Applications de données (alignées à la source)
Si vous choisissez de ne pas implémenter un moteur indépendant des données pour ingérer en une seule fois des données issues de sources opérationnelles, ou si les connexions complexes ne sont pas prises en charge dans votre moteur indépendant des données, créez une application de données alignée sur la source. Elle doit suivre le même flux qu’un moteur indépendant des données qui ingère des données à partir de sources de données externes.
Vue d’ensemble
Votre groupe de ressources d’application est responsable de l’ingestion et de l’enrichissement de données issues de sources externes uniquement (télémétrie, finances, CRM, etc.). Cette couche peut fonctionner à la fois en temps réel, par lots et par micro-lots.
Cette section décrit l’infrastructure déployée pour chacun des groupes de ressources d’application de données (alignée sur la source) de la zone d’atterrissage des données.
Conseil
En ce qui concerne le maillage de données, vous pouvez choisir d’en déployer un par source ou un par domaine. Les principes de normalisation, de qualité et de traçabilité des données doivent quand même être suivis. Les équipes chargées des opérations des plateformes de données peuvent pour cela développer des extraits de code standard et y faire appel.
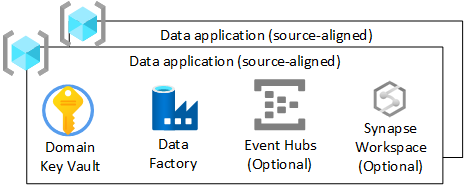
Pour chacun des groupes de ressources d’application de données (alignée sur la source) de votre zone d’atterrissage des données, créez les éléments suivants :
- Un coffre Azure Key Vault
- Une instance Azure Data Factory permettant d’exécuter les pipelines d’ingénierie développés qui transforment les données de l’état brut à l’état enrichi
- Un principal de service utilisé par l’application de données (alignée sur la source) pour déployer des travaux d’ingestion sur Azure Databricks (uniquement en cas de recours à Azure Databricks)
Vous pouvez également créer des instances d’autres services, notamment Azure Event Hubs, Azure IoT Hub, Azure Stream Analytics et Azure Machine Learning.
Notes
Vous devez utiliser un moteur Spark comme Azure Synapse Spark ou Azure Databricks pour appliquer la norme Delta Lake.
Si vous décidez d’utiliser Azure Databricks, nous vous recommandons de déployer Azure Data Factory plutôt qu’un espace de travail Azure Synapse Analytics pour réduire la surface d’exposition aux seules fonctionnalités nécessaires.
Si toutefois vous avez besoin d’une zone de développement globale avec des pipelines et Spark, utilisez Azure Synapse Analytics. Appliquez une stratégie permettant d’autoriser uniquement le recours à Spark et à des pipelines afin d’éviter de créer des silos dans un pool Azure Synapse SQL.
Azure Key Vault
Utilisez la fonctionnalité Azure Key Vault pour stocker les secrets dans Azure chaque fois que cela est possible.
Chaque groupe de ressources d’application de données (alignée sur la source) ou domaine de données (si maillage) dispose d’un coffre Azure Key Vault. Cela permet de garantir que la dérivation de clé de chiffrement, de secret et de certificat répond aux exigences de l’environnement. En résulte également une meilleure séparation des tâches administratives et une réduction du risque de mélange de clés, d’intégrations et de secrets de classifications différentes.
Toutes les clés relatives à votre application de données (alignée sur la source) doivent être contenues dans votre coffre Azure Key Vault.
Important
Les coffres de clés d’application de données (alignée sur la source) doivent suivre le modèle des privilèges minimum, et éviter les limites de mise à l’échelle des transactions et le partage de secrets entre les environnements.
Azure Data Factory
Déployez une instance Azure Data Factory pour permettre aux pipelines écrits par votre équipe responsable de l’application de données de faire passer les données de l’état brut à l’état enrichi à l’aide de pipelines développés. Utilisez des flux de données de mappage pour les transformations et répartissez-les entre l’espace de travail Azure Databricks (ingestion) et Azure Synapse Spark pour les transformations complexes.
Connectez Azure Data Factory à l’instance DevOps de votre référentiel d’applications de données (alignées sur la source) pour permettre les déploiements CI/CD.
Event Hubs
Si votre application de données (alignée sur la source) a besoin de diffuser des données en continu, vous pouvez déployer Event Hubs en aval dans votre groupe de ressources d’application de données (alignée sur la source).