Attention
Cet article fait référence à CentOS, une distribution Linux proche de l’état de fin de service (EOL). Faites le point sur votre utilisation et organisez-vous en conséquence. Pour plus d’informations, consultez les conseils d’aide relatifs à la fin de vie de CentOS.
Cet exemple de scénario montre comment exécuter Apache NiFi sur Azure. NiFi fournit un système de traitement et de distribution des données.
Apache®, Apache NiFi® et NiFi® sont soit des marques déposées, soit des marques commerciales d’Apache Software Foundation aux États-Unis et/ou dans d’autres pays. L’utilisation de ces marques n’implique aucune approbation de l’Apache Software Foundation.
Architecture

Téléchargez un fichier Visio de cette architecture.
Workflow
L’application NiFi s’exécute sur des machines virtuelles dans des nœuds de cluster NiFi. Les machines virtuelles se trouvent dans un groupe de machines virtuelles identiques que la configuration déploie sur plusieurs zones de disponibilité.
Apache ZooKeeper s’exécute sur des machines virtuelles dans un cluster distinct. NiFi utilise le cluster ZooKeeper à ces fins :
- Pour choisir un nœud coordinateur de cluster
- Pour coordonner le flux de données
Azure Application Gateway fournit l’équilibrage de charge de couche 7 pour l’interface utilisateur qui s’exécute sur les nœuds NiFi.
Monitor et sa fonctionnalité de Log Analytics collectent, analysent et agissent sur la télémétrie à partir du système NiFi. La télémétrie comprend les journaux système NiFi, les métriques d’intégrité du système et les métriques de performances.
Azure Key Vault stocke de manière sécurisée des certificats et des clés pour le cluster NiFi.
Microsoft Entra ID fournit une authentification unique (SSO) et une authentification multifacteur.
Composants
- NiFi fournit un système de traitement et de distribution des données.
- ZooKeeper est un serveur Open source qui gère les systèmes distribués.
- Les machines virtuellesconstituent une offre IaaS (Infrastructure-as-a-Service). Vous pouvez utiliser des machines virtuelles pour déployer des ressources de calcul à la demande et évolutives. Une machine virtuelle Azure offre la flexibilité de la virtualisation, sans les exigences de maintenance du matériel physique.
- Les groupes de machines virtuelles identiques Azure permettent de gérer un groupe de machines virtuelles à charge équilibrée. Le nombre d’instances de machine virtuelle peut augmenter ou diminuer automatiquement en fonction d’une demande ou d’un calendrier défini.
- Les Zones de disponibilité sont des emplacements physiques uniques au sein d’une région Azure. Ces offres à haute disponibilité protègent les applications et les données contre les défaillances du centre de données.
- Application Gateway est un équilibreur de charge de trafic web qui gère le trafic vers des applications web.
- Monitor collecte et analyse des données dans les environnements et ressources Azure. Ces données incluent la télémétrie des applications, comme les métriques de performances et les journaux d’activité. Pour plus d’informations, consultez Considérations relatives à la surveillance plus loin dans cet article.
- Log Analytics est un outil du portail Azure qui exécute des requêtes sur les données des journaux Monitor. Log Analytics fournit également des fonctionnalités de création de graphiques et d’analyse statistique des résultats de requête.
- Azure DevOps Services fournit des services, des outils et des environnements pour la gestion des projets et des déploiements de codage.
- Key Vault stocke et contrôle de manière sécurisée l’accès aux secrets d’un système, tels que les clés d’API, les mots de passe, les certificats et les clés de chiffrement.
- Microsoft Entra ID est un service d’identité basé sur le cloud qui contrôle l’accès à Azure et à d’autres applications cloud.
Autres solutions
- Azure Data Factory fournit une alternative à cette solution.
- Au lieu de Key Vault, vous pouvez utiliser un service comparable pour stocker les secrets système.
- Apache Airflow. Pour plus d’informations, consultez Différences entre Airflow et NiFi.
- Il est possible d’utiliser une alternative NiFi d’entreprise prise en charge comme Cloudera Apache NiFi. L’offre Cloudera est disponible par la Place de marché Azure.
Détails du scénario
Dans ce scénario, NiFi s’exécute dans une configuration en cluster sur des machines virtuelles Azure dans un groupe identique. Toutefois, la plupart des recommandations de cet article s’appliquent également aux scénarios qui exécutent NiFi en mode à instance unique sur une seule machine virtuelle. Les meilleures pratiques décrites dans cet article illustrent un déploiement évolutif, à haute disponibilité et sécurisé.
Cas d’usage potentiels
NiFi fonctionne bien pour le déplacement des données et la gestion du flot de données :
- Connexion de systèmes découplés dans le Cloud
- Déplacement de données dans et hors de stockage Azure et d’autres magasins de données
- Intégration d’applications de périphérie à cloud et de cloud hybride avec Azure IoT, Azure Stack et Azure Kubernetes Service (AKS)
Par conséquent, cette solution s’applique à de nombreux domaines :
Les entrepôts de données modernes (MDWs) apportent ensemble des données structurées et non structurées à l’échelle. Ils collectent et stockent les données à partir de différentes sources, récepteurs et formats. NiFi expose la réception de données dans des MDW basés sur Azure pour les raisons suivantes :
- Plus de 200 processeurs sont disponibles pour la lecture, l’écriture et la manipulation des données.
- Le système prend en charge les services de stockage tels que le stockage d’objets Blob Azure, Azure Data Lake Storage, Azure Event Hubs, Azure Queue Stockage, Azure Cosmos DB et Azure Synapse Analytics.
- Les fonctionnalités robustes de provenance des données permettent d’implémenter des solutions conformes. Pour plus d’informations sur la capture de données en provenance de la fonctionnalité Log Analytics de Azure Monitor, consultez Considérations relatives à la création de rapports plus loin dans cet article.
NiFi peut s’exécuter sur une base autonome sur des appareils à faible encombrement. Dans ce cas, NiFi permet de traiter les données de périphérie et de déplacer ces données vers des clusters ou des instances NiFi plus volumineuses dans le Cloud. NiFi permet de filtrer, de transformer et de hiérarchiser les données de périphérie en mouvement, garantissant ainsi des flux de données fiables et efficaces.
Les solutions IIoT (IoT industriel) gèrent le workflow des données entre la périphérie et le centre de données. Ce processus commence par l’acquisition de données à partir des systèmes et d’équipements de contrôle industriel. Les données sont ensuite transférées vers les solutions de gestion des données et des MDW. NiFi offre des fonctionnalités qui facilitent l’acquisition et le déplacement de données :
- Fonctionnalités de traitement des données de périphérie
- Prise en charge des protocoles utilisés par les passerelles et les appareils IoT
- Intégration avec les services Event Hubs et Stockage
Les applications IoT dans les domaines de la maintenance prédictive et de la gestion de la chaîne d’approvisionnement peuvent utiliser cette fonctionnalité.
Recommandations
Gardez à l’esprit les points suivants lorsque vous utilisez cette solution :
Versions recommandées de NiFi
Lorsque vous exécutez cette solution sur Azure, nous vous recommandons d’utiliser la version 1.13.2+ de NiFi. Vous pouvez exécuter d’autres versions, mais elles peuvent nécessiter des configurations différentes de celles de ce guide.
Pour installer NiFi sur des machines virtuelles Azure, il est préférable de télécharger les fichiers binaires de commodité à partir de la page de téléchargements NiFi. Vous pouvez également générer les binaires à partir du code source.
Versions recommandées de ZooKeeper
Pour cet exemple de charge de travail, nous vous recommandons d’utiliser les versions 3.5.5 et ultérieures ou 3.6.x de ZooKeeper.
Vous pouvez installer ZooKeeper sur des machines virtuelles Azure à l’aide de fichiers binaires de commodité ou de code source officiels. Les deux sont disponibles sur la page des versions de Apache ZooKeeper.
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework qui est un ensemble de principes directeurs qui permettent d’améliorer la qualité d’une charge de travail. Pour plus d’informations, consultez Microsoft Azure Well-Architected Framework.
Pour plus d’informations sur la configuration de NiFi, consultez le Guide de l’administrateur système Apache NiFi. Gardez également à l’esprit ces considérations lors de l’implémentation de cette solution.
Optimisation des coûts
L’optimisation des coûts consiste à examiner les moyens de réduire les dépenses inutiles et d’améliorer l’efficacité opérationnelle. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts.
- Utilisez la calculatrice de prix Azure pour estimer le coût de l’implémentation de cette solution.
- Pour obtenir une estimation qui comprend tous les services de cette architecture, à l’exception de la solution d’alerte personnalisée, consultez cet exemple de profil de coût.
Considérations relatives à la machine virtuelle
Les sections suivantes fournissent un aperçu détaillé de la configuration des machines virtuelles NiFi :
Taille de la machine virtuelle
Ce tableau répertorie les tailles de machine virtuelle recommandées pour démarrer. Pour la plupart des flux de données à usage général, Standard_D16s_v3 est préférable. Toutefois, chaque transmission de données dans NiFi a des exigences différentes. Testez votre flux et redimensionnez en fonction des besoins réels du flux.
