Approches architecturales pour les solutions multilocataires IA et ML
Le nombre de solutions multilocataires basées sur l’intelligence artificielle (AI) et le Machine Learning (ML) ne cesse de croître. Une solution IA/ML multilocataire propose des capacités de ML à un nombre illimité de locataires. En général, les locataires ne peuvent ni voir ni partager les données d’un autre locataire, mais dans certains cas, ils peuvent utiliser les mêmes modèles que d’autres locataires.
Les architectures d’IA/ML multilocataires doivent prendre en considération les besoins en matière de données et de modèles, ainsi que les ressources de calcul nécessaires à l’entraînement des modèles et la réalisation de l’inférence à partir des modèles. Il est important de réfléchir à la façon dont les modèles d’IA/ML multilocataires sont déployés, distribués et orchestrés, et de s’assurer que votre solution est précise, fiable et scalable.
Alors que les technologies d’IA générative, alimentées par des modèles de langage de grande et petite taille, gagnent en popularité, il est crucial d’établir des pratiques opérationnelles efficaces et des stratégies pour gérer ces modèles dans des environnements de production grâce à l’adoption des opérations de Machine Learning (MLOps) et GenAIOps (parfois connues sous le nom de LLMOps).
Principaux éléments et exigences à prendre en compte
Lorsque vous utilisez l’intelligence artificielle et le machine learning, il est important de prendre en compte vos besoins en matière d’entraînement et d’inférence de façon distincte. L’entraînement vise à créer un modèle prédictif à partir d’un ensemble de données. Vous effectuez l’inférence lorsque vous vous servez du modèle pour prédire quelque chose dans votre application. Chacun de ces processus présente des exigences différentes. Dans une solution multilocataire, vous devez réfléchir à la façon dont votre modèle de location influe sur chaque processus. En prenant en compte chacune de ces exigences, vous pouvez garantir la précision des résultats offerts par votre solution, son niveau de performance sous forte charge, son rapport coût-efficacité et sa scalabilité pour votre croissance future.
Isolation des locataires
Veillez à ce que les locataires n’aient pas un accès non autorisé ou indésirable aux données ou modèles d’autres locataires. Traitez les modèles avec la même sensibilité que les données brutes qui les ont été entraînés. Veillez à ce que vos locataires comprennent bien la façon dont leurs données sont utilisées pour l’entraînement des modèles et comment les modèles entraînés sur les données d’autres locataires peuvent être utilisés à des fins d’inférence sur leurs charges de travail.
