Résilience des composants Dapr (préversion)
Les stratégies de résilience empêchent, détectent et récupèrent de manière proactive les défaillances de votre application conteneur. Dans cet article, vous allez apprendre à appliquer des stratégies de résilience pour les applications qui utilisent Dapr pour s’intégrer à différents services cloud, tels que les magasins d’état, les répartiteurs de pub/sous-messages, les magasins secrets, etc.
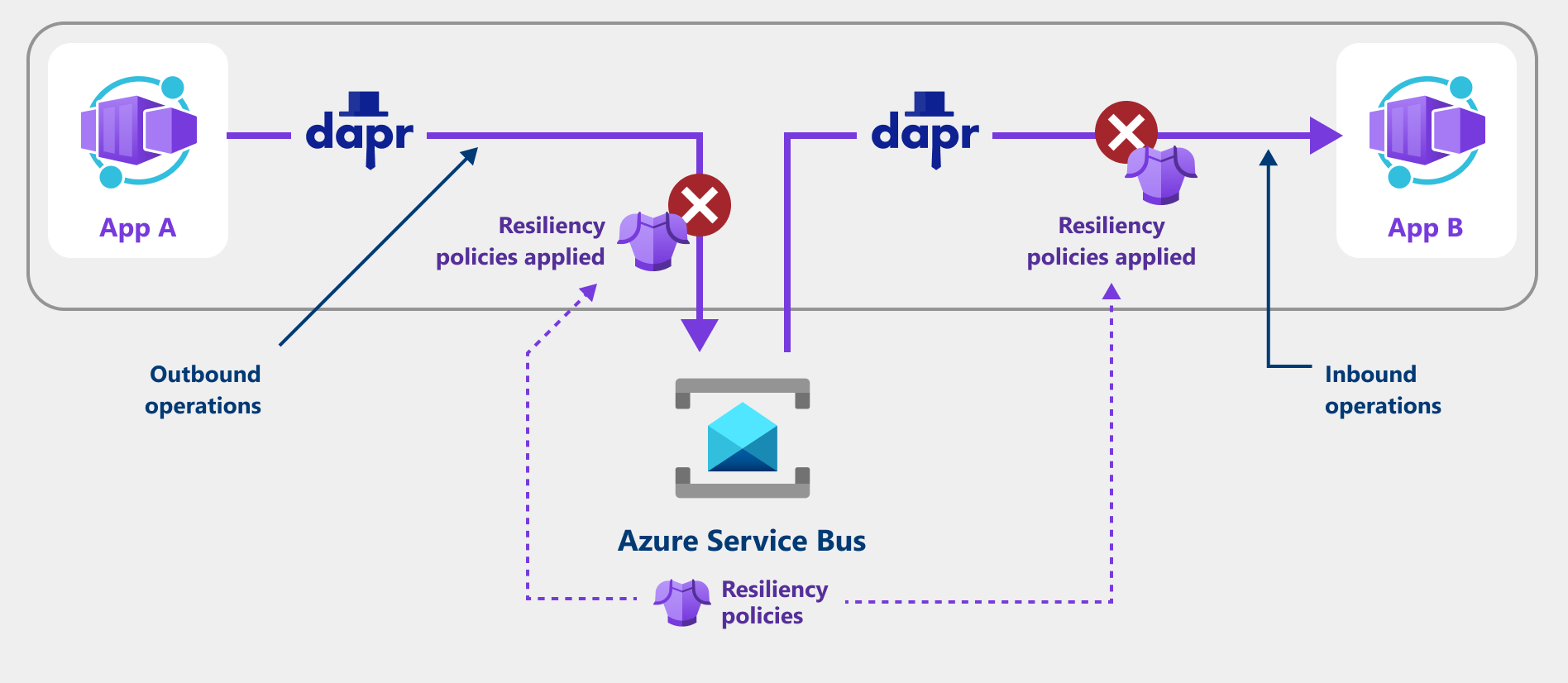
Vous pouvez configurer des stratégies de résilience telles que les nouvelles tentatives, les délais d’expiration et les disjoncteurs pour les instructions d’opération sortantes et entrantes suivantes via un composant Dapr :
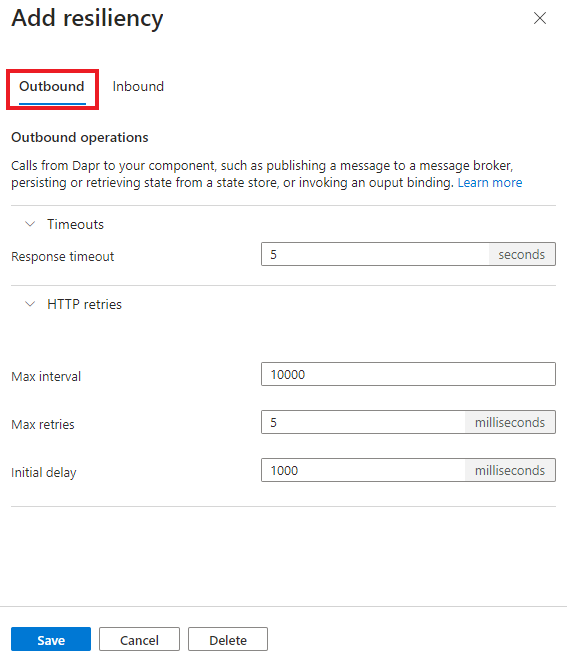