Envisagez d’activer la mise en réseau accélérée sur les machines virtuelles afin d’augmenter les performances du réseau. Pour plus d’informations, consultez Fonctionnalités réseau pour les groupes de machines virtuelles identiques Azure.
| Taille de la machine virtuelle | Processeurs virtuels | Mémoire en Go | Débit maximal du disque de données sans mise en cache dans les opérations d’E/S par seconde (IOPS) par Mbits/s* | Nombre maximal d’interfaces réseau/bande passante réseau attendue (Mbits/s) |
|---|---|---|---|---|
| Standard_D8s_v3 | 8 | 32 | 12 800/192 | 4/4 000 |
| Standard_D16s_v3** | 16 | 64 | 25 600/384 | 8/8 000 |
| Standard_D32s_v3 | 32 | 128 | 51 200/768 | 8/16 000 |
| Standard_M16m | 16 | 437.5 | 10 000/250 | 8/4 000 |
* Désactivez la mise en cache d’écriture sur le disque de données pour tous les disques de données que vous utilisez sur les nœuds NiFi.
* * Nous vous recommandons d’utiliser cette référence pour la plupart des flux de données à usage général. Les références SKU de machine virtuelle Azure avec des processeurs virtuels et des configurations de mémoire similaires doivent également être adéquates.
Système d’exploitation de machine virtuelle (OS)
Nous vous recommandons d’exécuter NiFi dans Azure sur l’un des systèmes d’exploitation invités suivants :
- Ubuntu 18.04 LTS ou version ultérieure
- CentOS 7.9
Pour répondre aux besoins spécifiques de votre workflow, il est important d’ajuster plusieurs paramètres au niveau du système d’exploitation, notamment :
- Nombre maximal de processus dupliqués.
- Nombre maximal de descripteurs de fichiers.
- Temps d’accès,
atime.
Après avoir ajusté le système d’exploitation pour l’adapter à votre cas d’utilisation attendu, utilisez Azure VM Image Builder pour codifier la génération de ces images réglées. Pour obtenir des instructions spécifiques à NiFi, consultez Meilleures pratiques de configuration dans le guide de l’administrateur système Apache NiFi.
Stockage
Stockez les différents dépôts NiFi sur les disques de données et non sur le disque du système d’exploitation pour trois raisons principales :
- Les flux ont souvent des exigences de débit de disque élevées qu’un seul disque ne peut pas satisfaire.
- Il est préférable de séparer les opérations de disque NiFi des opérations de disque du système d’exploitation.
- Les référentiels ne doivent pas se trouver sur un stockage temporaire.
Les sections suivantes décrivent les instructions de configuration des disques de données. Ces instructions sont spécifiques à Azure. Pour plus d’informations sur la configuration des référentiels, consultez Gestion de l’état dans le Guide de l’administrateur système Apache NiFi.
Type et taille du disque de données
Tenez compte des facteurs suivants lorsque vous configurez les disques de données pour NiFi :
- Type de disque
- Taille du disque
- Nombre total de disques
Notes
Pour obtenir des informations à jour sur les types de disques, le dimensionnement et la tarification, consultez Introduction aux disques managés Azure.
Le tableau suivant présente les types de disques managés actuellement disponibles dans Azure. Vous pouvez utiliser NiFi avec n’importe lequel de ces types de disques. Toutefois, pour les flux de données à débit élevé, nous vous recommandons SSD Premium.
| Disques de stockage Ultra (NVM Express (NVMe)) | SSD Premium | SSD Standard | HDD Standard | |
|---|---|---|---|---|
| Type de disque | SSD | SSD | SSD | HDD |
| Taille maximale du disque | 65 536 Go | 32 767 Go | 32 767 Go | 32 767 Go |
| Débit max. | 2 000 Mio/s | 900 Mio/s | 750 Mio/s | 500 Mio/s |
| Nb max. d’E/S par seconde | 160 000 | 20 000 | 6 000 | 2 000 |
Utilisez au moins trois disques de données pour augmenter le débit du flux de données. Pour connaître les meilleures pratiques pour la configuration des référentiels sur les disques, consultez Configuration du référentiel plus loin dans cet article.
Le tableau suivant répertorie la taille et le débit appropriés pour chaque taille et type de disque.
| Disque HDD standard S15 | Disque HDD standard S20 | Disque HDD standard S30 | Disque SSD standard S15 | Disque SSD standard S20 | Disque SSD standard S30 | Disque SSD premium P15 | Disque SSD premium P20 | Disque SSD premium P30 | |
|---|---|---|---|---|---|---|---|---|---|
| Taille du disque en Go | 256 | 512 | 1 024 | 256 | 512 | 1 024 | 256 | 512 | 1 024 |
| IOPS par disque | Jusqu’à 500 | Jusqu’à 500 | Jusqu’à 500 | Jusqu’à 500 | Jusqu’à 500 | Jusqu’à 500 | 1 100 | 2 300 | 5 000 |
| Débit par disque | Jusqu’à 60 Mbits/s | Jusqu’à 60 Mbits/s | Jusqu’à 60 Mbits/s | Jusqu’à 60 Mbits/s | Jusqu’à 60 Mbits/s | Jusqu’à 60 Mbits/s | 125 Mbits/s | 150 Mbits/s | 200 Mbits/s |
Si votre système atteint les limites de machines virtuelles, l’ajout de disques peut ne pas augmenter le débit :
- Les limites d’E/S par seconde et de débit dépendent de la taille du disque.
- La taille de machine virtuelle que vous choisissez impose des limites d’IOPS et de débit pour la machine virtuelle sur tous les disques de données.
Pour les limites de débit de disque au niveau de la machine virtuelle, consultez Tailles pour les machines virtuelles Linux dans Azure.
Mise en cache du disque de machine virtuelle
Sur les machines virtuelles Azure, la fonctionnalité de mise en cache d’hôte gère la mise en cache d’écriture sur disque. Pour augmenter le débit dans les disques de données que vous utilisez pour les référentiels, désactivez la mise en cache d’écriture sur le disque en définissant la mise en cache de l’hôte sur None.
Configuration du référentiel
Les recommandations relatives aux meilleures pratiques pour NiFi sont l’utilisation d’un ou plusieurs disques distincts pour chacun de ces référentiels :
- Contenu
- FlowFile
- Provenance
Cette approche nécessite un minimum de trois disques.
NiFi prend également en charge l’entrelacement au niveau de l’application. Cette fonctionnalité augmente la taille ou les performances des référentiels de données.
L’extrait suivant provient du fichier de configuration nifi.properties. Cette configuration partitionne et entrelace les dépôts sur les disques managés attachés aux machines virtuelles :
nifi.provenance.repository.directory.stripe1=/mnt/disk1/ provenance_repository
nifi.provenance.repository.directory.stripe2=/mnt/disk2/ provenance_repository
nifi.provenance.repository.directory.stripe3=/mnt/disk3/ provenance_repository
nifi.content.repository.directory.stripe1=/mnt/disk4/ content_repository
nifi.content.repository.directory.stripe2=/mnt/disk5/ content_repository
nifi.content.repository.directory.stripe3=/mnt/disk6/ content_repository
nifi.flowfile.repository.directory=/mnt/disk7/ flowfile_repository
Pour plus d’informations sur la conception d’un stockage à hautes performances, consultez Stockage Premium Azure : conception pour des performances élevées.
Création de rapports
NiFi comprend une tâche de création de rapports pour la fonctionnalité log Analytics.
Vous pouvez utiliser cette tâche de création de rapports pour décharger des événements de départ pour un stockage à long terme rentable et durable. La fonctionnalité Log Analytics fournit une interface de requête permettant d’afficher et de représenter sous forme graphique les événements individuels. Pour plus d’informations sur ces requêtes, consultez Requêtes Log Analytics plus loin dans cet article.
Vous pouvez également utiliser cette tâche avec un stockage de provenance en mémoire volatile. Dans de nombreux scénarios, vous pouvez ensuite obtenir une augmentation du débit. Toutefois, cette approche est risquée si vous devez conserver les données d’événement. Assurez-vous que le stockage volatile répond à vos exigences de durabilité pour les événements de départ. Pour plus d’informations, consultez Référentiel de provenance dans le Guide de l’administrateur système Apache NiFi.
Avant d’utiliser ce processus, créez un espace de travail Log Analytics dans votre abonnement Azure. Il est préférable de configurer l’espace de travail dans la même région que votre charge de travail.
Pour configurer la tâche de rapport de provenance :
- Ouvrez les paramètres du contrôleur dans NiFi.
- Sélectionnez le menu Tâches de création de rapports.
- Sélectionnez Créer une tâche de création de rapports.
- Sélectionnez la Tâche de création de rapports Azure Log Analytics.
