Tutoriel : Configurer des groupes de disponibilité pour SQL Server sur des machines virtuelles Ubuntu dans Azure
Ce didacticiel vous montre comment effectuer les opérations suivantes :
- Créer des machines virtuelles et les placer dans un groupe à haute disponibilité
- Activer la haute disponibilité
- Créez un cluster Pacemaker
- Configurer un agent d’isolation en créant un appareil STONITH
- Installer SQL Server et mssql-tools sur Ubuntu
- Configurer un groupe de disponibilité SQL Server AlwaysOn
- Configurer les ressources de groupe de disponibilité dans le cluster Pacemaker
- Tester un basculement et l’agent d’isolation
Remarque
Communication sans stéréotype
Cet article contient des références au terme esclave, un terme que Microsoft considère comme choquant lorsqu’il est utilisé dans ce contexte. Le terme apparaît dans cet article, car il apparaît actuellement dans le logiciel. Lorsque le terme sera supprimé du logiciel, nous le supprimerons de l’article.
Ce tutoriel utilise Azure CLI pour déployer des ressources dans Azure.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
Utilisez l’environnement Bash dans Azure Cloud Shell. Pour plus d’informations, consultez Démarrage rapide pour Bash dans Azure Cloud Shell.

Si vous préférez exécuter les commandes de référence de l’interface de ligne de commande localement, installez l’interface Azure CLI. Si vous exécutez sur Windows ou macOS, envisagez d’exécuter Azure CLI dans un conteneur Docker. Pour plus d’informations, consultez Guide pratique pour exécuter Azure CLI dans un conteneur Docker.
Si vous utilisez une installation locale, connectez-vous à Azure CLI à l’aide de la commande az login. Pour finir le processus d’authentification, suivez les étapes affichées dans votre terminal. Pour connaître les autres options de connexion, consultez Se connecter avec Azure CLI.
Lorsque vous y êtes invité, installez l’extension Azure CLI lors de la première utilisation. Pour plus d’informations sur les extensions, consultez Utiliser des extensions avec Azure CLI.
Exécutez az version pour rechercher la version et les bibliothèques dépendantes installées. Pour effectuer une mise à niveau vers la dernière version, exécutez az upgrade.
- Cet article nécessite la version 2.0.30 ou ultérieure de l’interface Azure CLI. Si vous utilisez Azure Cloud Shell, la version la plus récente est déjà installée.
Créer un groupe de ressources
Si vous avez plusieurs abonnements, sélectionnez l’abonnement dans lequel vous souhaitez déployer ces ressources.
Utilisez la commande suivante pour créer un groupe de ressources <resourceGroupName> dans une région. Remplacez <resourceGroupName> par le nom de votre choix. Ce didacticiel utilise East US 2. Pour plus d’informations, consultez ce guide de démarrage rapide.
az group create --name <resourceGroupName> --location eastus2
Créer un groupe à haute disponibilité
L’étape suivante consiste à créer un groupe à haute disponibilité. Exécutez la commande suivante dans Azure Cloud Shell et remplacez <resourceGroupName> par le nom de votre groupe de ressources. Choisissez un nom pour <availabilitySetName>.
az vm availability-set create \
--resource-group <resourceGroupName> \
--name <availabilitySetName> \
--platform-fault-domain-count 2 \
--platform-update-domain-count 2
Une fois l’exécution de la commande terminée, vous devez obtenir les résultats suivants :
{
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/availabilitySets/<availabilitySetName>",
"location": "eastus2",
"name": "<availabilitySetName>",
"platformFaultDomainCount": 2,
"platformUpdateDomainCount": 2,
"proximityPlacementGroup": null,
"resourceGroup": "<resourceGroupName>",
"sku": {
"capacity": null,
"name": "Aligned",
"tier": null
},
"statuses": null,
"tags": {},
"type": "Microsoft.Compute/availabilitySets",
"virtualMachines": []
}
Créer un réseau virtuel et un sous-réseau
Créez un sous-réseau nommé avec une plage d'adresses IP prédéfinie. Remplacez ces valeurs dans la commande suivante :
<resourceGroupName><vNetName><subnetName>
az network vnet create \ --resource-group <resourceGroupName> \ --name <vNetName> \ --address-prefix 10.1.0.0/16 \ --subnet-name <subnetName> \ --subnet-prefix 10.1.1.0/24La commande précédente crée un réseau virtuel et un sous-réseau contenant une plage d’adresses IP personnalisée.
