Tutoriel : Concevoir un tableau de bord analytique en temps réel à l'aide d'Azure Cosmos DB pour PostgreSQL
S’APPLIQUE À : ![]() Azure Cosmos DB for PostgreSQL (avec l’extension de base de données Citus pour PostgreSQL)
Azure Cosmos DB for PostgreSQL (avec l’extension de base de données Citus pour PostgreSQL)
Dans ce tutoriel, vous allez utiliser Azure Cosmos DB pour PostgreSQL pour découvrir comment :
- Créer un cluster
- Utiliser l’utilitaire psql pour créer un schéma
- Partitionner des tables entre des nœuds
- Générer un exemple de données
- Effectuer des cumuls
- Interroger des données brutes et agrégées
- Faire expirer des données
Prérequis
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Créer un cluster
Connectez-vous au portail Azure et procédez comme suit pour créer un cluster Azure Cosmos DB pour PostgreSQL :
Accédez à Créer un cluster Azure Cosmos DB pour PostgreSQL dans le portail Azure.
Sur le formulaire Créer un cluster Azure Cosmos DB pour PostgreSQL :
Renseignez l’onglet Informations de base.
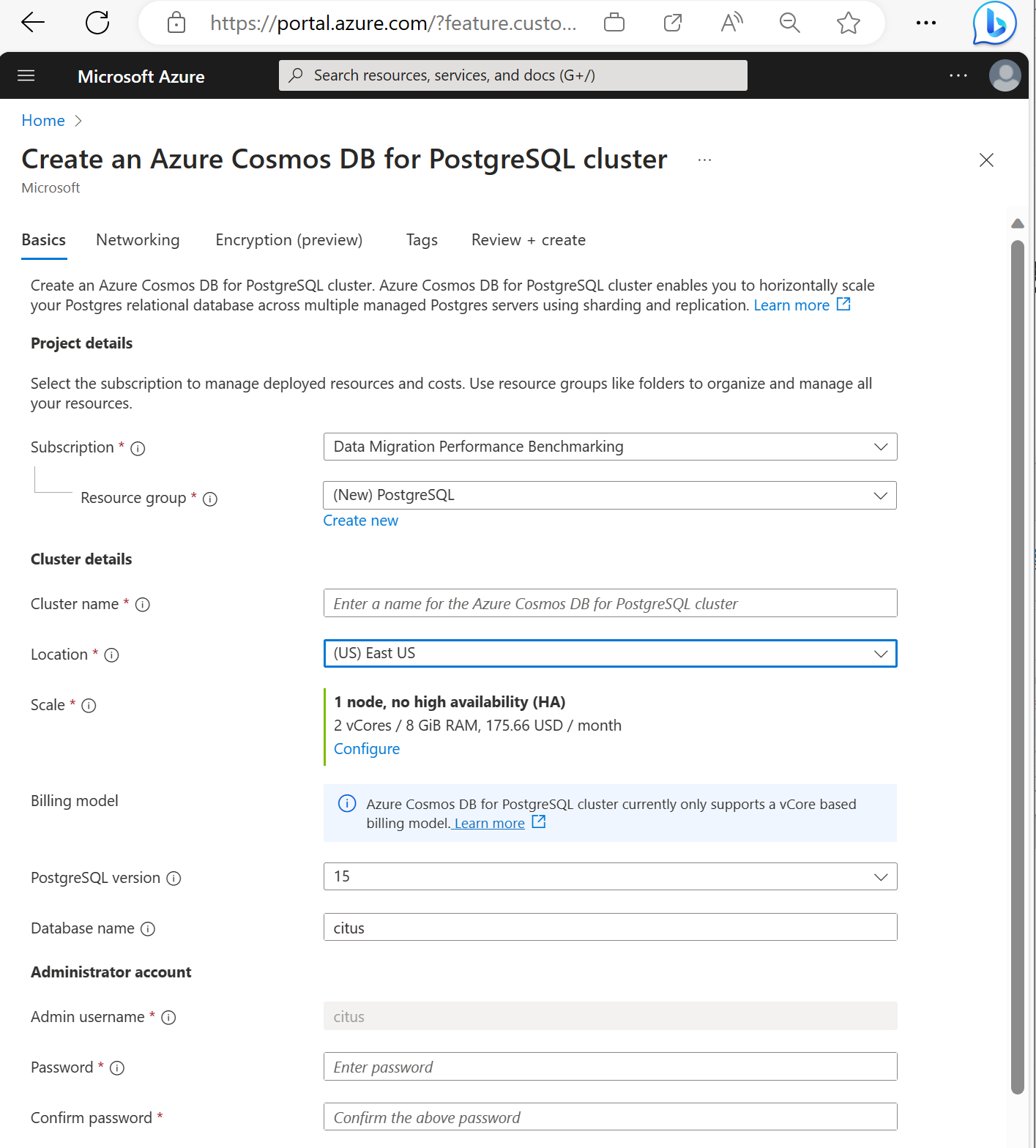
La plupart des options sont explicites, mais n’oubliez pas que :
- Le nom du cluster détermine le nom DNS que vos applications utilisent pour se connecter, au format