La capture d’écran suivante montre le menu des propriétés de cette tâche de création de rapports :
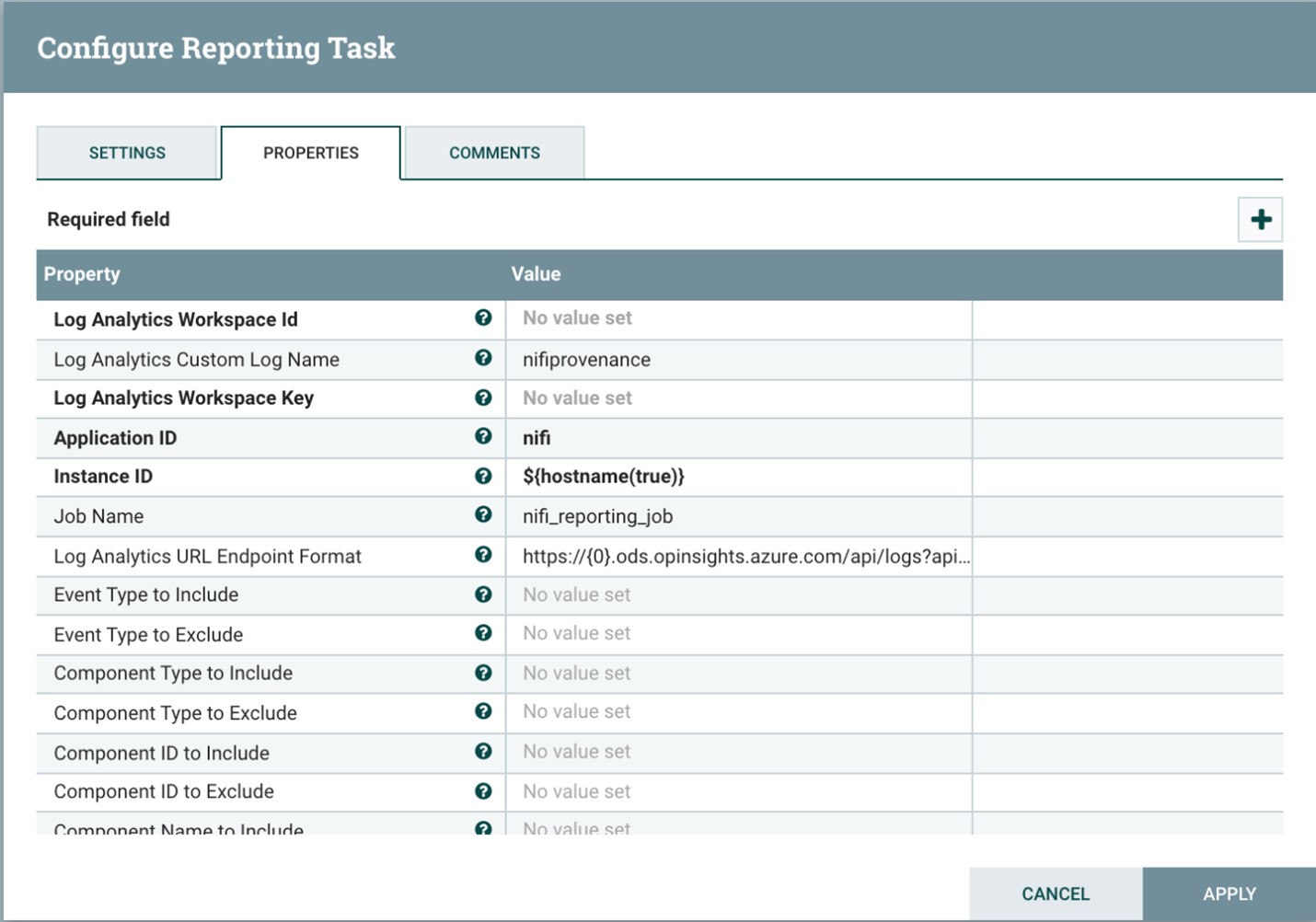
Deux propriétés sont requises :
- ID de l’espace de travail Log Analytics
- La clé d’espace de travail Log Analytics
Vous pouvez trouver ces valeurs dans le portail Azure en accédant à votre espace de travail Log Analytics.
D’autres options sont également disponibles pour la personnalisation et le filtrage des événements de provenance que le système envoie.
Sécurité
La sécurité fournit des garanties contre les attaques délibérées, et contre l’utilisation abusive de vos données et systèmes importants. Pour plus d’informations, consultez Vue d’ensemble du pilier Sécurité.
Vous pouvez sécuriser NiFi à partir d’un point de vue d’authentification et d’autorisation. Vous pouvez également sécuriser NiFi pour toutes les communications réseau, notamment :
- Au sein du cluster.
- Entre le cluster et ZooKeeper.
Consultez le Guide de l’administrateur Apache NiFi pour obtenir des instructions sur l’activation des options suivantes :
- Kerberos
- LDAP (Lightweight Directory Access Protocol)
- Authentification et autorisation basées sur le certificat
- SSL (Secure Sockets Layer) bidirectionnelle (SSL) pour les communications de cluster
Si vous activez l’accès client sécurisé ZooKeeper, configurez NiFi en ajoutant des propriétés associées à son fichier de configuration bootstrap.conf. Les entrées de configuration suivantes fournissent un exemple :
java.arg.18=-Dzookeeper.clientCnxnSocket=org.apache.zookeeper.ClientCnxnSocketNetty
java.arg.19=-Dzookeeper.client.secure=true
java.arg.20=-Dzookeeper.ssl.keyStore.location=/path/to/keystore.jks
java.arg.21=-Dzookeeper.ssl.keyStore.password=[KEYSTORE PASSWORD]
java.arg.22=-Dzookeeper.ssl.trustStore.location=/path/to/truststore.jks
java.arg.23=-Dzookeeper.ssl.trustStore.password=[TRUSTSTORE PASSWORD]
Pour obtenir des recommandations générales, consultez la base de référence de la sécurité Linux.
Sécurité du réseau
Lorsque vous implémentez cette solution, gardez à l’esprit les points suivants sur la sécurité réseau :
Groupes de sécurité réseau
Dans Azure, vous pouvez utiliser des groupes de sécurité réseau pour limiter le trafic réseau.
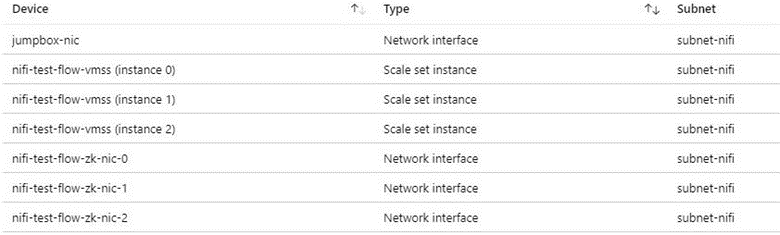
Nous recommandons un JumpBox pour la connexion au cluster NiFi pour les tâches d’administration. Utilisez cette machine virtuelle sécurisée avec un accès juste-à-temps (JIT) ou Azure Bastion. Configurez des groupes de sécurité réseau pour contrôler la façon dont vous accordez l’accès au JumpBox ou Azure Bastion. Vous pouvez obtenir l’isolement et le contrôle réseau en utilisant judicieusement des groupes de sécurité réseau sur les différents sous-réseaux de l’architecture.
La capture d’écran suivante montre les composants d’un réseau virtuel classique. Il contient un sous-réseau commun pour jumpBox, un groupe de machines virtuelles identiques et des machines virtuelles ZooKeeper. Cette topologie de réseau simplifiée regroupe les composants en un seul sous-réseau. Suivez les instructions de votre organisation en matière de séparation des tâches et de la conception du réseau.
Considérations relatives à l’accès Internet sortant
NiFi dans Azure n’a pas besoin d’accéder à l’Internet public pour s’exécuter. Si le flux de données n’a pas besoin d’un accès Internet pour récupérer des données, améliorez la sécurité du cluster en procédant comme suit pour désactiver l’accès Internet sortant :
Créez une règle de groupe de sécurité réseau supplémentaire dans le réseau virtuel.
Utilisez les paramètres suivants :
- Source :
Any - Destination :
Internet - Action :
Deny
- Source :

Une fois cette règle en place, vous pouvez toujours accéder à certains services Azure à partir du flux de données si vous configurez un point de terminaison privé dans le réseau virtuel. Utilisez Azure Private Link à cet effet. Ce service permet à votre trafic de circuler sur le réseau principal de Microsoft tout en ne nécessitant pas d’autre accès réseau externe. NiFi prend actuellement en charge Private Link pour les processeurs Stockage Blob et Data Lake Storage. Si un serveur NTP (Network Time Protocol) n’est pas disponible dans votre réseau privé, autorisez l’accès sortant à NTP. Pour plus d’informations, consultez Synchronisation temporelle pour les machines virtuelles Linux dans Azure.
Protection des données
Il est possible d’utiliser NiFi non sécurisé, sans chiffrement câblé, la gestion des identités et des accès (IAM) ou le chiffrement des données. Mais il est préférable de sécuriser les déploiements de production et du cloud public de plusieurs façons :
- Chiffrement de la communication avec le protocole TLS (Transport Layer Security)
- Utilisation d’un mécanisme d’authentification et d’autorisation pris en charge
- Chiffrement de données au repos
Le stockage Azure fournit un chiffrement transparent des données côté serveur. Mais à partir de la version 1.13.2, NiFi ne configure pas le chiffrement à câble ou IAM par défaut. Ce comportement peut changer dans une version ultérieure.
