Considérations relatives à la plateforme d’application pour les charges de travail stratégiques
Un domaine de conception clé de toute architecture stratégique est la plateforme d’application. La plateforme fait référence aux composants d’infrastructure et aux services Azure qui doivent être approvisionnés pour prendre en charge l’application. Voici quelques recommandations générales.
Conception en couches. Choisissez l’ensemble approprié de services, leur configuration et les dépendances spécifiques de l’application. Cette approche en couches permet de créer une segmentation logique et physique. Il est utile de définir des rôles et fonctions (et d’attribuer des privilèges appropriés), ainsi que des stratégies de déploiement. Cette approche augmente finalement la fiabilité du système.
Une application stratégique doit être hautement fiable et résistante aux défaillances de centre de données et régionales. La création d’une redondance zonale et régionale dans une configuration active-active est la stratégie principale. Lorsque vous choisissez des services Azure pour la plateforme de votre application, tenez compte de la prise en charge de leurs zones de disponibilité, ainsi que des modèles de déploiement et opérationnels pour utiliser plusieurs régions Azure.
Utilisez une architecture basée sur des unités d’échelle pour gérer une charge accrue. Des unités d’échelle vous permettent de regrouper logiquement des ressources, et une unité peut être mise à l’échelle indépendamment d’autres unités ou services dans l’architecture. Utilisez votre modèle de capacité et les performances attendues pour définir les limites, le nombre et l’échelle de base de chaque unité.
Dans cette architecture, la plateforme d’application se compose de ressources globales, d’empreinte de déploiement et régionales. Les ressources régionales sont approvisionnées dans le cadre d’une empreinte de déploiement. Chaque empreinte équivaut à une unité d’échelle et, si elle devient non saine, peut être entièrement remplacée.
Les ressources dans chaque couche présentent des caractéristiques distinctes. Pour plus d’informations, consultez Modèle d’architecture d’une charge de travail critique typique.
| Caractéristiques | Considérations |
|---|---|
| Durée de vie | Quelle est la durée de vie attendue de la ressource, par rapport à d’autres ressources de la solution ? La ressource doit-elle survivre, partager la durée de vie avec le système ou la région, ou être temporaire ? |
| State | Quel impact l’état persistant dant cette couche aura-t-il sur la fiabilité ou la gestion ? |
| Reach | La ressource doit-elle être distribuée globalement ? La ressource peut-elle communiquer avec d’autres ressources, globalement ou dans des régions ? |
| Les dépendances | Quelle est la dépendance à d’autres ressources, globalement ou dans d’autres régions ? |
| Limites de mise à l’échelle | Quel est le débit attendu pour cette ressource dans cette couche ? Quelle échelle la ressource fournit-elle pour répondre à cette demande ? |
| Disponibilité et récupération d’urgence | Quel est l’impact sur la disponibilité ou l’urgence dans cette couche ? Un sinistre entraînerait-il une panne systémique ou seulement un problème localisé de capacité ou de disponibilité ? |
Ressources globales
Certaines ressources de cette architecture sont partagées par des ressources déployées dans des régions. Dans cette architecture, elles sont utilisées pour distribuer le trafic entre plusieurs régions, stocker un état permanent pour l’ensemble de l’application et mettre en cache les données statiques globales.
| Caractéristiques | Considérations relatives aux couches |
|---|---|
| Durée de vie | La durée de vie de ces ressources devrait être longue. Elle est égale ou supérieure à la durée de vie du système. Souvent, les ressources sont gérées avec des mises à jour de plan de contrôle et de données sur place, supposant qu’elles prennent en charge les opérations de mise à jour sans temps d’arrêt. |
| State | Ces ressources existant pendant au moins la durée de vie du système, cette couche est souvent responsable du stockage de l’état géo-répliqué global. |
| Reach | Les ressources doivent être distribuées globalement. Il est recommandé que ces ressources communiquent avec des ressources régionales ou autres présentant une faible latence et la cohérence souhaitée. |
| Les dépendances | Les ressources devraient éviter les dépendances à des ressources régionales, car leur indisponibilité peut occasionner une défaillance globale. Par exemple, des certificats ou secrets conservés dans un seul coffre pourraient avoir un impact global en cas de défaillance de la région où se trouve le coffre. |
| Limites de mise à l’échelle | Ces ressources étant souvent des instances uniques dans le système, elles doivent pouvoir adapter leur échelle de manière à pouvoir prendre en charge le débit du système dans son ensemble. |
| Disponibilité et récupération d’urgence | Les ressources régionales et d’empreinte pouvant consommer des ressources globales ou étant mises en avant par celles-ci, il est essentiel que les ressources globales soient configurées avec une haute disponibilité et une récupération d’urgence pour l’intégrité du système entier. |
Dans cette architecture, les ressources de couche globale sont Azure Front Door, Azure Cosmos DB, Azure Container Registry et Azure Log Analytics pour le stockage de journaux et métriques d’autres ressources de couche globale.
