Qu’est-ce qu’un lac de données ?
Un lac de données est un référentiel de stockage qui contient une grande quantité de données au format natif, brut. Les lacs de données sont optimisés pour s’adapter à des téraoctets et pétaoctets de données. Les données proviennent généralement de plusieurs sources et peuvent être structurées, semi-structurées ou non structurées. Un lac de données vous permet de stocker des éléments dans leur état d’origine sans leur faire subir de transformation. Cette méthode diffère d’un entrepôt de données classique, qui transforme et traite les données au moment de l’ingestion.
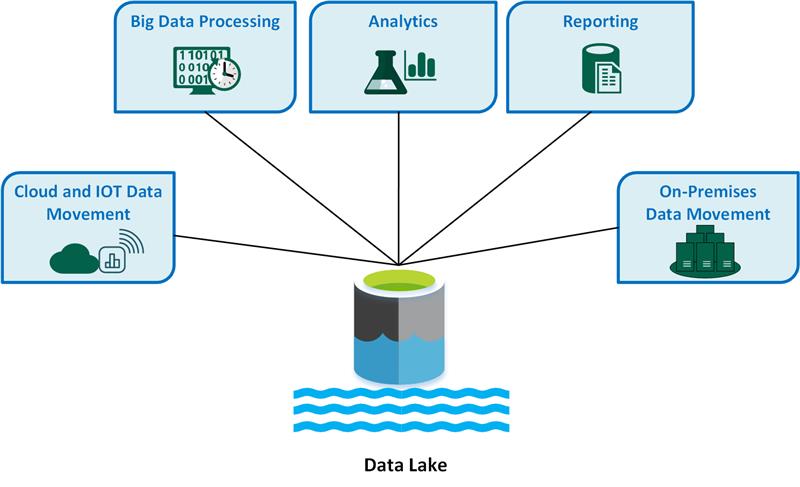
Les principaux cas d’utilisation des lacs de données sont les suivants :
- Déplacement des données Cloud et Internet des objets (IoT).
- Traitement du Big Data.
- Analytique.
- Les rapports.
- Déplacement de données locales.
Tenez compte des avantages suivants des lacs de données :
Un lac de données ne supprime jamais de données, car il les stocke dans leur format brut. Cette fonction est particulièrement utile dans un environnement de données volumineux, car vous ne savez peut-être pas à l’avance quelles informations sont disponibles à partir des données.
Les utilisateurs peuvent explorer les données et créer leurs propres requêtes.
Un lac de données peut être plus rapide que les outils ETL (extract, transform, load) traditionnels.
Un lac de données est plus flexible qu’un entrepôt de données, car il peut stocker des données non structurées et semi-structurées.
Une solution Data Lake complète regroupe à la fois le stockage et le traitement. Le lac de données est conçu pour la tolérance aux pannes, l’évolutivité infinie et l’ingestion à débit élevé de données de différentes formes et tailles. Le traitement des lacs de données implique un ou plusieurs moteurs de traitement capables d'intégrer ces objectifs et qui peuvent fonctionner sur des données stockées dans un lac de données à grande échelle.
Quand utiliser un lac de données
Nous vous recommandons d’utiliser un lac de données pour l’exploration des données, l’analyse des données et l’apprentissage automatique.
Un lac de données peut agir en tant que source de données pour un entrepôt de données. Lorsque vous utilisez cette méthode, le lac de données ingère des données brutes, puis les transforme en un format structuré interrogeable. En général, cette transformation utilise un pipeline ELT (extract, load, transform), où les données sont ingérées et transformées sur place. Les données sources relationnelles peuvent être placées directement dans l’entrepôt de données via un processus ETL et ignorer le lac de données.
Vous pouvez utiliser les lacs de données pour la diffusion en continu d’événements ou dans des scénarios IoT, car ils permettent de conserver de grandes quantités de données relationnelles et non relationnelles sans transformation ou définition de schéma. Les lacs de données sont conçus pour gérer de grands volumes de petites écritures à faible latence, et sont optimisés pour un débit important.
