Copier des données du stockage Blob Azure vers une base de données SQL Database en utilisant l’outil Copier les données
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Dans ce didacticiel, vous utilisez le portail Azure pour créer une fabrique de données. Vous utilisez ensuite l’outil Copier les données pour créer un pipeline qui copie des données du stockage Blob Azure vers une base de données SQL Database.
Notes
Si vous débutez avec Azure Data Factory, consultez Présentation d’Azure Data Factory.
Dans ce tutoriel, vous effectuerez les étapes suivantes :
- Créer une fabrique de données.
- Utiliser l’outil Copier les données pour créer un pipeline.
- Surveiller les exécutions de pipeline et d’activité.
Prérequis
- Abonnement Azure : Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
- Compte Stockage Azure : Utilisez le stockage blob comme magasin de données source. Si vous n’avez pas de compte Stockage Azure, consultez les instructions dans Créer un compte de stockage.
- Azure SQL Database : Utilisez une base de données SQL Database comme magasin de données récepteur. Si vous n’avez pas de base de données SQL Database, consultez les instructions dans Créer une base de données SQL Database.
Préparer la base de données SQL
Autorisez les services Azure à accéder au serveur SQL logique de votre base de données Azure SQL Database.
Vérifiez que le paramètre Autoriser les services et les ressources Azure à accéder à ce serveur est activé pour votre serveur exécutant SQL Database. Ce paramètre permet à Data Factory d’écrire des données dans votre instance de base de données. Pour vérifier et activer ce paramètre, accédez au serveur SQL logique > Sécurité > Pare-feux et réseaux virtuels et définissez l’option Autoriser les services et les ressources Azure à accéder à ce serveur sur Activé.
Notes
L’option Autoriser les services et les ressources Azure à accéder à ce serveur permet d’activer l’accès réseau à votre serveur SQL Server à partir de n’importe quelle ressource Azure, pas seulement celles de votre abonnement. Il peut ne pas convenir à tous les environnements, mais il convient à ce didacticiel limité. Pour plus d’informations, consultez Règles de pare-feu Azure SQL Server. À la place, vous pouvez vous servir de points de terminaison privés pour vous connecter aux services Azure PaaS sans utiliser d’IP publiques.
Créer un objet blob et une table SQL
