Groupes à haute disponibilité dans AKS activés par Azure Arc
Les groupes à haute disponibilité sont des groupes logiques de machines virtuelles qui ont des relations anti-affinité faibles entre elles, pour s’assurer qu’elles sont réparties uniformément entre les domaines d’erreur disponibles dans un cluster physique. Un domaine d’erreur dans ce contexte est un hôte physique ou un groupe d’hôtes physiques. En utilisant des groupes à haute disponibilité, AKS Arc peut améliorer la disponibilité et la distribution de vos charges de travail Kubernetes. Les groupes à haute disponibilité peuvent éviter les scénarios dans lesquels une défaillance de nœud unique peut entraîner l’arrêt de plusieurs machines virtuelles ou devenir déséquilibrés.
Vue d’ensemble
Si vous utilisez AKS sur Azure Stack HCI et Windows Server pour exécuter des charges de travail Kubernetes localement, vous pouvez rencontrer des problèmes avec l’architecture actuelle. Par exemple, vous remarquerez peut-être que plusieurs machines virtuelles au sein du même pool de nœuds peuvent exister sur le même hôte physique, ce qui n’est pas idéal pour la haute disponibilité. Vous pouvez également voir que les machines virtuelles ne rééquilibrent pas entre les hôtes physiques lorsqu’un hôte récupère à partir d’un problème, ce qui entraîne une distribution inégale des charges de travail. Ces problèmes peuvent affecter les performances et la fiabilité de vos applications, ce qui provoque des interruptions inutiles dans vos opérations métier.
Les groupes à haute disponibilité offrent plusieurs avantages pour les utilisateurs AKS sur Azure Stack HCI et Windows Server, tels que :
- Améliore la disponibilité et la résilience de vos applications en évitant les scénarios dans lesquels plusieurs machines virtuelles dans le même pool de nœuds ou le même plan de contrôle tombent en panne ou deviennent déséquilibrés en raison d’une défaillance de nœud unique.
- Optimise l’utilisation et les performances des ressources de votre cluster en garantissant que les machines virtuelles sont réparties uniformément entre les nœuds disponibles et ne se concentrent pas sur un seul nœud ou un sous-ensemble de nœuds.
- S’aligne sur les meilleures pratiques et les attentes de vos clients et partenaires qui recherchent une expérience Kubernetes locale fiable et cohérente.
Activer les groupes à haute disponibilité
Avec AKS sur Azure Stack HCI 23H2, la fonctionnalité des groupes à haute disponibilité est activée par défaut lorsque vous créez un pool de nœuds.
Avec AKS sur Azure Stack HCI 22H2, la fonctionnalité des groupes à haute disponibilité est désactivée par défaut. Pour l’activer, ajoutez le -enableAvailabilitySet paramètre lorsque vous créez un cluster de charge de travail. Par exemple :
New-AksHciCluster -Name <name> -controlPlaneNodeCount 3 -osType Linux -kubernetesVersion $kubernetesVersion -enableAvailabilitySet
Fonctionnement des groupes à haute disponibilité dans AKS activé par Azure Arc
Lorsque vous créez un cluster AKS Arc, AKS Arc crée automatiquement des groupes à haute disponibilité, un pour les machines virtuelles du plan de contrôle et un autre pour chacun des pools de nœuds du cluster. Chaque pool de nœuds a son propre groupe à haute disponibilité. Avec cette disposition, AKS Arc garantit que les machines virtuelles du même rôle (plan de contrôle ou pool de nœuds) ne sont jamais situées sur le même hôte physique et qu’elles sont distribuées sur les nœuds disponibles dans un cluster.
Une fois les groupes à haute disponibilité créés et les machines virtuelles affectées, le système les place automatiquement sur les nœuds physiques appropriés. En cas d’échec d’un nœud, le système bascule automatiquement les machines virtuelles vers d’autres nœuds et les rééquilibrée lorsque le nœud récupère. De cette façon, vous pouvez obtenir une haute disponibilité et une distribution optimale de vos charges de travail Kubernetes sans intervention manuelle.
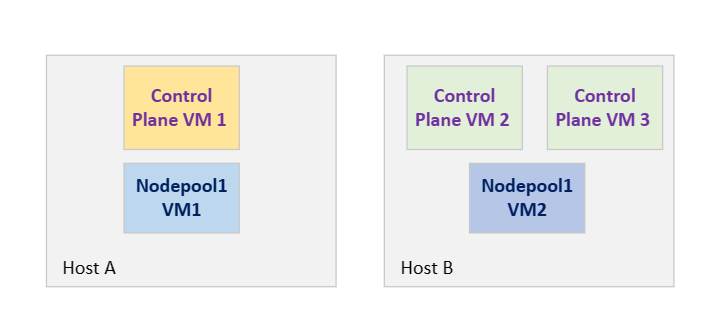
Considérez un cluster AKS sur Azure Stack HCI 23H2 avec deux machines hôtes physiques, Host A et Host B, trois machines virtuelles de plan de contrôle et deux machines virtuelles de nœud Worker, Nodepool1VM1 et Nodepool1VM2. Pour garantir la haute disponibilité de vos applications Kubernetes, les machines virtuelles du pool de nœuds ne doivent jamais partager le même hôte, sauf si l’un des hôtes n’est pas temporairement indisponible pour la maintenance planifiée ou le problème de capacité, ce qui peut entraîner la mise temporairement de la machine virtuelle (machine virtuelle) sur un autre hôte.
