Opérationnaliser le maillage de données pour l’ingénierie de caractéristiques IA/ML basée sur le domaine
Le maillage de données aide les organisations à passer d’un lac de données ou entrepôt de données centralisé à une décentralisation des données d’analytique basée sur le domaine, soulignée par quatre principes : Propriété du domaine, Données en tant que produit, Plateforme de données libre-service et Gouvernance informatique fédérée. Le maillage de données offre comme avantages une propriété des données distribuées et une amélioration de la qualité et de la gouvernance des données qui accélère l’activité et réduit le temps de valorisation pour les organisations.
Implémentation du maillage de données
Une implémentation de maillage de données classique inclut des équipes de domaine avec des ingénieurs Données qui créent des pipelines de données. L’équipe gère des magasins de données opérationnelles et analytiques, tels que des lacs de données, un entrepôt de données ou un data lakehouse. Elle publie les pipelines en tant que produits de données consommables par d’autres équipes de domaine ou équipes de science des données. D’autres équipes consomment les produits de données à l’aide d’une plateforme de gouvernance des données centrale, comme illustré dans le diagramme suivant.
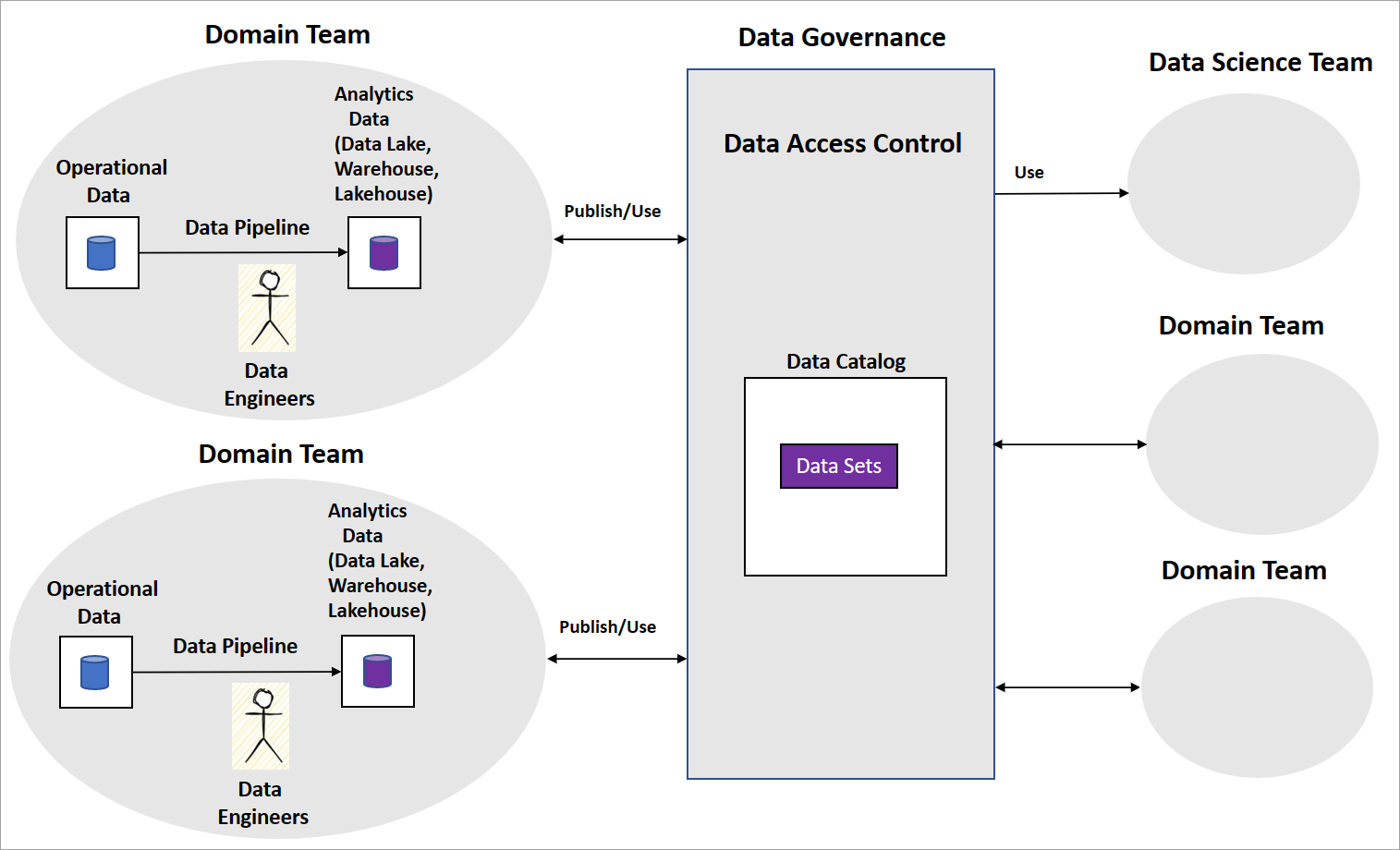
Le maillage de données est clair quant à la manière dont les produits de données servent les jeux de données transformés et agrégés pour l’aide à la décision, mais il n’est pas explicite concernant l’approche que les organisations doivent adopter pour créer des modèles IA/ML. Il n’existe pas non plus d’instructions expliquant comment structurer les équipes de science des données ou la gouvernance des modèles IA/ML, et comment partager des caractéristiques ou des modèles IA/ML entre les équipes de domaine.