Créer des ordinateurs virtuels Ubuntu dans le groupe à haute disponibilité
Obtenez la liste des images de machine virtuelle qui offrent un système d'exploitation basé sur Ubuntu dans Azure.
az vm image list --all --offer "sql2022-ubuntupro2004"Vous devez voir les résultats suivants lorsque vous recherchez les images BYOS :
[ { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "enterprise_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:enterprise_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "sqldev_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:sqldev_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "standard_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:standard_upro:16.0.230808", "version": "16.0.230808" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.221108", "version": "16.0.221108" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.230207", "version": "16.0.230207" }, { "architecture": "x64", "offer": "sql2022-ubuntupro2004", "publisher": "MicrosoftSQLServer", "sku": "web_upro", "urn": "MicrosoftSQLServer:sql2022-ubuntupro2004:web_upro:16.0.230808", "version": "16.0.230808" } ]Ce didacticiel utilise
Ubuntu 20.04.Important
Pour la configuration du groupe de disponibilité, les noms de machines doivent comporter moins de 15 caractères. Les noms d'utilisateur ne peuvent pas contenir de caractères en majuscules et les mots de passe doivent comporter entre 12 et 72 caractères.
Créez trois machines virtuelles dans le groupe à haute disponibilité. Remplacez ces valeurs dans la commande suivante :
<resourceGroupName><VM-basename><availabilitySetName><VM-Size>- Par exemple, « Standard_D16s_v3 »<username><adminPassword><vNetName><subnetName>
for i in `seq 1 3`; do az vm create \ --resource-group <resourceGroupName> \ --name <VM-basename>$i \ --availability-set <availabilitySetName> \ --size "<VM-Size>" \ --os-disk-size-gb 128 \ --image "Canonical:0001-com-ubuntu-server-jammy:20_04-lts-gen2:latest" \ --admin-username "<username>" \ --admin-password "<adminPassword>" \ --authentication-type all \ --generate-ssh-keys \ --vnet-name "<vNetName>" \ --subnet "<subnetName>" \ --public-ip-sku Standard \ --public-ip-address "" done
La commande précédente crée les machines virtuelles à l’aide du réseau virtuel défini précédemment. Pour plus d’informations sur les différentes configurations, consultez l’article az vm create.
La commande inclut également le paramètre --os-disk-size-gb permettant de créer une taille de lecteur de système d’exploitation personnalisée de 128 Go. Si vous augmentez cette taille ultérieurement, développez les volumes de dossiers appropriés pour prendre en charge votre installation, configurez le Gestionnaire de volumes logiques (LVM).
Une fois la commande exécutée sur chaque machine virtuelle, vous devez obtenir des résultats similaires à ce qui suit :
{
"fqdns": "",
"id": "/subscriptions/<subscriptionId>/resourceGroups/<resourceGroupName>/providers/Microsoft.Compute/virtualMachines/ubuntu1",
"location": "westus",
"macAddress": "<Some MAC address>",
"powerState": "VM running",
"privateIpAddress": "<IP1>",
"resourceGroup": "<resourceGroupName>",
"zones": ""
}
Tester la connexion aux machines virtuelles créées
Connectez-vous à chaque machine virtuelle à l’aide de la commande suivante dans Azure Cloud Shell. Si vous ne parvenez pas à trouver les adresses IP de vos machines virtuelles, suivez ce Démarrage rapide sur Azure Cloud Shell.
ssh <username>@<publicIPAddress>
Si la connexion a réussi, vous devez voir la sortie suivante qui représente le terminal Linux :
[<username>@ubuntu1 ~]$
Tapez exit pour quitter la session SSH.
Configurer l’accès SSH sans mot de passe entre les nœuds
L’accès SSH sans mot de passe permet à vos machines virtuelles de communiquer entre elles à l’aide de clés publiques SSH. Vous devez configurer des clés SSH sur chaque nœud et copier ces clés sur chaque nœud.
