Ingérer des données d’Azure Stream Analytics dans Azure Data Explorer
Important
Ce connecteur peut être utilisé dans Real-Time Intelligence dans Microsoft Fabric. Utilisez les instructions contenues dans cet article avec les exceptions suivantes :
- Si nécessaire, créez des bases de données à l’aide des instructions contenues dans Créer une base de données KQL.
- Si nécessaire, créez des tables à l’aide des instructions contenues dans Créer une table vide.
- Obtenir des URI de requête ou d’ingestion à l’aide des instructions contenues dans Copier l’URI.
- Exécutez des requêtes dans un ensemble de requêtes KQL.
Azure Data Explorer prend en charge l’ingestion de données d’Azure Stream Analytics. Azure Stream Analytics est un moteur de traitement des événements complexes et d’analyse en temps réel conçu pour traiter de grands volumes de données diffusées en Fast Streaming par plusieurs sources à la fois.
Un travail Azure Stream Analytics se compose d’une source d’entrée, d’une requête de transformation et d’une connexion de sortie. Vous pouvez créer, modifier et tester des travaux Stream Analytics à l’aide du portail Azure, de modèles Azure Resource Manager (ARM), d’Azure PowerShell, de l’API .NET, de l’API REST, de Visual Studio et de l’Éditeur sans code Stream Analytics.
Dans cet article, vous allez apprendre à utiliser un travail Stream Analytics pour collecter des données à partir d’un Event Hub et à les envoyer à votre cluster Azure Data Explorer à l’aide du portail Azure ou d’un modèle ARM.
Prérequis
Créez un cluster et une base de données, ainsi qu’une table.
Créez un hub d’événements en vous aidant des sections suivantes du tutoriel Azure Stream Analytics :
- Créer un concentrateur d’événements
- Permettre d’accéder à Event Hub et obtenir une chaîne de connexion
Conseil
Pour le test, nous vous recommandons de télécharger l’application de génération d’événements d’appel téléphonique à partir du Centre de téléchargement Microsoft, ou d’obtenir le code source à partir de GitHub. Lors de la définition du travail Azure Stream Analytics, vous le configurez de façon à extraire (pull) des données du hub d’événements et à les passer au connecteur de sortie Azure Data Explorer.
Créer une connexion de sortie Azure Data Explorer
Procédez comme suit afin de créer une sortie Azure Data Explorer pour un travail Stream Analytics à l’aide du portail Azure ou d’un modèle ARM. La connexion est utilisée par le travail Stream Analytics pour envoyer des données à une table Azure Data Explorer spécifiée. Une fois la connexion créée et le travail en cours d’exécution, les données qui circulent dans le travail sont ingérées dans la table cible spécifiée.
Important
- Le connecteur de sortie Azure Data Explorer prend uniquement en charge l’authentification d’identité managée. Dans le cadre de la création du connecteur, les autorisations Moniteur de base de données et Ingesteur de base de données sont accordés à l’identité managée du travail Azure Stream Analytics.
- Lorsque vous configurez le connecteur de sortie Azure Data Explorer, vous spécifiez le cluster cible, la base de données et le nom de la table. Pour que l’ingestion réussisse, toutes les colonnes définies dans la requête Azure Stream Analytics doivent correspondre aux noms et types de colonnes de la table Azure Data Explorer. Les noms de colonnes respectent la casse et peuvent être dans n’importe quel ordre. S’il existe des colonnes dans la requête Azure Stream Analytics qui ne correspondent pas aux colonnes de la table Azure Data Explorer, une erreur est générée.
Remarque
- Toutes les entrées Azure Stream Analytics sont prises en charge. Le connecteur transforme les entrées au format CSV, puis importe les données dans la table Azure Data Explorer spécifiée.
- Azure Data Explorer est associé à une stratégie d’agrégation (traitement par lot) conçue pour optimiser le processus d’ingestion des données. Par défaut, la stratégie est configurée sur 5 minutes, 1 000 éléments ou 1 Go de données. Vous pouvez donc rencontrer une certaine latence. Pour plus d’informations sur la configuration des options d’agrégation, consultez la stratégie de traitement par lot.