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Vous pouvez choisir une version principale de PostgreSQL, telle que la 15. Azure Cosmos DB for PostgreSQL prend toujours en charge la dernière version de Citus pour la principale version de Postgres sélectionnée.
- Le nom d’utilisateur de l’administrateur doit être
citus. - Vous pouvez laisser le nom de la base de données à sa valeur par défaut « citus » ou définir votre unique nom de base de données. Vous ne pouvez pas renommer une base de données après l’approvisionnement du cluster.
- Le nom du cluster détermine le nom DNS que vos applications utilisent pour se connecter, au format
Sélectionnez Suivant : Mise en réseau en bas de l’écran.
Sur l’écran Mise en réseau, sélectionnez Autoriser l’accès public à partir des ressources et services Azure dans Azure sur ce cluster.
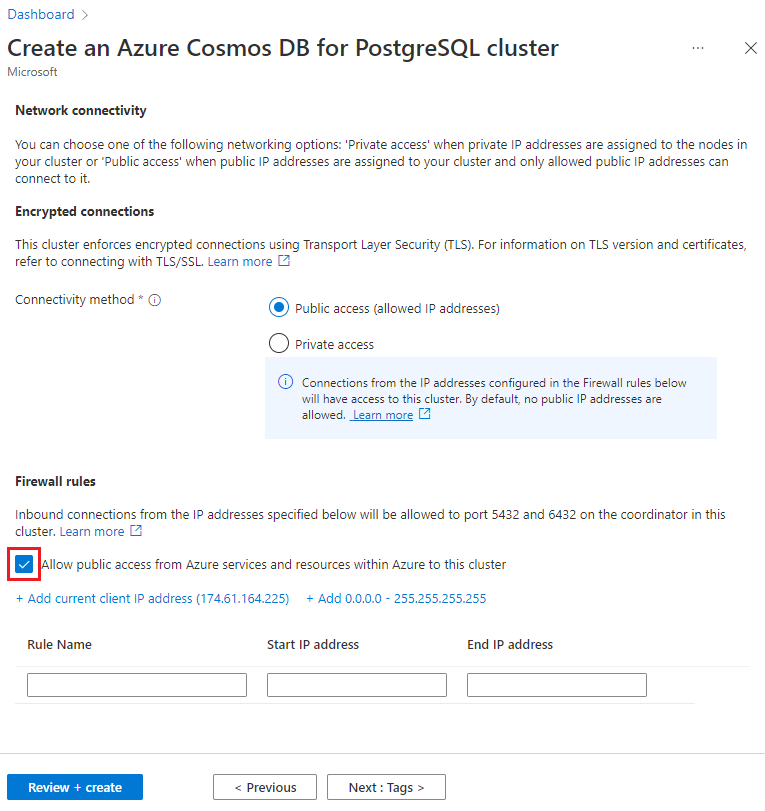
Sélectionnez Vérifier + créer puis, une fois la validation réussie, sélectionnez Créer pour créer le cluster.
Le provisionnement prend quelques minutes. La page redirige vers la supervision du déploiement. Quand l’état passe de Le déploiement est en cours à Votre déploiement est terminé, sélectionnez Accéder à la ressource.
