Flux de données de mappage dans Azure Data Factory
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Que sont les flux de données de mappage ?
Les mappages de flux de données sont des transformations de données conçues de manière graphique dans Azure Data Factory. Les flux de données permettent aux ingénieurs de données de développer une logique de transformation des données sans rédiger de code. Les flux de données qui en résultent sont exécutés en tant qu'activités dans les pipelines Azure Data Factory qui utilisent des clusters Apache Spark faisant l'objet d'un scale-out. Les activités de flux de données peuvent être mises en œuvre à l’aide de fonctionnalités de planification, de contrôle, de flux et de supervision Azure Data Factory existantes.
Le flux de données de mappage fournit une expérience entièrement visuelle sans aucun codage. Vos flux de données sont exécutés sur les clusters d'exécution gérés par ADF pour un traitement des données faisant l'objet d'un scale-out. Azure Data Factory gère intégralement la traduction du code, l’optimisation du chemin et l'exécution de vos travaux de flux de données.
Prise en main
Les flux de données sont créés à partir du volet Ressources de la fabrique, comme les pipelines et jeux de données. Pour créer un flux de données, sélectionnez le signe plus (+) en regard de Ressources Factory, puis sélectionnez Flux de données.
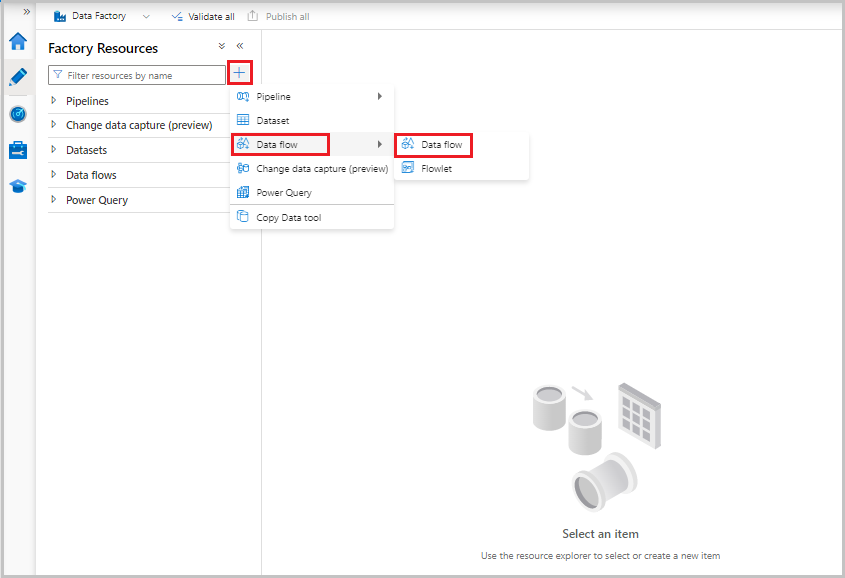 Cette action vous fait accéder au canevas du flux de données où vous pouvez créer votre logique de transformation. Sélectionnez Ajouter une source pour commencer à configurer votre transformation de la source. Pour plus d’informations, consultez Transformation de la source.
Cette action vous fait accéder au canevas du flux de données où vous pouvez créer votre logique de transformation. Sélectionnez Ajouter une source pour commencer à configurer votre transformation de la source. Pour plus d’informations, consultez Transformation de la source.
Création de flux de données
Le flux de données de mappage a un canevas de création unique conçu pour faciliter la création de logique de transformation. Le canevas de flux de données est divisé en trois parties : la barre supérieure, le graphe et le panneau de configuration.
