Moteur d'ingestion agnostique de données
Cet article explique comment implémenter des scénarios de moteur d'ingestion agnostique de données en utilisant une combinaison de PowerApps, d'Azure Logic Apps et de tâches de copie pilotées par les métadonnées dans Azure Data Factory.
Les scénarios impliquant un moteur d’ingestion agnostique de données visent généralement à permettre aux utilisateurs non techniques (non ingénieurs de données) de publier des ressources de données dans un lac de données en vue d’un traitement ultérieur. Pour implémenter ce scénario, vous devez disposer de capacités d'intégration permettant les opérations suivantes :
- Inscription des ressources de données
- Approvisionnement du workflow et capture des métadonnées
- Planification de l'ingestion
Vous pouvez voir comment ces capacités interagissent :
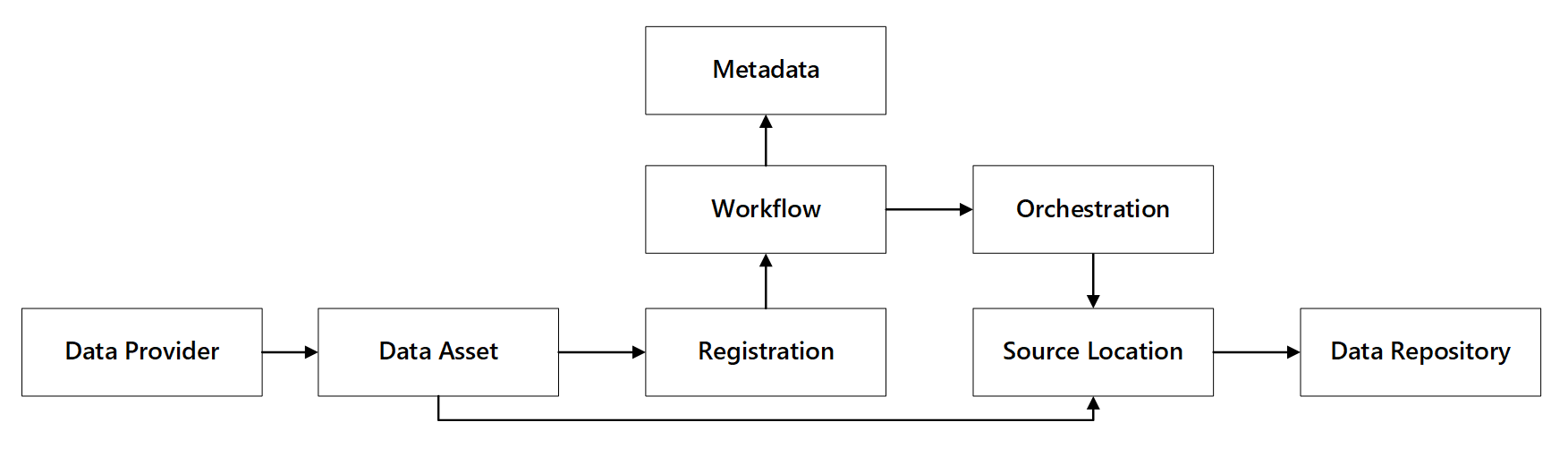
Figure 1 : Interactions des capacités d'inscription des données.