Il existe d’autres ressources de base dans cette conception, telles que Microsoft Entra ID et Azure DNS. Cette image les omet par souci de concision.

Équilibreur de charge global
Azure Front Door est utilisé comme unique point d’entrée pour le trafic utilisateur. Azure garantit qu’Azure Front Door fournira le contenu demandé sans erreur 99,99 % du temps. Pour plus d’informations, consultez Limites du service Front Door. Si Front Door devient indisponible, l’utilisateur final voit le système arrêté.
L’instance Front Door envoie le trafic aux services principaux configurés, tels que le cluster de calcul hébergeant l’API et la SPA frontale. Des mauvaises configurations de serveur principal dans Front Door peuvent entraîner des pannes. Pour éviter les pannes occasionnées par de mauvaises configurations, vous devriez tester largement les paramètres de votre Front Door.
Une autre erreur courante peut résulter de certificats TLS mal configurés ou manquants, empêchant les utilisateurs d’utiliser le serveur frontal ou Front Door communiquant vers le serveur principal. L’atténuation du problème pourrait nécessiter une intervention manuelle. Par exemple, vous pourriez éventuellement restaurer la configuration précédente et réécrire le certificat. Quoi qu’il en soit, attendez-vous à une indisponibilité le temps que les modifications prennent effet. L’utilisation de certificats managés offerts par Front door est recommandée pour réduire la surcharge opérationnelle, comme la gestion des expirations.
Front Door offre de nombreuses fonctionnalités en plus du routage du trafic global. Une fonctionnalité importante est le service Web Application Firewall (WAF) qui permet à Front Door d’inspecter le trafic en transit. Configuré en mode Prévention, il bloque le trafic suspect avant qu’il atteigne des serveurs principaux.
Pour plus d’informations sur les fonctionnalités de Front Door, consultez Questions fréquentes (FAQ) sur Azure Front Door.
Pour d'autres considérations sur la distribution globale du trafic, voir les orientations critiques dans un cadre bien architecturé : Routage global.
Container Registry
Azure Container Registry est utilisé pour stocker des artefacts Open Container Initiative (OCI), en particulier des graphiques helm et des images conteneurs. Il ne participe pas au flux de demandes et n’est consulté que périodiquement. Le registre de conteneurs doit préexister au déploiement de ressources d’empreinte, et doit être exempt de toute dépendance à des ressources de couche régionale.
Activez la redondance de zone et la géoréplication des registres afin que l’accès du runtime aux images soit rapide et résilient aux défaillances. En cas d’indisponibilité, l’instance peut basculer vers des régions réplicas, et les demandes sont automatiquement réacheminées vers une autre région. Attendez-vous à des erreurs temporaires d’extraction d’images jusqu’à ce que le basculement soit terminé.
Des défaillances peuvent également se produire si des images sont supprimées par inadvertance, empêchant de nouveaux nœuds de calcul d’extraire des images, mais les nœuds existants peuvent toujours utiliser les images mises en cache. La principale stratégie de récupération d’urgence est le redéploiement. Les artefacts dans un registre de conteneurs peuvent être régénérés à partir de pipelines. Un registre de conteneurs doit être en mesure de résister à de nombreuses connexions simultanées pour prendre en charge tous vos déploiements.
Il est recommandé d’utiliser la référence (SKU) Premium pour permettre la géoréplication. La fonctionnalité de redondance de zone garantit la résilience et la haute disponibilité au sein d’une région spécifique. En cas de panne régionale, les réplicas dans d’autres régions sont toujours disponibles pour les opérations de plan de données. Avec cette référence (SKU), vous pouvez restreindre l’accès aux images via des points de terminaison privés.
Pour plus d’informations, consultez Meilleures pratiques pour Azure Container Registry.
Base de données
Il est recommandé de stocker tous les états globalement dans une base de données séparée des empreintes régionales. Créez une la redondance en déployant la base de données dans plusieurs régions. Pour les charges de travail stratégiques, la synchronisation des données dans plusieurs régions devrait être la première préoccupation. En outre, en cas de défaillance, les demandes d’écriture dans la base de données doivent toujours être fonctionnelles.