Il existe trois approches courantes en matière d’utilisation de modèles ML dans les solutions multilocataires : les modèles propres au locataire, les modèles partagés et les modèles partagés ajustés.
Modèles propres au locataire
Les modèles propres au locataire sont entraînés uniquement sur les données d’un même locataire avant d’être appliqués à celui-ci. Les modèles propres au locataire sont indiqués quand les données des locataires sont sensibles ou qu’il y a peu à apprendre des données fournies par un locataire et que vous appliquez le modèle à un autre locataire. Le diagramme suivant illustre la façon dont vous pourriez créer une solution avec des modèles propres au locataire pour deux locataires :
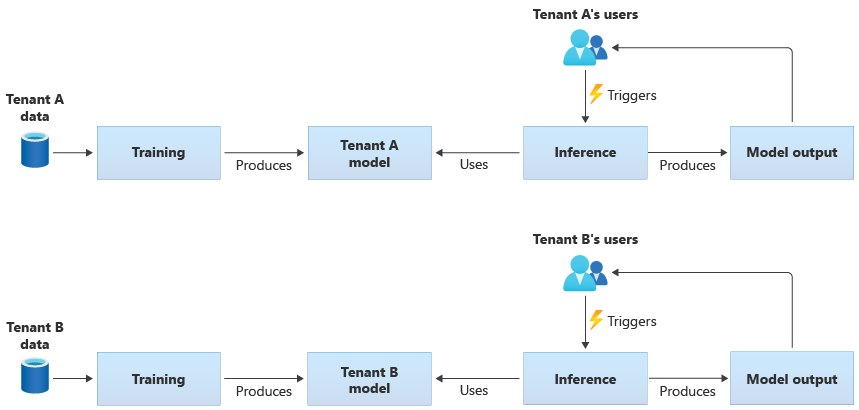
Modèles partagés
Dans les solutions qui utilisent des modèles partagés, tous les locataires effectuent une inférence à partir d’un même modèle partagé. Les modèles partagés peuvent être des modèles préentraînés que vous vous procurez ou obtenez auprès d’une source communautaire. Le diagramme suivant illustre la façon dont un même modèle préentraîné peut être utilisé par tous les locataires pour l’inférence :
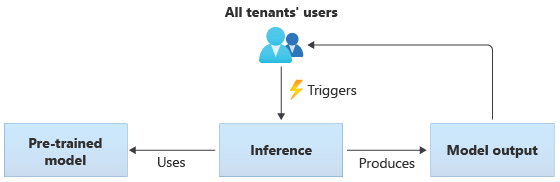
Vous pouvez aussi créer vos propres modèles partagés en les entraînant à partir des données fournies par tous vos locataires. Le diagramme suivant illustre un modèle partagé unique, qui est entraîné sur les données de tous les locataires :
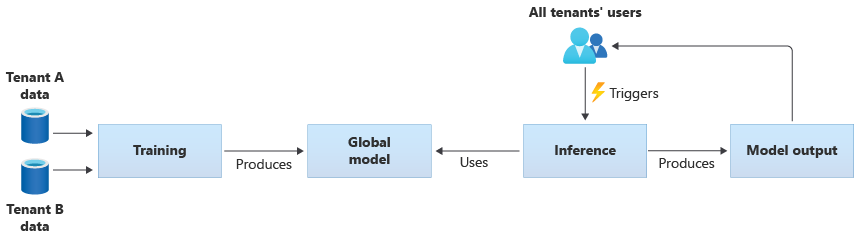
Important
Si vous entraînez un modèle partagé à partir des données de vos locataires, vérifiez qu’ils ont bien compris que leurs données allaient être utilisées et qu’ils sont d’accord. Vérifiez que les informations d’identification sont supprimées des données de vos locataires.
Envisagez une solution si un locataire s’oppose à ce que ses données servent à entraîner un modèle destiné à être appliqué à un autre locataire. Par exemple, auriez-vous la possibilité d’exclure les données d’un certain locataire du jeu de données d’entraînement ?
Modèles partagés ajustés
Vous pouvez aussi choisir de vous procurer un modèle de base préentraîné pour le faire évoluer par des ajustements afin de le rendre applicable à chacun de vos locataires, à partir de leurs propres données. Le diagramme suivant illustre cette approche :
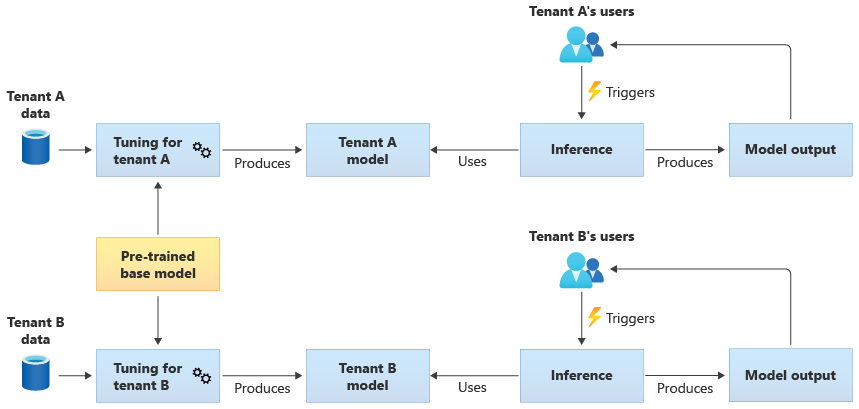
Extensibilité
Réfléchissez aux effets de la croissance de votre solution sur votre utilisation de composants IA et ML. « Croissance » peut renvoyer à une augmentation du nombre de locataires, de la quantité de données stockées pour chaque locataire, du nombre d’utilisateurs et du volume de demandes envoyées à votre solution.