Le schéma suivant montre comment implémenter ce processus en utilisant une combinaison de services Azure :
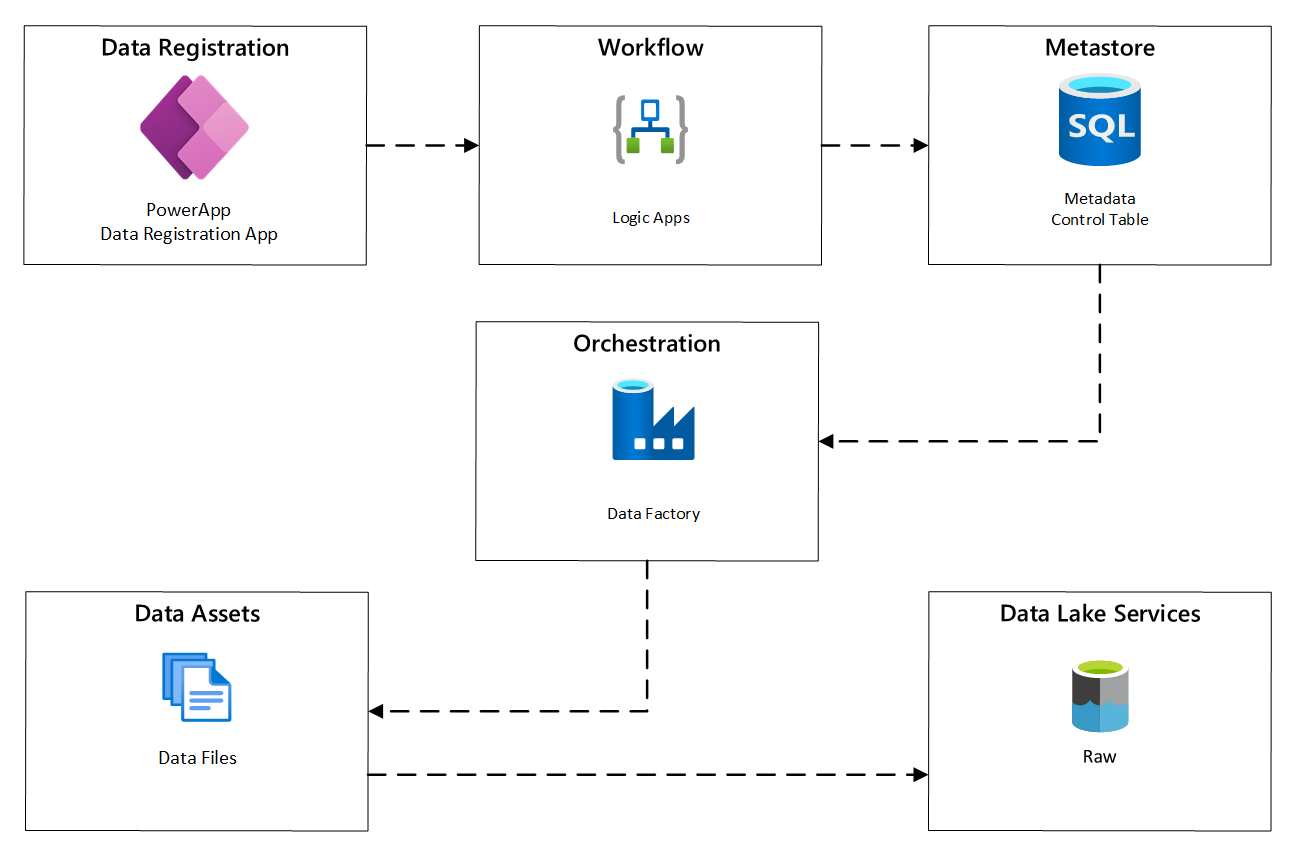
Figure 2 : Processus d’ingestion automatisée.
Inscription des ressources de données
Afin de fournir les métadonnées utilisées pour piloter l’ingestion automatisée, vous devez inscrire les ressources de données. Les informations que vous capturez incluent :
- Informations techniques : nom de la ressource de données, système source, type, format et fréquence.
- Informations de gouvernance : propriétaire, administrateurs, visibilité (pour la découverte) et sensibilité.
PowerApps sert à capturer les métadonnées décrivant chaque ressource de données. Utilisez une application pilotée par un modèle pour saisir les informations conservées dans une table Dataverse personnalisée. Lorsque des métadonnées sont créées ou mises à jour dans Dataverse, elles déclenchent un flux de cloud automatisé qui appelle d'autres étapes de traitement.
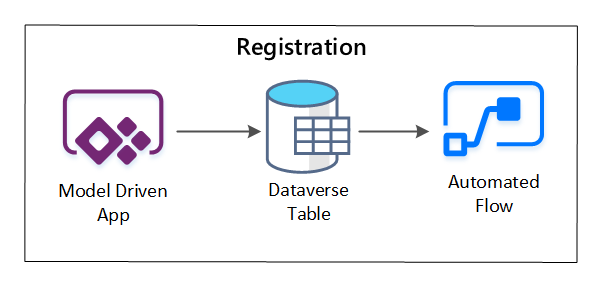
Figure 3 : Inscription des ressources de données.