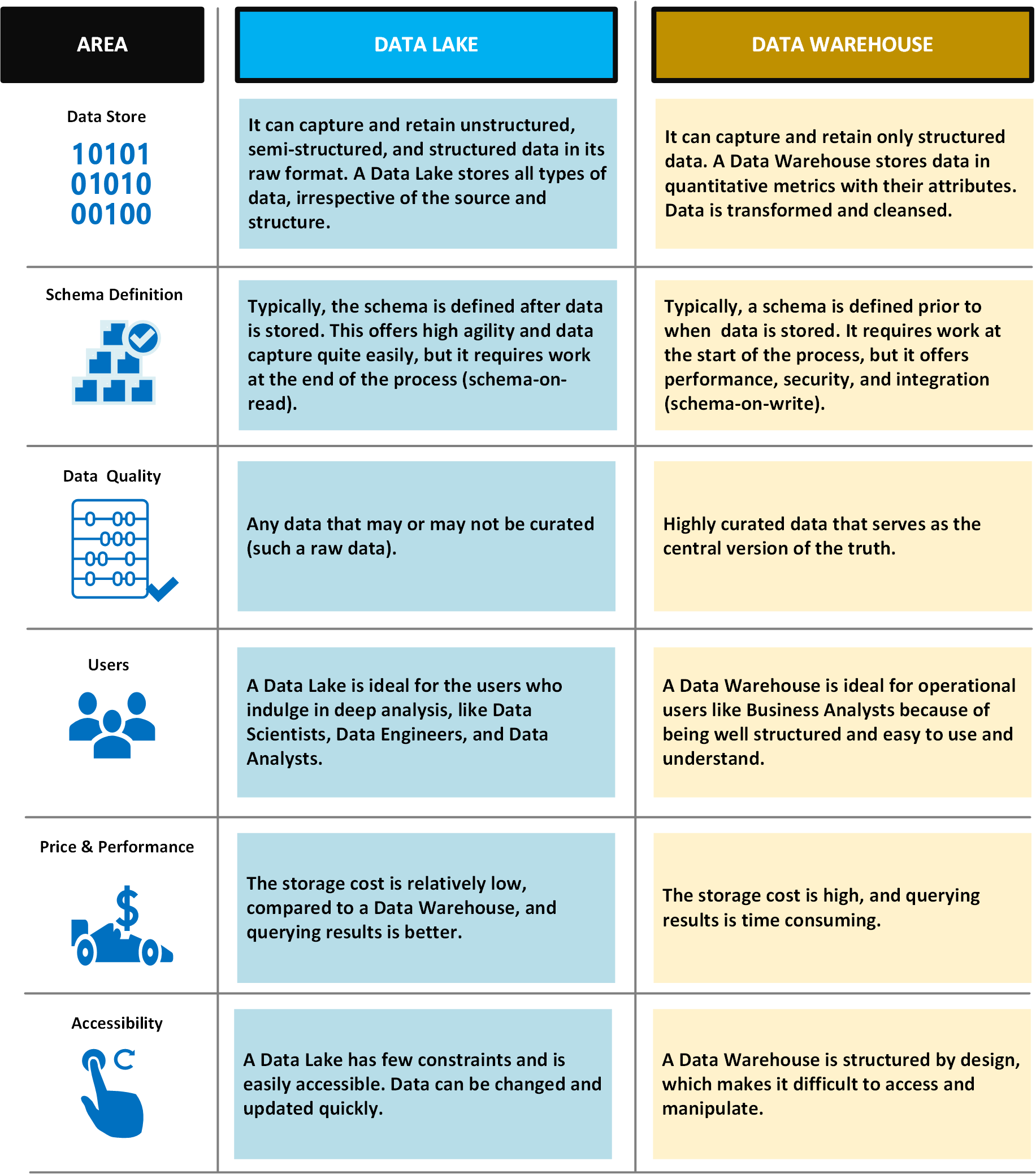
Le tableau suivant compare les lacs de données et les entrepôts de données.
Défis
Grands volumes de données : la gestion de grandes quantités de données brutes et non structurées peut être complexe et gourmande en ressources, c'est pourquoi vous avez besoin d’une infrastructure et d’outils robustes.
Goulots d’étranglement potentiels : le traitement des données peut entraîner des retards et des inefficacités, en particulier lorsque vous avez de grands volumes et différents types de données.
Risques d’altération des données : une validation et un contrôle incorrects des données entraînent un risque d’altération des données, ce qui peut compromettre l’intégrité du lac de données.
Problèmes de contrôle de la qualité : la qualité des données est un défi en raison de la diversité des sources et des formats de données. Vous devez implémenter des pratiques strictes de gouvernance des données.
Problèmes de performances : les performances des requêtes peuvent se dégrader à mesure que le lac de données s'agrandit. Vous devez donc optimiser les stratégies de stockage et de traitement.
Choix de technologie
Lorsque vous créez une solution de lac de données complète sur Azure, tenez compte des technologies suivantes :
Azure Data Lake Storage associe Stockage Blob Azure avec les fonctionnalités de lac de données, qui fournit un accès compatible avec Apache Hadoop, des fonctionnalités d’espace de noms hiérarchique et une sécurité renforcée pour une analytique Big Data efficace.
Azure Databricks est une plateforme unifiée que vous pouvez utiliser pour traiter, stocker, analyser et monétiser des données. Elle prend en charge les processus ETL, les tableaux de bord, la sécurité, l’exploration de données, l'apprentissage automatique et l’IA générative.
Azure Synapse Analytics est un service unifié qui vous permet d’ingérer, d’explorer, de préparer, de transformer, de gérer et de fournir des données pour des besoins immédiats en décisionnel d’entreprise et en Machine Learning. Il s’intègre profondément aux lacs de données Azure afin de pouvoir interroger et analyser efficacement des jeux de données volumineux.
Azure Data Factory est un service d’intégration de données basé sur le cloud qui vous permet de créer des workflows orientés données pour orchestrer et automatiser le déplacement et la transformation des données.
Microsoft Fabric est une plateforme de données complète qui unifie l’ingénierie, la science et l’entreposage de données, les analyses en temps réel et le décisionnel d'entreprise dans une solution unique.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Avijit Prasad | Consultant Cloud
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
- Qu’est-ce que OneLake ?
- Présentation de Data Lake Storage
- Documentation Azure Data Lake Analytics
- Formation : Présentation d’Azure Data Lake Storage
- Intégration de Hadoop et d’Azure Data Lake Storage
- Se connecter à Data Lake Storage et Stockage Blob
- Charger des données dans Data Lake Storage avec Azure Data Factory