Les sections suivantes montrent comment sécuriser les déploiements de plusieurs manières :
- Activer le chiffrement de câble avec TLS
- Configurer l’authentification basée sur des certificats ou Microsoft Entra ID
- Gérer le stockage chiffré sur Azure
Chiffrement de disque
Pour améliorer la sécurité, utilisez Azure Disk Encryption. Pour une procédure détaillée, voir Chiffrer des disques de système d’exploitation et de données attachés dans un groupe de machines virtuelles identiques avec l’interface Azure CLI. Ce document contient également des instructions sur la façon de fournir votre propre clé de chiffrement. Les étapes suivantes décrivent un exemple de base pour NiFi qui fonctionnent pour la plupart des déploiements :
Pour activer le chiffrement de disque dans une instance de Key Vault existante, utilisez la commande Azure CLI suivante :
az keyvault create --resource-group myResourceGroup --name myKeyVaultName --enabled-for-disk-encryptionActivez le chiffrement des disques de données du groupe de machines virtuelles identiques à l’aide de la commande suivante :
az vmss encryption enable --resource-group myResourceGroup --name myScaleSet --disk-encryption-keyvault myKeyVaultID --volume-type DATAVous pouvez éventuellement utiliser une clé de chiffrement à clé (KEK). Utilisez la commande Azure CLI suivante pour chiffrer avec une KEK :
az vmss encryption enable --resource-group myResourceGroup --name myScaleSet \ --disk-encryption-keyvault myKeyVaultID \ --key-encryption-keyvault myKeyVaultID \ --key-encryption-key https://<mykeyvaultname>.vault.azure.net/keys/myKey/<version> \ --volume-type DATA
Remarque
Si vous avez configuré votre groupe de machines virtuelles identiques pour le mode de mise à jour manuelle, exécutez la commande update-instances. Incluez la version de la clé de chiffrement que vous avez stockée dans Key Vault.
Chiffrement en transit
NiFi prend en charge TLS 1.2 pour le chiffrement en transit. Ce protocole offre une protection pour l’accès utilisateur à l’interface utilisateur. Avec les clusters, le protocole protège la communication entre les nœuds NiFi. Il peut également protéger la communication avec ZooKeeper. Lorsque vous activez TLS, NiFi utilise un protocole TLS mutuel (mTLS) pour l’authentification mutuelle pour :
- Authentification du client basée sur les certificats si vous avez configuré ce type d’authentification.
- Toutes les communications intra-cluster.
Pour activer TLS, procédez comme suit :
Créez un magasin de clés et un trustStore pour les communications et l’authentification du client – serveur et intra-cluster.
Configurez
$NIFI_HOME/conf/nifi.properties. Définissez les valeurs suivantes :- Noms d’hôte
- Ports
- Propriétés du magasin de clés
- Propriétés du trustStore
- Propriétés de sécurité de cluster et ZooKeeper, le cas échéant
Configurez l’authentification dans
$NIFI_HOME/conf/authorizers.xml, généralement avec un utilisateur initial qui dispose d’une authentification basée sur les certificats ou d’une autre option.Vous pouvez éventuellement configurer mTLS et une stratégie de lecture de proxy entre NiFi et les proxys, les équilibrages de charge ou les points de terminaison externes.
Pour obtenir une procédure pas à pas complète, consultez Sécurisation de NiFi avec TLS dans la documentation du projet Apache.
Notes
À partir de la version 1.13.2 :
- NiFi n’active pas TLS par défaut.
- Il n’existe pas de prise en charge prête à l’emploi pour l’accès anonyme et utilisateur unique pour les instances NiFi compatibles TLS.
Pour activer TLS pour le chiffrement en transit, configurez un groupe d’utilisateurs et un fournisseur de stratégie pour l’authentification et l’autorisation dans $NIFI_HOME/conf/authorizers.xml. Pour plus d’informations, consultez Contrôle des accès et des identité, plus loin dans cet article.
Certificats, clés et magasins de clés
Pour prendre en charge TLS, générez des certificats, stockez-les dans le magasin de clés Java et TrustStore, puis distribuez-les sur un cluster NiFi. Il existe deux options générales pour les certificats :
- Certificats auto-signés
- Certificats signés par les autorités de certification (CA)
Avec les certificats signés par une autorité de certification, il est préférable d’utiliser une autorité de certification intermédiaire pour générer des certificats pour les nœuds du cluster.
Le magasin de clés et TrustStore sont les conteneurs clé et certificat de la plateforme Java. Le magasin de clés stocke la clé privée et le certificat d’un nœud dans le cluster. TrustStore stocke l’un des types de certificats suivants :
- Tous les certificats approuvés, pour les certificats auto-signés dans le magasin de clés
- Un certificat d’une autorité de certification, pour les certificats signés par une autorité de certification dans le magasin de clés
Gardez à l’esprit l’évolutivité de votre cluster NiFi lorsque vous choisissez un conteneur. Par exemple, vous souhaiterez peut-être augmenter ou diminuer le nombre de nœuds dans un cluster à l’avenir. Dans ce cas, choisissez des certificats signés par une autorité de certification dans le magasin de clés et un ou plusieurs certificats d’une autorité de certification dans TrustStore. Avec cette option, il n’est pas nécessaire de mettre à jour les TrustStore existants dans les nœuds existants du cluster. Un TrustStore existant approuve et accepte des certificats à partir de ces types de nœuds :
- Nœuds que vous ajoutez au cluster
- Nœuds qui remplacent les autres nœuds du cluster
Configuration de NiFi
Pour activer TLS pour NiFi, utilisez $NIFI_HOME/conf/nifi.properties pour configurer les propriétés dans ce tableau. Assurez-vous que les propriétés suivantes incluent le nom d’hôte que vous utilisez pour accéder à NiFi :
nifi.web.https.hostounifi.web.proxy.host- Nom désigné du certificat hôte ou autre nom de l’objet
Dans le cas contraire, un échec de vérification du nom d’hôte ou un échec de vérification de l’en-tête de l’hôte HTTP peut entraîner un refus de l’accès.
| Nom de la propriété | Description | Exemples de valeurs |
|---|---|---|
nifi.web.https.host |
Nom d’hôte ou adresse IP à utiliser pour l’interface utilisateur et l’API REST. Cette valeur doit être résolue en interne. Nous vous recommandons de ne pas utiliser un nom accessible publiquement. | nifi.internal.cloudapp.net |
nifi.web.https.port |
Port HTTPs à utiliser pour l’interface utilisateur et l’API REST. | 9443 (valeur par défaut) |
nifi.web.proxy.host |
Liste séparée par des virgules des noms d’hôte alternatifs que les clients utilisent pour accéder à l’interface utilisateur et à l’API REST. Cette liste comprend généralement le nom d’hôte spécifié comme autre nom de l’objet (SAN) dans le certificat de serveur. La liste peut également inclure n’importe quel nom d’hôte et port utilisé par un équilibreur de charge, un proxy ou un contrôleur d’entrée Kubernetes. | 40.67.218.235, 40.67.218.235:443, nifi.westus2.cloudapp.com, nifi.westus2.cloudapp.com:443 |
nifi.security.keystore |
Chemin d’accès à un magasin de clés JKS ou PKCS12 qui contient la clé privée du certificat. | ./conf/keystore.jks |
nifi.security.keystoreType |
Type de magasin de clés. | JKS ou PKCS12 |
nifi.security.keystorePasswd |
Mot de passe du magasin de clés. | O8SitLBYpCz7g/RpsqH+zM |
nifi.security.keyPasswd |
Mot de passe de la clé privée (facultatif). | |
nifi.security.truststore |
Le chemin d’accès à un JKS ou un trustStore PKCS12 qui contient des certificats ou des certificats d’autorité de certification qui authentifient les utilisateurs approuvés et les nœuds de cluster. | ./conf/truststore.jks |
nifi.security.truststoreType |
Type de trustStore. | JKS ou PKCS12 |
nifi.security.truststorePasswd |
Mot de passe de trustStore. | RJlpGe6/TuN5fG+VnaEPi8 |
nifi.cluster.protocol.is.secure |
État de TLS pour la communication intra-cluster. Si nifi.cluster.is.node est true, définissez cette valeur sur true pour activer le TLS de cluster. |
true |
nifi.remote.input.secure |
État de TLS pour la communication de site à site. | true |
L’exemple suivant montre comment ces propriétés s’affichent dans $NIFI_HOME/conf/nifi.properties. Notez que les valeurs nifi.web.http.host et nifi.web.http.port sont vides.
nifi.remote.input.secure=true
nifi.web.http.host=
nifi.web.http.port=
nifi.web.https.host=nifi.internal.cloudapp.net
nifi.web.https.port=9443
nifi.web.proxy.host=40.67.218.235, 40.67.218.235:443, nifi.westus2.cloudapp.com, nifi.westus2.cloudapp.com:443
nifi.security.keystore=./conf/keystore.jks
nifi.security.keystoreType=JKS
nifi.security.keystorePasswd=O8SitLBYpCz7g/RpsqH+zM
nifi.security.keyPasswd=
nifi.security.truststore=./conf/truststore.jks
nifi.security.truststoreType=JKS
nifi.security.truststorePasswd=RJlpGe6/TuN5fG+VnaEPi8
nifi.cluster.protocol.is.secure=true
Configuration de ZooKeeper
Pour obtenir des instructions sur l’activation de TLS dans Apache ZooKeeper pour les communications de quorum et l’accès client, consultez le Guide de l’administrateur ZooKeeper. Seules les versions 3.5.5 ou ultérieures prennent en charge cette fonctionnalité.
NiFi utilise ZooKeeper pour le clustering à zéro et la coordination des clusters. À partir de la version 1.13.0, NiFi prend en charge l’accès client sécurisé aux instances de ZooKeeper compatibles TLS. ZooKeeper stocke l’appartenance du cluster et l’état du processeur de l’étendue du cluster en texte brut. Il est donc important d’utiliser l’accès client sécurisé à ZooKeeper pour authentifier les demandes du client ZooKeeper. Chiffre également les valeurs sensibles en transit.
