Cet article décrit comment une équipe de développement a utilisé des métriques pour détecter des goulets d’étranglement et améliorer les performances d’un système distribué. L’article est basé sur des tests de charge réels que nous avons effectués pour un exemple d’application. L’application provient de la ligne de base du service Azure Kubernetes (AKS) pour les microservices.
Cet article fait partie d’une série. Lisez la première partie ici.
Scénario : Une application cliente lance une transaction commerciale qui comporte plusieurs étapes.
Ce scénario implique une application de livraison par drone s’exécutant sur AKS. Les clients utilisent une application web pour planifier les livraisons par drone. Chaque transaction se décompose en plusieurs étapes exécutées sur le back-end par des microservices distincts :
- Le service Livraison gère les remises.
- Le service Planification des drones planifie les drones pour la collecte.
- Le service Colis gère les colis.
Il existe deux autres services : le service Ingestion, qui accepte les requêtes des clients et les met en file d'attente à des fins de traitement, et le service Flux de travail qui coordonne les étapes du flux de travail.

Pour plus d'informations sur ce scénario, consultez Conception d'une architecture de microservices.
Test 1 : Ligne de base
Pour le premier test de charge, l’équipe a créé un cluster AKS à six nœuds et déployé trois réplicas de chaque microservice. Le test de charge, un test par étapes, est passé de 2 à 40 utilisateurs simulés.
| Paramètre | Valeur |
|---|---|
| Nœuds de cluster | 6 |
| Pods | 3 par service |
Le graphique suivant présente les résultats du test de charge, tels qu'ils sont fournis dans Visual Studio. La ligne violette indique la charge utilisateur et la ligne orange le nombre total de requêtes.
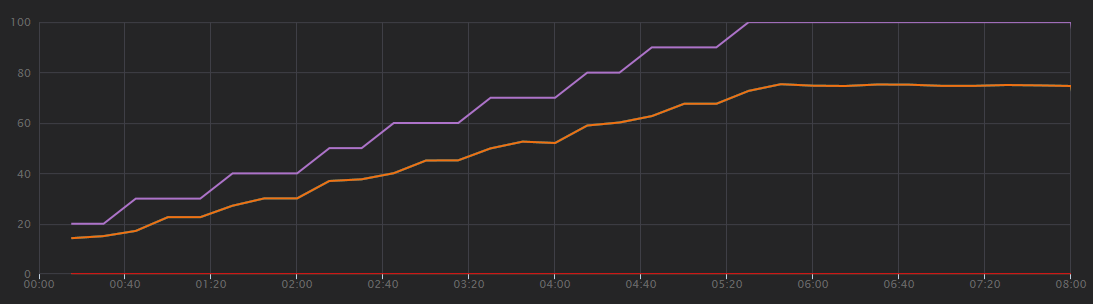
Première remarque concernant ce scénario : les requêtes client par seconde ne constituent pas une métrique de performance utile. En effet, l'application traite les requêtes de manière asynchrone, de sorte que le client obtient immédiatement une réponse. Le code de réponse est toujours HTTP 202 (Accepté), ce qui signifie que la requête a été acceptée mais que le traitement n'est pas terminé.
Ce que nous voulons vraiment savoir, c'est si le back-end suit le rythme des requêtes. La file d'attente Service Bus peut absorber des pics, mais si le back-end n'est pas capable de gérer une charge soutenue, le traitement prendra de plus en plus de retard.
Voici un graphique plus instructif. Il indique le nombre de messages entrants et sortants dans la file d'attente Service Bus. Les messages entrants sont affichés en bleu clair et les messages sortants en bleu foncé :
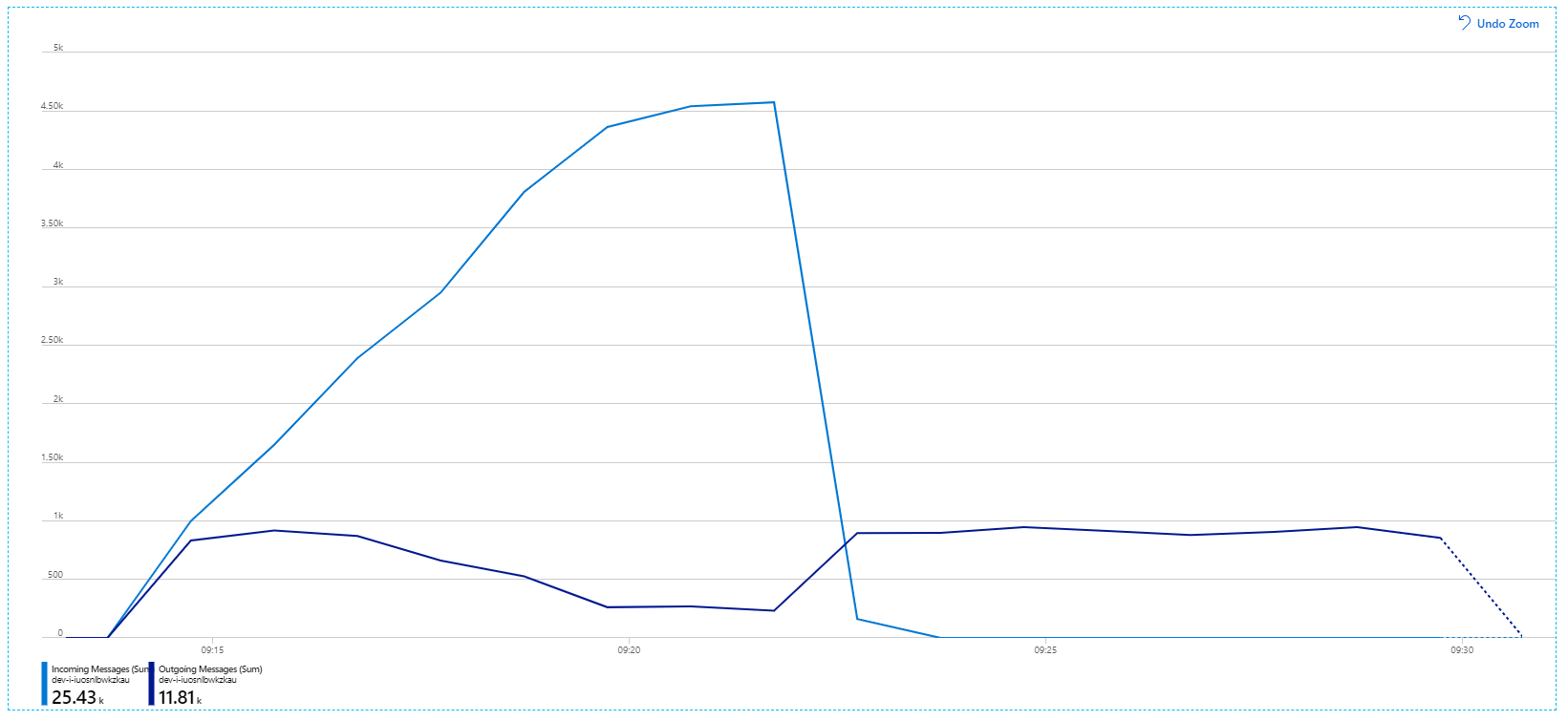
Ce graphique montre que le nombre de messages entrants augmente, atteint un pic puis retombe à zéro à la fin du test de charge. Le nombre de messages sortants, quant à lui, atteint un pic au début du test, puis diminue. Cela signifie que le service Flux de travail, qui gère les requêtes, ne suit pas. Même après la fin du test de charge (vers 9:22 sur le graphique), les messages sont toujours en cours de traitement alors que le service Flux de travail continue de vider la file d'attente.