La section suivante décrit quelques stratégies que les organisations peuvent adopter pour développer des caractéristiques IA/ML dans le maillage de données. Et vous verrez une proposition pour une stratégie d’ingénierie de caractéristiques ou de maillage de caractéristiques basée sur le domaine.
Stratégies IA/ML pour le maillage de données
Une stratégie courante consiste, pour l’organisation, à adopter des équipes de science des données en tant que consommateurs de données. Ces équipes accèdent à différents produits de données de domaine dans le maillage de données en fonction du cas d’usage. Elles effectuent l’exploration des données et l’ingénierie de caractéristiques pour développer et créer des modèles IA/ML. Dans certains cas, les équipes de domaine développent également leurs propres modèles IA/ML en utilisant leurs données et le produit de données d’autres équipes afin d’étendre et de dériver de nouvelles caractéristiques.
L’ingénierie de caractéristiques est au cœur de la génération de modèle ; elle est généralement complexe et nécessite une expertise dans le domaine. La stratégie ci-dessus peut être chronophage, car les équipes de science des données doivent ensuite analyser différents produits de données. Il se peut qu’elles ne disposent pas d’une connaissance complète du domaine pour créer des caractéristiques de haute qualité. Le manque de connaissances du domaine peut entraîner la duplication des efforts d’ingénierie de caractéristiques entre les équipes de domaine, ainsi que des problèmes tels que la reproductibilité de modèle IA/ML dus à l’incohérence des ensembles de caractéristiques entre les équipes. Les équipes de science des données ou de domaine doivent actualiser en permanence les caractéristiques à mesure que de nouvelles versions des produits de données sont publiées.
Une autre stratégie consiste, pour les équipes de domaine, à publier des modèles IA/ML dans un format tel qu’ONNX (Open Neural Network Exchange), mais ces résultats sont des boîtes noires et la combinaison de modèles IA/ML ou de caractéristiques entre les domaines serait difficile.
Existe-t-il un moyen de décentraliser la création de modèles IA/ML entre les équipes de domaine et de science des données pour relever les défis ? La stratégie d’ingénierie de caractéristiques ou de maillage de caractéristiques basé(e) sur le domaine proposée est une option.
Ingénierie de caractéristiques ou maillage de caractéristiques basé(e) sur le domaine
La stratégie d’ingénierie de caractéristiques ou de maillage de caractéristiques basé(e) sur le domaine offre une approche décentralisée de la création de modèles IA/ML dans un contexte de maillage de données. Le diagramme suivant montre la stratégie et la façon dont elle répond aux quatre principes majeurs du maillage de données.
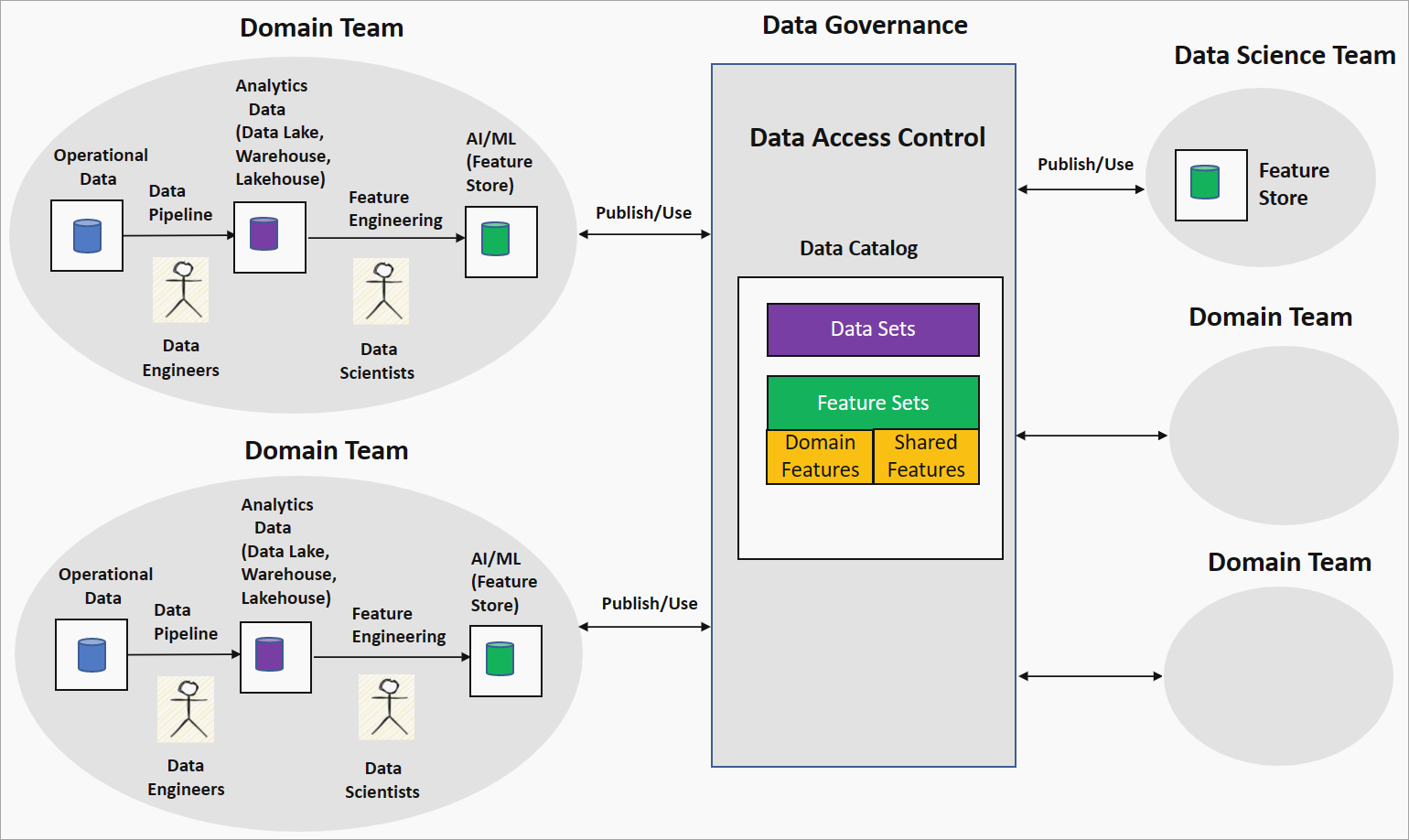
Ingénierie de caractéristiques de propriété de domaine par les équipes de domaine