Avant de commencer, vérifiez que vous disposez d’un travail Stream Analytics existant ou créez-en un, puis effectuez les étapes suivantes pour créer votre connexion Azure Data Explorer.
Connectez-vous au portail Azure.
Dans le portail Azure, ouvrez Toutes les ressources, puis sélectionnez votre travail Stream Analytics.
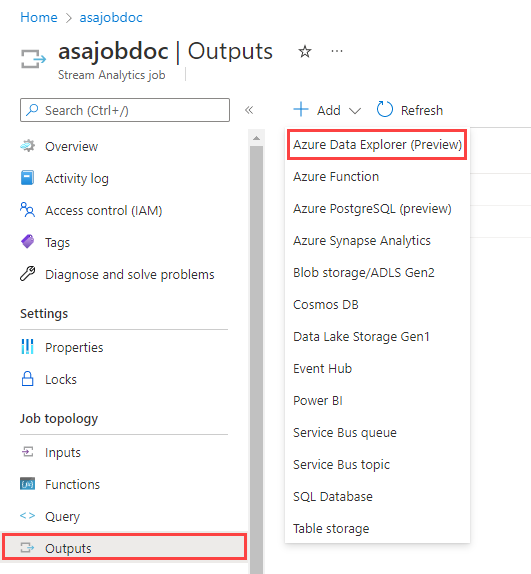
Sous Topologie de la tâche, sélectionnez Sorties.
Sélectionnez Ajouter>Azure Data Explorer.
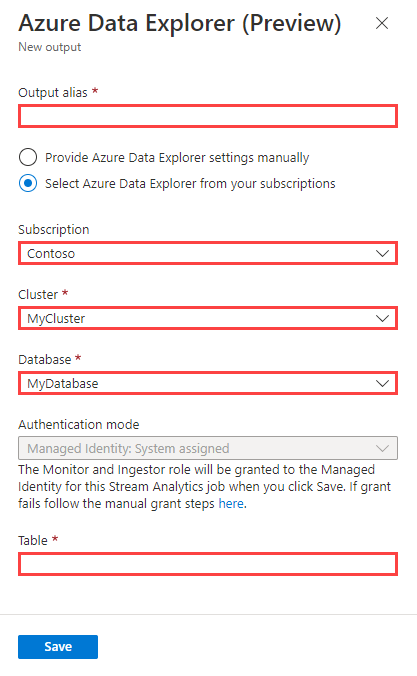
Remplissez le formulaire de sortie avec les informations suivantes, puis sélectionnez Enregistrer.
Remarque
Vous pouvez utiliser les options suivantes pour spécifier votre cluster et votre base de données :
- Abonnement : sélectionnez Azure Data Explorer dans vos abonnements, sélectionnez votre abonnement, puis choisissez votre cluster et votre base de données.
- Manuellement : sélectionnez Fournir manuellement les paramètres d’Azure Data Explorer, puis spécifiez l’URI et la base de données du cluster.
Nom de la propriété Description Alias de sortie Nom convivial utilisé dans les requêtes pour diriger la sortie de requête vers cette base de données. Abonnement Sélectionnez l’abonnement Azure où réside votre cluster. Cluster Nom unique qui identifie votre cluster. Le nom de domaine [Région].kusto.windows.net est ajouté au nom de cluster que vous fournissez. Le nom doit être uniquement composé de lettres minuscules et de chiffres. Il doit comprendre entre 4 et 22 caractères. URI de cluster URI d’ingestion de données de votre cluster. Vous pouvez spécifier l’URI des points de terminaison d’ingestion de données Azure Data Explorer ou Azure Synapse Data Explorer. Base de données Nom de la base de données où vous envoyez votre sortie. Ce nom de base de données doit être unique dans le cluster. Authentification Identité managée de Microsoft Entra permettant à votre cluster d’accéder facilement à d’autres ressources protégées par Microsoft Entra. Managée par la plateforme Azure, l’identité ne nécessite pas que vous approvisionniez ou permutiez de secrets. La configuration d’une identité managées vous permet d’utiliser des clés gérées par le client pour votre cluster. Table Nom de la table où vous envoyez votre sortie. Les noms de colonnes et les types de données de la sortie Azure Stream Analytics doivent correspondre au schéma de la table Azure Data Explorer.