Générer de nouvelles clés SSH
La taille de clé SSH requise est de 4 096 bits. Sur chaque machine virtuelle, accédez au dossier /root/.ssh et exécutez la commande suivante :
ssh-keygen -t rsa -b 4096
Au cours de cette étape, vous pourriez être invité à remplacer un fichier SSH existant. Vous devez accepter cette invite. Vous n’avez pas besoin d’entrer une phrase secrète.
Copiez les clés SSH publiques
Sur chaque nœud managé, vous devez copier la clé publique à partir du nœud que vous venez de créer, à l’aide de la commande ssh-copy-id. Si vous souhaitez spécifier le répertoire cible sur le nœud managé, vous pouvez utiliser le paramètre -i.
Dans la commande suivante, le compte <username> peut être le même que celui que vous avez configuré pour chaque nœud lors de la création de la machine virtuelle. Vous pouvez également utiliser le compte root, bien que cette option ne soit pas recommandée dans un environnement de production.
sudo ssh-copy-id <username>@ubuntu1
sudo ssh-copy-id <username>@ubuntu2
sudo ssh-copy-id <username>@ubuntu3
Vérifier l’accès sans mot de passe à partir de chaque nœud
Pour vérifier que la clé publique SSH a été copiée sur chaque nœud, utilisez la commande ssh à partir du nœud de contrôleur. Si vous avez correctement copié les clés, vous ne serez pas invité à entrer de mot de passe et la connexion aboutira.
Dans cet exemple, nous nous connectons aux deuxième et troisième nœuds à partir de la première machine virtuelle (ubuntu1). De nouveau, le compte <username> peut être le même que celui que vous avez configuré pour chaque nœud lors de la création de de la machine virtuelle.
ssh <username>@ubuntu2
ssh <username>@ubuntu3
Répétez ce processus à partir des trois nœuds, afin que chaque nœud puisse communiquer avec les autres sans nécessiter de mots de passe.
Configurer la résolution de noms
Vous pouvez configurer la résolution de noms à l’aide de DNS ou en modifiant manuellement le fichier etc/hosts sur chaque nœud.
Pour plus d’informations sur DNS et Active Directory, consultez Joindre SQL Server sur un hôte Linux à un domaine Active Directory.
Important
Nous vous recommandons d’utiliser votre adresse IP privée dans l’exemple précédent. L’utilisation de l’adresse IP publique dans cette configuration entraînera l’échec de l’installation et exposera votre machine virtuelle à des réseaux externes.
Les machines virtuelles et leur adresse IP utilisées dans cet exemple sont répertoriées comme suit :
ubuntu1: 10.0.0.85ubuntu2: 10.0.0.86ubuntu3: 10.0.0.87
Activer la haute disponibilité
Utilisez ssh pour vous connecter à chacun des 3 ordinateurs virtuels, puis une fois connectées, exécutez les commandes suivantes pour activer la haute disponibilité.
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Installer et configurer le cluster Pacemaker
Pour procéder à la configuration du cluster Pacemaker, vous devez installer les packages et les agents de ressources nécessaires. Exécutez les commandes ci-dessous sur chacune de vos machine virtuelle :
sudo apt-get install -y pacemaker pacemaker-cli-utils crmsh resource-agents fence-agents csync2 python3-azure
procédez à présent à la création de la clé d'authentification sur le serveur principal :
sudo corosync-keygen
La clé d'authentification est générée dans l'emplacement /etc/corosync/authkey. Copiez clé d'authentification sur les serveurs secondaires à cet emplacement : /etc/corosync/authkey
sudo scp /etc/corosync/authkey username@ubuntu2:~
sudo scp /etc/corosync/authkey username@ubuntu3:~
déplacez la clé d'authentification du répertoire de base vers /etc/corosync.
