Les cycles de mise en production plus rapides constituent l’un des principaux avantages des architectures de microservices. Mais sans un bon processus CI/CD, vous n’obtiendrez pas l’agilité que les microservices promettent. Cet article décrit les défis et recommande certaines approches du problème.
Qu’est-ce que CI/CD ?
Lorsque nous parlons de CI/CD, nous parlons vraiment de plusieurs processus connexes : intégration continue, livraison continue et déploiement continu.
d’intégration continue . Les modifications de code sont fréquemment fusionnées dans la branche principale. Les processus de génération et de test automatisés garantissent que le code dans la branche principale est toujours de qualité de production.
livraison continue. Toutes les modifications de code qui passent le processus CI sont automatiquement publiées dans un environnement de type production. Le déploiement dans l’environnement de production dynamique peut nécessiter une approbation manuelle, mais est sinon automatisé. L’objectif est que votre code doit toujours être prêt à déployer en production.
de déploiement continu. Les modifications de code qui passent les deux étapes précédentes sont déployées automatiquement en production.
Voici quelques objectifs d’un processus CI/CD robuste pour une architecture de microservices :
Chaque équipe peut créer et déployer les services qu’elle possède indépendamment, sans affecter ni perturber d’autres équipes.
Avant qu’une nouvelle version d’un service soit déployée en production, elle est déployée dans des environnements dev/test/QA à des fins de validation. Les portes de qualité sont appliquées à chaque étape.
Une nouvelle version d’un service peut être déployée côte à côte avec la version précédente.
Des stratégies de contrôle d’accès suffisantes sont en place.
Pour les charges de travail conteneurisées, vous pouvez approuver les images conteneur déployées en production.
Pourquoi un pipeline CI/CD robuste importe
Dans une application monolithique traditionnelle, il existe un pipeline de génération unique dont la sortie est l’exécutable de l’application. Tous les travaux de développement se nourrissent dans ce pipeline. Si un bogue à priorité élevée est trouvé, un correctif doit être intégré, testé et publié, ce qui peut retarder la publication de nouvelles fonctionnalités. Vous pouvez atténuer ces problèmes en ayant des modules bien factornés et en utilisant des branches de fonctionnalités pour réduire l’impact des modifications de code. Mais à mesure que l’application augmente plus complexe et que d’autres fonctionnalités sont ajoutées, le processus de mise en production d’un monolithe tend à devenir plus fragile et susceptible de s’interrompre.
Après la philosophie des microservices, il ne devrait jamais y avoir un long train de mise en production où chaque équipe doit se mettre en ligne. L’équipe qui génère le service « A » peut publier une mise à jour à tout moment, sans attendre que les modifications apportées au service « B » soient fusionnées, testées et déployées.
diagramme 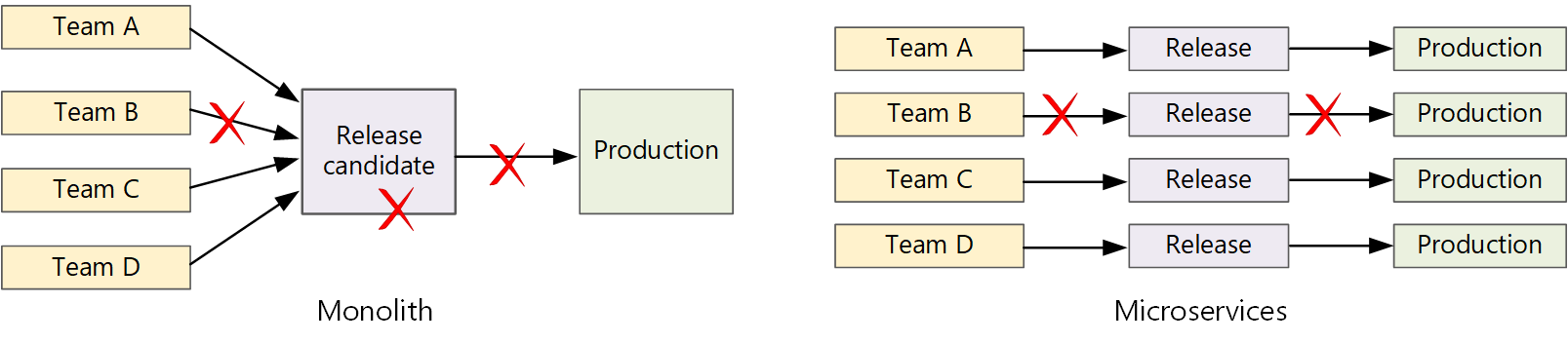 monolithique CI/CD
monolithique CI/CD
Pour atteindre une vitesse de mise en production élevée, votre pipeline de mise en production doit être automatisé et hautement fiable pour réduire les risques. Si vous relâchez en production une ou plusieurs fois par jour, les régressions ou interruptions de service doivent être rares. En même temps, si une mise à jour incorrecte est déployée, vous devez disposer d’un moyen fiable de restaurer ou de restaurer rapidement vers une version précédente d’un service.