Pour activer TLS pour l’accès client NiFi à ZooKeeper, définissez les propriétés suivantes dans $NIFI_HOME/conf/nifi.properties. Si vous définissez nifi.zookeeper.client.secure true sans configurer les propriétés nifi.zookeeper.security, NiFi revient au magasin de clés et au trustStore que vous spécifiez dans nifi.securityproperties.
| Nom de la propriété | Description | Exemples de valeurs |
|---|---|---|
nifi.zookeeper.client.secure |
État du client TLS lors de la connexion à ZooKeeper. | true |
nifi.zookeeper.security.keystore |
Chemin d’accès à un magasin de clés JKS, PKCS12 ou PEM qui contient la clé privée du certificat présenté à ZooKeeper pour l’authentification. | ./conf/zookeeper.keystore.jks |
nifi.zookeeper.security.keystoreType |
Type de magasin de clés. | JKS, PKCS12, PEM, ou détection automatique par extension |
nifi.zookeeper.security.keystorePasswd |
Mot de passe du magasin de clés. | caB6ECKi03R/co+N+64lrz |
nifi.zookeeper.security.keyPasswd |
Mot de passe de la clé privée (facultatif). | |
nifi.zookeeper.security.truststore |
Chemin d’accès à un JKS, PKCS12 ou PEM trustStore qui contient des certificats ou des certificats d’autorité de certification qui sont utilisés pour authentifier ZooKeeper. | ./conf/zookeeper.truststore.jks |
nifi.zookeeper.security.truststoreType |
Type de trustStore. | JKS, PKCS12, PEM, ou détection automatique par extension |
nifi.zookeeper.security.truststorePasswd |
Mot de passe de trustStore. | qBdnLhsp+mKvV7wab/L4sv |
nifi.zookeeper.connect.string |
Chaîne de connexion à l’hôte ou au quorum ZooKeeper. Cette chaîne est une liste de valeurs host:port séparées par des virgules. En général, la valeur secureClientPort n’est pas la même que la valeur clientPort. Consultez votre configuration ZooKeeper pour obtenir la valeur correcte. |
zookeeper1.internal.cloudapp.net:2281, zookeeper2.internal.cloudapp.net:2281, zookeeper3.internal.cloudapp.net:2281 |
L’exemple suivant montre comment ces propriétés s’affichent dans $NIFI_HOME/conf/nifi.properties :
nifi.zookeeper.client.secure=true
nifi.zookeeper.security.keystore=./conf/keystore.jks
nifi.zookeeper.security.keystoreType=JKS
nifi.zookeeper.security.keystorePasswd=caB6ECKi03R/co+N+64lrz
nifi.zookeeper.security.keyPasswd=
nifi.zookeeper.security.truststore=./conf/truststore.jks
nifi.zookeeper.security.truststoreType=JKS
nifi.zookeeper.security.truststorePasswd=qBdnLhsp+mKvV7wab/L4sv
nifi.zookeeper.connect.string=zookeeper1.internal.cloudapp.net:2281,zookeeper2.internal.cloudapp.net:2281,zookeeper3.internal.cloudapp.net:2281
Pour plus d’informations sur la sécurisation de ZooKeeper avec TLS, consultez le Guide d’administration d’Apache NiFi.
Contrôle des accès et des identités
Dans NiFi, l’identité et le contrôle d’accès sont atteints par le biais de l’authentification et de l’autorisation des utilisateurs. Pour l’authentification utilisateur, NiFi offre plusieurs options à choisir : utilisateur unique, LDAP, Kerberos, Security Assertion Markup Language (SAML) et OpenID Connecter (OIDC). Si vous ne configurez pas d’option, NiFi utilise des certificats clients pour authentifier les utilisateurs sous HTTPS.
Si vous envisagez d’utiliser l’authentification multifacteur, nous vous recommandons la combinaison de Microsoft Entra ID et OIDC. Microsoft Entra ID prend en charge l’authentification unique (SSO) native cloud avec OIDC. Grâce à cette combinaison, les utilisateurs peuvent tirer parti de nombreuses fonctionnalités de sécurité d’entreprise :
- Journalisation et alertes sur les activités suspectes de comptes d’utilisateur
- Surveiller les tentatives d’accès à des informations d’identification désactivées
- Alerte sur un comportement de connexion de compte inhabituel
Pour l’autorisation, NiFi fournit la mise en œuvre basée sur les stratégies d’accès, de groupe et d’utilisateur. NiFi fournit cette mise en œuvre via UserGroupProviders et AccessPolicyProviders. Par défaut, les fournisseurs incluent les UserGroupProviders basés sur des fichiers, LDAP, Shell et Azure Graph. Avec AzureGraphUserGroupProvider, vous pouvez utiliser des groupes d’utilisateurs source à partir de Microsoft Entra ID. Vous pouvez ensuite affecter des stratégies à ces groupes. Pour obtenir des instructions de configuration, consultez le Guide d’administration Apache NiFi.
Les AccessPolicyProviders basés sur des fichiers et Apache Ranger sont actuellement disponibles pour la gestion et le stockage des stratégies d’utilisateur et de groupe. Pour plus d’informations, consultez la documentation Apache NiFi et la documentation Apache Ranger.
passerelle d’application
Une passerelle Application Gateway fournit un équilibreur de charge de couche 7 géré pour l’interface NiFi. Configurez la passerelle d’application pour utiliser le groupe de machines virtuelles identiques des nœuds NiFi comme pool principal.
Pour la plupart des installations NiFi, nous vous recommandons d’utiliser la configuration de Application Gateway suivante :
- Niveau : Standard
- Taille de la référence SKU : moyenne
- Nombre d’instances : au moins deux
Utilisez une sonde d’intégrité en vue de superviser l’intégrité du serveur web sur chaque nœud. Supprimez les nœuds défectueux de la rotation de l’équilibreur de charge. Cette approche facilite l’affichage de l’interface utilisateur lorsque l’ensemble du cluster est défectueux. Le navigateur vous dirige uniquement vers les nœuds qui sont actuellement sains et qui répondent aux demandes.
Deux sondes d’intégrité clés sont à prendre en compte. Ensemble, ils fournissent une pulsation régulière sur l’intégrité globale de chaque nœud du cluster. Configurez la première sonde d’intégrité pour pointer sur le chemin d’accès /NiFi. Cette sonde détermine l’intégrité de l’interface utilisateur NiFi sur chaque nœud. Configurez une deuxième sonde d’intégrité pour le chemin d’accès /nifi-api/controller/cluster . Cette sonde indique si chaque nœud est actuellement intègre et s’il est joint au cluster global.
Vous avez le choix entre deux options pour configurer l’adresse IP frontale de la passerelle d’application :
- Avec une adresse IP publique
- Avec une adresse IP de sous-réseau privé
N’incluez une adresse IP publique que si les utilisateurs ont besoin d’accéder à l’interface utilisateur via l’Internet public. Si l’accès Internet public pour les utilisateurs n’est pas nécessaire, accédez au serveur frontal de l’équilibreur de charge à partir d’un JumpBox dans le réseau virtuel ou via l’homologation sur votre réseau privé. Si vous configurez la passerelle d’application avec une adresse IP publique, nous vous recommandons d’activer l’authentification par certificat client pour NiFi et d’activer TLS pour l’interface utilisateur NiFi. Vous pouvez également utiliser un groupe de sécurité réseau dans le sous-réseau de passerelle d’application délégué pour limiter les adresses IP sources.
Diagnostic et surveillance de l’intégrité
Dans les paramètres de diagnostic de passerelle d’application, il existe une option de configuration pour l’envoi des métriques et des journaux d’accès. À l’aide de cette option, vous pouvez envoyer ces informations à partir de l’équilibreur de charge vers différents emplacements :
- Un compte de stockage
- Event Hubs
- Un espace de travail Log Analytics
L’activation de ce paramètre est utile pour déboguer les problèmes d’équilibrage de charge et pour obtenir des informations sur l’intégrité des nœuds de cluster.
La requête Log Analytics suivante montre l’intégrité du nœud de cluster dans le temps à partir d’une perspective de passerelle d’application. Vous pouvez utiliser une requête similaire pour générer des alertes ou des actions de réparation automatisées pour les nœuds défectueux.
AzureDiagnostics
| summarize UnHealthyNodes = max(unHealthyHostCount_d), HealthyNodes = max(healthyHostCount_d) by bin(TimeGenerated, 5m)
| render timechart
Le graphique suivant des résultats de la requête affiche une vue heure de l’intégrité du cluster :

Disponibilité
Lorsque vous implémentez cette solution, gardez à l’esprit les points suivants sur la disponibilité :
Équilibrage de charge
Utilisez un équilibreur de charge pour l’interface utilisateur afin d’augmenter la disponibilité de l’interface utilisateur pendant le temps d’arrêt du nœud.
Machines virtuelles distinctes
Pour augmenter la disponibilité, déployez le cluster ZooKeeper sur des machines virtuelles distinctes à partir des machines virtuelles du cluster NiFi. Pour plus d’informations sur la configuration de ZooKeeper, consultez Gestion de l’état dans le Guide de l’administrateur système Apache NiFi.
Zones de disponibilité
Déployez à la fois le groupe de machines virtuelles identiques NiFi et le cluster ZooKeeper dans une configuration inter-zones pour optimiser la disponibilité. Lorsque la communication entre les nœuds du cluster dépasse les zones de disponibilité, elle introduit une faible latence. Toutefois, cette latence a généralement un effet global minime sur le débit du cluster.
Groupes identiques de machines virtuelles
Nous vous recommandons de déployer les nœuds NiFi dans un seul groupe de machines virtuelles identiques qui couvre les zones de disponibilité, le cas échéant. Pour plus d’informations sur l’utilisation des groupes identiques de cette manière, consultez Créer un groupe de machines virtuelles identiques qui utilise les zones de disponibilité.