Une réplication des données dans une configuration active-active est vivement recommandée. L’application devrait être en mesure de se connecter instantanément à une autre région. Toutes les instances devraient pouvoir traiter les demandes de lecture et d’écriture.
Pour plus d’informations, consultez Plateforme de données pour les charges de travail stratégiques.
Surveillance globale
Azure Log Analytics est utilisé pour stocker les journaux de diagnostic de toutes les ressources globales. Il est recommandé de restreindre le quota quotidien de stockage, en particulier dans les environnements utilisés pour les tests de charge. Définissez également une stratégie de rétention. Ces restrictions permettront d’éviter tout dépassement de budget dû à un stockage de données inutiles au-delà d’une certaine limite.
Considérations relatives aux services fondamentaux
Le système est susceptible d’utiliser d’autres services de plateforme critiques pouvant entraîner un risque pour l’ensemble du système, comme Azure DNS et Microsoft Entra ID. Azure DNS garantit un contrat SLA de disponibilité à 100 % pour les requêtes DNS valides. Microsoft Entra garantit au moins 99,99 % de durée de bon fonctionnement. Toutefois, vous devez être conscient de l’impact en cas de défaillance.
La prise d’une dépendance dure à des services fondamentaux est inévitable parce que de nombreux services Azure en dépendent. Attendez-vous à une interruption du système s’ils sont indisponibles. Exemple :
- Azure Front Door utilise Azure DNS pour atteindre le serveur principal et d’autres services globaux.
- Azure Container Registry utilise Azure DNS pour basculer les demandes vers une autre région.
Dans les deux cas, les deux services Azure seront affectés si Azure DNS est indisponible. La résolution de noms pour les demandes d’utilisateur en provenance de Front Door échouera. Les images Docker ne seront pas extraites du registre. L’utilisation d’un service DNS externe comme sauvegarde n’atténue pas le risque, car de nombreux services Azure n’autorisent pas cette configuration et s’appuient sur un DNS interne. Attendez-vous à une panne complète.
De même, Microsoft Entra ID est utilisé pour des opérations de plan de contrôle telles que la création de nœuds AKS, l’extraction d’images à partir de Container Registry ou l’accès à Key Vault lors du démarrage de pod. Si Microsoft Entra ID est indisponible, les composants existants ne devraient pas être affectés, mais il se peut que les performances globales se dégradent. Les nouveaux pods ou nœuds AKS ne seront pas fonctionnels. Par conséquent, si des opérations de scale-out sont requises pendant ce temps, attendez-vous à une altération de l’expérience utilisateur.
Ressources d’empreinte de déploiement régionales
Dans cette architecture, l’empreinte de déploiement déploie la charge de travail et approvisionne les ressources qui participent à l’accomplissement des transactions commerciales. Une empreinte correspond généralement à un déploiement dans une région Azure. Une région peut néanmoins avoir plusieurs empreintes.
| Caractéristiques | Considérations |
|---|---|
| Durée de vie | Les ressources sont censées avoir une durée de vie éphémère, l’intention étant qu’elles puissent être ajoutées et supprimées de façon dynamique, tandis que les ressources régionales en dehors de l’empreinte continuent de persister. La nature éphémère est nécessaire pour offrir une plus grande résilience, une mise à l’échelle et une proximité avec les utilisateurs. |
| State | Les empreintes étant éphémères et pouvant être détruites à tout moment, elles doivent être autant que possible sans état. |
| Reach | Peut communiquer avec des ressources régionales et globales. Toutefois, la communication avec d’autres régions ou d’autres empreintes devrait être évitée. Dans cette architecture, il n’est pas nécessaire que ces ressources soient distribuées globalement. |
| Les dépendances | Les ressources d’empreinte doivent être indépendantes. Autrement dit, elles ne doivent pas dépendre d’autres empreintes ou composants dans d’autres régions. Elles sont censées avoir des dépendances régionales et globales. Le composant partagé principal est constitué de la couche de base de données et du registre de conteneurs. Ce composant nécessite une synchronisation au moment du runtime. |
| Limites de mise à l’échelle | Le débit est établi par le biais de tests. Le débit de l’empreinte globale est limité à la ressource la moins performante. Le débit d’empreinte doit tenir compte de l’estimation du niveau élevé de la demande et de tout basculement résultant de l’indisponibilité d’une autre empreinte dans la région. |
| Disponibilité et récupération d’urgence | En raison de la nature temporaire des empreintes, la récupération d’urgence est effectuée en redéployant l’empreinte. Si l’état de certaines ressources est non sain, l’empreinte, dans son ensemble, peut être détruite et redéployée. |
Dans cette architecture, les ressources d’empreinte sont Azure Kubernetes Service, Azure Event Hubs, Azure Key Vault et Stockage Blob Azure.