- opérations sortantes : appels du side-car Dapr à un composant, par exemple :
- Persistance ou récupération de l’état
- Publication d’un message
- Appel d’une liaison de sortie
- opérations entrantes : appels depuis le side-car Dapr vers votre application conteneur, par exemple :
- Abonnements lors de la remise d’un message
- Liaisons d’entrée fournissant un événement
La capture d’écran suivante montre comment une application utilise une stratégie de nouvelle tentative pour tenter de récupérer à partir de requêtes ayant échoué.
Stratégies de résilience prises en charge
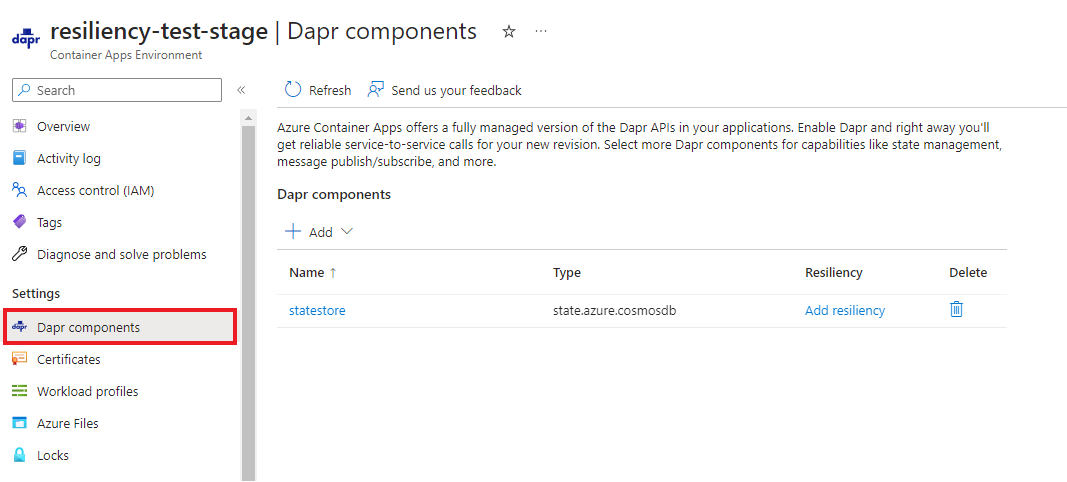
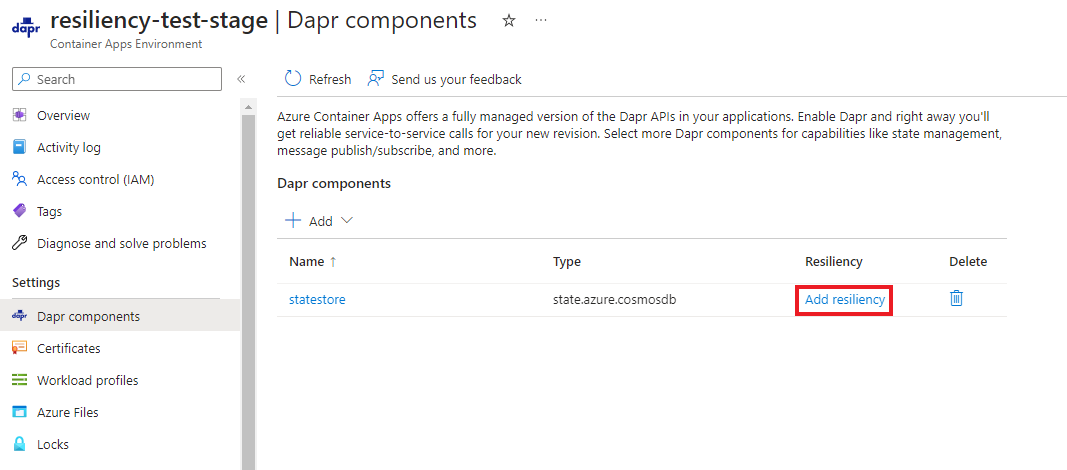
Configurer des stratégies de résilience
Vous pouvez choisir de créer des stratégies de résilience à l’aide de Bicep, de l’interface CLI ou du portail Azure.