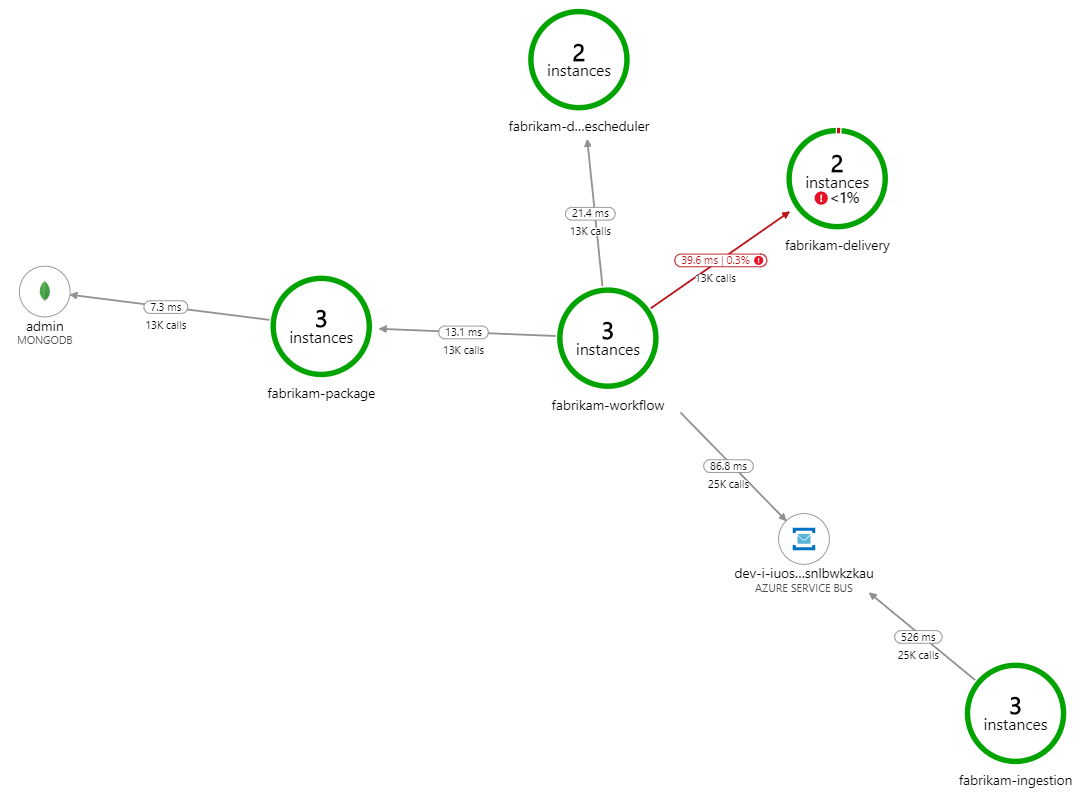
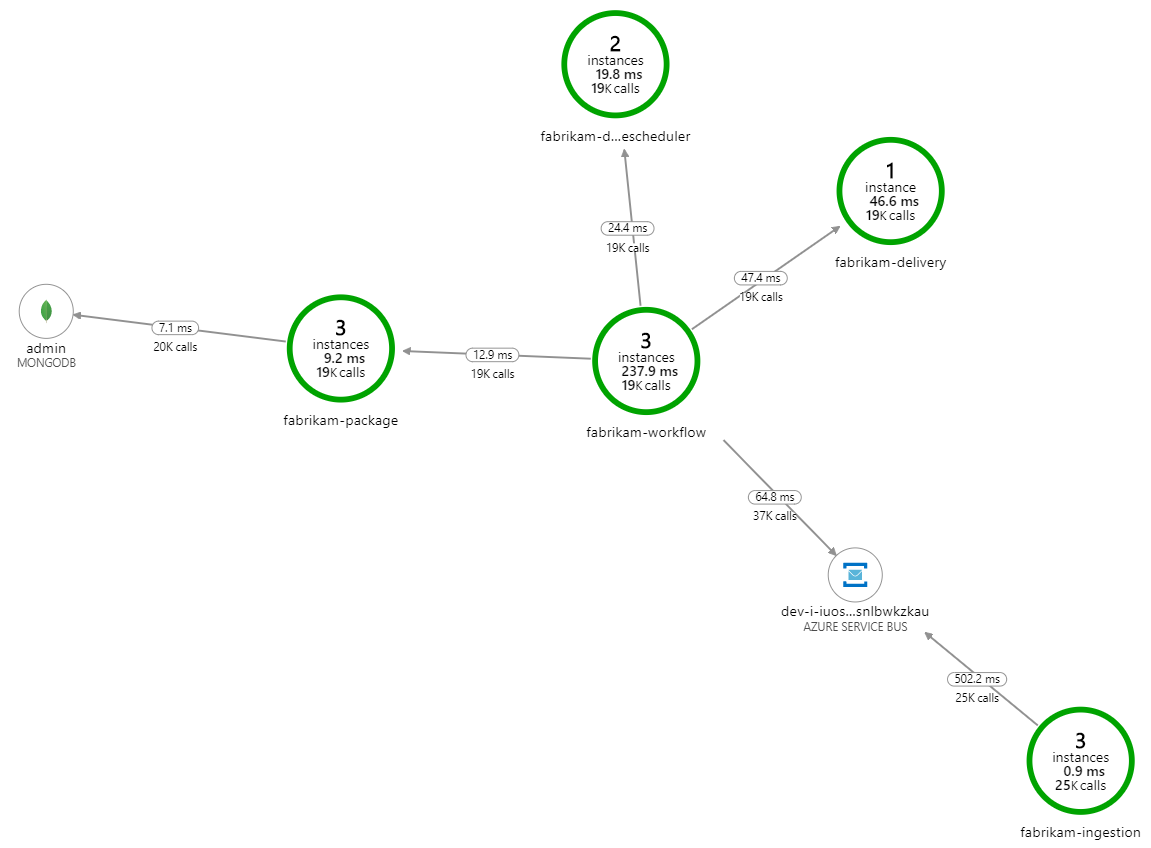
Qu'est-ce qui ralentit le traitement ? Il convient d'abord de rechercher les erreurs ou exceptions susceptibles de révéler un problème systématique. La cartographie d'application d'Azure Monitor fournit un graphique des appels entre les composants qui permet de repérer rapidement les problèmes. Il suffit ensuite cliquer pour obtenir plus de détails.
La cartographie d'application montre que le service Flux de travail reçoit des erreurs du service de livraison :
Pour plus de détails, vous pouvez sélectionner un nœud sur le graphique et cliquer dans une vue de transactions de bout en bout. Ici, vous pouvez constater que le service de livraison renvoie des erreurs HTTP 500. Les messages d'erreur indiquent qu'une exception est levée en raison des limites de mémoire d'Azure Cache pour Redis.