Entraînement : les ressources nécessaires à l’entraînement de vos modèles varient en fonction de plusieurs facteurs. Ces facteurs peuvent être le nombre de modèles dont vous avez besoin pour l’entraînement, la quantité de données avec laquelle vous entraînez les modèles ou encore la fréquence à laquelle vous entraînez ou réentraînez les modèles. Si vous créez des modèles propres au locataire, vos besoins en ressources de calcul et en stockage croîtront probablement à mesure que le nombre de locataires augmentera. Si vous créez des modèles partagés et les entraînez à partir des données de tous vos locataires, il est moins probable que les ressources destinées à l’entraînement évolueront au même rythme que le nombre de locataires. Cependant, une accroissement de la quantité globale de données d’entraînement aura un impact sur les ressources consommées pour l’entraînement des modèles partagés et propres au locataire.
Inférence : les ressources nécessaire à l’inférence sont généralement proportionnelles au nombre de demandes qui accèdent aux modèles pour l’inférence. Plus le nombre de locataires augmente, plus le nombre de demandes a également des chances d’augmenter.
L’utilisation de services Azure qui assurent une bonne scalabilité constitue une bonne pratique générale. Sachant que les charges de travail IA/ML ont tendance à utiliser des conteneurs, Azure Kubernetes Service (AKS) et Azure Container Instances (ACI) sont souvent privilégiés pour les charges de travail IA/ML. AKS s’avère généralement un bon choix en termes de scalabilité et permet une mise à l’échelle dynamique des ressources de calcul en fonction de la demande. Si, pour les petites charges de travail, ACI constitue une plateforme de calcul facile à configurer, sa mise à l’échelle n’est pas aussi simple qu’AKS.
Performances
Prenez en considération les exigences de performances pour les composants IA/ML de votre solution, aussi bien pour l’entraînement que pour l’inférence. Il est important de clarifier vos besoins en matière de latence et de performances pour chaque processus, de façon à pouvoir établir des mesures et à apporter les amélioration nécessaires.
Entraînement : l’entraînement se présente souvent sous la forme d’un processus de traitement par lots, ce qui signifie qu’il n’est pas forcément aussi sensible aux performances que les autres parties de votre charge de travail. Cependant, vous devez veiller à provisionner suffisamment de ressources pour assurer un entraînement de modèle efficace, y compris lorsque vous procédez à une mise à l’échelle.
Inférence : l’inférence est un processus sensible à la latence, qui demande souvent une réponse rapide voire en temps réel. Même si vous n’avez pas besoin d’assurer une inférence en temps réel, veillez à surveiller le niveau de performance de votre solution et à utiliser les services appropriés pour optimiser votre charge de travail.
Envisagez d’utiliser les capacités de calcul hautes performances d’Azure pour vos charges de travail d’IA et de ML. Azure propose différents types de machines virtuelles et d’autres instances matérielles. Déterminez si l’utilisation de processeurs, de GPU, de FPGA ou d’autres environnements à accélération matérielle pourrait profiter à votre solution. Par ailleurs, Azure assure une inférence en temps réel au moyen de GPU NVIDIA, y compris des serveurs d’inférence NVIDIA Triton. Pour les besoins en calcul de faible priorité, envisagez d’utiliser des pools de nœuds spot AKS. Pour en savoir plus sur l’optimisation des services de calcul dans une solution multilocataire, consultez Approches architecturales pour le calcul dans les solutions multilocataires.
Dans le mesure où l’entraînement de modèle suppose de nombreuses interactions avec vos magasins de données, il est également important de prendre en compte votre stratégie de données et le niveau de performance proposé par votre couche Données. Pour plus d’informations sur la multilocation et les services de données, consultez Approches architecturales pour le stockage et les données dans les solutions multilocataires.
Envisagez de profiler le niveau de performance de votre solution. Par exemple, Azure Machine Learning propose des capacités de profilage que vous pouvez exploiter au moment de développer et d’instrumenter votre solution.
Complexité de l’implémentation
Quand vous créez une solution destinée à utiliser l’IA et le ML, vous pouvez choisir d’utiliser des composants prédéfinis ou de créer des composants personnalisés. Vous avez deux décisions importantes à prendre. La première porte sur la plateforme ou le service que vous allez utiliser pour l’IA et le ML. La deuxième consiste à déterminer si vous allez utiliser des modèles préentraînés ou bien créer vos propres modèles personnalisés.