L’exemple de résilience suivant illustre toutes les configurations disponibles.
resource myPolicyDoc 'Microsoft.App/managedEnvironments/daprComponents/resiliencyPolicies@2023-11-02-preview' = {
name: 'my-component-resiliency-policies'
parent: '${componentName}'
properties: {
outboundPolicy: {
timeoutPolicy: {
responseTimeoutInSeconds: 15
}
httpRetryPolicy: {
maxRetries: 5
retryBackOff: {
initialDelayInMilliseconds: 1000
maxIntervalInMilliseconds: 10000
}
}
circuitBreakerPolicy: {
intervalInSeconds: 15
consecutiveErrors: 10
timeoutInSeconds: 5
}
}
inboundPolicy: {
timeoutPolicy: {
responseTimeoutInSeconds: 15
}
httpRetryPolicy: {
maxRetries: 5
retryBackOff: {
initialDelayInMilliseconds: 1000
maxIntervalInMilliseconds: 10000
}
}
circuitBreakerPolicy: {
intervalInSeconds: 15
consecutiveErrors: 10
timeoutInSeconds: 5
}
}
}
}
Important
Une fois que vous avez appliqué toutes les stratégies de résilience, vous devez redémarrer vos applications Dapr.
Spécifications de stratégie
Délais d'attente
Les délais d’expiration sont utilisés pour arrêter rapidement les opérations de longue durée. La stratégie de délai d’expiration inclut les propriétés suivantes.
properties: {
outbound: {
timeoutPolicy: {
responseTimeoutInSeconds: 15
}
}
inbound: {
timeoutPolicy: {
responseTimeoutInSeconds: 15
}
}
}
| Métadonnées | Requis | Description | Exemple |
|---|---|---|---|
responseTimeoutInSeconds |
Oui | Délai d’attente d’une réponse du composant Dapr. | 15 |
Nouvelles tentatives
Définissez une stratégie de httpRetryPolicy pour les opérations ayant échoué. La stratégie de nouvelle tentative inclut les configurations suivantes.
properties: {
outbound: {
httpRetryPolicy: {
maxRetries: 5
retryBackOff: {
initialDelayInMilliseconds: 1000
maxIntervalInMilliseconds: 10000
}
}
}
inbound: {
httpRetryPolicy: {
maxRetries: 5
retryBackOff: {
initialDelayInMilliseconds: 1000
maxIntervalInMilliseconds: 10000
}
}
}
}
| Métadonnées | Requis | Description | Exemple |
|---|---|---|---|
maxRetries |
Oui | Nombre maximal de nouvelles tentatives à exécuter pour une requête http ayant échoué. | 5 |
retryBackOff |
Oui | Surveillez les demandes et arrêtez tout le trafic vers le service concerné lorsque les critères de délai d’expiration et de nouvelle tentative sont satisfaits. | N/A |
retryBackOff.initialDelayInMilliseconds |
Oui | Délai entre la première erreur et la première nouvelle tentative. | 1000 |
retryBackOff.maxIntervalInMilliseconds |
Oui | Délai maximal entre les nouvelles tentatives. | 10000 |
Disjoncteurs
Définissez une circuitBreakerPolicy pour surveiller les demandes à l’origine de taux d’échec élevés et arrêter tout le trafic vers le service concerné lorsqu’un certain critère est satisfait.