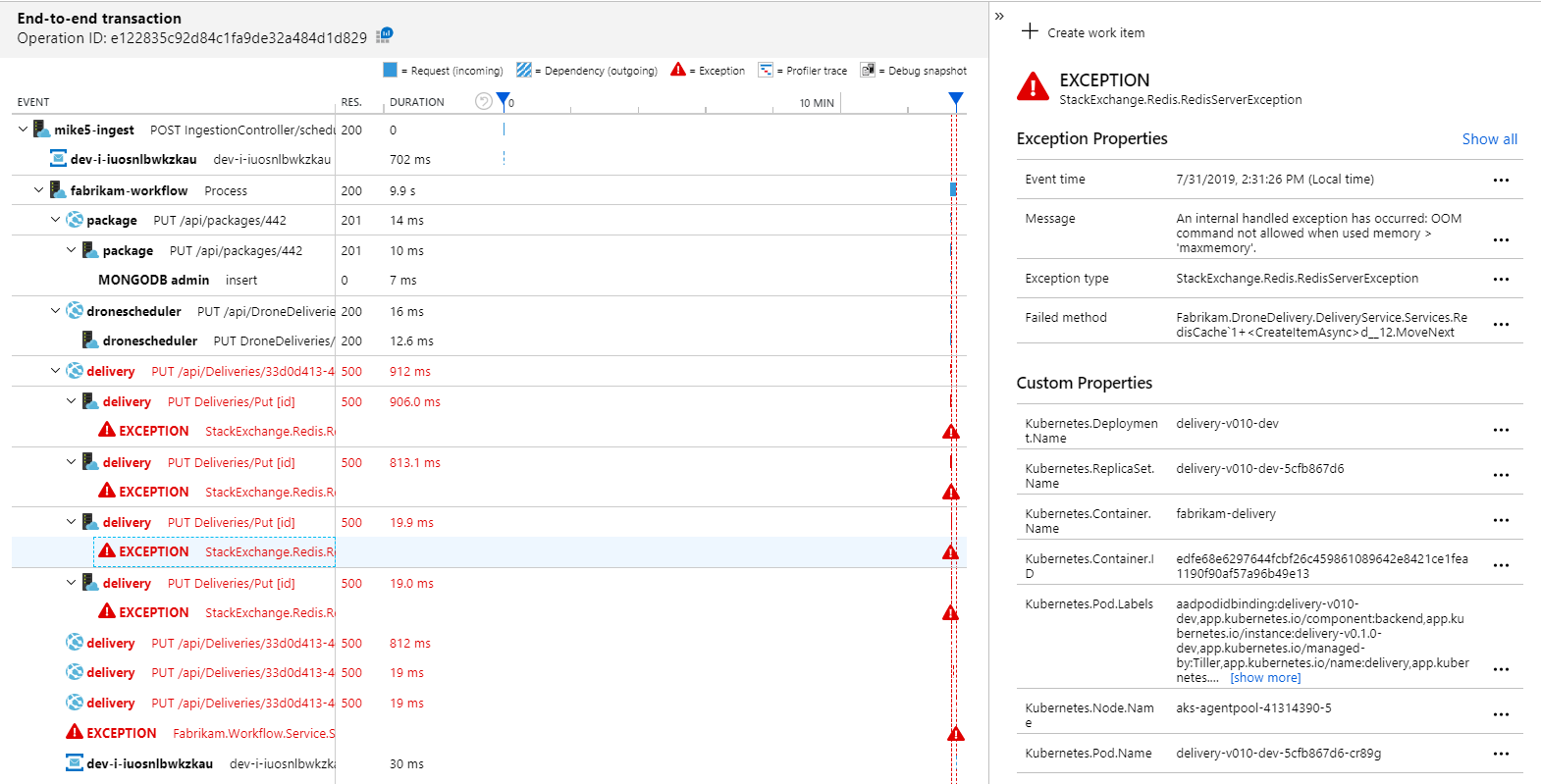
Vous remarquerez peut-être que ces appels à Redis n'apparaissent pas dans la cartographie d'application. En effet, la bibliothèque .NET pour Application Insights ne dispose d'aucune prise en charge intégrée pour le suivi de Redis en tant que dépendance. (Pour obtenir la liste de ce qui est pris en charge, consultez Collecte automatique des dépendances.) En guise de solution de repli, vous pouvez utiliser l'API TrackDependency pour suivre une dépendance. Les tests de charge révèlent souvent ce type de lacunes dans les données de télémétrie, lesquelles peuvent être comblées.
Test 2 : Augmentation de la taille du cache
Pour le deuxième test de charge, l'équipe de développement a augmenté la taille du cache dans Azure Cache pour Redis. (Voir Mise à l'échelle d'Azure Cache pour Redis). Ce changement a permis de résoudre les exceptions liées à une mémoire insuffisante, et la cartographie d'application n'affiche désormais plus aucune erreur :
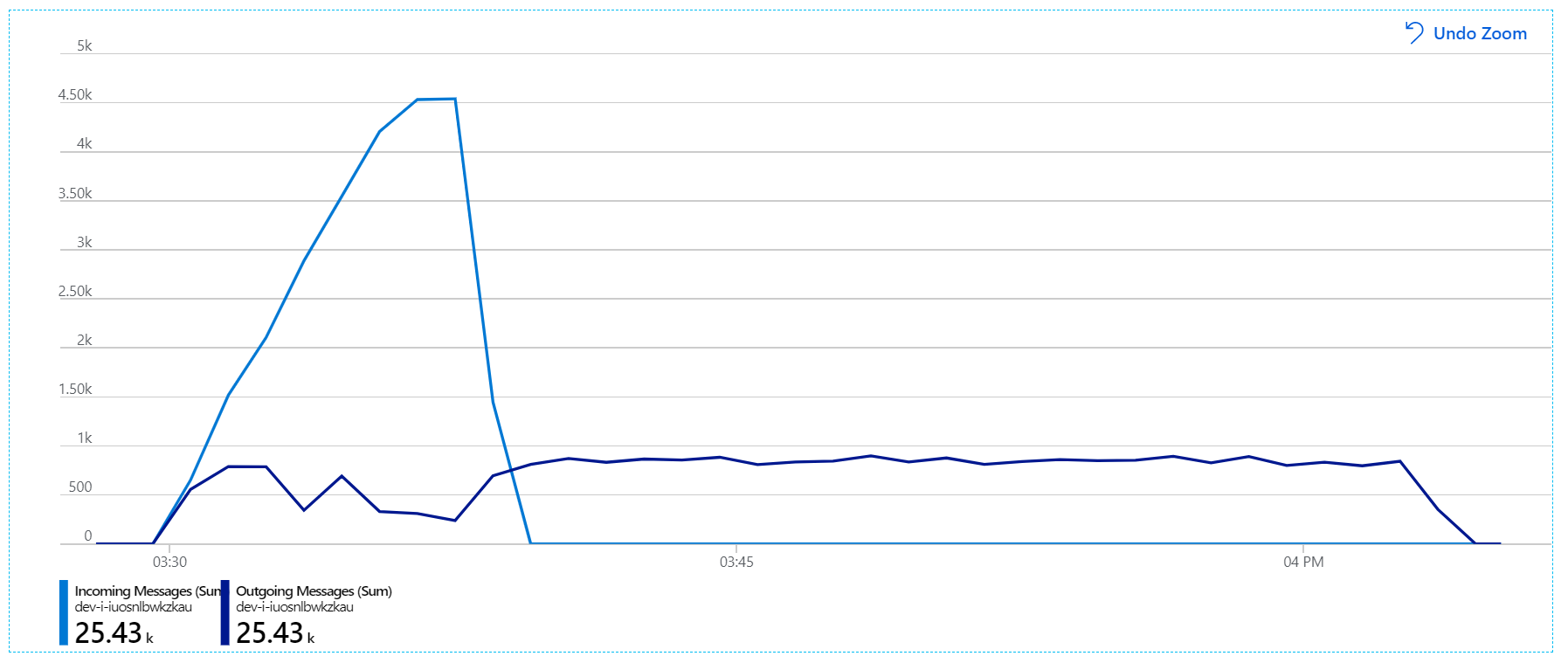