sudo mv authkey /etc/corosync/authkey
Procédez à la création du cluster en utilisant les commandes suivantes :
cd /etc/corosync/
sudo vi corosync.conf
modifiez le fichier Corosync pour représenter le contenu comme suit :
totem {
version: 2
secauth: off
cluster_name: demo
transport: udpu
}
nodelist {
node {
ring0_addr: 10.0.0.85
name: ubuntu1
nodeid: 1
}
node {
ring0_addr: 10.0.0.86
name: ubuntu2
nodeid: 2
}
node {
ring0_addr: 10.0.0.87
name: ubuntu3
nodeid: 3
}
}
quorum {
provider: corosync_votequorum
two_node: 0
}
qb {
ipc_type: native
}
logging {
fileline: on
to_stderr: on
to_logfile: yes
logfile: /var/log/corosync/corosync.log
to_syslog: no
debug: off
}
copiez le fichier corosync.conf vers d'autres nœuds vers /etc/corosync/corosync.conf :
sudo scp /etc/corosync/corosync.conf username@ubuntu2:~
sudo scp /etc/corosync/corosync.conf username@ubuntu3:~
sudo mv corosync.conf /etc/corosync/
redémarrez Pacemaker et Corosync, puis confirmez le status :
sudo systemctl restart pacemaker corosync
sudo crm status
La sortie doit ressembler à celle-ci :
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by hacluster via crmd on ubuntu1
* 3 nodes configured
* 0 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* No resources
Configurer l’agent d’isolation
configurez l'isolation sur le cluster. L'isolation est l'isolation du nœud ayant échoué dans un cluster. Elle redémarre le nœud ayant échoué, le laisse être mis hors service, réinitialisé et remis en service, rejoignant ainsi le cluster.
Pour configurer l'isolation, effectuez les actions suivantes :
- inscrivez une nouvelle application dans Microsoft Entra ID et créez un secret.
- Créer un rôle personnalisé à partir d'un fichier json dans powershell/CLI
- Attribuer le rôle et l'application aux ordinateurs virtuels du cluster
- Définir les propriétés de l'agent d'isolation
inscrivez une nouvelle application dans Microsoft Entra ID et créez un secret.
- Accédez à Microsoft Entra ID dans le portail et notez l'ID de client.
- Sélectionnez Inscriptions d'applications dans le menu de gauche, puis sélectionnez Nouvelle inscription.
- Saisissez un nom, puis sélectionnez Comptes dans l'annuaire de cette organization uniquement.
- Pour Type d'application, sélectionnez Web, saisissez
http://localhosten tant que URL de connexion, puis sélectionnez Inscrire. - Sélectionnez Certificats et secrets dans le menu de gauche, puis sélectionnez Nouvelle clé secrète client.
- Saisissez une description et sélectionnez une période d'expiration.
- Notez la valeur du secret, elle est utilisée comme mot de passe suivant. Par ailleurs, l'ID de secret est utilisée comme nom d'utilisateur suivant.
- Sélectionnez « Vue d'ensemble » et notez l'ID d'application. Elle est utilisée comme identifiant de connexion suivant.
Créez un fichier JSON appelé fence-agent-role.json et ajoutez ce qui suit (ajout de votre ID d'abonnement) :
{
"Name": "Linux Fence Agent Role-ap-server-01-fence-agent",
"Id": null,
"IsCustom": true,
"Description": "Allows to power-off and start virtual machines",
"Actions": [
"Microsoft.Compute/*/read",
"Microsoft.Compute/virtualMachines/powerOff/action",
"Microsoft.Compute/virtualMachines/start/action"
],
"NotActions": [],
"AssignableScopes": [
"/subscriptions/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
]
}
créer un rôle personnalisé à partir d'un fichier JSON dans PowerShell/CLI
az role definition create --role-definition fence-agent-role.json
Attribuer le rôle et l'application aux ordinateurs virtuels du cluster
- Pour chacun des ordinateurs virtuels du cluster, sélectionnez Access Control (IAM) dans le menu latéral.
- Sélectionnez Ajouter une attribution de rôle (utilisez l'expérience classique).
- Sélectionnez le rôle créé précédemment.
- Dans la liste Sélectionner, saisissez le nom de l'application créée précédemment.