properties: {
outbound: {
circuitBreakerPolicy: {
intervalInSeconds: 15
consecutiveErrors: 10
timeoutInSeconds: 5
}
},
inbound: {
circuitBreakerPolicy: {
intervalInSeconds: 15
consecutiveErrors: 10
timeoutInSeconds: 5
}
}
}
| Métadonnées | Requis | Description | Exemple |
|---|---|---|---|
intervalInSeconds |
Non | Période cyclique (en secondes) utilisée par le disjoncteur pour effacer son nombre interne. Si elle n’est pas fournie, l’intervalle est défini sur la même valeur que celle fournie pour timeoutInSeconds. |
15 |
consecutiveErrors |
Oui | Nombre d’erreurs de requête autorisées à se produire avant que le circuit ne se coupe et s’ouvre. | 10 |
timeoutInSeconds |
Oui | Période (en secondes) d’état ouvert, directement après l’échec. | 5 |
Processus disjoncteur
Spécifier consecutiveErrors (la condition de trajet du circuit comme consecutiveFailures > $(consecutiveErrors)-1) définit le nombre d’erreurs autorisées à se produire avant que le circuit ne se coupe coupe et s’ouvre à mi-chemin.
Le circuit attend la moitié ouverte pour la durée de timeoutInSeconds, pendant laquelle le nombre de demandes consecutiveErrors doit réussir consécutivement.
- Si les requêtes réussissent, le circuit se ferme.
- Si les requêtes échouent, le circuit reste dans un état demi-ouvert.
Si vous n’avez défini aucune valeur intervalInSeconds, le circuit est réinitialisé à un état fermé après la durée que vous avez définie pour timeoutInSeconds, quel que soit le nombre de réussites ou d’échecs consécutifs de la demande. Si vous définissez intervalInSeconds sur 0, le circuit ne se réinitialise jamais automatiquement, il passe simplement de l’état « à moitié ouvert » à « fermé » en effectuant correctement les demandes consecutiveErrors dans une ligne.
Si vous avez défini une valeur intervalInSeconds, cela détermine la durée pendant laquelle le circuit est réinitialisé à l’état fermé, indépendamment de la réussite ou non des demandes envoyées dans un état à moitié ouvert.
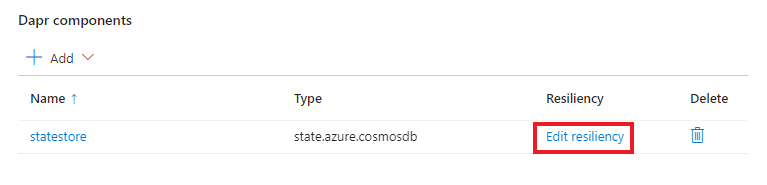
Journaux de résilience
Dans la section Analyse de votre application conteneur, sélectionnez Journaux d’activité.
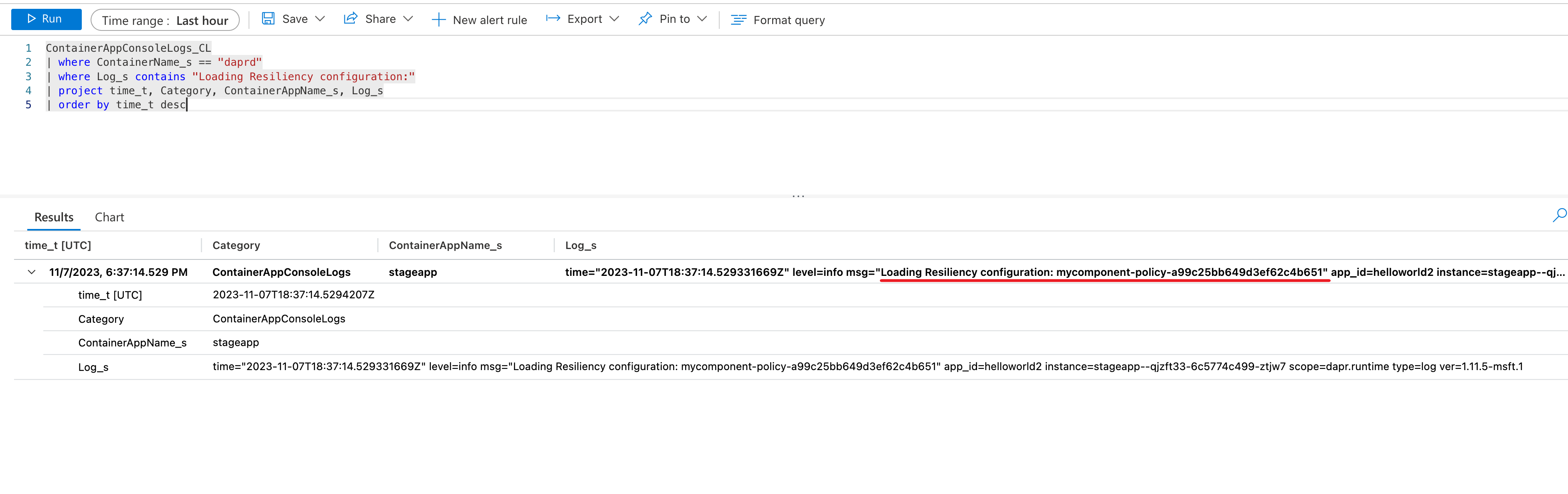
Dans le volet Journaux, écrivez et exécutez une requête pour rechercher la résilience via les journaux de votre système d’application conteneur. Par exemple, pour déterminer si une stratégie de résilience a été chargée :
ContainerAppConsoleLogs_CL
| where ContainerName_s == "daprd"
| where Log_s contains "Loading Resiliency configuration:"
| project time_t, Category, ContainerAppName_s, Log_s
| order by time_t desc
Cliquez sur Exécuter pour exécuter la requête et afficher le résultat avec le message de journal indiquant que la stratégie est chargée.