Cependant, le retard de traitement des messages reste considérable. Au plus fort du test de charge, le taux de messages entrants est supérieur à 5 fois le taux de messages sortants :
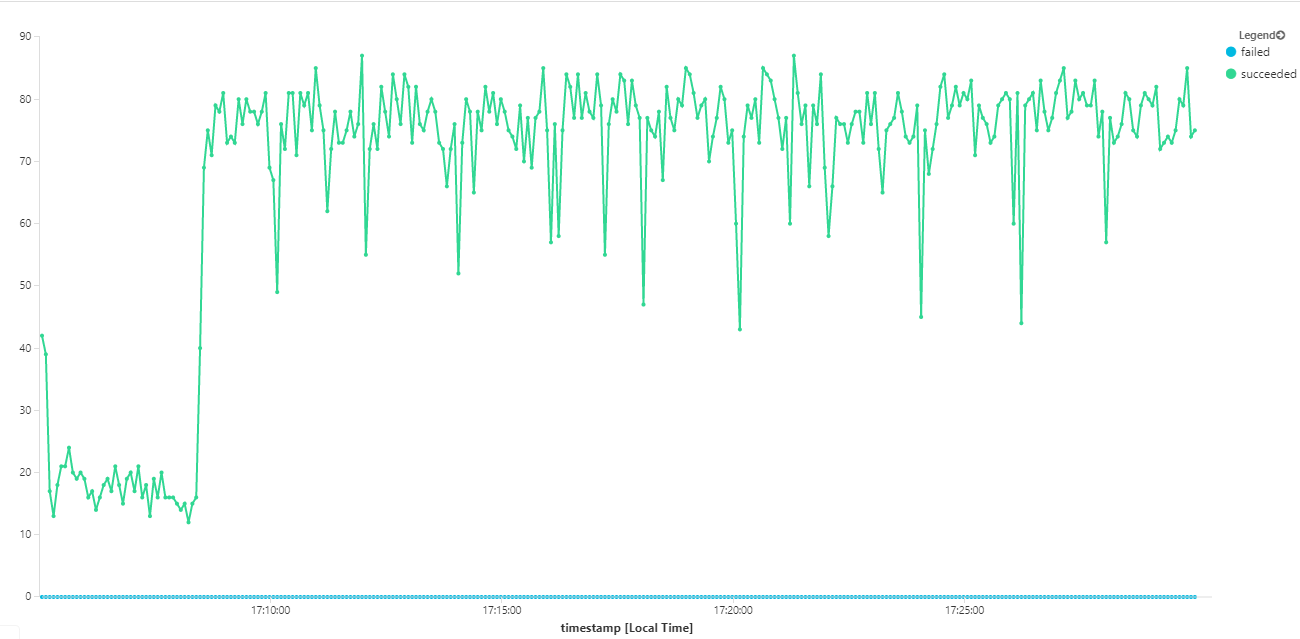
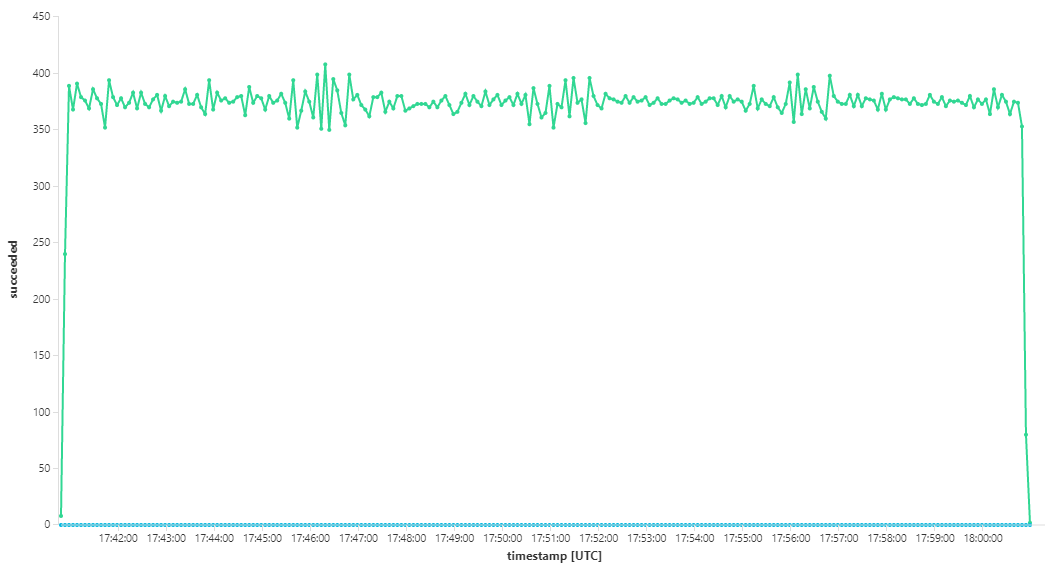
Le graphique suivant mesure le débit en termes d’achèvement des messages, autrement dit la vitesse à laquelle le service Flux de travail marque les messages Service Bus comme terminés. Chaque point du graphique représente 5 secondes de données, soit un débit maximal d'environ 16/s.
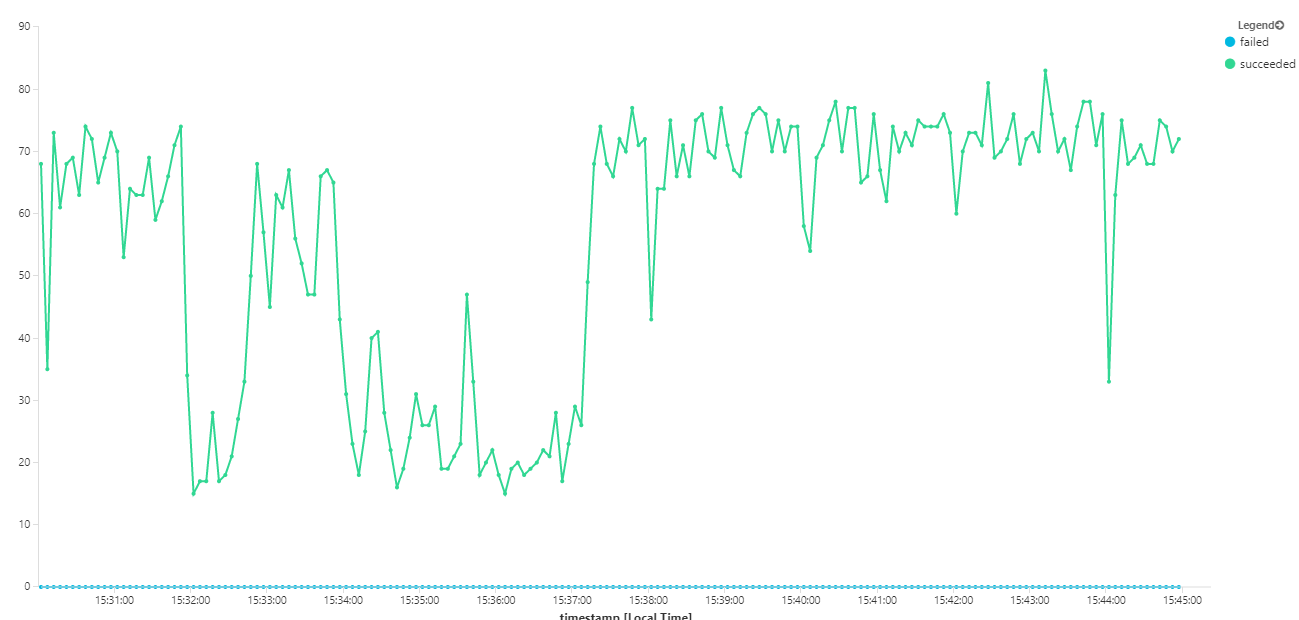
Ce graphique a été généré en exécutant une requête dans l'espace de travail Log Analytics, à l'aide du langage de requête Kusto :
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
Test 3 : Effectuer un scale-out des services back-end
Le back-end semble être à l'origine du goulot d'étranglement. L'étape suivante consiste à effectuer un scale-out des services métier (Colis, Livraison et Planification des drones) et à déterminer si le débit s'améliore. Pour le test de charge suivant, l'équipe a fait passer ces services de trois à six réplicas.