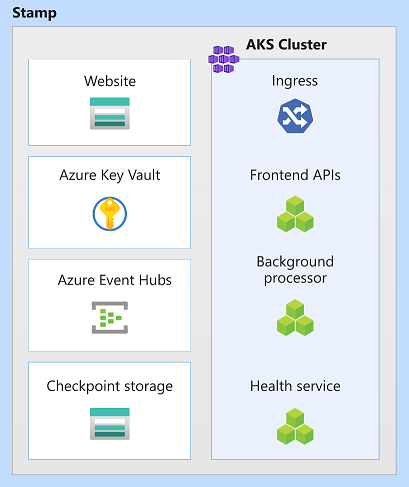
Unité d'échelle
Une empreinte peut également être considérée comme une unité d’échelle (SU). Tous les composants et services au sein d’un tampon donné sont configurés et testés pour servir les demandes dans une plage donnée. Voici un exemple d’unité d’échelle utilisée dans l’implémentation.
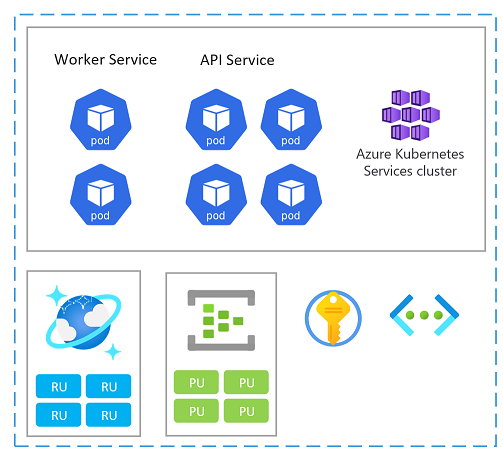
Chaque unité d’échelle étant déployée dans une région Azure, elle gère principalement le trafic en provenance de cette zone (même si elle peut reprendre en charge le trafic provenant d’autres régions si nécessaire). Cette répartition géographique étant susceptible d’entraîner des modèles de charge et des heures ouvrées variables d’une région à l’autre, chaque unité d’échelle est conçue pour s’adapter en cas d’inactivité.
Vous pouvez déployer une nouvelle empreinte pour la mise à l’échelle. À l’intérieur d’une empreinte, des ressources individuelles peuvent également être des unités d’échelle.
Voici quelques considérations relatives à la mise à l’échelle et à la disponibilité lors du choix de services Azure dans une unité :
Évaluez les relations de capacité entre toutes les ressources dans une unité d’échelle. Par exemple, pour gérer 100 demandes entrantes, 5 pods contrôleurs d’entrée, 3 pods de service de catalogue et 1000 unités de requête dans Azure Cosmos DB seraient nécessaires. Par conséquent, compte tenu de ces plages, lors de la mise à l’échelle automatique des pods d’entrée, attendez-vous à une mise à l’échelle du service de catalogue et des unités de requête Azure Cosmos DB.
Testez la charge des services pour déterminer une plage dans laquelle les demandes seront servies. En fonction des résultats, configurez les instances minimales et maximales, ainsi que les métriques cibles. Lorsque la cible est atteinte, vous pouvez choisir d’automatiser la mise à l’échelle de l’unité entière.
Examinez les limites et quotas d’échelle d’abonnement Azure pour prendre en charge le modèle de capacité et de coût défini par les exigences métier. Vérifiez également les limites des services individuels pris en considération. Étant donné que des unités sont généralement déployées ensemble, tenez compte des limites de ressources d’abonnement requises pour les déploiements de contrôle de validité. Pour plus d’informations, consultez Limites de service Azure.
Choisissez les services qui prennent en charge les zones de disponibilité afin de mettre en place une redondance. Cela pourrait limiter vos choix technologiques. Pour plus d’informations, consultez Zones de disponibilité.
Pour d'autres considérations sur la taille d'une unité et la combinaison des ressources, voir les orientations relatives aux missions essentielles dans le cadre bien conçu : L'architecture des unités à grande échelle.