Utiliser l’utilitaire psql pour créer un schéma
Une fois connecté à Azure Cosmos DB pour PostgreSQL à l’aide de psql, vous pouvez effectuer quelques tâches de base. Ce tutoriel vous guide lors de l’ingestion de données de trafic à partir d’analytiques web, puis du cumul des données pour fournir des tableaux de bord en temps réel basés sur ces données.
Vous allez créer une table qui consomme toutes vos données de trafic web brutes. Exécutez les commandes suivantes dans le terminal psql :
CREATE TABLE http_request (
site_id INT,
ingest_time TIMESTAMPTZ DEFAULT now(),
url TEXT,
request_country TEXT,
ip_address TEXT,
status_code INT,
response_time_msec INT
);
Vous allez également créer une table qui conserve vos agrégats par minute et une table qui conserve la position de votre dernier cumul. Exécutez également les commandes suivantes dans psql :
CREATE TABLE http_request_1min (
site_id INT,
ingest_time TIMESTAMPTZ, -- which minute this row represents
error_count INT,
success_count INT,
request_count INT,
average_response_time_msec INT,
CHECK (request_count = error_count + success_count),
CHECK (ingest_time = date_trunc('minute', ingest_time))
);
CREATE INDEX http_request_1min_idx ON http_request_1min (site_id, ingest_time);
CREATE TABLE latest_rollup (
minute timestamptz PRIMARY KEY,
CHECK (minute = date_trunc('minute', minute))
);
Vous pouvez localiser les tables nouvellement créées dans la liste des tables avec cette commande psql :
\dt
Partitionner des tables entre des nœuds
Un déploiement de Azure Cosmos DB pour PostgreSQL stocke les lignes de la table sur différents nœuds en fonction de la valeur d’une colonne désignée par l’utilisateur. Cette « colonne de distribution » marque la façon dont les données sont partitionnées entre les nœuds.
Nous allons définir la colonne de distribution sur site_id, la clé de partitionnement. Dans psql, exécutez les fonctions suivantes :
SELECT create_distributed_table('http_request', 'site_id');
SELECT create_distributed_table('http_request_1min', 'site_id');
Important
La distribution de tables ou l’utilisation du partitionnement basé sur un schéma est nécessaire pour tirer parti des fonctionnalités de performances d’Azure Cosmos DB for PostgreSQL. Si vous ne distribuez pas de tables ou de schémas, les nœuds Worker ne peuvent s’empêcher d’exécuter des requêtes impliquant leurs tables.
Générer un exemple de données
Votre groupe de serveurs doit à présent être prêt à recevoir des données. Vous pouvez exécuter ce qui suit localement à partir de votre connexion psql pour insérer des données en continu.
DO $$
BEGIN LOOP
INSERT INTO http_request (
site_id, ingest_time, url, request_country,
ip_address, status_code, response_time_msec
) VALUES (
trunc(random()*32), clock_timestamp(),
concat('http://example.com/', md5(random()::text)),
('{China,India,USA,Indonesia}'::text[])[ceil(random()*4)],
concat(
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2)
)::inet,
('{200,404}'::int[])[ceil(random()*2)],
5+trunc(random()*150)
);
COMMIT;
PERFORM pg_sleep(random() * 0.25);
END LOOP;
END $$;
La requête insère environ huit lignes par seconde. Les lignes sont stockées sur différents nœuds Worker, comme indiqué par la colonne de distribution, site_id.
Notes
Continuez à exécuter la requête de génération de données, puis ouvrez une deuxième connexion psql pour les commandes restantes dans ce tutoriel.
Requête
Azure Cosmos DB pour PostgreSQL permet à plusieurs nœuds de traiter des requêtes en parallèle pour une vitesse. Par exemple, la base de données calcule des agrégats tels que SUM (SOMME) et COUNT (NOMBRE) sur les nœuds Worker et combine les résultats dans une réponse finale.
Voici une requête qui compte les requêtes web par minute ainsi que quelques statistiques. Essayez de l’exécuter dans psql pour voir les résultats.