| Paramètre | Valeur |
|---|---|
| Nœuds de cluster | 6 |
| Service Ingestion | 3 réplicas |
| Service Flux de travail | 3 réplicas |
| Services Colis, Livraison, Planification des drones | 6 réplicas chacun |
Malheureusement, ce test de charge ne montre qu'une modeste amélioration. Les messages sortants ne suivent toujours pas le rythme des messages entrants :
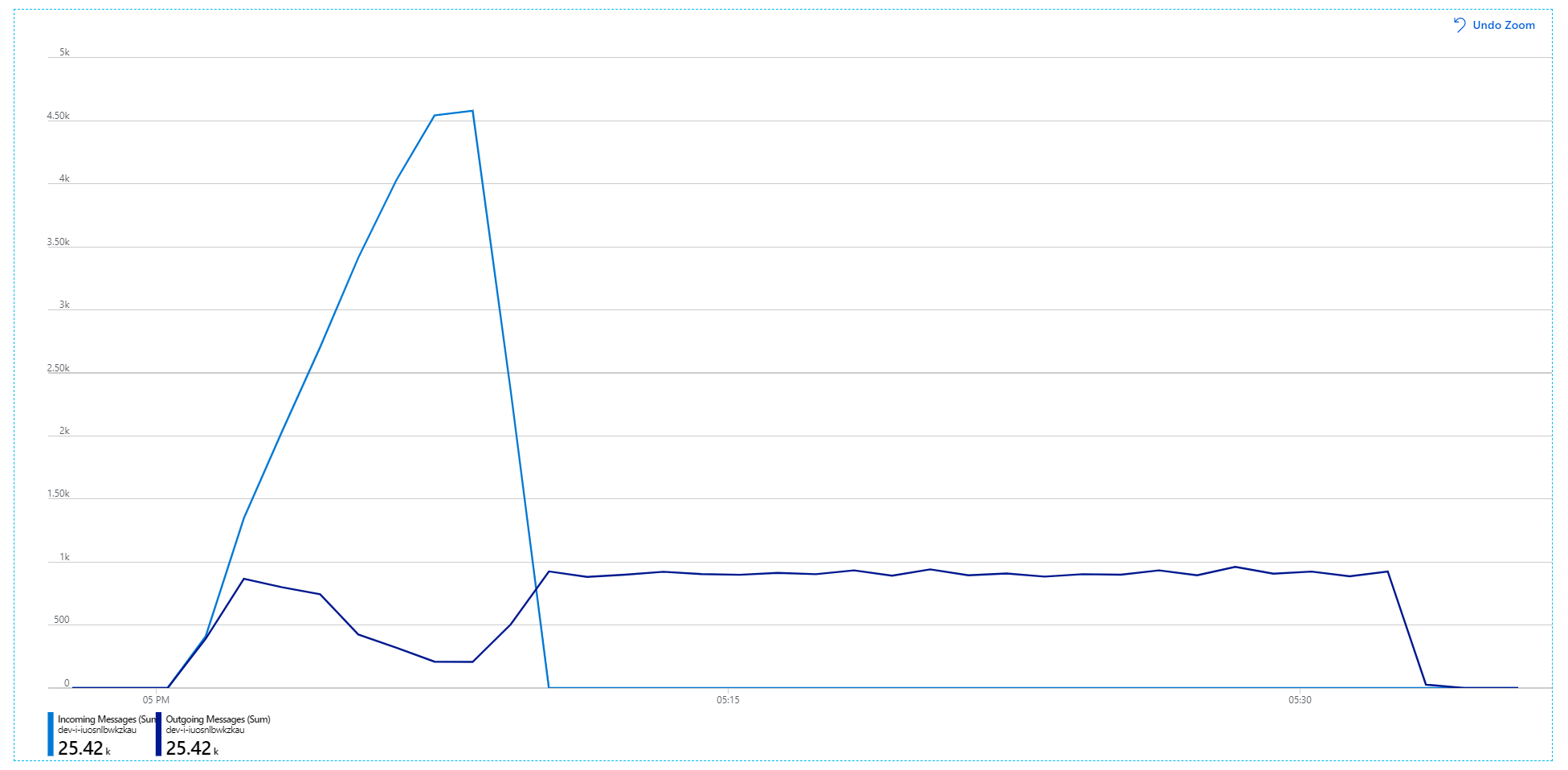
Le débit est plus cohérent, mais le maximum atteint est à peu près le même que dans le test précédent :
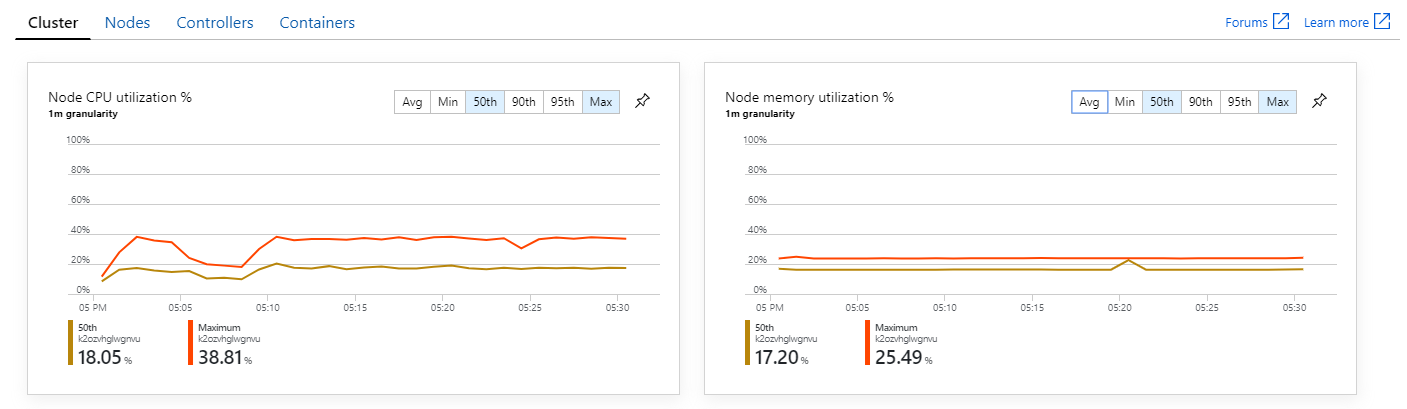
De plus, en examinant les insights de conteneur Azure Monitor, il semble que le problème ne soit pas dû à une insuffisance de ressources au sein du cluster. Premièrement, les métriques au niveau des nœuds montrent que l'utilisation de l'UC reste inférieure à 40 %, même au 95e centile, et que l'utilisation de la mémoire est d'environ 20 %.
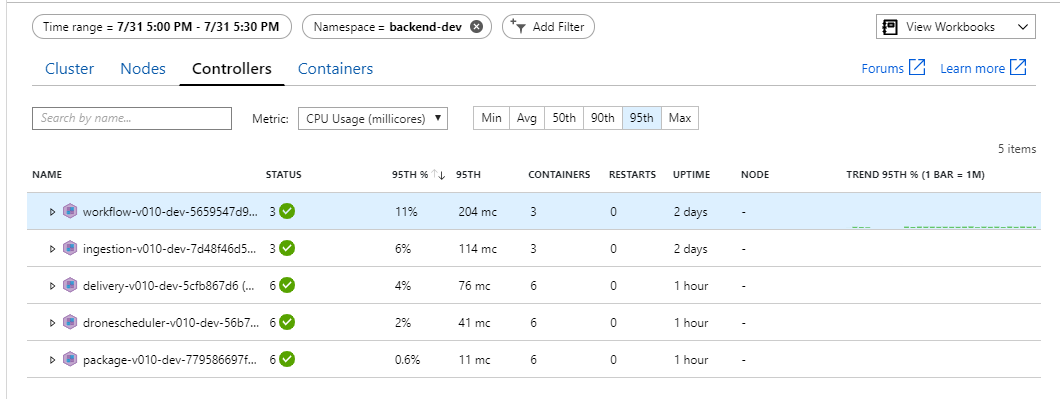
Dans un environnement Kubernetes, les pods individuels peuvent être limités en ressources, même si les nœuds ne le sont pas. Mais la vue au niveau des pods montre que tous les pods sont sains.
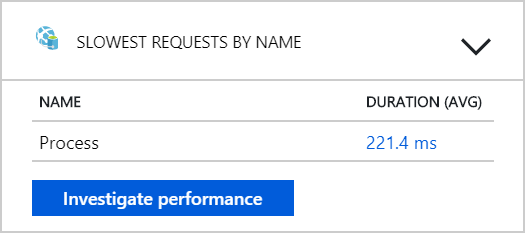
D'après ce test, il semble que le fait d'ajouter des pods supplémentaires au back-end ne soit d'aucune utilité. L'étape suivante consiste à examiner de plus près le service Flux de travail pour comprendre ce qui se passe lors du traitement des messages. Application Insights montre que la durée moyenne de l'opération Process du service Flux de travail est de 246 ms.