Cluster de calcul
Pour conteneuriser la charge de travail, chaque empreinte doit exécuter un cluster de calcul. Dans cette architecture, Azure Kubernetes Service (AKS) est choisi parce que Kubernetes est la plateforme de calcul la plus populaire pour les applications modernes et conteneurisées.
La durée de vie du cluster AKS est liée à la nature éphémère de l’empreinte. Le cluster est sans état et dépourvu de volumes persistants. Il utilise des disques de système d’exploitation éphémères au lieu de disques managés, car les disques ne sont pas censés faire l’objet d’une maintenance au niveau du système ou de l’application.
Pour augmenter la fiabilité, le cluster est configuré pour utiliser les trois zones de disponibilité dans une région donnée. En outre, pour activer l'AKS Uptime SLA avec une disponibilité garantie de 99,95 % du plan de contrôle de l'AKS, le cluster doit utiliser le niveau Standard ou Premium. Pour en savoir plus, consultez les paliers de tarification d'AKS.
D’autres facteurs tels que des limites d’échelle, une capacité de calcul ou un quota d’abonnement peuvent également avoir un impact sur la fiabilité. Si le capacité est insuffisante ou si des limites sont atteintes, des opérations de mise à l’échelle échouent, mais le calcul existant est censé fonctionner.
La mise à l’échelle automatique du cluster est activée pour permettre aux pools de nœuds de monter en puissance automatiquement si nécessaire, ce qui améliore la fiabilité. Lorsque vous utilisez plusieurs pools de nœuds, tous devraient se mettre à l’échelle automatiquement.
Au niveau pod, l’autoscaler de pods horizontaux (HPA) met à l’échelle les pods en fonction de métriques d’UC, de mémoire ou personnalisées configurées. Testez en charge les composants de la charge de travail afin d’établir une ligne de base pour les valeurs de l’autoscaler et du HPA.
Le cluster est également configuré pour les mises à niveau automatiques d’images de nœud et pour une mise à l’échelle appropriée pendant ces mises à niveau. Cette mise à l’échelle permet d’éviter tout temps d’arrêt pendant les mises à niveau. Une défaillance du cluster dans une empreinte lors d’une mise à niveau ne devrait pas affecter d’autres clusters dans d’autres empreintes, mais des mises à niveau dans les empreintes devraient se produire à différents moments pour maintenir la disponibilité. Par ailleurs, les mises à niveau de cluster sont automatiquement déployées sur les nœuds de façon à ce que ceux-ci ne soient pas indisponibles en même temps.
Certains composants tels que cert-manager et ingress-nginx nécessitent des images conteneurs extraites de registres de conteneurs externes. Si ces référentiels ou images sont indisponibles, il se peut que de nouvelles instances sur de nouveaux nœuds (où l’image n’est pas mise en cache) ne puissent pas démarrer. Il est possible d’atténuer ce risque en important ces images dans l’Azure Container Registry de l’environnement.
L’observabilité est essentielle dans cette architecture, car les empreintes sont éphémères. Les paramètres de diagnostic sont configurés pour stocker toutes les données de journal et de métrique dans un espace de travail Log Analytics régional. En outre, AKS Container Insights est activé via un agent OMS dans le cluster. Cet agent permet au cluster d’envoyer des données de surveillance à l’espace de travail Log Analytics.
Pour d'autres considérations sur le cluster de calcul, consultez les conseils relatifs aux missions critiques dans Well-architected Framework : Orchestration de conteneurs et Kubernetes.
Key Vault
Azure Key Vault est utilisé pour stocker des secrets globaux tels que des chaînes de connexion à la base de données, et des secrets d’empreinte tels que la chaîne de connexion Event Hubs.
Cette architecture utilise un Pilote CSI du magasin de secrets dans le cluster de calcul pour obtenir des secrets du Key Vault. Des secrets sont nécessaires lors de la production de nouveaux pods. Si Key Vault est indisponible, il se peut que les nouveaux pods de démarrent pas. Cela pourrait occasionner des perturbations des opérations de mise à l’échelle, des mises à jour et des nouveaux déploiements.
Key Vault limite le nombre d’opérations. En raison de la mise à jour automatique des secrets, la limite peut être atteinte si les pods sont nombreux. Pour éviter cette situation, vous pouvez réduire la fréquence des mises à jour.
Pour d'autres considérations sur la gestion des secrets, voir les orientations relatives aux missions critiques dansWell-architected Framework : Protection de l'intégrité des données.