Workflow d’approvisionnement / capture des métadonnées
Dans l'étape du workflow d’approvisionnement, vous validez et conservez dans le metastore les données collectées lors de l'étape d'inscription. Des étapes de validation technique et commerciale sont effectuées, notamment :
- Validation de flux de données d'entrée
- Déclenchement du workflow d'approbation
- Traitement logique pour déclencher la conservation des métadonnées dans le magasin de métadonnées
- Audit d'activité
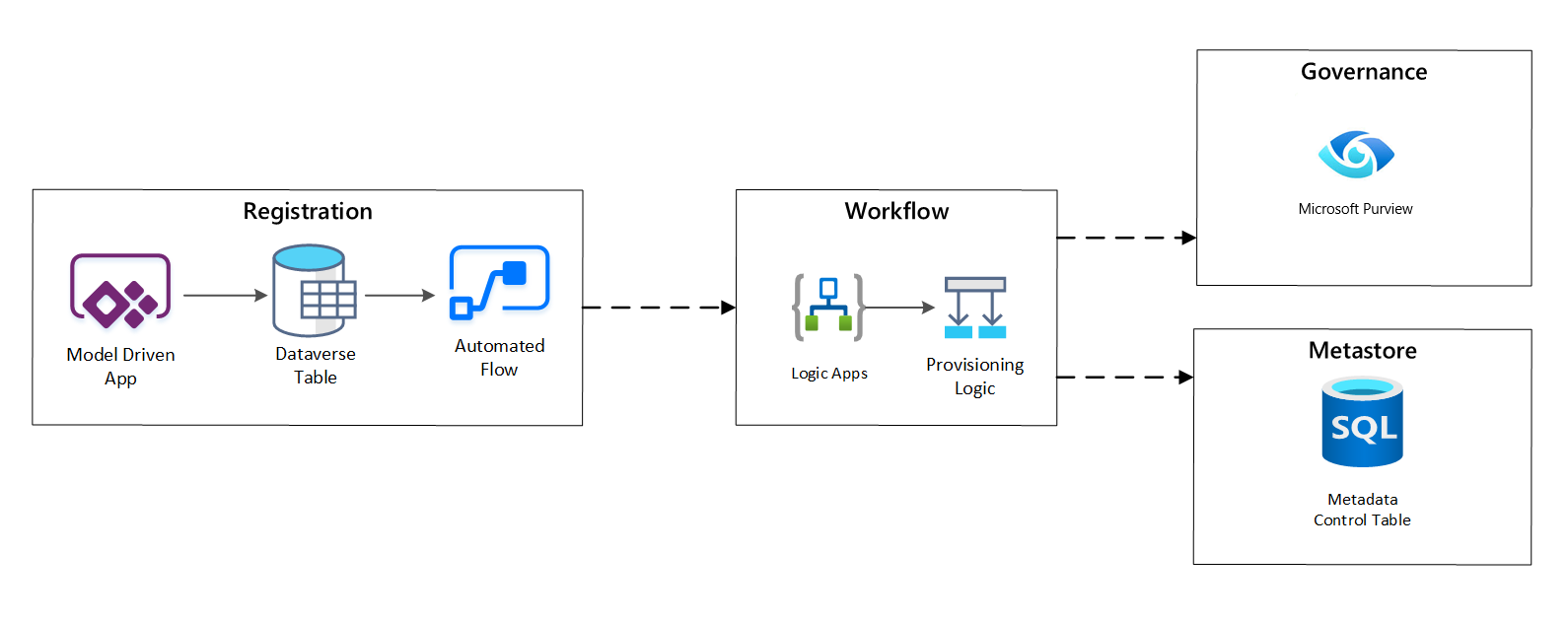
Figure 4 : Workflow d’inscription.
Une fois les demandes d’ingestion approuvées, le workflow utilise l’API REST Azure Purview pour insérer les sources dans Azure Purview.