Nous pouvons également exécuter une requête pour obtenir des métriques sur les opérations individuelles au sein de chaque transaction :
| target | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86,66950203 | 283,4255578 |
| livraison continue | 37 | 57 |
| package | 12 | 17 |
| dronescheduler | 21 | 41 |
La première ligne de ce tableau représente la file d'attente Service Bus. Les autres lignes représentent les appels aux services back-end. Pour référence, voici la requête Log Analytics correspondant à ce tableau :
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target
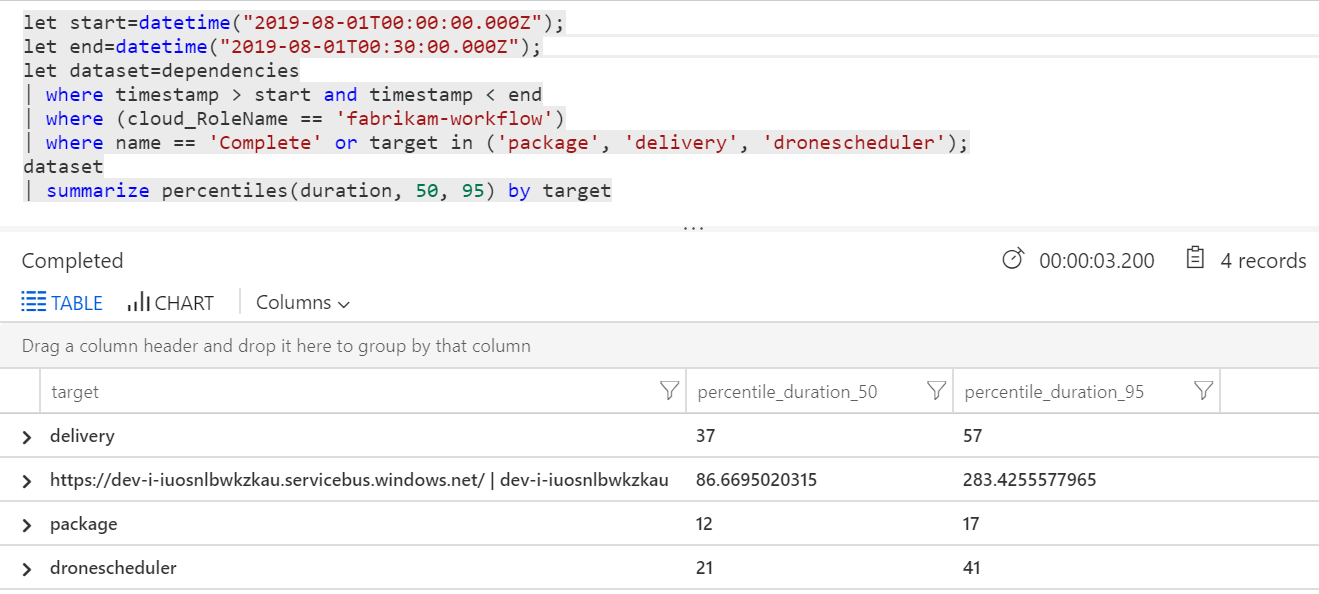
Ces latences semblent raisonnables. Mais voici l'insight clé : Si la durée totale de l'opération est d'environ 250 ms, une limite supérieure stricte s'impose quant à la vitesse à laquelle les messages peuvent être traités en série. La clé de l'amélioration du débit est donc un plus grand parallélisme.
Cela devrait être possible dans ce scénario, pour deux raisons :
- Il s'agit d'appels réseau ; la majeure partie du temps est donc passée à attendre la fin des E/S
- Les messages sont indépendants et n'ont pas besoin d'être traités dans l'ordre
Test 4 : Accroître le parallélisme
Pour ce test, l'équipe s'est concentrée sur l'accroissement du parallélisme. Pour ce faire, elle a ajusté deux paramètres sur le client Service Bus utilisé par le service Flux de travail :
| Paramètre | Description | Default | Nouvelle valeur |
|---|---|---|---|
MaxConcurrentCalls |
Nombre maximum de messages à traiter simultanément. | 1 | 20 |
PrefetchCount |
Nombre de messages que le client récupérera à l'avance dans son cache local. | 0 | 3000 |
Pour plus d'informations sur ces paramètres, consultez Meilleures pratiques relatives aux améliorations de performances à l'aide de la messagerie Service Bus. L'utilisation de ces paramètres lors de l'exécution du test a produit le graphique suivant :
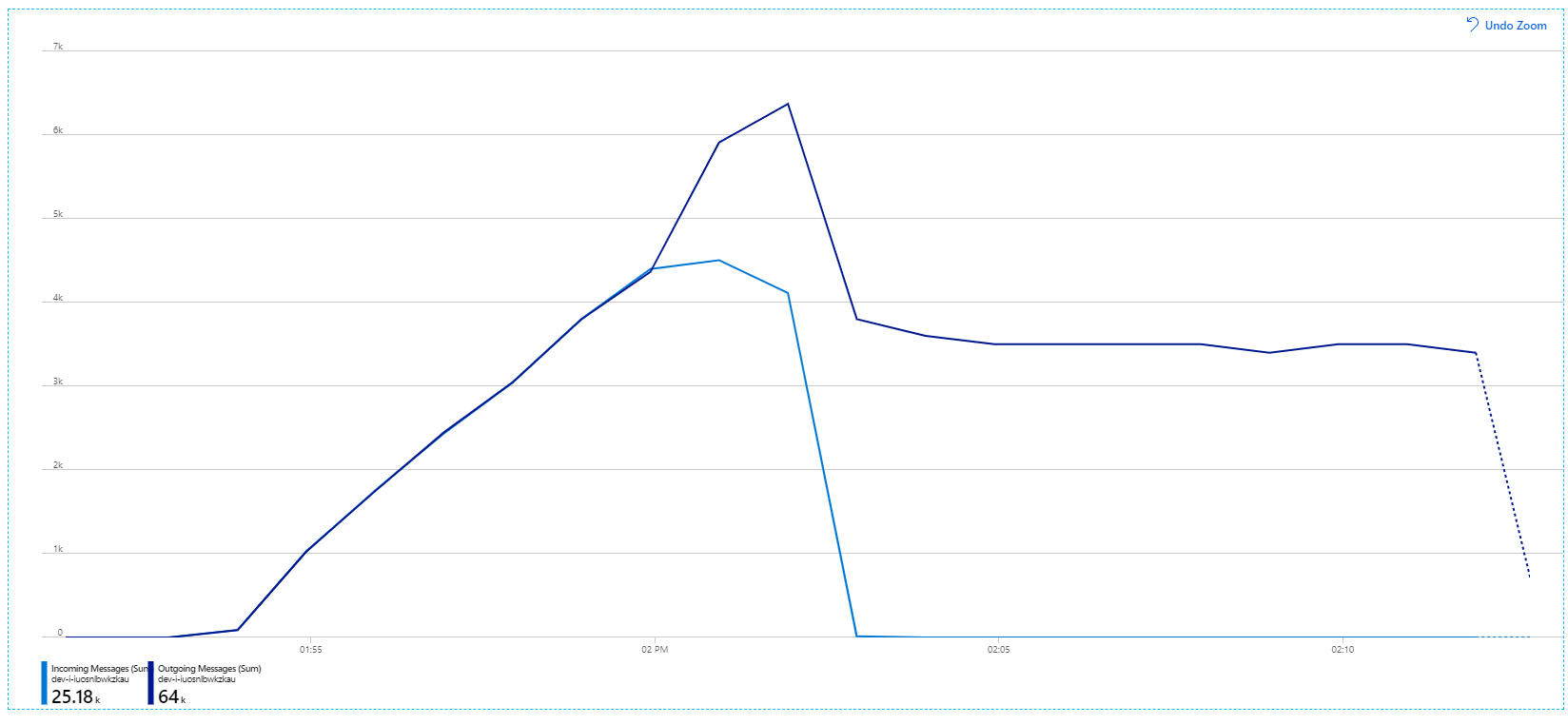
Pour rappel, les messages entrants sont affichés en bleu clair et les messages sortants en bleu foncé.
À première vue, ce graphique est très étrange. Pendant un certain temps, le débit des messages sortants suit exactement le débit des messages entrants. Puis, vers 2:03, le nombre de messages entrants se stabilise, tandis que le nombre de messages sortants continue d'augmenter, dépassant le nombre total de messages entrants. Cela semble impossible.
La clé de ce mystère se trouve dans la vue Dépendances d'Application Insights. Ce graphique récapitule tous les appels que le service Flux de travail a passés à Service Bus :
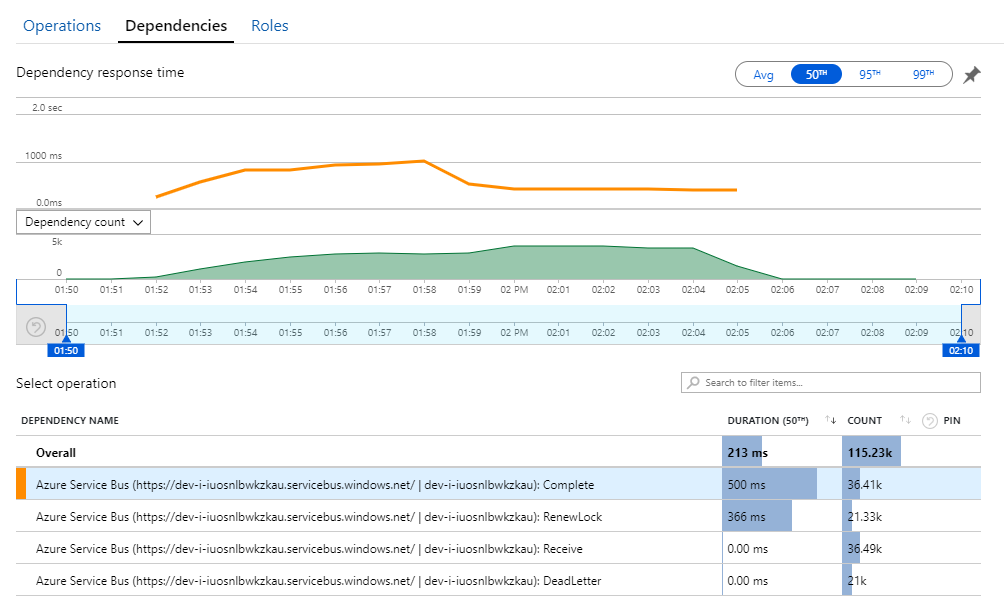
Notez l'entrée relative à DeadLetter. Cet appel indique que les messages entrent dans la file d'attente des lettres mortes de Service Bus.