Event Hubs
Le seul service avec état dans l’empreinte est le répartiteur de messages, Azure Event Hubs, qui stocke les demandes pendant une courte période. Le répartiteur répond au besoin de mise en mémoire tampon et de messagerie fiable. Les demandes traitées sont conservées dans la base de données globale.
Dans cette architecture, une référence (SKU) Standard est utilisée et une redondance de zone est activée pour la haute disponibilité.
L’intégrité d’Event Hubs est vérifiée par le composant HealthService s’exécutant sur le cluster de calcul. Celui-ci vérifie périodiquement diverses ressources. C’est utile pour détecter des conditions non saines. Par exemple, si des messages ne peuvent pas être envoyés au hub d’événements, l’empreinte est inutilisable pour toutes les opérations d’écriture. HealthService devrait détecter automatiquement cette condition et signaler l’état non sain à Front Door qui retirera l’empreinte de la rotation.
Pour la scalabilité, l’activation de la majoration automatique est recommandée.
Pour plus d’informations, consultez Services de messagerie pour les charges de travail stratégiques.
Pour d'autres considérations sur la messagerie, voir les conseils sur les missions critiques dans le cadre bien architecturé : Messagerie asynchrone.
Comptes de stockage
Dans cette architecture, deux comptes de stockage sont approvisionnés. Tous deux sont déployés en mode redondant interzone (ZRS).
Un compte est utilisé pour la création de point de contrôle Event Hubs. Si ce compte n’est pas réactif, l’empreinte ne peut pas traiter les messages d’Event Hubs, ce qui pourrait avoir un impact sur d’autres services dans l’empreinte. Cette condition est vérifiée périodiquement par HealthService, l’un des composants d’application s’exécutant dans le cluster de calcul.
L’autre compte est utilisé pour héberger l’application monopage d’interface utilisateur. Si le service du site web statique rencontre des problèmes, Front Door détecte le problème et n’envoie pas de trafic à ce compte de stockage. Pendant ce temps, Front Door peut utiliser du contenu mis en cache.
Pour plus d’informations sur la récupération, consultez Récupération d’urgence et basculement de compte de stockage.
Ressources régionales
Un système peut avoir des ressources déployées dans une région, qui survivent aux ressources d’empreinte. Dans cette architecture, les données d’observabilité pour les ressources d’empreinte sont stockées dans des magasins de données régionaux.
| Caractéristiques | Considération |
|---|---|
| Durée de vie | Les ressources ont la même durée de vie que la région et survivent aux ressources d’empreinte. |
| State | La durée de vie d’un état stocké dans une région ne peut pas dépasser la durée de vie de celle-ci. Si l’état doit être partagé entre plusieurs régions, envisagez d’utiliser un magasin de données global. |
| Reach | Les ressources n’ont pas besoin d’être distribuées globalement. Une communication directe avec d’autres régions doit être évitée à tout prix. |
| Les dépendances | Les ressources peuvent présenter des dépendances à des ressources globales, mais pas à des ressources d’empreinte, car les empreintes sont censées être de courte durée. |
| Limites de mise à l’échelle | Déterminez la limite d’échelle des ressources régionales en combinant tous les empreintes au sein de la région. |
Surveillance de données pour des ressources d’empreinte
Le déploiement de ressources de surveillance est un exemple classique pour des ressources régionales. Dans cette architecture, chaque région dispose d’un espace de travail Log Analytics individuel configuré pour stocker toutes les données de journal et de métrique émises à partir de ressources d’empreinte. Les ressources régionales survivant aux ressources d’empreinte, les données restent disponibles après la suppression de l’empreinte.
Azure Log Analytics et Azure Application Insights sont utilisés pour stocker les journaux et les métriques de la plateforme. Il est recommandé de restreindre le quota quotidien de stockage, en particulier dans les environnements utilisés pour les tests de charge. Définissez également une stratégie de rétention pour stocker toutes les données. Ces restrictions permettront d’éviter tout dépassement de budget dû à un stockage de données inutiles au-delà d’une certaine limite.
De même, Application Insights est également déployé en tant que ressource régionale pour collecter toutes les données de surveillance d’application.
Pour des recommandations de conception sur la surveillance, voir les conseils sur les missions critiques dans le cadre bien architecturé : Modélisation de l'intégrité.
Étapes suivantes
Déployez l’implémentation de référence pour comprendre pleinement les ressources utilisées dans cette architecture, ainsi que leur configuration.