Surveillance
Pour surveiller l’intégrité et les performances d’un cluster NiFi, utilisez les tâches de création de rapports.
Génération de rapports d’analyse basés sur les tâches
Pour la surveillance, vous pouvez utiliser une tâche de création de rapports que vous configurez et exécutez dans NiFi. À mesure que les Diagnostics et la surveillance de l’intégrité le décrivent, Log Analytics fournit une tâche de création de rapports dans le pack Azure NiFi. Vous pouvez utiliser cette tâche de création de rapports pour intégrer la surveillance à Log Analytics et à des systèmes de journalisation et de surveillance existants.
Requêtes Log Analytics
Des exemples de requêtes dans les sections suivantes peuvent vous aider à commencer. Pour obtenir une vue d’ensemble de l’interrogation des données de Log Analytics, consultez Azure Monitor des requêtes de journal.
Les requêtes de journal dans Monitor et Azure Monitor utilisent une version du langage de requête Kusto. Toutefois, il existe des différences entre les requêtes de journal et les requêtes Kusto. Pour en savoir plus, consultez Vue d’ensemble de requête Kusto.
Pour plus d’informations, consultez les didacticiels suivants :
- Bien démarrer avec les requêtes de journal Azure Monitor.
- Prise en main de Log Analytics dans Azure Monitor
Tâche de création de rapports Log Analytics
Par défaut, NiFi envoie des données de métriques au tableau nifimetrics. Toutefois, vous pouvez configurer une destination différente dans les propriétés de la tâche de création de rapports. La tâche de création de rapports capture les mesures NiFi suivantes :
| Type de métrique | Nom de métrique |
|---|---|
| Mesures NiFi | FlowFilesReceived |
| Mesures NiFi | FlowFilesSent |
| Mesures NiFi | FlowFilesQueued |
| Mesures NiFi | BytesReceived |
| Mesures NiFi | BytesWritten |
| Mesures NiFi | BytesRead |
| Mesures NiFi | BytesSent |
| Mesures NiFi | BytesQueued |
| Métriques de l’état du port | InputCount |
| Métriques de l’état du port | InputBytes |
| Métriques de l’état de connexion | QueuedCount |
| Métriques de l’état de connexion | QueuedBytes |
| Métriques de l’état du port | OutputCount |
| Métriques de l’état du port | OutputBytes |
| Mesure de la machine virtuelle Java (JVM) | jvm.uptime |
| Métriques de JVM | jvm.heap_used |
| Métriques de JVM | jvm.heap_usage |
| Métriques de JVM | jvm.non_heap_usage |
| Métriques de JVM | jvm.thread_states.runnable |
| Métriques de JVM | jvm.thread_states.blocked |
| Métriques de JVM | jvm.thread_states.timed_waiting |
| Métriques de JVM | jvm.thread_states.terminated |
| Métriques de JVM | jvm.thread_count |
| Métriques de JVM | jvm.daemon_thread_count |
| Métriques de JVM | jvm.file_descriptor_usage |
| Métriques de JVM | jvm.gc.runs jvm.gc.runs.g1_old_generation jvm.gc.runs.g1_young_generation |
| Métriques de JVM | jvm.gc.time jvm.gc.time.g1_young_generation jvm.gc.time.g1_old_generation |
| Métriques de JVM | jvm.buff_pool_direct_capacity |
| Métriques de JVM | jvm.buff_pool_direct_count |
| Métriques de JVM | jvm.buff_pool_direct_mem_used |
| Métriques de JVM | jvm.buff_pool_mapped_capacity |
| Métriques de JVM | jvm.buff_pool_mapped_count |
| Métriques de JVM | jvm.buff_pool_mapped_mem_used |
| Métriques de JVM | jvm.mem_pool_code_cache |
| Métriques de JVM | jvm.mem_pool_compressed_class_space |
| Métriques de JVM | jvm.mem_pool_g1_eden_space |
| Métriques de JVM | jvm.mem_pool_g1_old_gen |
| Métriques de JVM | jvm.mem_pool_g1_survivor_space |
| Métriques de JVM | jvm.mem_pool_metaspace |
| Métriques de JVM | jvm.thread_states.new |
| Métriques de JVM | jvm.thread_states.waiting |
| Métriques au niveau du processeur | BytesRead |
| Métriques au niveau du processeur | BytesWritten |
| Métriques au niveau du processeur | FlowFilesReceived |
| Métriques au niveau du processeur | FlowFilesSent |
Voici un exemple de requête pour la métrique BytesQueued d’un cluster :
let table_name = nifimetrics_CL;
let metric = "BytesQueued";
table_name
| where Name_s == metric
| where Computer contains {ComputerName}
| project TimeGenerated, Computer, ProcessGroupName_s, Count_d, Name_s
| summarize sum(Count_d) by bin(TimeGenerated, 1m), Computer, Name_s
| render timechart
Cette requête produit un graphique semblable à celui de cette capture d’écran :

Notes
Lorsque vous exécutez NiFi sur Azure, vous n’êtes pas limité à la tâche de création de rapports Log Analytics. NiFi prend en charge les tâches de création de rapports pour de nombreuses technologies de surveillance tierces. Pour obtenir la liste des tâches de création de rapports prises en charge, consultez la section Tâches de création de rapports de l’index de documentation Apache NiFi.
Surveillance des infrastructures NiFi
Outre la tâche de création de rapports, installez l’extension de machine virtuelle Log Analytics sur les nœuds NiFi et ZooKeeper. Cette extension rassemble les journaux, les métriques supplémentaires au niveau de la machine virtuelle et les métriques de ZooKeeper.
Journaux personnalisés pour l’application NiFi, l’utilisateur, le démarrage et ZooKeeper
Pour capturer plus de journaux, procédez comme suit :
Sur le Portail Azure, sélectionnez Espaces de travail Log Analytics puis sélectionnez votre espace de travail.
Sous Paramètres, sélectionnez Journaux personnalisés.
Sélectionnez Ajouter un journal personnalisé.
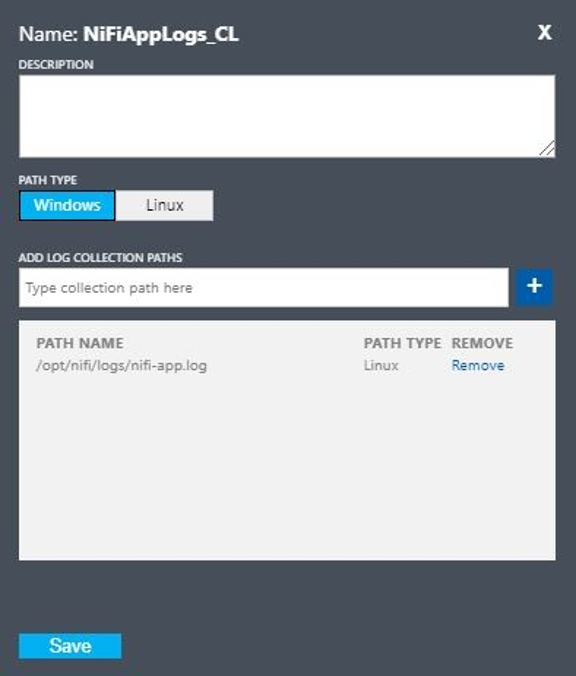
Configurez un journal personnalisé avec ces valeurs :
- Nom :
NiFiAppLogs - Type de chemin :
Linux - Nom du chemin :
/opt/nifi/logs/nifi-app.log
- Nom :
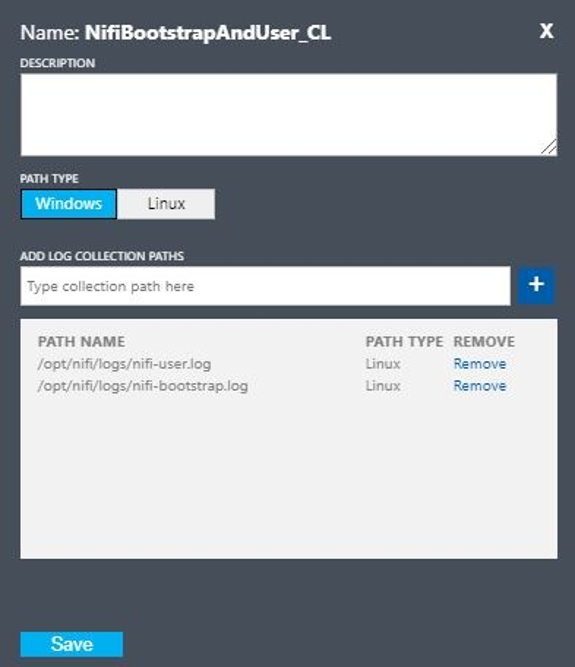
Configurez un journal personnalisé avec ces valeurs :
- Nom :
NiFiBootstrapAndUser - Type du premier chemin :
Linux - Nom du premier chemin :
/opt/nifi/logs/nifi-user.log - Type du deuxième chemin :
Linux - Nom du deuxième chemin :
/opt/nifi/logs/nifi-bootstrap.log
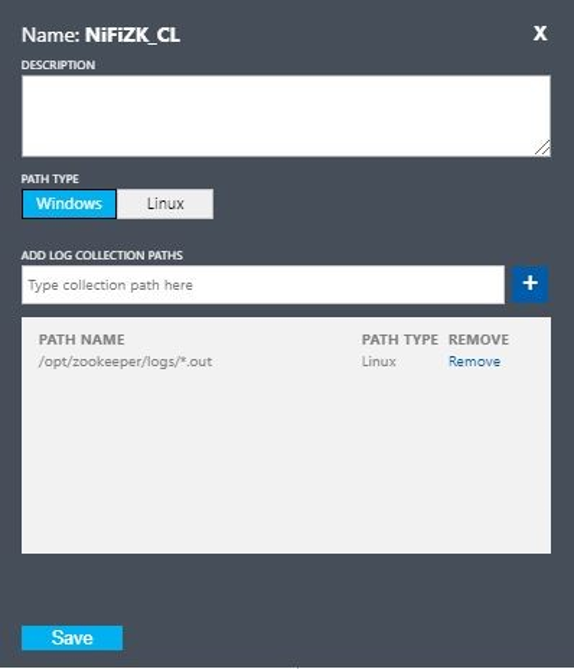
- Nom :
Configurez un journal personnalisé avec ces valeurs :
- Nom :
NiFiZK - Type de chemin :
Linux - Nom du chemin :
/opt/zookeeper/logs/*.out
- Nom :
Voici un exemple de requête de la table personnalisée NiFiAppLogs que le premier exemple a créé :
NiFiAppLogs_CL
| where TimeGenerated > ago(24h)
| where Computer contains {ComputerName} and RawData contains "error"
| limit 10
Cette requête produit des résultats similaires aux résultats suivants :

Configuration du journal d’infrastructure
Vous pouvez utiliser l’analyse pour surveiller et gérer les machines virtuelles ou les ordinateurs physiques. Ces ressources peuvent se trouver dans votre centre de ressources local ou dans un autre environnement Cloud. Pour configurer cette analyse, déployez l’agent de Log Analytics. Configurez l’agent pour qu’il rende compte à un espace de travail Log Analytics. Pour plus d’informations, consultez Présentation de l’agent Log Analytics.