Pour comprendre ce qui se passe, vous devez connaître la sémantique de la fonctionnalité Peek-Lock de Service Bus. Lorsqu'un client utilise Peek-Lock, Service Bus récupère et verrouille un message de manière atomique. Tant que le verrou est maintenu, le message a la garantie de ne pas être transmis aux autres récepteurs. Si le verrou expire, le message devient disponible pour les autres récepteurs. Après un nombre maximum de tentatives de livraison (qui est configurable), Service Bus place les messages dans une file d'attente de lettres mortes, où ils pourront ultérieurement être examinés.
N’oubliez pas que le service Flux de travail prélève des lots importants de messages (3000 messages à la fois). Cela signifie que la durée totale de traitement de chaque message est plus longue, ce qui entraîne l'expiration des messages, leur retour en file d'attente, et finalement leur transfert vers la file d'attente des lettres mortes.
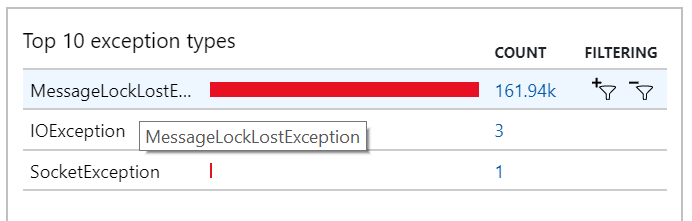
Ce comportement s'applique également aux exceptions, sachant que de nombreuses exceptions MessageLostLockException sont enregistrées :
Test 5 : Augmenter la durée de verrouillage
Pour ce test de charge, la durée de verrouillage des messages a été définie sur 5 minutes pour éviter les dépassements de délai d'attente de verrou. Le graphique des messages entrants et sortants montre maintenant que le système suit le rythme des messages entrants :
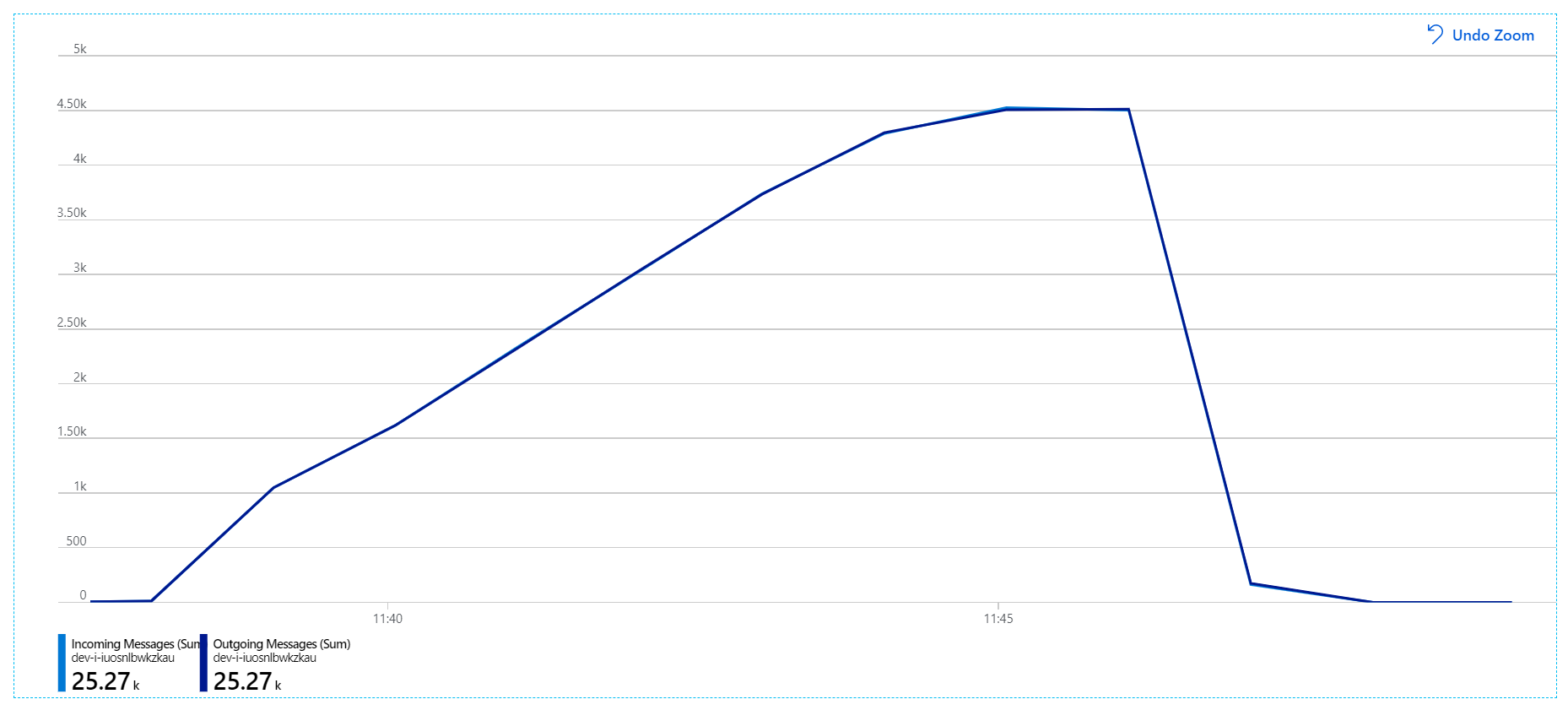
Sur la durée totale du test de charge de 8 minutes, l'application a effectué 25 000 opérations, avec un débit de pointe de 72 opérations/s, ce qui représente une augmentation de 400 % du débit maximum.