Workflow détaillé pour l’intégration des produits de données
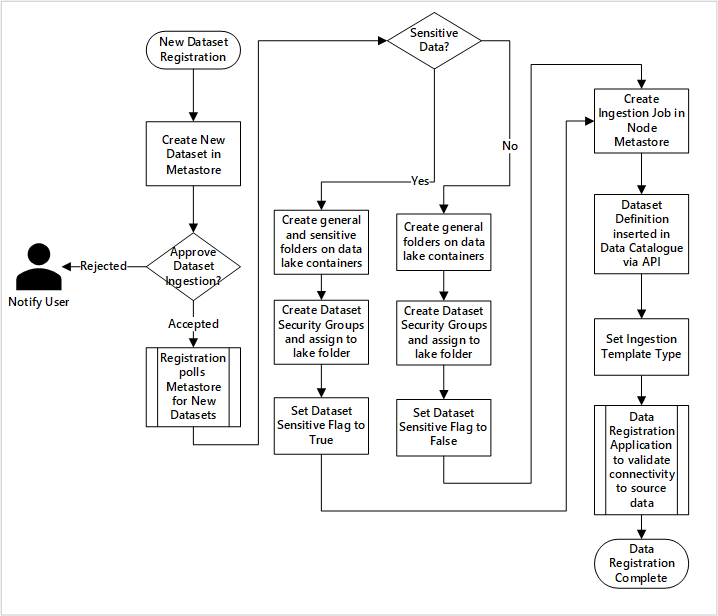
Figure 5 : Comment les nouveaux jeux de données sont ingérés (automatisé).
La figure 5 montre le processus d’inscription détaillé pour l’automatisation de l’ingestion de nouvelles sources de données :
- Les détails de la source sont inscrits, y compris les environnements de production et Data Factory.
- Les contraintes de forme, de format et de qualité des données sont capturées.
- Les équipes d’application de données doivent indiquer si les données sont sensibles (données personnelles). Cette classification oriente le processus au cours duquel les dossiers du lac de données sont créés pour ingérer des données brutes, enrichies et organisées. La source nomme les données brutes et enrichies et produit de données nomme les données organisées.
- Le principal de service et les groupes de sécurité sont créés pour l’ingestion et l’octroi de l’accès à un jeu de données.
- Un travail d’ingestion est créé dans le metastore Data Factory de la zone d’atterrissage des données.
- Une API insère la définition de données dans Azure Purview.
- Sous réserve de la validation de la source de données et de l’approbation par l’équipe des opérations, les détails sont publiés dans un metastore Data Factory.
Planification de l'ingestion
Dans Azure Data Factory, les tâches de copie basées sur les métadonnées fournissent une fonctionnalité qui permet aux pipelines d'orchestration d'être pilotés par les lignes d'une table de contrôle stockée dans Azure SQL Database. Vous pouvez utiliser l'outil Copier des données pour précréer des pipelines basés sur les métadonnées.