Nous pouvons à présent créer la ressource agent d'isolation en utilisant les valeurs précédentes et l'ID de votre abonnement :
sudo crm configure primitive fence-vm stonith:fence_azure_arm \
params \
action=reboot \
resourceGroup="resourcegroupname" \
resourceGroup="$resourceGroup" \
username="$secretId" \
login="$applicationId" \
passwd="$password" \
tenantId="$tenantId" \
subscriptionId="$subscriptionId" \
pcmk_reboot_timeout=900 \
power_timeout=60 \
op monitor \
interval=3600 \
timeout=120
Définir les propriétés de l'agent d'isolation
Exécutez les commandes suivantes pour définir les propriétés de l'agent d'isolation :
sudo crm configure property cluster-recheck-interval=2min
sudo crm configure property start-failure-is-fatal=true
sudo crm configure property stonith-timeout=900
sudo crm configure property concurrent-fencing=true
sudo crm configure property stonith-enabled=true
ensuite, confirmez le status du cluster :
sudo crm status
La sortie doit ressembler à celle-ci :
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 1 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* fence-vm (stonith:fence_azure_arm): Started ubuntu1
Installer SQL Server et mssql-tools
Exécutez les commandes suivantes pour installer SQL Server :
Importez les clés GPG de dépôt public :
curl https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.ascenregistrez le référentiel Ubuntu.
sudo add-apt-repository "$(wget -qO- https://packages.microsoft.com/config/ubuntu/20.04/mssql-server-2022.list)"Exécutez les commandes suivantes pour installer SQL Server :
sudo apt-get update sudo apt-get install -y mssql-serverUne fois l'installation du package terminée, lancez
mssql-conf setupet suivez les invites pour définir le mot de passe AS et choisir votre édition. Pour rappel, les éditions suivantes sont sous licence libre : Evaluation, Developer, et Express.sudo /opt/mssql/bin/mssql-conf setupUne fois la configuration terminée, vérifiez que le service est en cours d'exécution :
systemctl status mssql-server --no-pagerInstaller les outils en ligne de commande SQL Server
Pour créer une base de données, vous devez vous connecter à un outil capable d’exécuter des instructions Transact-SQL sur SQL Server. Les étapes suivantes installent les outils en ligne de commande SQL Server : sqlcmd et bcp.
Procédez comme suit pour installer mssql-tools18 sur Ubuntu.
Remarque
- Ubuntu 18.04 est pris en charge à compter de SQL Server 2019 CU 3.
- Ubuntu 20.04 est pris en charge à compter de SQL Server 2019 CU 10.
- Ubuntu 22.04 est pris en charge à compter de SQL Server 2022 CU 10.
Entrez en mode superutilisateur.
sudo suImportez les clés GPG de référentiel public.
curl https://packages.microsoft.com/keys/microsoft.asc | sudo tee /etc/apt/trusted.gpg.d/microsoft.ascEnregistrez le référentiel Microsoft Ubuntu.
Pour Ubuntu 22.04, utilisez la commande suivante :
curl https://packages.microsoft.com/config/ubuntu/22.04/prod.list > /etc/apt/sources.list.d/mssql-release.listPour Ubuntu 20.04, utilisez la commande suivante :
curl https://packages.microsoft.com/config/ubuntu/20.04/prod.list > /etc/apt/sources.list.d/mssql-release.listPour Ubuntu 18.04, utilisez la commande suivante :
curl https://packages.microsoft.com/config/ubuntu/18.04/prod.list > /etc/apt/sources.list.d/mssql-release.listPour Ubuntu 16.04, utilisez la commande suivante :
curl https://packages.microsoft.com/config/ubuntu/16.04/prod.list > /etc/apt/sources.list.d/mssql-release.list
Quittez le mode superutilisateur.
exitMettez à jour la liste des sources et exécutez la commande d'installation avec le package pour développeur unixODBC.