Plateformes : les services Azure que vous pouvez utiliser pour vos charges de travail IA et ML sont nombreux. Par exemple, Azure AI Services et Azure OpenAI Service fournissent des API pour effectuer des inférences sur des modèles prédéfinis, et Microsoft gère les ressources sous-jacentes. Azure AI Services vous permet de déployer rapidement une nouvelle solution, mais vous donne moins de contrôle sur la manière dont l’entraînement et l’inférence sont réalisés, et il pourrait ne pas convenir à tous les types de charges de travail. En revanche, Azure Machine Learning est une plateforme qui vous permet de créer, entraîner et utiliser vos propres modèles ML. Azure Machine Learning procure contrôle et flexibilité, mais accentue la complexité de votre conception et de votre implémentation. Passez en revue les produits et technologies de machine learning de Microsoft pour choisir une approche de façon avisée.
Modèles : Même si vous n’utilisez pas un modèle complet fourni par un service comme Azure AI Services, vous pouvez toujours accélérer votre développement en utilisant un modèle pré-entraîné. Si un modèle préentraîné ne répond pas précisément à vos besoins, vous pouvez le développer en appliquant une technique appelée apprentissage de transfert ou ajustement. L’apprentissage de transfert vous permet de développer un modèle existant et de l’appliquer à un autre domaine. Par exemple, si vous créez un service de recommandations musicales multilocataire, vous pouvez envisager d’utiliser un modèle de recommandations musicales préentraîné et d’utiliser l’apprentissage de transfert pour entraîner le modèle en fonction des goûts musicaux d’un utilisateur déterminé.
En utilisant des plateformes ML prédéfinies comme Azure AI Services ou Azure OpenAI Service, ou un modèle préentraîné, vous pouvez réduire considérablement vos coûts initiaux de recherche et développement. L’utilisation de plateformes prédéfinies peut vous faire gagner plusieurs mois de recherche et vous éviter d’avoir à recruter des scientifiques de données hautement qualifiés pour entraîner, concevoir et optimiser des modèles.
Optimisation des coûts
En général, les coûts induits par les charges de travail IA et ML sont largement imputables aux ressources de calcul nécessaires à l’entraînement et à l’inférence des modèles. Consultez Approches architecturales pour le calcul dans les solutions multilocataires pour savoir comment optimiser le coût de votre charge de travail de calcul en fonction de vos besoins.
Au moment de planifier vos coûts d’IA et de ML, prenez en considération les points suivants :
- Déterminez les références SKU de calcul à utiliser pour l’entraînement. Pour cela, reportez-vous aux recommandations pour Azure Machine Learning à titre d’exemple.
- Déterminez les références SKU de calcul à utiliser pour l’inférence. Pour obtenir un exemple d’estimation de coûts pour l’inférence, reportez-vous aux recommandations pour Azure Machine Learning.
- Supervisez votre utilisation. En observant l’utilisation de vos ressources de calcul, vous pouvez déterminer s’il est nécessaire d’accroître leur capacité en déployant différentes références SKU ou de les mettre à l’échelle à mesure que vos besoins évoluent. Consultez Supervision d’Azure Machine Learning.
- Optimisez votre environnement de clustering de calcul. Quand vous utilisez des clusters de calcul, supervisez leur utilisation ou configurez la mise à l’échelle automatique pour effectuer un scale-down au niveau des nœuds de calcul.
- Partagez vos ressources de calcul. Déterminez si vous pouvez optimiser le coût de vos ressources de calcul en les partageant entre plusieurs locataires.
- Tenez compte de votre budget. Déterminez si votre budget est fixe et supervisez votre consommation en conséquence. Vous pouvez définir des budgets pour éviter les dépassements et pour allouer des quotas en fonction de la priorité des locataires.
Approches et modèles à prendre en compte
Azure offre un ensemble de services pour permettre les charges de travail IA et ML. Plusieurs approches architecturales sont couramment utilisées dans les solutions multilocataires : utilisation de solutions IA/ML prédéfinies, création d’une architecture IA/ML personnalisée à l’aide d’Azure Machine Learning et utilisation de l’une des plateformes d’analytique Azure.