Une fois qu'un pipeline a été créé, votre workflow d’approvisionnement ajoute des entrées à la table de contrôle pour prendre en charge l'ingestion à partir des sources identifiées par les métadonnées d'inscription des ressources de données. Les pipelines Azure Data Factory et la base de données Azure SQL contenant votre metastore de table de contrôle peuvent tous deux exister dans chaque zone d'atterrissage de données pour créer de nouvelles sources de données et les ingérer dans les zones d'atterrissage de données.
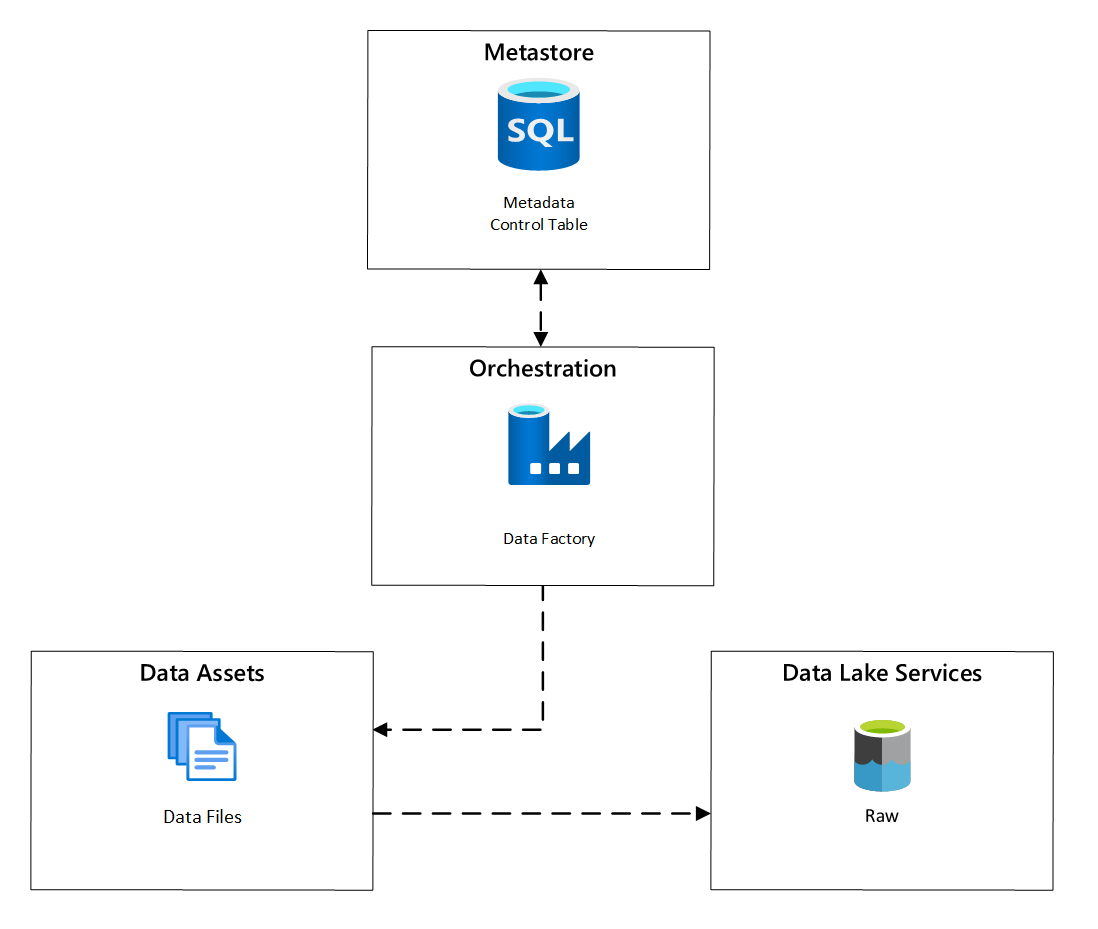
Figure 6 : Planification de l'ingestion des ressources de données.
Workflow détaillé pour l'ingestion de nouvelles sources de données
Le diagramme suivant montre comment extraire des sources de données enregistrées dans un metastore Data Factory SQL Database et comment les données sont ingérées en premier :
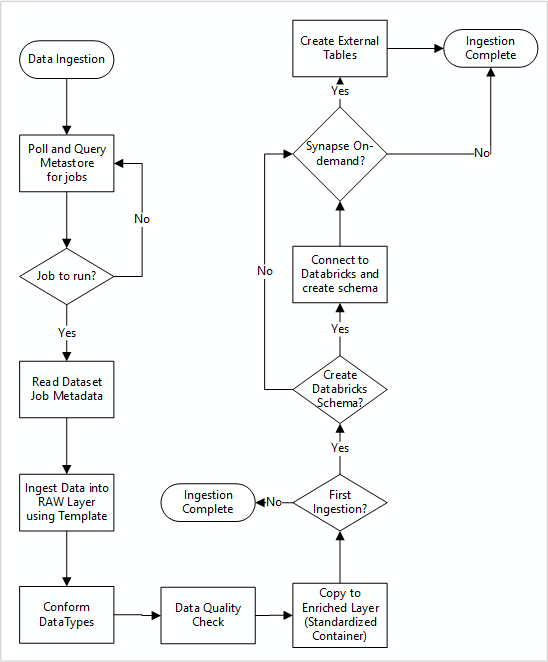
Votre pipeline d’ingestion maître Data Factory lit les configurations à partir d’un metastore Data Factory SQL Database, puis s’exécute de façon itérative avec les paramètres corrects. Les données se déplacent sans ou avec peu de modifications de la source à la couche brute dans Azure Data Lake. La forme des données est validée en fonction de votre metastore Data Factory. Les formats de fichiers sont convertis aux formats Apache Parquet ou Avro, puis copiés dans la couche enrichie.
Les données ingérées se connectent à un espace de travail d’ingénierie et de science des données Azure Databricks, et une définition de données est créée dans le metastore Apache Hive de la zone d’atterrissage des données.
Si vous devez utiliser un pool SQL serverless Azure Synapse pour exposer des données, votre solution personnalisée doit créer des vues sur les données du lac.