Dans le diagramme suivant, chaque couleur représente un groupe anti-affinité :
Si l’hôte B tombe en panne en raison d’un redémarrage, d’un plan de contrôle VM2, d’un plan de contrôle VM3 et d’un basculement Nodepool1VM2 vers l’hôte A , comme illustré dans la figure suivante. En supposant que votre application exécute des pods dans NodePoolVM1, ce redémarrage n’a aucun impact sur votre application :
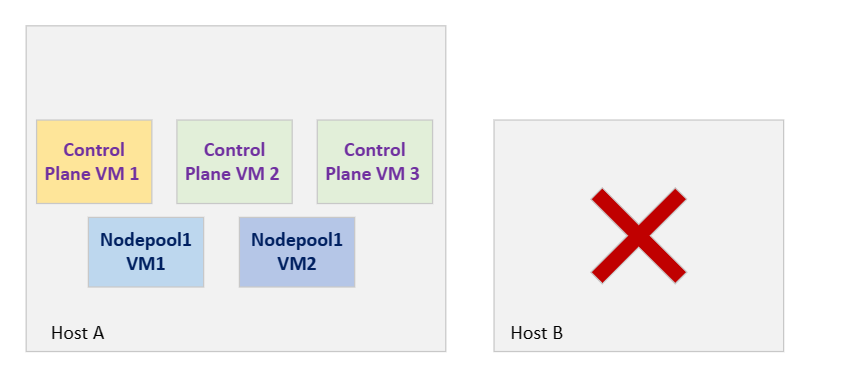
Dans l’ancienne architecture, si l’hôte B est revenu en ligne après un redémarrage, il n’y avait aucune garantie que les machines virtuelles revenaient de l’hôte A à l’hôte B (rééquilibrage), obligeant ainsi les charges de travail à rester sur le même hôte et à créer un point de défaillance unique, comme illustré dans le diagramme suivant :
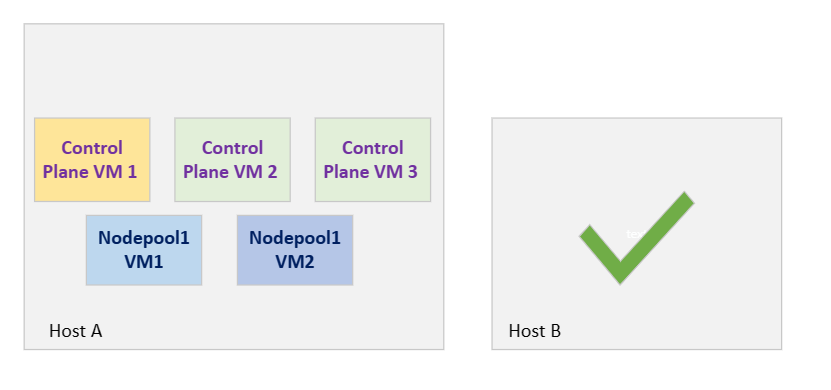
Les groupes à haute disponibilité pour AKS Arc peuvent aider à rééquilibrer les machines virtuelles une fois qu’un hôte se rétablit à partir d’une panne temporaire. Dans cet exemple, ControlPlaneVM2, ControlPlaneVM3 et Nodepool1VM2 se déplacent automatiquement vers l’hôte B, comme illustré ici :
Important
Les groupes à haute disponibilité dans AKS Arc sont une nouvelle fonctionnalité qui évolue toujours et améliore. Nous ne prenons pas encore en charge la configuration manuelle des domaines d’erreur ou des groupes à haute disponibilité. Vous ne pouvez pas modifier les domaines d’erreur d’un groupe à haute disponibilité après sa création. Les machines virtuelles sont affectées à un groupe à haute disponibilité lors de la création du cluster et ne peuvent pas être migrées vers un autre groupe à haute disponibilité.
Ajouter ou supprimer des ordinateurs
Dans un scénario de suppression d’hôte, l’hôte n’est plus considéré comme une partie du cluster. Cette suppression se produit généralement lorsque vous remplacez un ordinateur en raison de problèmes matériels ou effectuez un scale-down du cluster HCI pour d’autres raisons. Lors d’une panne de nœud, le nœud reste partie du cluster HCI, mais apparaît en tant que panne.
Si une machine physique (domaine d’erreur) est définitivement supprimée du cluster, la configuration du groupe à haute disponibilité n’est pas modifiée pour réduire le nombre de domaines d’erreur. Dans ce scénario, le groupe à haute disponibilité entre dans un état non sain. Nous vous recommandons de redéployer vos clusters de charge de travail afin que le groupe à haute disponibilité soit mis à jour avec le nombre approprié de domaines d’erreur.
Lorsqu’une nouvelle machine physique (domaine d’erreur) est ajoutée au cluster, la configuration du groupe à haute disponibilité est automatiquement développée pour inclure la nouvelle machine. Toutefois, les machines virtuelles existantes ne rééquilibrent pas pour appliquer cette nouvelle configuration, car elles sont déjà affectées aux groupes à haute disponibilité. Nous vous recommandons de redéployer vos clusters de charge de travail afin que le groupe à haute disponibilité soit mis à jour avec le nombre approprié de domaines d’erreur.