sudo apt-get update sudo apt-get install mssql-tools18 unixodbc-devNotes
Pour effectuer la mise à jour vers la version de mssql-tools la plus récente, exécutez les commandes suivantes :
sudo apt-get update sudo apt-get install mssql-tools18Facultatif : Ajoutez
/opt/mssql-tools18/bin/à votre variable d'environnementPATHdans un interpréteur de commandes Bash.Pour rendre sqlcmd et bcp accessibles depuis l’interpréteur de commandes Bash pour les sessions de connexion, modifiez votre
PATHdans le fichier~/.bash_profileà l’aide de la commande suivante :echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bash_profilePour rendre sqlcmd et bcp accessibles depuis l’interpréteur de commandes Bash pour les sessions interactives/sans connexion, modifiez le
PATHdans le fichier~/.bashrcà l’aide de la commande suivante :echo 'export PATH="$PATH:/opt/mssql-tools18/bin"' >> ~/.bashrc source ~/.bashrc
Installer l’agent à haute disponibilité de SQL Server
Exécutez la commande suivante sur tous les nœuds pour installer le package d’agent à haute disponibilité pour SQL Server :
sudo apt-get install mssql-server-ha
Configurer un groupe de disponibilité
Effectuez les étapes suivantes pour configurer un groupe de disponibilité AlwaysOn SQL Server sur vos machines virtuelles. Pour plus d'informations, consultez Configurer des groupes de disponibilité Always On SQL Server pour la haute disponibilité sur Linux.
Activer les groupes de disponibilité et redémarrer SQL Server
Activez les groupes de disponibilité sur chaque nœud qui héberge une instance SQL. Ensuite, redémarrez le service mssql-server. Exécutez les commandes suivantes sur chaque nœud :
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
Créer un certificat
Microsoft ne prend pas en charge l’authentification Active Directory sur le point de terminaison du groupe de disponibilité. Par conséquent, nous devons utiliser un certificat pour le chiffrement du point de terminaison du groupe de disponibilité.
Connectez-vous à tous les nœuds à l’aide de SQL Server Management Studio (SSMS) ou de sqlcmd. Exécutez les commandes suivantes pour activer une session AlwaysOn_health et créer une clé principale :
Important
Si vous vous connectez à distance à votre instance SQL Server, le port 1433 doit être ouvert dans votre pare-feu. Vous devez également autoriser les connexions entrantes sur le port 1433 de votre groupe de sécurité réseau pour chaque machine virtuelle. Pour plus d’informations sur la création d’une règle de sécurité de trafic entrant, consultez Créer une règle de sécurité.
- Remplacez
<MasterKeyPassword>par votre propre mot de passe.
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE = ON); GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<MasterKeyPassword>'; GO- Remplacez
Connectez-vous au réplica principal à l’aide de SSMS ou de sqlcmd. Les commandes ci-dessous créent un certificat dans
/var/opt/mssql/data/dbm_certificate.ceret une clé privée dansvar/opt/mssql/data/dbm_certificate.pvksur votre réplica de SQL Server principal :- Remplacez
<PrivateKeyPassword>par votre propre mot de passe.
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; GO BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO- Remplacez
Quittez la session sqlcmd en exécutant la commande exit, puis revenez à votre session SSH.
Copier le certificat sur les réplicas secondaires et créer les certificats sur le serveur
Copiez les deux fichiers qui ont été créés au même emplacement sur tous les serveurs qui hébergeront les réplicas de disponibilité.
Sur le serveur principal, exécutez la commande
scpsuivante pour copier le certificat sur les serveurs cibles :- Remplacez
<username>etsles2par le nom d’utilisateur et le nom de la machine virtuelle cible que vous utilisez. - Exécutez cette commande pour tous les réplicas secondaires.
Notes
Vous n’êtes pas obligé d’exécuter
sudo -i, qui vous indique l’environnement racine. Vous pouvez exécuter la commandesudodevant chaque commande à la place.# The below command allows you to run commands in the root environment sudo -iscp /var/opt/mssql/data/dbm_certificate.* <username>@sles2:/home/<username>- Remplacez
Sur le serveur cible, exécutez la commande suivante :
- Remplacez
<username>par votre ID d’utilisateur. - La commande
mvpermet de déplacer les fichiers ou le répertoire. - La commande
chownest utilisée pour modifier le propriétaire ainsi que le groupe de fichiers, de répertoires ou de liens. - Exécutez ces commandes pour tous les réplicas secondaires.