La capture d’écran suivante montre un exemple de configuration de l’agent pour les machines virtuelles NiFi. Le tableau Perf stocke les données collectées.

Voici un exemple de requête pour les journaux d’application NiFi Perf :
let cluster_name = {ComputerName};
// The hourly average of CPU usage across all computers.
Perf
| where Computer contains {ComputerName}
| where CounterName == "% Processor Time" and InstanceName == "_Total"
| where ObjectName == "Processor"
| summarize CPU_Time_Avg = avg(CounterValue) by bin(TimeGenerated, 30m), Computer
Cette requête produit un rapport semblable à celui de cette capture d’écran :

Alertes
Utilisez l’analyse pour créer des alertes sur l’intégrité et les performances du cluster NiFi. Les exemples d’alertes sont les suivants :
- Le nombre total de files d’attente a dépassé un seuil.
- La valeur
BytesWrittenest inférieure à un seuil attendu. - La valeur
FlowFilesReceivedest inférieure à un seuil. - Le cluster est défectueux.
Pour plus d’informations concernant la configuration des alertes sur Monitor, consultez Vue d’ensemble des alertes sur Microsoft Azure.
Paramètres de configuration
Les sections suivantes présentent les configurations non par défaut recommandées pour NiFi et ses dépendances, notamment ZooKeeper et Java. Ces paramètres sont adaptés aux tailles de cluster possibles dans le Cloud. Définissez les propriétés dans les fichiers de configuration suivants :
$NIFI_HOME/conf/nifi.properties$NIFI_HOME/conf/bootstrap.conf$ZOOKEEPER_HOME/conf/zoo.cfg$ZOOKEEPER_HOME/bin/zkEnv.sh
Pour plus d’informations sur les propriétés et les fichiers de configuration disponibles, consultez le Guide de l’administrateur système Apache NiFi et le Guide de l’administrateur ZooKeeper.
NiFi
Pour un déploiement Azure, envisagez d’ajuster les propriétés dans $NIFI_HOME/conf/nifi.properties. Le tableau suivant répertorie les propriétés les plus importantes. Pour plus d’informations et de recommandations, consultez les listes de distribution Apache NiFi.
| Paramètre | Description | Default | Recommandation |
|---|---|---|---|
nifi.cluster.node.connection.timeout |
Délai d’attente lors de l’ouverture d’une connexion à d’autres nœuds de cluster. | 5 secondes | 60 secondes |
nifi.cluster.node.read.timeout |
Délai d’attente d’une réponse lors d’une demande adressée à d’autres nœuds de cluster. | 5 secondes | 60 secondes |
nifi.cluster.protocol.heartbeat.interval |
Fréquence de renvoi des pulsations au coordinateur de cluster. | 5 secondes | 60 secondes |
nifi.cluster.node.max.concurrent.requests |
Niveau de parallélisme à utiliser lors de la réplication d’appels HTTP comme les appels d’API REST vers d’autres nœuds de cluster. | 100 | 500 |
nifi.cluster.node.protocol.threads |
Taille initiale du pool de threads pour les communications entre clusters/répliquées. | 10 | 50 |
nifi.cluster.node.protocol.max.threads |
Nombre maximal de threads à utiliser pour les communications entre clusters/répliquées. | 50 | 75 |
nifi.cluster.flow.election.max.candidates |
Nombre de nœuds à utiliser lors de la détermination du déroulement actuel. Cette valeur courts-circuits le vote au nombre spécifié. | empty | 75 |
nifi.cluster.flow.election.max.wait.time |
Délai d’attente sur les nœuds avant de déterminer le déroulement actuel. | 5 minutes | 5 minutes |
Comportement du cluster
Quand vous configurez des clusters, gardez à l’esprit les points suivants.
Délai d’expiration
Pour garantir l’intégrité globale d’un cluster et de ses nœuds, il peut être avantageux d’augmenter les délais d’attente. Cette pratique permet de garantir que les échecs ne sont pas dus à des problèmes réseau temporaires ou à des charges élevées.
Dans un système distribué, les performances des systèmes individuels varient. Cette variation comprend les communications réseau et la latence, ce qui affecte généralement la communication entre les nœuds entre les clusters. L’infrastructure réseau ou le système lui-même peut provoquer cette variation. Par conséquent, la probabilité de variation est très probablement dans les clusters de grande taille des systèmes. Dans les applications Java en cours de charge, les pauses en garbage collection (GC) de la machine virtuelle Java (JVM) peuvent également affecter les temps de réponse des requêtes.
Utilisez les propriétés des sections suivantes pour configurer les délais d’attente en fonction des besoins de votre système :
nifi.cluster.node.connection.timeout et nifi.cluster.node.read.timeout
La propriété nifi.cluster.node.connection.timeout spécifie le délai d’attente lors de l’ouverture d’une connexion. La propriété nifi.cluster.node.read.timeout spécifie le délai d’attente lors de la réception de données entre les demandes. La valeur par défaut de chaque propriété est de cinq secondes. Ces propriétés s’appliquent aux requêtes de nœud à nœud. L’amélioration de ces valeurs permet d’atténuer plusieurs problèmes connexes :
- En cours de déconnexion par le coordinateur de cluster en raison d’interruptions de pulsation
- Échec de l’extraction du workflow du coordinateur lors de la jonction du cluster
- Établissement de communications de site à site (S2S) et d’équilibrage de charge
À moins que votre cluster ne dispose d’un très petit groupe identique, par exemple trois nœuds ou moins, utilisez des valeurs supérieures aux valeurs par défaut.
nifi.cluster.protocol.heartbeat.interval
Dans le cadre de la stratégie de clustering NiFi, chaque nœud émet une pulsation pour communiquer son état sain. Par défaut, les nœuds envoient des pulsations toutes les cinq secondes. Si le coordinateur de cluster détecte que huit pulsations d’une ligne d’un nœud ont échoué, il déconnecte le nœud. Augmentez l’intervalle défini dans la propriété nifi.cluster.protocol.heartbeat.interval pour faciliter la prise en charge des pulsations lentes et empêcher le cluster de déconnecter les nœuds inutilement.
Accès concurrentiel
Utilisez les propriétés des sections suivantes pour configurer les paramètres de concurrence :
nifi.cluster.node.protocol.threads et nifi.cluster.node.protocol.max.threads
La propriété nifi.cluster.node.protocol.max.threads spécifie le nombre maximal de threads à utiliser pour toutes les communications en cluster, telles que l’équilibrage de charge S2S et l’agrégation d’interface utilisateur. La valeur par défaut pour cette propriété est 50 threads. Pour les clusters de grande taille, augmentez cette valeur pour prendre en compte le plus grand nombre de requêtes nécessaires à ces opérations.
La propriété nifi.cluster.node.protocol.threads détermine la taille initiale du pool de threads. La valeur par défaut est 10 threads. Cette valeur est minimale. Ce nombre augmente jusqu’à la valeur maximale définie dans nifi.cluster.node.protocol.max.threads. Augmentez la valeur nifi.cluster.node.protocol.threads pour les clusters qui utilisent un groupe à grande échelle au lancement.
nifi.cluster.node.max.concurrent.requests
De nombreuses requêtes HTTP, telles que les appels d’API REST et les appels d’interface utilisateur, doivent être répliquées sur d’autres nœuds du cluster. À mesure que la taille du cluster augmente, un nombre grandissant de demandes sont répliquées. La propriété nifi.cluster.node.max.concurrent.requests limite le nombre de demandes en suspens. Sa valeur doit être supérieure à la taille de cluster attendue. La valeur par défaut est 100 demandes simultanées. À moins que vous n’exécutiez un petit cluster de trois nœuds ou moins, vous pouvez empêcher les demandes ayant échoué en accroissant cette valeur.