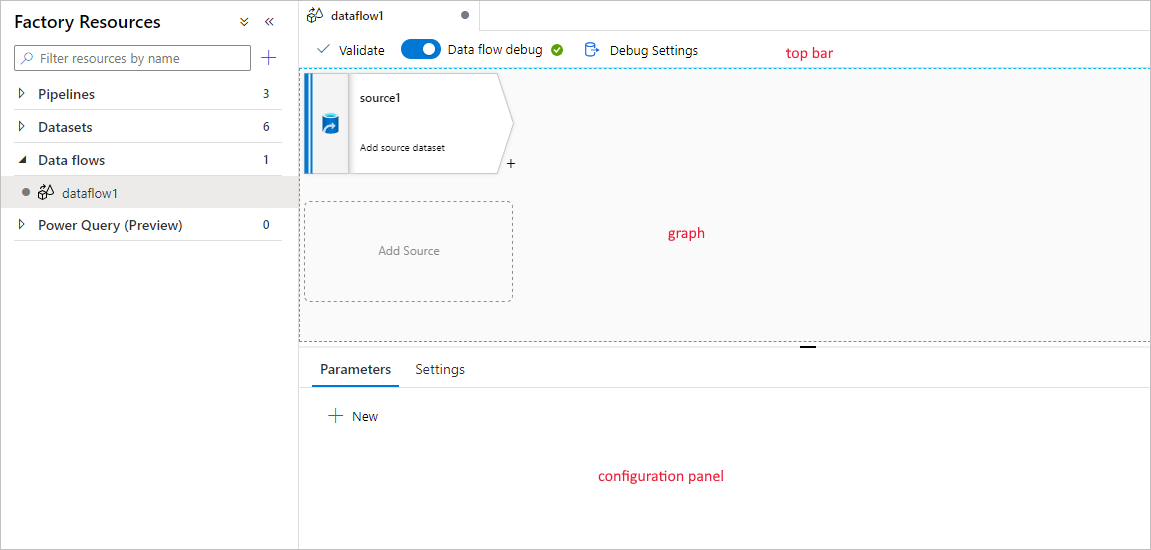
Graph
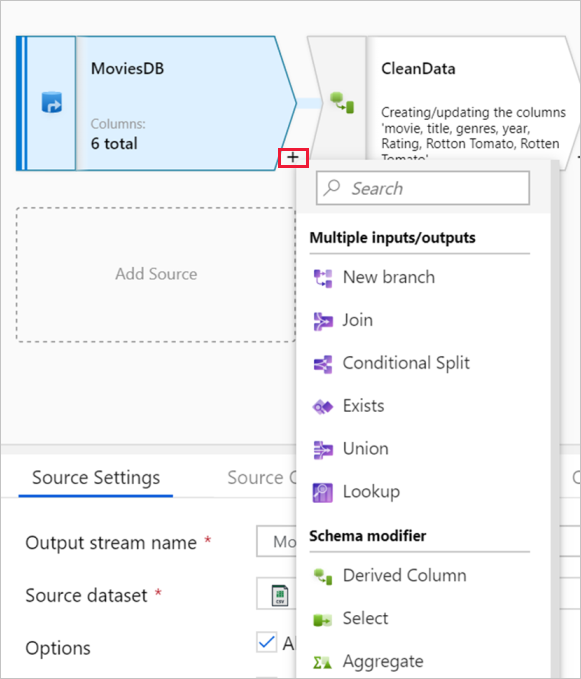
Le graphe affiche le flux de transformation. Il montre la traçabilité des données sources à mesure qu’elles sont transmises à un ou plusieurs récepteurs. Les récepteurs peuvent être n’importe quelle destination de source de données vers laquelle vous souhaitez déplacer les résultats de vos données transformées. Pour ajouter une nouvelle source, sélectionnez Ajouter une source. Pour ajouter une nouvelle transformation, sélectionnez le signe plus (+) situé dans la partie inférieure droite d’une transformation existante. Apprenez à gérer le graphique des flux de données.
Panneau de configuration
Le panneau de configuration affiche les paramètres spécifiques à la transformation actuellement sélectionnée. Si aucune transformation n’est sélectionnée, le flux de données est affiché. Dans la configuration globale du flux de données, vous pouvez ajouter des paramètres via l’onglet Paramètres. Pour plus d’informations, consultez Paramètres du mappage de flux de données.
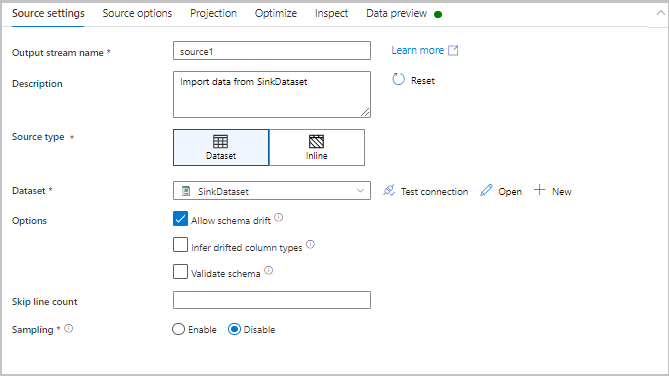
Chaque transformation contient au moins quatre onglets de configuration.
Paramètres de transformation
Le premier onglet du volet de configuration de chaque transformation contient les paramètres spécifiques à cette transformation. Pour plus d’informations, reportez-vous à la page de documentation de cette transformation.
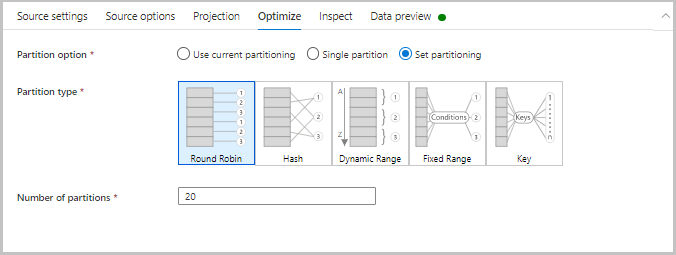
Optimiser
L’onglet Optimiser contient des paramètres pour configurer des schémas de partitionnement. Pour en savoir plus sur l’optimisation de vos flux de données, consultez le Guide des performances de flux de données de mappage.
Inspecter
Le volet Inspecter permet de visualiser les métadonnées du flux de données que vous êtes en train de transformer. Vous pouvez voir le nombre de colonnes, les colonnes modifiées, les colonnes ajoutées, les types de données, l'ordre des colonnes et les références des colonnes. Inspecter est un affichage en lecture seule de vos métadonnées. Il n’est pas nécessaire que le mode de débogage soit activé pour voir les métadonnées dans le volet Inspecter.