SELECT
site_id,
date_trunc('minute', ingest_time) as minute,
COUNT(1) AS request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
WHERE date_trunc('minute', ingest_time) > now() - '5 minutes'::interval
GROUP BY site_id, minute
ORDER BY minute ASC;
Cumuler les données
La requête précédente fonctionne bien dans les premières étapes, mais ses performances diminuent à mesure que la quantité de données augmente. Même avec un traitement distribué, il est plus rapide de précalculer les données que de les recalculer de façon répétée.
Vous pouvez vérifier que votre tableau de bord a conservé sa rapidité en cumulant régulièrement les données brutes dans une table d’agrégation. Vous pouvez tester la durée d’agrégation. Nous avons utilisé une table d’agrégation par minute, mais vous pouvez diviser les données par 5, 15 ou 60 minutes.
Pour exécuter ce cumul plus facilement, nous allons le placer dans une fonction plpgsql. Exécutez les commandes suivantes dans psql pour créer la fonction rollup_http_request.
-- initialize to a time long ago
INSERT INTO latest_rollup VALUES ('10-10-1901');
-- function to do the rollup
CREATE OR REPLACE FUNCTION rollup_http_request() RETURNS void AS $$
DECLARE
curr_rollup_time timestamptz := date_trunc('minute', now());
last_rollup_time timestamptz := minute from latest_rollup;
BEGIN
INSERT INTO http_request_1min (
site_id, ingest_time, request_count,
success_count, error_count, average_response_time_msec
) SELECT
site_id,
date_trunc('minute', ingest_time),
COUNT(1) as request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
-- roll up only data new since last_rollup_time
WHERE date_trunc('minute', ingest_time) <@
tstzrange(last_rollup_time, curr_rollup_time, '(]')
GROUP BY 1, 2;
-- update the value in latest_rollup so that next time we run the
-- rollup it will operate on data newer than curr_rollup_time
UPDATE latest_rollup SET minute = curr_rollup_time;
END;
$$ LANGUAGE plpgsql;
Une fois votre fonction en place, exécutez-la pour cumuler les données :
SELECT rollup_http_request();
Avec vos données au format préagrégé, vous pouvez interroger la table de cumul pour obtenir le même rapport que précédemment. Exécutez la requête suivante :
SELECT site_id, ingest_time as minute, request_count,
success_count, error_count, average_response_time_msec
FROM http_request_1min
WHERE ingest_time > date_trunc('minute', now()) - '5 minutes'::interval;
Expiration des données anciennes
Les cumuls accélèrent les requêtes, mais vous devez tout de même faire expirer les données anciennes pour éviter les coûts de stockage démesurés. Déterminez la durée pendant laquelle vous souhaitez conserver les données pour chaque granularité et utilisez des requêtes standard pour supprimer les données expirées. Dans l’exemple suivant, vous allez conserver les données brutes pendant un jour et les agrégations par minute pendant un mois :
DELETE FROM http_request WHERE ingest_time < now() - interval '1 day';
DELETE FROM http_request_1min WHERE ingest_time < now() - interval '1 month';
En production, vous pouvez encapsuler ces requêtes dans une fonction et appeler celle-ci toutes les minutes dans un travail cron.
Nettoyer les ressources
Au cours des étapes précédentes, vous avez créé des ressources Azure dans un groupe de serveurs. Si vous ne pensez pas avoir besoin de ces ressources à l'avenir, supprimez le cluster. Appuyez sur le bouton Supprimer dans la page Vue d’ensemble de votre groupe de serveurs. Quand vous y êtes invité dans une page contextuelle, confirmez le nom du groupe de serveurs, puis cliquez sur le bouton Supprimer.
Étapes suivantes
Dans ce tutoriel, vous avez appris à approvisionner un cluster. Vous vous y êtes connecté avec psql, vous avez créé un schéma et vous avez distribué les données. Vous avez vu comment interroger des données sous leur forme brute, à agréger régulièrement ces données, à interroger les tables agrégées et à faire expirer les données anciennes.
- En savoir plus sur les types de nœuds de cluster
- Déterminer la meilleure taille initiale pour votre cluster