Utiliser des services IA/ML prédéfinis
Une bonne pratique consiste à essayer d’utiliser des services IA/ML prédéfinis, dans la mesure du possible. Tel est le cas, par exemple, si votre organisation envisage l’IA/ML et qu’elle souhaite une intégration rapide avec un service utile. De même, vous pouvez avoir des besoins limités qui ne vous imposent pas d’entraîner et développement des modèles ML. Les services ML prédéfinis vous permettent d’utiliser l’inférence sans créer et entraîner vos propres modèles.
Azure propose plusieurs services offrant une technologie d’IA et ML dans divers domaines, notamment la compréhension du langage, la reconnaissance vocale, la connaissance, la reconnaissance de documents et de formulaires, et la vision par ordinateur. Les services d’IA/ML prédéfinis d’Azure incluent Azure AI Services, Azure OpenAI Service, Azure AI Search, et Azure AI Document Intelligence. Chaque service propose une interface simple pour l’intégration ainsi qu’une collection de modèles préentraînés et testés. En tant que services gérés, ils offrent des contrats de niveau de service et demandent une configuration ou une gestion continue limitées. Vous n’avez pas besoin de développer ou de tester vos propres modèles pour utiliser ces services.
Dans la mesure où la plupart des services ML gérés n’imposent pas de données ou d’entraînement de modèles, l’isolation des données de locataires n’est généralement pas un problème. Cependant, lorsque vous travaillez avec AI Search dans une solution multi-locataire, consultez Modèles de conception pour les applications SaaS multi-locataires et Azure AI Search.
Tenez compte des besoins de mise à l’échelle des composants de votre solution. Par exemple, de nombreuses API au sein d’Azure AI Services prennent en charge un nombre maximal de requêtes par seconde. Si vous déployez une seule ressource AI Services à partager entre vos locataires, alors à mesure que le nombre de locataires augmente, il se peut que vous deviez passer à plusieurs ressources.
Remarque
Certains services managés vous permettent de vous entraîner avec vos propres données, notamment le service Custom Vision, l’API Face, les modèles personnalisés de Document Intelligence, et certains modèles OpenAI qui prennent en charge la personnalisation et l’affinement. Quand vous utilisez ces services, il est important de prendre en compte les exigences d’isolation des données de vos locataires.
Architecture IA/ML personnalisée
Si votre solution nécessite des modèles personnalisés ou si vous travaillez dans un domaine qui n’est pas couvert par un service ML géré, envisagez de créer votre propre architecture IA/ML. Azure Machine Learning offre une suite de fonctionnalités destinées à orchestrer l’entraînement et le déploiement de modèles ML. Azure Machine Learning prend en charge de nombreuses bibliothèques de machine learning open source, notamment PyTorch, Tensorflow, Scikit et Keras. Vous pouvez constamment superviser les métriques de performances des modèles, détecter une dérive de données et déclencher un nouvel entraînement pour améliorer le niveau de performance des modèles. Tout au long du cycle de vie de vos modèles ML, Azure Machine Learning offre des capacités d’audit et de gouvernance grâce à un suivi et une traçabilité intégrés pour tous vos artefacts ML.
Quand vous travaillez dans une solution multilocataire, il est important de prendre en compte les exigences d’isolation de vos locataires pendant les phases d’entraînement et d’inférence. Vous devez aussi déterminer votre processus d’entraînement et de déploiement de modèles. Azure Machine Learning propose un pipeline pour entraîner les modèles et les déployer dans un environnement à utiliser pour l’inférence. Dans un contexte multilocataire, déterminez si les modèles doivent être déployés sur des ressources de calcul partagées ou si chaque locataire dispose de ressources dédiées. Concevez vos pipelines de déploiement de modèles en fonction de votre modèle d’isolation et de votre processus de déploiement de locataire.
Si vous utilisez des modèles open source, vous serez peut-être amené à entraîner à nouveau ces modèles en procédant à un apprentissage de transfert ou à un ajustement. Réfléchissez à la façon dont vous allez gérer les différents modèles et les données d’entraînement pour chaque locataire, ainsi que les versions du modèle.