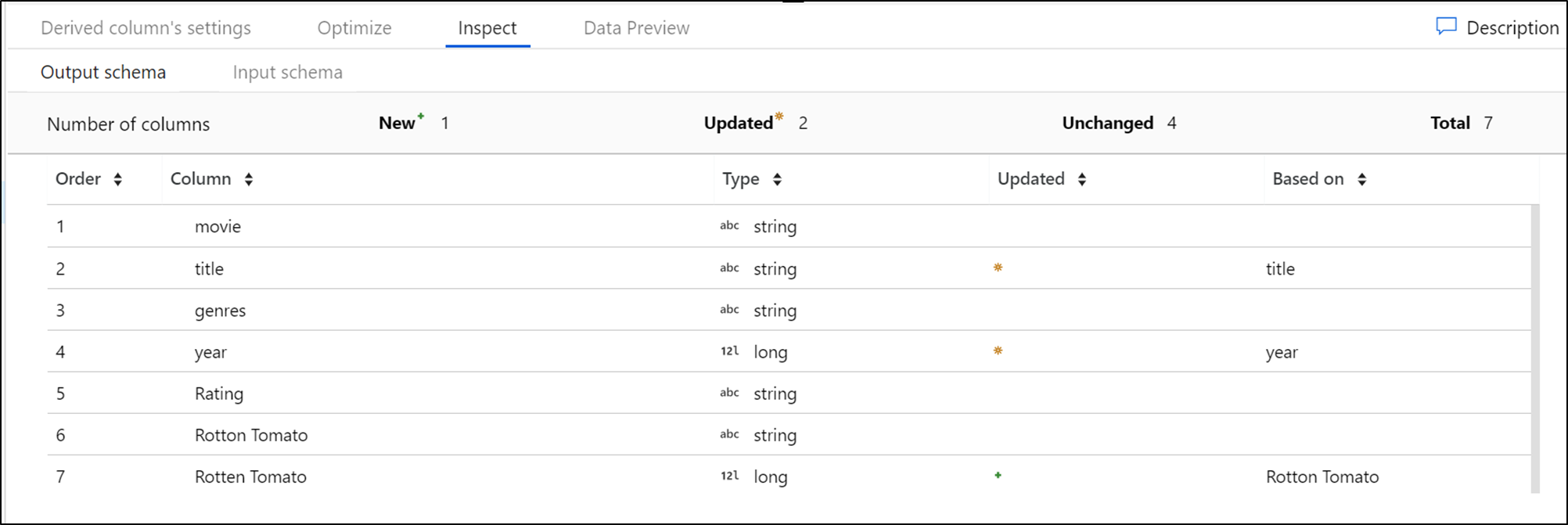
À mesure que vous modifiez la forme de vos données par le biais de transformations, le flux des changements de métadonnées est visible dans le volet Inspecter. Si votre transformation de la source ne comporte pas de schéma défini, les métadonnées ne sont pas visibles dans le volet Inspecter. L’absence de métadonnées est fréquent dans les scénarios de dérive de schéma.
Aperçu des données
Si le mode de débogage est activé, l’onglet Aperçu des données vous donne une capture instantanée interactive des données à chaque transformation. Pour en savoir plus, consultez Aperçu des données en mode de débogage.
Barre supérieure
La barre supérieure contient des actions qui affectent l’ensemble du flux de données comme l’enregistrement et la validation. Vous pouvez également afficher le code JSON sous-jacent et le script de flux de données de votre logique de transformation. Pour plus d’informations, consultez le script de flux de données.
Transformations disponibles
Pour obtenir la liste des transformations disponibles, consultez la Vue d’ensemble de la transformation de flux de données de mappage.
Types de données de flux de données
- tableau
- binary
- boolean
- complex
- décimal (comprend la précision)
- Date
- float
- entier
- long
- carte
- short
- string
- timestamp
Activité de flux de données
Les flux de données de mappage sont mis en œuvre dans les pipelines ADF à l’aide de l’activité de flux de données. Il suffit à l’utilisateur de spécifier le runtime d’intégration à utiliser et de passer des valeurs de paramètre. Pour plus d’informations, consultez Runtime d’intégration Azure.
Mode débogage
Le mode débogage vous permet de voir de manière interactive les résultats de chaque étape de transformation pendant que vous générez et déboguez vos flux de données. La session de débogage peut être utilisée à la fois lors de la génération de votre logique de flux de données et lors des exécutions de débogage de pipeline avec les activités de flux de données. Pour plus d’informations, consultez la documentation relative au mode de débogage.
Surveillance des flux de données
Le mappage du flux de données s’intègre aux fonctionnalités d’analyse existantes d’Azure Data Factory. Pour savoir comment comprendre la sortie de la surveillance du flux de données, consultez Supervision des flux de données de mappage.
L’équipe Azure Data Factory a créé un guide de réglage des performances pour vous aider à optimiser le temps d’exécution de vos flux de données après avoir généré votre logique métier.
Contenu connexe
- Découvrez comment créer une transformation de la source.
- Découvrez comment créer vos flux de données en mode de débogage.