Défis
De nombreuses bases de code indépendantes de petite taille. Chaque équipe est responsable de la création de son propre service, avec son propre pipeline de build. Dans certaines organisations, les équipes peuvent utiliser des référentiels de code distincts. Des dépôts distincts peuvent entraîner une situation où les connaissances sur la façon de créer le système sont réparties entre les équipes, et personne dans l’organisation ne sait comment déployer l’ensemble de l’application. Par exemple, que se passe-t-il dans un scénario de récupération d’urgence, si vous devez déployer rapidement sur un nouveau cluster ?
d’atténuation : disposez d’un pipeline unifié et automatisé pour créer et déployer des services, afin que ces connaissances ne soient pas « masquées » au sein de chaque équipe.
plusieurs langages et infrastructures. Avec chaque équipe utilisant sa propre combinaison de technologies, il peut être difficile de créer un processus de génération unique qui fonctionne au sein de l’organisation. Le processus de génération doit être suffisamment flexible pour que chaque équipe puisse l’adapter à son choix de langage ou d’infrastructure.
d’atténuation : conteneurisez le processus de génération pour chaque service. De cette façon, le système de génération doit simplement être en mesure d’exécuter les conteneurs.
d’intégration et de test de charge . Avec les équipes qui publient des mises à jour à leur propre rythme, il peut être difficile de concevoir des tests de bout en bout robustes, en particulier lorsque les services ont des dépendances sur d’autres services. En outre, l’exécution d’un cluster de production complet peut être coûteuse. Il est donc peu probable que chaque équipe exécute son propre cluster complet à l’échelle de production, juste pour les tests.
release management. Chaque équipe doit pouvoir déployer une mise à jour en production. Cela ne signifie pas que chaque membre de l’équipe dispose des autorisations nécessaires. Mais avoir un rôle Release Manager centralisé peut réduire la vitesse des déploiements.
atténuation: plus votre processus CI/CD est automatisé et fiable, moins il doit y avoir besoin d’une autorité centrale. Cela dit, vous pouvez avoir des stratégies différentes pour publier des mises à jour de fonctionnalités majeures et des correctifs de bogues mineurs. L’être décentralisé ne signifie pas zéro gouvernance.
Service met à jour. Lorsque vous mettez à jour un service vers une nouvelle version, il ne doit pas interrompre les autres services qui en dépendent.
d’atténuation : utilisez des techniques de déploiement telles que la mise en production bleue-verte ou canary pour les changements non cassants. Pour les modifications d’API cassants, déployez la nouvelle version côte à côte avec la version précédente. Ainsi, les services qui consomment l’API précédente peuvent être mis à jour et testés pour la nouvelle API. Consultez Mise à jour des services, ci-dessous.
Monorepo et multi-référentiel
Avant de créer un flux de travail CI/CD, vous devez savoir comment la base de code sera structurée et gérée.
- Les équipes travaillent-elles dans des référentiels distincts ou dans un monorepo (référentiel unique) ?
- Quelle est votre stratégie de branchement ?
- Qui peut envoyer du code en production ? Existe-t-il un rôle de gestionnaire de versions ?
L’approche monorepo a gagné en faveur, mais il existe des avantages et des inconvénients pour les deux.
| Monorepo | Dépôts multiples | |
|---|---|---|
| avantages | Partage de code Plus facile à normaliser le code et les outils Code plus facile à refactoriser Détectabilité - vue unique du code |
Effacer la propriété par équipe Moins de conflits de fusion Aide à appliquer le découplage des microservices |
| Défis | Les modifications apportées au code partagé peuvent affecter plusieurs microservices Plus grand potentiel pour les conflits de fusion Les outils doivent être mis à l’échelle vers une base de code volumineuse Contrôle d’accès Processus de déploiement plus complexe |
Plus difficile à partager du code Plus difficile d’appliquer les normes de codage Gestion des dépendances Base de code diffuse, mauvaise détectabilité Absence d’infrastructure partagée |
Mise à jour des services
Il existe différentes stratégies pour mettre à jour un service déjà en production. Ici, nous abordons trois options courantes : mise à jour propagée, déploiement bleu-vert et mise en production canary.
Mises à jour propagées
Dans une mise à jour propagée, vous déployez de nouvelles instances d’un service et les nouvelles instances commencent immédiatement à recevoir des demandes. À mesure que les nouvelles instances s’affichent, les instances précédentes sont supprimées.
Exemple. Dans Kubernetes, les mises à jour propagées sont le comportement par défaut lorsque vous mettez à jour la spécification de pod pour un Deployment. Le contrôleur de déploiement crée un replicaSet pour les pods mis à jour. Ensuite, il effectue un scale-up du nouveau ReplicaSet tout en effectuant un scale-down de l’ancien, pour conserver le nombre de réplicas souhaité. Il ne supprime pas les anciens pods tant que les nouveaux ne sont pas prêts. Kubernetes conserve un historique de la mise à jour. Vous pouvez donc restaurer une mise à jour si nécessaire.