Élection de flux
Utilisez les propriétés des sections suivantes pour configurer les paramètres d’élection de flux :
nifi.cluster.flow.election.max.candidates
NiFi utilise le clustering à l’origine zéro, ce qui signifie qu’il n’existe pas de nœud spécifique faisant autorité. Par conséquent, les nœuds votent sur la définition de workflow qui compte comme le bon. Ils votent également pour décider quels nœuds rejoignent le cluster.
Par défaut, la propriété nifi.cluster.flow.election.max.candidates correspond à la durée d’attente maximale que la propriété spécifie nifi.cluster.flow.election.max.wait.time. Lorsque cette valeur est trop élevée, le démarrage peut être lent. La valeur par défaut pour nifi.cluster.flow.election.max.wait.time est de cinq minutes. Définissez le nombre maximal de candidats sur une valeur non vide, 1 par exemple ou supérieur, pour vous assurer que l’attente n’est pas plus longue que nécessaire. Si vous définissez cette propriété, assignez-lui une valeur qui correspond à la taille du cluster ou une fraction majoritaire de la taille de cluster attendue. Pour les petits clusters statiques de 10 nœuds ou moins, définissez cette valeur sur le nombre de nœuds dans le cluster.
nifi.cluster.flow.election.max.wait.time
Dans un environnement de cloud élastique, le temps nécessaire pour approvisionner les hôtes affecte le temps de démarrage de l’application. La propriété nifi.cluster.flow.election.max.wait.time détermine la durée d’attente de NiFi avant de décider d’un flux. Faites en sorte que cette valeur soit proportionnelle à la durée de lancement globale du cluster à sa taille initiale. Dans les tests initiaux, cinq minutes sont plus que suffisantes dans toutes les régions Azure avec les types d’instances recommandés. Toutefois, vous pouvez augmenter cette valeur si la durée d’approvisionnement régulière dépasse la valeur par défaut.
Java
Nous vous recommandons d’utiliser une version LTS de Java. Parmi ces versions, Java 11 est légèrement préférable à Java 8, car Java 11 prend en charge une implémentation de garbage collection plus rapide. Toutefois, il est possible d’avoir un déploiement NiFi à hautes performances à l’aide de l’une ou l’autre version.
Les sections suivantes décrivent les configurations JVM courantes à utiliser lors de l’exécution de NiFi. Définissez les paramètres JVM dans le fichier de configuration de démarrage à l’adresse $NIFI_HOME/conf/bootstrap.conf.
Garbage collector
Si vous exécutez Java 11, nous vous recommandons d’utiliser le garbage collector G1 (G1GC) dans la plupart des cas. G1GC a amélioré les performances par rapport à ParallelGC, car G1GC réduit la longueur des pauses GC. G1GC est la valeur par défaut dans Java 11, mais vous pouvez la configurer explicitement en définissant la valeur suivante dans bootstrap.conf :
java.arg.13=-XX:+UseG1GC
Si vous exécutez Java 8, n’utilisez pas G1GC. Utilisez ParallelGC à la place. L’implémentation Java 8 de G1GC présente des lacunes qui vous empêchent de l’utiliser avec les implémentations de référentiel recommandées. ParallelGC est plus lent que G1GC. Mais avec ParallelGC, vous pouvez toujours avoir un déploiement NiFi à hautes performances avec Java 8.
Segment de mémoire (heap)
Un ensemble de propriétés dans le fichier bootstrap.conf détermine la configuration du tas JVM NiFi. Pour un flux standard, configurez un segment de mémoire de 32 Go à l’aide des paramètres suivants :
java.arg.3=-Xmx32g
java.arg.2=-Xms32g
Pour choisir la taille de tas optimale à appliquer au processus JVM, prenez en compte deux facteurs :
- Les caractéristiques du workflow
- La façon dont NiFi utilise la mémoire dans son traitement
Consultez la documentation détaillée sur Apache NiFi en profondeur.
Rendez le tas aussi grand que nécessaire pour répondre aux exigences de traitement. Cette approche réduit la durée des pauses GC. Pour des informations générales sur les garbage collection Java, consultez le Guide de paramétrage garbage collection pour votre version de Java.
Lorsque vous ajustez les paramètres de mémoire de JVM, tenez compte des facteurs importants suivants :
Nombre d’enregistrements de données FlowFilesou NiFi qui sont actifs pendant une période donnée. Ce nombre comprend les FlowFiles sous pression arrière ou en file d’attente.
Nombre d’attributs définis dans FlowFiles.
Quantité de mémoire requise par un processeur pour traiter un élément de contenu particulier.
La façon dont un processeur traite les données :
- Diffusion de données
- Utilisation de processeurs orientés enregistrement
- Conservation de toutes les données en mémoire en même temps
Ces détails sont importants. Pendant le traitement, NiFi contient des références et des attributs pour chaque FlowFile en mémoire. À des performances optimales, la quantité de mémoire utilisée par le système est proportionnelle au nombre de FlowFiles Live et à tous les attributs qu’ils contiennent. Ce nombre comprend les FlowFiles mis en file d’attente. NiFi peut basculer sur le disque. Mais évitez cette option, car elle nuit aux performances.
Gardez également à l’esprit l’utilisation de la mémoire des objets de base. Plus précisément, rendez le tas suffisamment grand pour contenir des objets en mémoire. Tenez compte des conseils suivants pour la configuration des paramètres de mémoire :
- Exécutez votre flux avec des données représentatives et une faible sollicitation en commençant par le paramètre
-Xmx4G, puis en optimisant la mémoire de manière conservatrice si nécessaire. - Exécutez votre flux avec des données représentatives et les pics de sollicitation en commençant par le paramètre
-Xmx4G, puis en optimisant la taille de cluster de manière conservatrice si nécessaire. - Profilez l’application pendant l’exécution du flux à l’aide d’outils tels que VisualVM et YourKit.
- Si les augmentations conservatrices du tas n’améliorent pas de manière significative les performances, envisagez de reconcevoir des flux, des processeurs et d’autres aspects de votre système.
Paramètres JVM supplémentaires
Le tableau suivant répertorie les options JVM supplémentaires. Il fournit également les valeurs qui ont fonctionné le mieux dans les tests initiaux. Les tests ont examiné l’activité GC et l’utilisation de la mémoire et ont utilisé le profilage attentif.
| Paramètre | Description | JVM par défaut | Recommandation |
|---|---|---|---|
InitiatingHeapOccupancyPercent |
Quantité de tas en cours d’utilisation avant le déclenchement d’un cycle de marquage. | 45 | 35 |
ParallelGCThreads |
Nombre de threads utilisés par GC. Cette valeur est limitée pour limiter l’effet global sur le système. | 5/8 du nombre de processeurs virtuels | 8 |
ConcGCThreads |
Nombre de threads GC à exécuter en parallèle. Cette valeur est augmentée pour tenir compte du ParallelGCThreads limité. | 1/4 de la valeur ParallelGCThreads |
4 |
G1ReservePercent |
Pourcentage de mémoire réservée à conserver libre. Cette valeur est augmentée pour éviter l’épuisement de l’espace, ce qui permet d’éviter la totalité du GC. | 10 | 20 |
UseStringDeduplication |
Indique s’il faut essayer d’identifier et de dédupliquer les références aux chaînes identiques. L’activation de cette fonctionnalité peut entraîner des économies de mémoire. | - | present |
Configurez ces paramètres en ajoutant les entrées suivantes à NiFi bootstrap.conf :
java.arg.17=-XX:+UseStringDeduplication
java.arg.18=-XX:G1ReservePercent=20
java.arg.19=-XX:ParallelGCThreads=8
java.arg.20=-XX:ConcGCThreads=4
java.arg.21=-XX:InitiatingHeapOccupancyPercent=35
ZooKeeper
Pour une meilleure tolérance de panne, exécutez ZooKeeper en tant que cluster. Adoptez cette approche même si la plupart des déploiements NiFi placent une charge relativement modeste sur ZooKeeper. Activez le clustering pour ZooKeeper explicitement. Par défaut, ZooKeeper s’exécute en mode mono-serveur. Pour plus d’informations, consultez Configuration en cluster (multiserveur) dans le Guide de l’administrateur ZooKeeper.
À l’exception des paramètres de clustering, utilisez les valeurs par défaut de votre configuration ZooKeeper.
Si vous disposez d’un cluster NiFi volumineux, vous devrez peut-être utiliser un plus grand nombre de serveurs ZooKeeper. Pour les plus petites tailles de clusters, les plus petites tailles de machines virtuelles et les disques gérés SSD Standard sont suffisants.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Muazma Zahid | Principal PM Manager
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
Le matériel et les recommandations de ce document proviennent de plusieurs sources :
- Expérimentation
- Bonnes pratiques Azure
- Connaissances de la communauté NiFi, meilleures pratiques et documentation
Pour plus d’informations, consultez les ressources suivantes :
- Guide de l’administrateur système Apache NiFi
- Listes de distribution Apache NiFi
- Meilleures pratiques de Cloudera pour la configuration d’une installation NiFi haute performance
- Stockage Azure Premium : conception sous le signe de la haute performance
- Résoudre les problèmes de performances des machines virtuelles Azure sur Linux ou Windows