Si vous avez besoin d'un chiffrement au niveau des lignes ou des colonnes, votre solution personnalisée doit faire atterrir les données dans votre lac de données, puis les ingérer directement dans les tables internes des pools SQL et mettre en place la sécurité appropriée sur le calcul des pools SQL.
Métadonnées capturées
Lorsque vous utilisez l'ingestion de données automatisée, vous pouvez interroger les métadonnées associées et créer des tableaux de bord pour :
- Suivre les travaux et les timestamps de chargement des données les plus récents pour les produits de données associés à leurs fonctions.
- Suivre les produits de données disponibles.
- Augmenter les volumes de données.
- Obtenir des mises à jour en temps réel sur les échecs des travaux.
Les métadonnées opérationnelles peuvent être utilisées pour effectuer le suivi des éléments suivants :
- Travaux, étapes des travaux et leurs dépendances.
- Performances des travaux et historique des performances.
- Croissance du volume des données.
- Échecs des travaux.
- Modifications des métadonnées sources.
- Fonctions professionnelles qui dépendent de produits de données.
Utiliser l’API REST Azure Purview pour découvrir des données
Les API REST d'Azure Purview doivent être utilisées pour enregistrer les données lors de l'ingestion initiale. Vous pouvez utiliser les API pour soumettre des données à votre catalogue de données peu après leur ingestion.
Pour plus d'informations, découvrez comment utiliser les API REST d'Azure Purview.
Inscription des sources de données
Utilisez l’appel d’API suivant pour inscrire de nouvelles sources de données :
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}
Paramètres d’URI pour la source de données :
| Nom | Requise | Type | Description |
|---|---|---|---|
accountName |
True | String | Nom du compte Azure Purview |
dataSourceName |
True | String | Nom de la source de données |
Utiliser l'API REST Azure Purview pour l'inscription
Les exemples suivants montrent comment utiliser l’API REST Azure Purview pour inscrire des sources de données avec des charges utiles :
Inscrire une source de données Azure Data Lake Storage Gen2 :
{
"kind":"AdlsGen2",
"name":"<source-name> (for example, My-AzureDataLakeStorage)",
"properties":{
"endpoint":"<endpoint> (for example, https://adls-account.dfs.core.windows.net/)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Inscrire une source de données SQL Database :
{
"kind":"<source-kind> (for example, AdlsGen2)",
"name":"<source-name> (for example, My-AzureSQLDatabase)",
"properties":{
"serverEndpoint":"<server-endpoint> (for example, sqlservername.database.windows.net)",
"subscriptionId":"<azure-subscription-guid>",
"resourceGroup":"<resource-group>",
"location":"<region>",
"parentCollection":{
"type":"DataSourceReference",
"referenceName":"<collection-name>"
}
}
}
Remarque
<collection-name> est une collection actuelle qui existe dans un compte Azure Purview.
Créer une analyse
Apprenez à créer des informations d’identification pour authentifier des sources dans Azure Purview avant de configurer et d’exécuter une analyse.
Utilisez l’appel d’API suivant pour analyser les sources de données :
PUT https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/
Paramètres d’URI pour une analyse :
| Nom | Requise | Type | Description |
|---|---|---|---|
accountName |
True | String | Nom du compte Azure Purview |
dataSourceName |
True | String | Nom de la source de données |
newScanName |
True | String | Nom de la nouvelle analyse |
Utiliser l'API REST Azure Purview pour l'analyse
Les exemples suivants montrent comment utiliser l’API REST Azure Purview pour analyser des sources de données avec des charges utiles :
Analyser une source de données Azure Data Lake Storage Gen2 :
{
"name":"<scan-name>",
"kind":"AdlsGen2Msi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AdlsGen2"
}
}
Analyser une source de données SQL Database :
{
"name":"<scan-name>",
"kind":"AzureSqlDatabaseMsi",
"properties":
{
"scanRulesetType":"System",
"scanRulesetName":"AzureSqlDatabase",
"databaseName": "<database-name>",
"serverEndpoint": "<server-endpoint> (for example, sqlservername.database.windows.net)"
}
}
Utiliser l’appel d’API suivant pour analyser les sources de données :
POST https://{accountName}.scan.purview.azure.com/datasources/{dataSourceName}/scans/{newScanName}/run