Exemple. Azure Service Fabric utilise la stratégie de mise à jour propagée par défaut. Cette stratégie convient le mieux au déploiement d’une version d’un service avec de nouvelles fonctionnalités sans modifier les API existantes. Service Fabric démarre un déploiement de mise à niveau en mettant à jour le type d’application vers un sous-ensemble des nœuds ou un domaine de mise à jour. Il est ensuite transféré vers le domaine de mise à jour suivant jusqu’à ce que tous les domaines soient mis à niveau. Si un domaine de mise à niveau ne parvient pas à être mis à jour, le type d’application revient à la version précédente sur tous les domaines. N’oubliez pas qu’un type d’application avec plusieurs services (et si tous les services sont mis à jour dans le cadre d’un déploiement de mise à niveau) est susceptible d’échouer. Si un service ne parvient pas à être mis à jour, l’application entière est restaurée vers la version précédente et les autres services ne sont pas mis à jour.
L’un des défis liés aux mises à jour propagées est que pendant le processus de mise à jour, un mélange d’anciennes et nouvelles versions s’exécute et reçoit du trafic. Pendant cette période, toute demande peut être acheminée vers l’une des deux versions.
Pour les changements d’API cassants, une bonne pratique consiste à prendre en charge les deux versions côte à côte, jusqu’à ce que tous les clients de la version précédente soient mis à jour. Consultez de contrôle de version des API.
Déploiement bleu-vert
Dans un déploiement bleu-vert, vous déployez la nouvelle version en même temps que la version précédente. Après avoir validé la nouvelle version, vous basculez tout le trafic à la fois de la version précédente vers la nouvelle version. Après le commutateur, vous surveillez l’application pour tout problème. Si un problème se produit, vous pouvez revenir à l’ancienne version. En supposant qu’il n’y a aucun problème, vous pouvez supprimer l’ancienne version.
Avec une application monolithique ou multiniveau plus traditionnelle, le déploiement bleu-vert implique généralement l’approvisionnement de deux environnements identiques. Vous devez déployer la nouvelle version dans un environnement intermédiaire, puis rediriger le trafic client vers l’environnement intermédiaire, par exemple en échangeant des adresses IP virtuelles. Dans une architecture de microservices, les mises à jour se produisent au niveau du microservice. Vous devez donc généralement déployer la mise à jour dans le même environnement et utiliser un mécanisme de découverte de service pour échanger.
Exemple de. Dans Kubernetes, vous n’avez pas besoin de provisionner un cluster distinct pour effectuer des déploiements bleu-vert. Au lieu de cela, vous pouvez tirer parti des sélecteurs. Créez une ressource Deployment avec une nouvelle spécification de pod et un autre ensemble d’étiquettes. Créez ce déploiement, sans supprimer le déploiement précédent ou modifier le service qui pointe vers celui-ci. Une fois les nouveaux pods en cours d’exécution, vous pouvez mettre à jour le sélecteur du service pour qu’il corresponde au nouveau déploiement.
L’un des inconvénients du déploiement bleu-vert est que pendant la mise à jour, vous exécutez deux fois plus de pods pour le service (actuel et suivant). Si les pods nécessitent un grand nombre de ressources processeur ou mémoire, vous devrez peut-être effectuer un scale-out temporaire du cluster pour gérer la consommation de ressources.
Version de Canary
Dans une version canary, vous déployez une version mise à jour sur un petit nombre de clients. Ensuite, vous surveillez le comportement du nouveau service avant de le déployer sur tous les clients. Cela vous permet d’effectuer un déploiement lent de manière contrôlée, d’observer des données réelles et de repérer les problèmes avant que tous les clients ne soient affectés.
Une version canary est plus complexe à gérer que la mise à jour bleue ou propagée, car vous devez acheminer dynamiquement les demandes vers différentes versions du service.
Exemple de. Dans Kubernetes, vous pouvez configurer un Service pour couvrir deux jeux de réplicas (un pour chaque version) et ajuster le nombre de réplicas manuellement. Toutefois, cette approche est plutôt grossière, en raison de la façon dont Kubernetes équilibre la charge entre les pods. Par exemple, si vous avez un total de 10 réplicas, vous ne pouvez déplacer le trafic que par incréments de 10%. Si vous utilisez un maillage de service, vous pouvez utiliser les règles de routage de maillage de service pour implémenter une stratégie de mise en production canary plus sophistiquée.
Étapes suivantes
- parcours d’apprentissage : définir et implémenter des d’intégration continue
- formation : Présentation des de livraison continue
- architecture de microservices
- Pourquoi utiliser une approche de microservices pour créer des applications