Vous pouvez également trouver la stratégie de résilience réelle en activant les journaux de débogage sur votre application conteneur et en interrogeant pour voir si une ressource de résilience est chargée.
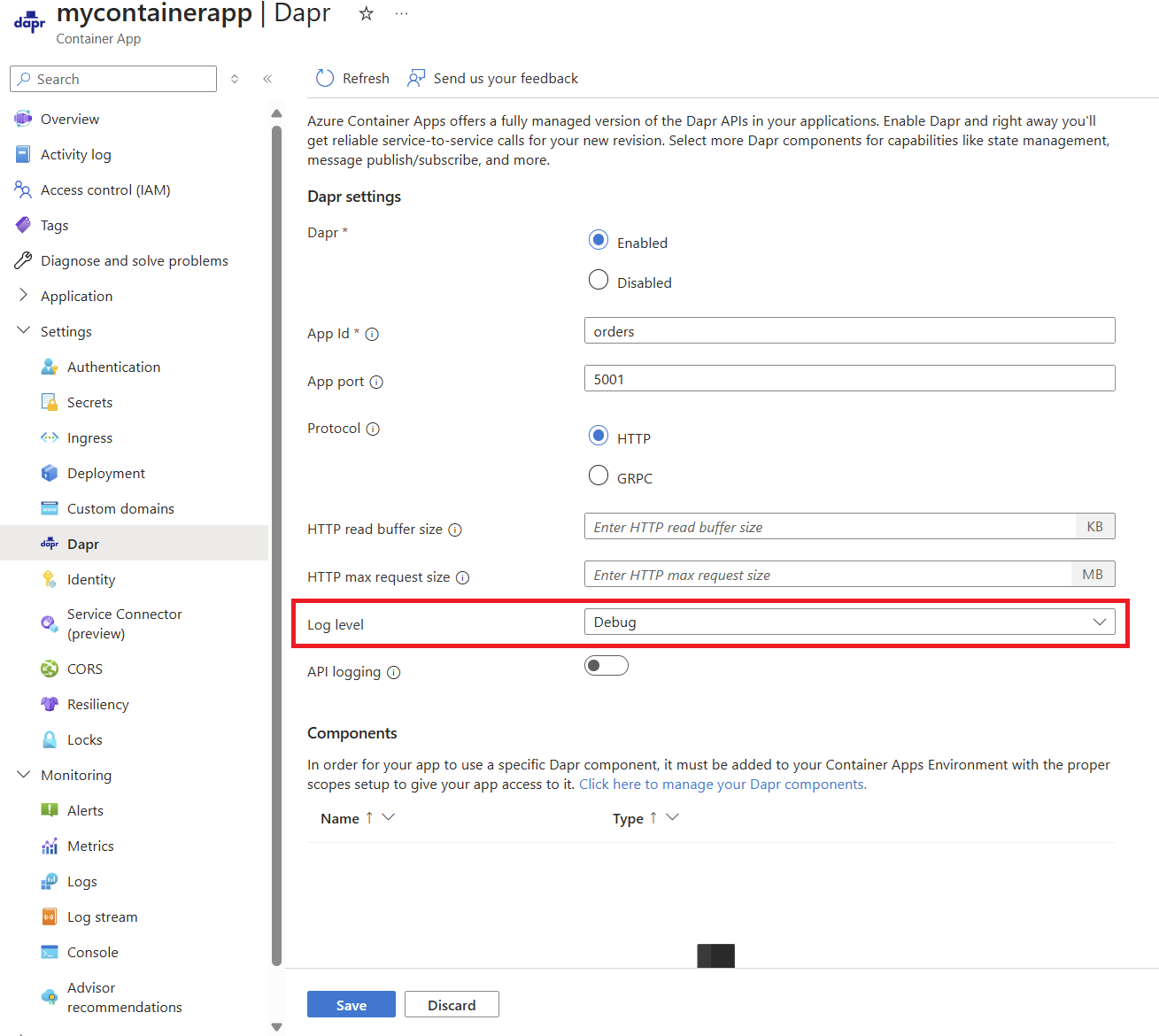
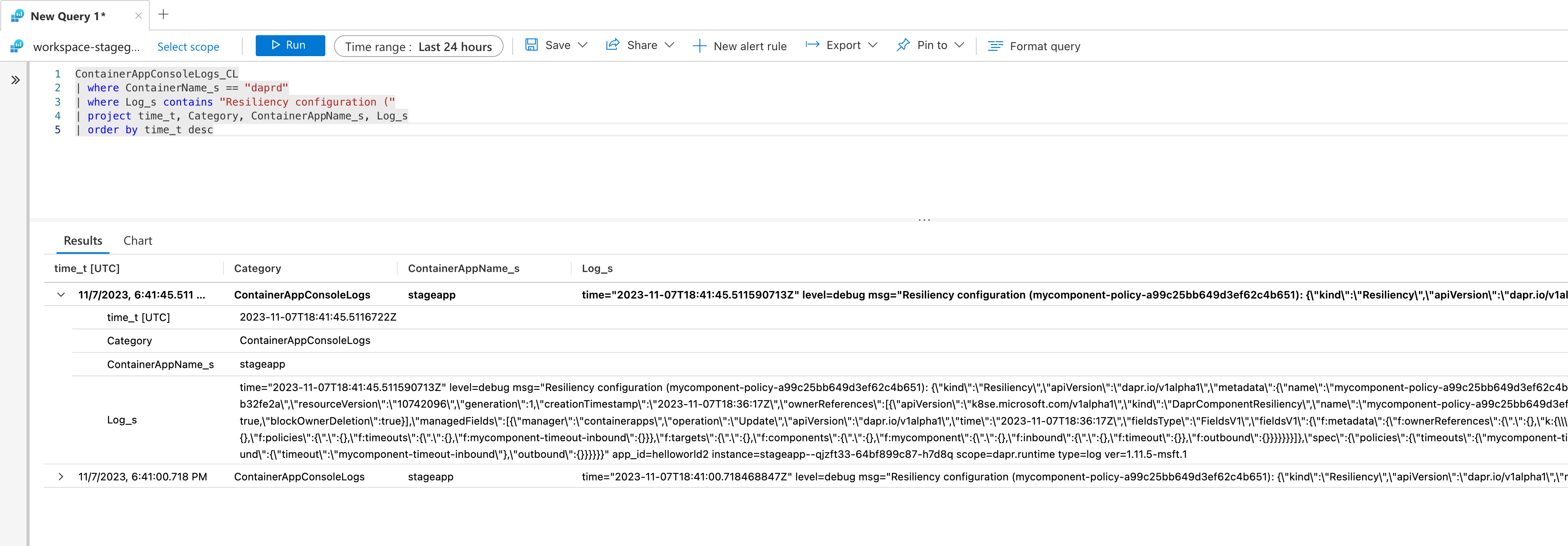
Une fois les journaux de débogage activés, utilisez une requête similaire à ce qui suit :
ContainerAppConsoleLogs_CL
| where ContainerName_s == "daprd"
| where Log_s contains "Resiliency configuration ("
| project time_t, Category, ContainerAppName_s, Log_s
| order by time_t desc
Cliquez sur Exécuter pour exécuter la requête et afficher le message de journal résultant avec la configuration de la stratégie.
Contenu connexe
Découvrez comment fonctionne la résilience pour communication de service à service à l’aide de Azure Container Apps intégré à la découverte de service