sudo -i mv /home/<username>/dbm_certificate.* /var/opt/mssql/data/ cd /var/opt/mssql/data chown mssql:mssql dbm_certificate.*- Remplacez
Le script Transact-SQL suivant crée un certificat à partir de la sauvegarde que vous avez créée sur le réplica SQL Server principal. Mettez à jour le script avec des mots de passe forts. Le mot de passe de déchiffrement est le même que celui que vous avez utilisé pour créer le fichier .pvk à l’étape précédente. Pour créer le certificat, exécutez le script suivant à l’aide de sqlcmd ou de SSMS sur tous les serveurs secondaires :
CREATE CERTIFICATE dbm_certificate FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<PrivateKeyPassword>' ); GO
Créer les points de terminaison de mise en miroir de bases de données sur tous les réplicas
Exécutez le script suivant sur toutes les instances SQL à l’aide de sqlcmd ou de SSMS :
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
GO
Créez le groupe de disponibilité
Connectez-vous à l’instance SQL qui héberge le réplica principal à l’aide de sqlcmd ou de SSMS. Exécutez la commande suivante pour créer le groupe de disponibilité :
- Remplacez
ag1par le nom désiré pour votre groupe de disponibilité. - Remplacez les valeurs
ubuntu1,ubuntu2etubuntu3par les noms des instances SQL Server qui hébergent les réplicas.
CREATE AVAILABILITY
GROUP [ag1]
WITH (
DB_FAILOVER = ON,
CLUSTER_TYPE = EXTERNAL
)
FOR REPLICA
ON N'ubuntu1'
WITH (
ENDPOINT_URL = N'tcp://ubuntu1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'ubuntu2'
WITH (
ENDPOINT_URL = N'tcp://ubuntu2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'ubuntu3'
WITH (
ENDPOINT_URL = N'tcp://ubuntu3:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
);
GO
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
GO
Créer une connexion SQL Server pour Pacemaker
Sur toutes les instances SQL Server, créez un compte de connexion SQL Server pour Pacemaker. Le code Transact-SQL ci-dessous a pour effet de créer un compte de connexion.
- Remplacez
<password>par votre propre mot de passe complexe.
USE [master]
GO
CREATE LOGIN [pacemakerLogin]
WITH PASSWORD = N'<password>';
GO
ALTER SERVER ROLE [sysadmin]
ADD MEMBER [pacemakerLogin];
GO
Sur toutes les instances SQL Server, enregistrez les informations d’identification utilisées pour le compte de connexion SQL Server.
Créez le fichier :
sudo vi /var/opt/mssql/secrets/passwdAjoutez les deux lignes suivantes au fichier :
pacemakerLogin <password>Pour quitter l’éditeur vi, appuyez d’abord sur la touche Echap, puis entrez la commande
:wqpour écrire le fichier et quitter.Rendez le fichier lisible uniquement par la racine :
sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 400 /var/opt/mssql/secrets/passwd
Joindre les réplicas secondaires au groupe de disponibilité
Sur vos réplicas secondaires, exécutez les commandes suivantes pour les joindre au groupe de disponibilité :
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOExécutez le script Transact-SQL suivant sur le réplica principal et sur chaque réplica secondaire :
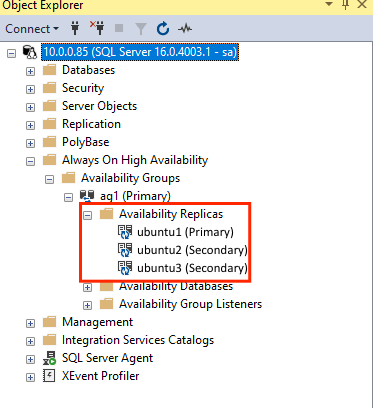
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemakerLogin; GO GRANT VIEW SERVER STATE TO pacemakerLogin; GOUne fois les réplicas secondaires joints, vous pouvez les afficher dans l’Explorateur d’objets de SSMS en développant le nœud Haute disponibilité Always On :
Ajouter une base de données au groupe de disponibilité
Cette section suit l’article relatif à l’ajout d’une base de données à un groupe de disponibilité.