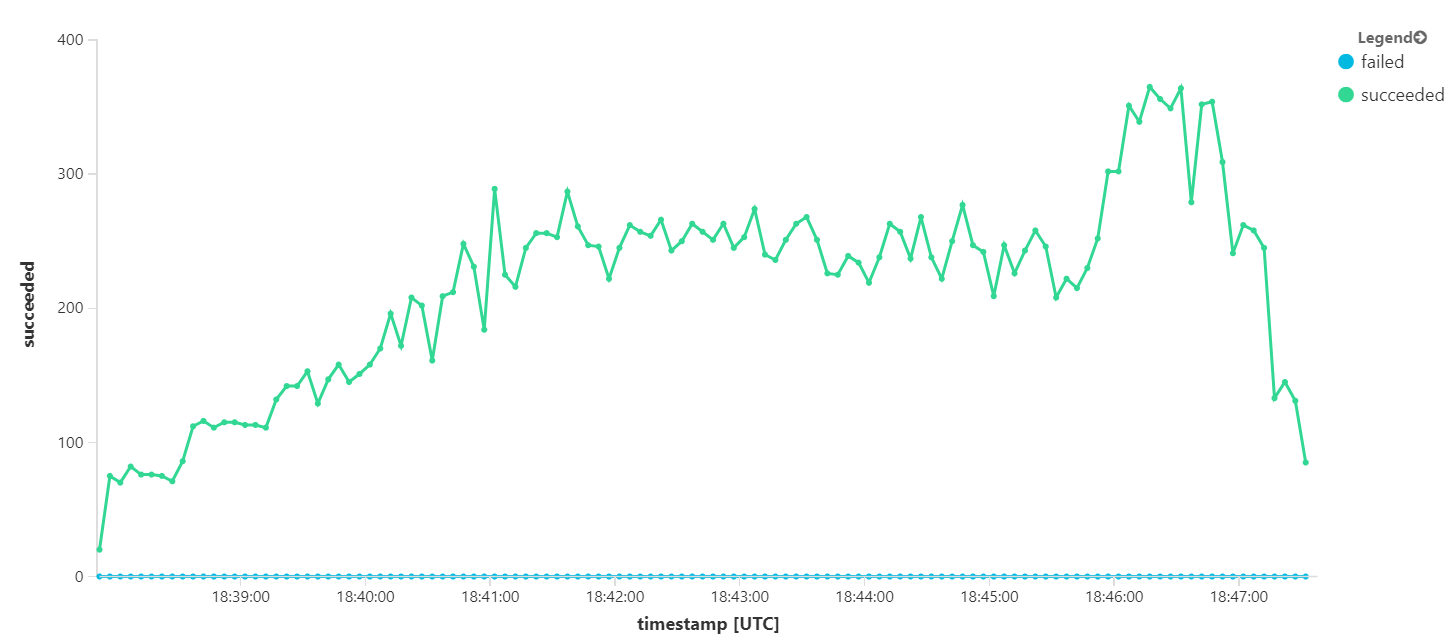
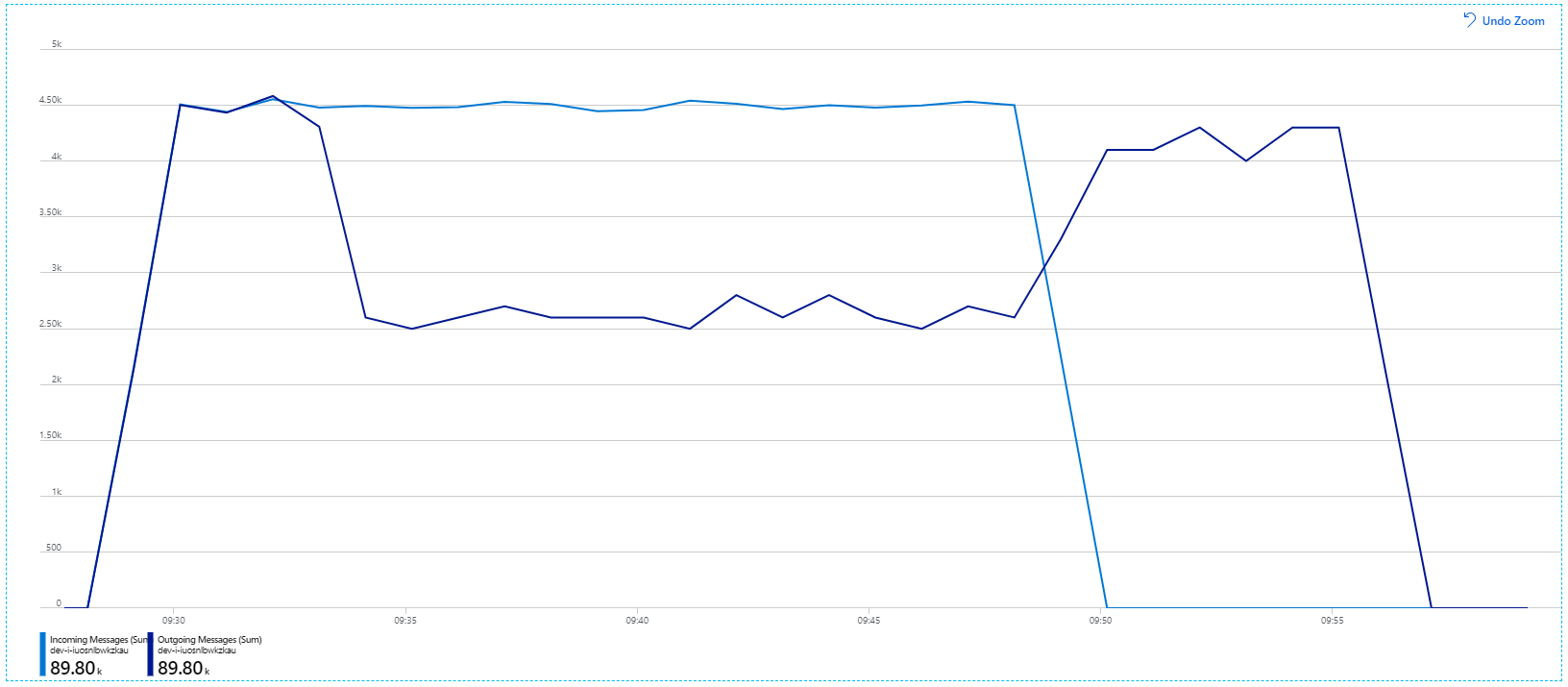
Cependant, l'exécution du même test avec une durée plus longue a montré que l'application ne pouvait pas suivre ce rythme :
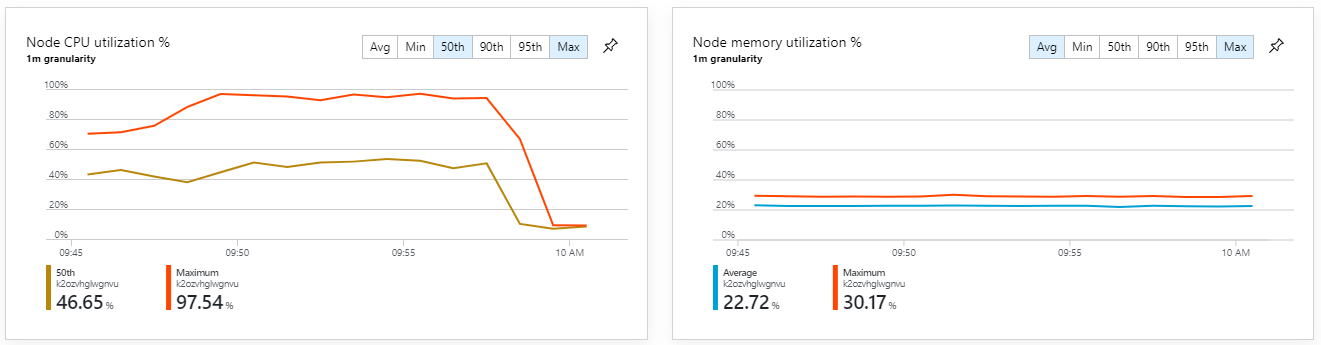
Les métriques de conteneur montrent que l'utilisation maximale de l'UC était proche de 100 %. À ce stade, l'application semble liée à l'UC. Une mise à l'échelle du cluster pourrait maintenant améliorer les performances, contrairement à la précédente tentative de mise à l'échelle.
Test 6 : Effectuer un scale-out des services back-end (une nouvelle fois)
Pour le dernier test de charge de la série, l'équipe a effectué un scale-out du cluster et des pods Kubernetes comme suit :
| Paramètre | Valeur |
|---|---|
| Nœuds de cluster | 12 |
| Service Ingestion | 3 réplicas |
| Service Flux de travail | 6 réplicas |
| Services Colis, Livraison, Planification des drones | 9 réplicas chacun |
Ce test a permis d'obtenir un débit soutenu plus élevé, sans aucun retard significatif dans le traitement des messages. En outre, l'utilisation de l'UC des nœuds est restée inférieure à 80 %.
Résumé
Pour ce scénario, les goulets d’étranglement suivants ont été identifiés :
- Exceptions liées à une mémoire insuffisante dans Azure Cache pour Redis
- Absence de parallélisme dans le traitement des messages
- Durée de verrouillage des messages insuffisante, ce qui entraîne des dépassements de délai d'attente de verrou et le placement des messages dans la file d'attente des lettres mortes
- Épuisement de l'UC
Pour diagnostiquer ces problèmes, l’équipe de développement s’est appuyée sur les mesures suivantes :
- Nombre de messages Service Bus entrants et sortants
- Cartographie d'application et Application Insights
- Erreurs et exceptions
- Requêtes Log Analytics personnalisées
- Utilisation de l'UC et de la mémoire dans les insights de conteneur Azure Monitor.
Étapes suivantes
Pour plus d'informations sur la conception de ce scénario, consultez Conception d'une architecture de microservices.