Avec cette stratégie, l’organisation associe des scientifiques des données à des ingénieurs Données d’une équipe de domaine pour exécuter l’exploration des données sur des données propres et transformées, par exemple un lac de données. L’ingénierie génère des caractéristiques qui sont stockées dans un magasin de caractéristiques. Le magasin de caractéristiques est un référentiel de données qui fournit des caractéristiques pour l’entraînement et l’inférence, et permet de suivre la version des caractéristiques, les métadonnées et les statistiques. Cette fonctionnalité permet aux scientifiques des données de l’équipe de domaine de travailler en étroite collaboration avec des experts du domaine, et de maintenir les caractéristiques actualisées à mesure que les données changent dans le domaine.
Données en tant que produit : ensembles de caractéristiques
Les caractéristiques générées par l’équipe de domaine, appelées caractéristiques de domaine ou locales, sont publiées dans le catalogue de données de la plateforme de gouvernance des données en tant qu’ensembles de caractéristiques. Ces ensembles de caractéristiques peuvent être consommés par les équipes de science des données ou d’autres équipes de domaine pour créer des modèles IA/ML. Pendant le développement de modèles IA/ML, les équipes de science des données ou de domaine peuvent combiner des caractéristiques de domaine pour produire de nouvelles caractéristiques, appelées caractéristiques partagées ou globales. Ces caractéristiques partagées sont republiées dans le catalogue d’ensembles de caractéristiques en vue de leur consommation.
Plateforme de données libre-service et Gouvernance informatique fédérée : normalisation et qualité des caractéristiques
Cette stratégie peut conduire à l’adoption d’une pile technologique différente pour les pipelines d’ingénierie de caractéristiques et à des définitions de caractéristiques incohérentes entre les équipes de domaine. Les principes de plateforme de données libre-service garantissent que les équipes de domaine utilisent une infrastructure et des outils communs pour créer les pipelines d’ingénierie de caractéristiques, et qu’elles appliquent le contrôle d’accès. Le principe de gouvernance informatique fédérée garantit l’interopérabilité des ensembles de caractéristiques par le biais d’une normalisation globale et de vérifications de la qualité des caractéristiques.
L’adoption d’une stratégie d’ingénierie de caractéristiques ou de maillage de caractéristiques basé(e) sur le domaine offre une approche décentralisée de la création de modèles IA/ML pour les organisations afin de réduire la durée de développement des modèles IA/ML. Cette stratégie permet de maintenir la cohérence des caractéristiques entre les équipes de domaine. Elle évite la duplication des efforts et aboutit à des caractéristiques de haute qualité pour des modèles IA/ML plus précis, ce qui accroît la valeur pour l’entreprise.
Implémentation du maillage de données dans Azure
Cet article décrit les concepts relatifs à l’opérationnalisation de l’IA/ML dans un maillage de données, et ne couvre pas les outils ou les architectures permettant de créer ces stratégies. Azure propose des offres de magasin de caractéristiques telles qu’Azure Databricks et Feathr de LinkedIn. Vous pouvez développer des connecteurs personnalisés Microsoft Purview pour gérer et gouverner les magasins de caractéristiques.