Les commandes Transact-SQL suivantes sont utilisées dans cette étape. Exécutez les commandes suivantes sur le réplica principal :
CREATE DATABASE [db1]; -- creates a database named db1
GO
ALTER DATABASE [db1] SET RECOVERY FULL; -- set the database in full recovery mode
GO
BACKUP DATABASE [db1] -- backs up the database to disk
TO DISK = N'/var/opt/mssql/data/db1.bak';
GO
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1]; -- adds the database db1 to the AG
GO
Vérifier que la base de données est créée sur les serveurs secondaires
Sur chaque réplica SQL Server secondaire, exécutez la requête suivante pour déterminer si la base de données db1 a été créée et si son état indique « SYNCHRONIZED » :
SELECT * FROM sys.databases
WHERE name = 'db1';
GO
SELECT DB_NAME(database_id) AS 'database',
synchronization_state_desc
FROM sys.dm_hadr_database_replica_states;
GO
Si synchronization_state_desc indique SYNCHRONIZED pour db1, cela signifie que les réplicas sont synchronisés. Les réplicas secondaires indiquent db1 dans le réplica principal.
Créer les ressources de groupe de disponibilité dans le cluster Pacemaker
Pour créer la ressource du groupe de disponibilité dans Pacemaker, exécutez les commandes suivantes :
sudo crm
configure
primitive ag1_cluster \
ocf:mssql:ag \
params ag_name="ag1" \
meta failure-timeout=60s \
op start timeout=60s \
op stop timeout=60s \
op promote timeout=60s \
op demote timeout=10s \
op monitor timeout=60s interval=10s \
op monitor timeout=60s on-fail=demote interval=11s role="Master" \
op monitor timeout=60s interval=12s role="Slave" \
op notify timeout=60s
ms ms-ag1 ag1_cluster \
meta master-max="1" master-node-max="1" clone-max="3" \
clone-node-max="1" notify="true"
commit
cette commande ci-dessus crée la ressource ag1_cluster, autrement dit la ressource du groupe de disponibilité. elle crée ensuite la ressource ms-ag1 (ressource primaire/secondaire dans Pacemaker), puis y ajoute la ressource du groupe de disponibilité. Ainsi, la ressource du groupe de disponibilité fonctionne sur les trois nœuds du cluster, mais seul l'un d'entre eux est primaire.
Pour afficher la ressource du groupe de disponibilité et vérifier le statut du cluster :
sudo crm resource status ms-ag1
sudo crm status
La sortie doit ressembler à celle-ci :
resource ms-ag1 is running on: ubuntu1 Master
resource ms-ag1 is running on: ubuntu3
resource ms-ag1 is running on: ubuntu2
Le résultat ressemble à l’exemple qui suit. Pour ajouter des contraintes de colocation et de promotion, reportez-vous à Tutoriel : Configurer un écouteur de groupe de disponibilité sur les machines virtuelles Linux.
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 4 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* Clone Set: ms-ag1 [ag1_cluster] (promotable):
* Masters: [ ubuntu1 ]
* Slaves : [ ubuntu2 ubuntu3 ]
* fence-vm (stonith:fence_azure_arm): Started ubuntu1
Exécutez la commande suivante pour créer une ressource de groupe, de sorte que les contraintes de colocation et de promotion appliquées à l'écouteur et à l'équilibreur de charge ne soient pas appliquées individuellement.
sudo crm configure group virtualip-group azure-load-balancer virtualip
La sortie de crm status ressemblera à l'exemple suivant :
Cluster Summary:
* Stack: corosync
* Current DC: ubuntu1 (version 2.0.3-4b1f869f0f) - partition with quorum
* Last updated: Wed Nov 29 07:01:32 2023
* Last change: Sun Nov 26 17:00:26 2023 by root via cibadmin on ubuntu1
* 3 nodes configured
* 6 resource instances configured
Node List:
* Online: [ ubuntu1 ubuntu2 ubuntu3 ]
Full List of Resources:
* Clone Set: ms-ag1 [ag1_cluster] (promotable):
* Masters: [ ubuntu1 ]
* Slaves : [ ubuntu2 ubuntu3 ]
* Resource Group: virtual ip-group:
* azure-load-balancer (ocf :: heartbeat:azure-lb): Started ubuntu1
* virtualip (ocf :: heartbeat: IPaddr2): Started ubuntu1
* fence-vm (stonith:fence_azure_arm): Started ubuntu1