie dans le tableau de résultats des métriques détaillées pour mieux comprendre le résultat de l’évaluation. Comme l’évaluation multimodale est actuellement prise en charge seulement pour les scénarios de conversation, vous pouvez sélectionner « Afficher les résultats d’évaluation par tour » pour examiner l’entrée et la sortie de chaque tour.


Sélectionnez l’image à développer et visualisez-la. Par défaut, toutes les images sont floutées pour vous protéger contre les contenus potentiellement dangereux. Pour visualiser l’image en clair, activez le bouton bascule « Vérifier l’image floutée ».

Pour les métriques de risque et de sécurité, l’évaluation fournit un score de gravité et un raisonnement pour chaque score. Voici quelques exemples de résultats de métriques de risque et de sécurité pour le scénario de réponse aux questions :

Les résultats de l’évaluation peuvent avoir des significations différentes en fonction du public. Par exemple, les évaluations de sécurité peuvent générer une étiquette ayant le niveau de gravité « faible » pour un contenu violent, qui ne correspond pas forcément à la définition qu’un réviseur humain donne de la gravité de ce contenu violent spécifique. Nous fournissons une colonne de commentaires humains avec des pouces vers le haut et des pouces vers le bas lors de l’examen de vos résultats d’évaluation pour faire apparaître les instances approuvées ou signalées comme incorrectes par un réviseur humain.

Lorsque vous comprenez chaque métrique de risque de contenu, vous pouvez facilement afficher chaque définition de métrique et l’échelle de gravité en sélectionnant le nom de la métrique au-dessus du graphique pour afficher une explication détaillée dans une fenêtre contextuelle.

Si l’exécution ne se déroule pas correctement, vous pouvez également déboguer l’exécution de l’évaluation à l’aide du journal et de la trace.
Voici quelques exemples de journaux que vous pouvez utiliser pour déboguer l’exécution de votre évaluation :

Si vous évaluez un flux d’invite, vous pouvez sélectionner le bouton Voir dans le flux pour accéder à la page de flux évaluée pour effectuer la mise à jour de votre flux. Par exemple, l’ajout d’instructions d’invite de métadonnées supplémentaires ou la modification de certains paramètres et la réévaluation.
Gérer et partager la vue avec les options d’affichage
Dans la page Détails de l’évaluation, vous pouvez personnaliser votre affichage en ajoutant des graphiques personnalisés ou en modifiant des colonnes. Une fois personnalisé, vous avez la possibilité d’enregistrer l’affichage et/ou de le partager avec d’autres utilisateurs à l’aide des options d’affichage. Cela vous permet de passer en revue les résultats d’évaluation dans un format adapté à vos préférences et facilite la collaboration avec vos collègues.

Comparer les résultats de l’évaluation
Pour faciliter une comparaison complète entre deux exécutions ou plus, vous avez la possibilité de sélectionner les exécutions souhaitées et de lancer le processus en sélectionnant le bouton Comparer ou, pour une vue générale détaillée du tableau de bord, sur le bouton Basculer vers l’affichage Tableau de bord. Cette fonctionnalité vous permet d’analyser et de comparer les performances et les résultats de plusieurs exécutions, ce qui permet de prendre des décisions plus éclairées et d’apporter des améliorations ciblées.

Dans l’affichage du tableau de bord, vous avez accès à deux composants précieux : le graphique de comparaison de la distribution des métriques et le tableau de comparaison. Ces outils vous permettent d’effectuer une analyse côte à côte des exécutions d’évaluation sélectionnées. Vous pouvez ainsi comparer les différents aspects de chaque échantillon de données avec facilité et précision.

Dans le tableau de comparaison, vous avez la possibilité d’établir une ligne de base pour votre comparaison en pointant avec votre souris sur l’exécution spécifique que vous souhaitez utiliser comme point de référence et définir comme ligne de base. De plus, en activant le bouton bascule « Afficher le delta », vous pouvez facilement visualiser les différences entre l’exécution de la ligne de base et les autres exécutions pour les valeurs numériques. En outre, en activant le bouton bascule « Afficher uniquement la différence », le tableau affiche uniquement les lignes qui diffèrent entre les exécutions sélectionnées, ce qui facilite l’identification des variantes distinctes.
En utilisant ces fonctions de comparaison, vous pouvez prendre une décision éclairée pour sélectionner la meilleure version :
- Comparaison avec la ligne de base : En définissant une exécution de ligne de base, vous pouvez identifier un point de référence avec lequel vous pourrez comparer les autres exécutions. Cela vous permet de voir comment chaque exécution s’écarte de votre norme choisie.
- Évaluation de la valeur numérique : L’activation de l’option « Afficher le delta » vous permet de comprendre l’étendue des différences entre la ligne de base et les autres exécutions. Cela est utile pour évaluer la façon dont différentes exécutions s’exécutent en termes de métriques d’évaluation spécifiques.
- Isolation des différences : La fonctionnalité « Afficher uniquement la différence » simplifie votre analyse en mettant en évidence uniquement les zones où il existe des différences entre les exécutions. Cela peut contribuer à identifier les paramètres qui nécessitent des améliorations ou des ajustements.
Une utilisation efficace de ces outils de comparaison vous permettra d’identifier la version de votre modèle ou de votre système la plus performante par rapport aux critères et aux métriques que vous avez définis, ce qui vous aidera à choisir l’option la plus adaptée à votre application.

Mesure de la vulnérabilité du jailbreak
L’évaluation du jailbreak est une mesure comparative, et non une métrique assistée par l’IA. Exécutez des évaluations sur deux jeux de données différents soumis à des tests de contrainte par des experts : un jeu de données de test contradictoire de référence, et le même jeu de données de test contradictoire avec des injections de jailbreak au premier tour. Vous pouvez utiliser le simulateur de données contradictoires pour générer le jeu de données avec ou sans injections de jailbreak.
Pour comprendre si votre application est vulnérable au jailbreak, vous pouvez spécifier quelle est la base de référence, puis activer les « taux » de défaut de jailbreak bascule dans la table de comparaison. Le taux de défauts de jailbreak est défini comme le pourcentage d’instances dans votre jeu de données de test où une injection de jailbreak a généré un score de gravité plus élevé pour toute mesure de risque de contenu par rapport à une base de référence sur toute la taille du jeu de données. Vous pouvez sélectionner plusieurs évaluations dans votre tableau de bord de comparaison pour afficher la différence dans les taux de défauts.

Conseil
Le taux de défaut de jailbreak se calcule par comparaison uniquement pour les jeux de données de même taille et uniquement lorsque toutes les exécutions incluent des métriques de risque et de sécurité de contenu.
Comprendre les métriques d’évaluation intégrées
Il est essentiel de comprendre les paramètres intégrés pour évaluer les performances et l’efficacité de votre application IA. En vous familiarisant avec ces outils de mesure clés, vous êtes plus à même d’interpréter les résultats, de prendre des décisions éclairées et d’affiner votre application pour obtenir les meilleurs résultats. Si vous souhaitez en savoir plus sur l’importance de chaque métrique, son mode de calcul, son rôle dans l’évaluation des différents aspects de votre modèle et la manière d’interpréter les résultats pour apporter des améliorations fondées sur des données, veuillez consulter la rubrique Métriques d’évaluation et de monitoring.
Étapes suivantes
En savoir plus sur la manière d’évaluer vos applications IA générative :
- Évaluer vos applications IA générative via le terrain de jeu
- Évaluer vos applications d’IA générative avec le portail Azure AI Foundry ou le kit de développement logiciel (SDK)
En savoir plus sur les techniques d’atténuation des risques.