Le diagramme suivant illustre un exemple d’architecture qui utilise Azure Machine Learning. L’exemple utilise l’approche d’isolation reposant sur des modèles propres au locataire.
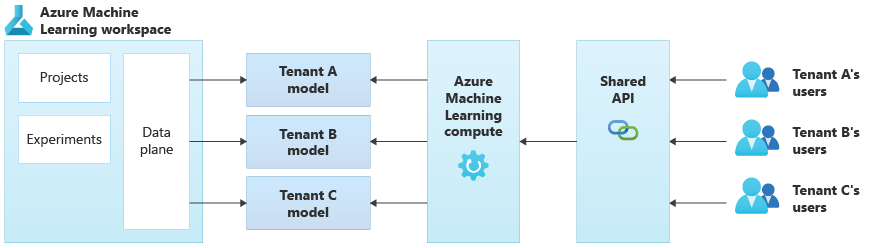
Solutions IA/ML intégrées
Azure propose plusieurs plateformes d’analytique puissantes qui peuvent être utilisées à diverses fins. Il s’agit notamment des plateformes Azure Synapse Analytics, Databricks et Apache Spark.
Vous pouvez envisager d’utiliser ces plateformes pour l’IA/ML quand vous avez besoin de mettre à l’échelle vos capacités ML pour un très grand nombre de locataires et que vous avez besoin d’une orchestration et de capacités de calcul à grande échelle. De même, vous pouvez envisager d’utiliser ces plateformes pour l’IA/ML si vous avez besoin d’une plateforme d’analytique de portée générale pour d’autres parties de votre solution, notamment pour l’analytique Données et l’intégration à la création de rapports via Microsoft Power BI. Vous pouvez déployer une plateforme unique qui couvre l’ensemble de vos besoins en matière d’analytique et d’IA/ML. Quand vous implémentez des plateformes de données dans une solution multilocataire, consultez Approches architecturales en matière de stockage et de données dans les solutions multilocataires.
Modèle opérationnel ML
Lors de l’adoption de pratiques liées à l’IA et au machine learning, y compris l’IA générative, il est recommandé d’améliorer et d’évaluer en permanence vos capacités organisationnelles à les gérer. L’introduction de MLOps et GenAIOps offre objectivement un cadre pour étendre continuellement les capacités de vos pratiques d’IA et de ML dans votre organisation. Consultez les documents Modèle de maturité MLOps et Modèle de maturité LLMOps pour obtenir des conseils supplémentaires.
Antimodèles à éviter
- Non prise en compte des exigences d’isolation. Il est important de réfléchir soigneusement à la façon dont vous allez isoler les données et les modèles des locataires, à la fois pour l’entraînement et pour l’inférence. À défaut, vous risquez de contrevenir à des obligations légales ou contractuelles. De même, la précision de vos modèles risque d’en pâtir si vous les entraînez avec des données très différentes issues de plusieurs locataires.
- Voisins bruyants. Déterminez si vos processus d’entraînement ou d’inférence peuvent être exposés au problème des voisins bruyants. Par exemple, si vous avez plusieurs locataires de grande taille et un seul de petite taille, veillez à ce que l’entraînement pour les locataires de grande taille ne consomme pas malencontreusement toutes les ressources de calcul et prive le locataire de petite taille. Assurez la gouvernance et la supervision des ressources pour limiter le risque que la charge de travail de calcul d’un locataire soit affectée par l’activité des autres locataires.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Kevin Ashley | Ingénieur client senior, FastTrack for Azure
Autres contributeurs :
- Paul Burpo | Ingénieur client principal, FastTrack for Azure
- John Downs | Ingénieur logiciel principal
- Daniel Scott-Raynsford | Stratégiste de la technologie partenaire
- Arsen Vladimirskiy | Ingénieur client principal, FastTrack for Azure
- Vic Perdana | Architecte de solution partenaire ISV
Étapes suivantes
- Consultez Approches architecturales pour le calcul dans les solutions multilocataires.
- Pour en savoir plus sur la conception de pipelines Azure Machine Learning pour prendre en charge plusieurs locataires, consultez Une solution pour les pipelines ML en mode multitenant.