Préparez votre stockage Blob et votre base de données SQL Database pour ce tutoriel en effectuant ces étapes.
Créer un objet blob source
Lancez le Bloc-notes. Copiez le texte suivant et enregistrez-le dans un fichier nommé inputEmp.txt sur votre disque :
FirstName|LastName John|Doe Jane|DoeCréez un conteneur nommé adfv2tutorial et chargez le fichier inputEmp.txt dedans. Vous pouvez utiliser le portail Azure ou différents outils, comme l’Explorateur Stockage Azure pour effectuer ces tâches.
Créer une table SQL de récepteur
Utilisez le script SQL suivant pour créer une table nommée
dbo.empdans votre base de données SQL Database :CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
Créer une fabrique de données
Dans le menu de gauche, sélectionnez Créer une ressource>Intégration>Data Factory :
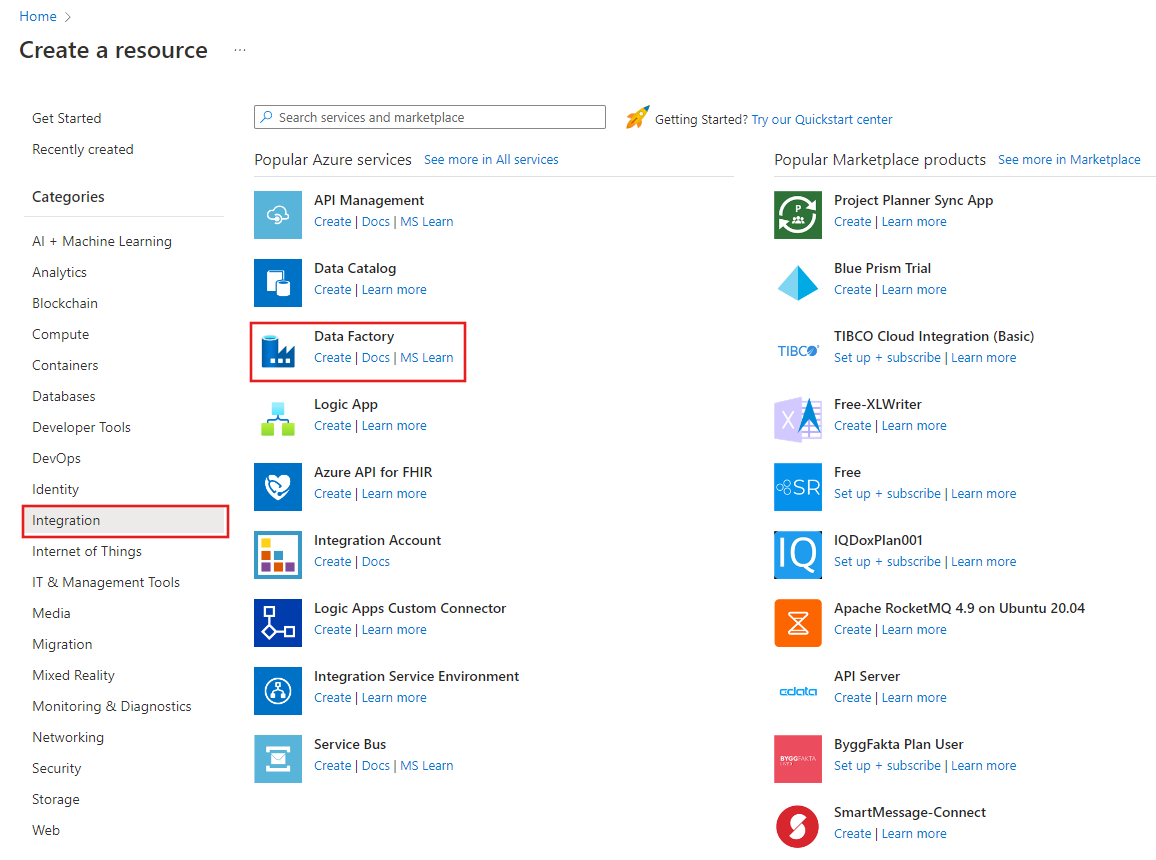
Sur la page Nouvelle fabrique de données, entrez ADFTutorialDataFactory dans le champ Nom.
Le nom de votre fabrique de données doit être un nom global unique. Vous pouvez recevoir le message d’erreur suivant :
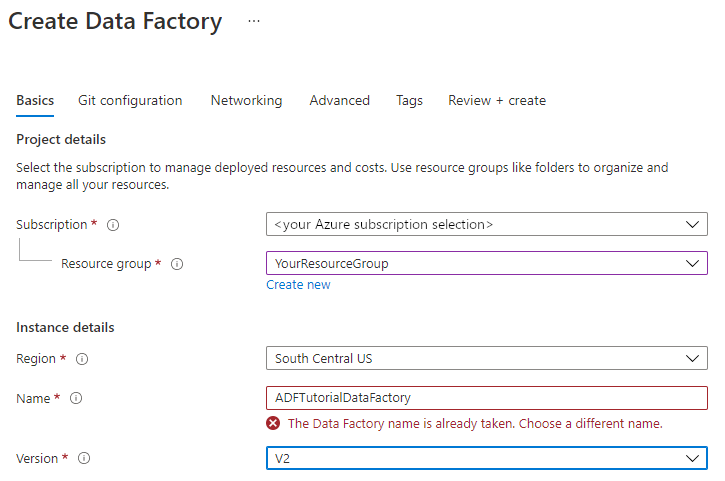
Si vous recevez un message d’erreur concernant la valeur du nom, saisissez un autre nom pour la fabrique de données. Par exemple, utilisez le nom votrenomADFTutorialDataFactory. Pour savoir comment nommer les artefacts Data Factory, voir Data Factory - Règles d’affectation des noms.
Sélectionnez l’abonnement Azure dans lequel vous créez la nouvelle fabrique de données.
Pour Groupe de ressources, réalisez l’une des opérations suivantes :
a. Sélectionnez Utiliser l’existant, puis sélectionnez un groupe de ressources existant dans la liste déroulante.
b. Sélectionnez Créer, puis entrez le nom d’un groupe de ressources.
Pour plus d’informations sur les groupes de ressources, consultez Utilisation des groupes de ressources pour gérer vos ressources Azure.
Sous Version, sélectionnez V2 pour la version.
Sous Emplacement, sélectionnez l’emplacement de la fabrique de données. Seuls les emplacements pris en charge sont affichés dans la liste déroulante. Les magasins de données (tels que le Stockage Azure et SQL Database) et les services de calcul (comme Azure HDInsight) utilisés par votre fabrique de données peuvent se trouver dans d’autres emplacements et régions.
Sélectionnez Create (Créer).
Une fois la création terminée, la page d’accueil Data Factory s’affiche.

Pour lancer l’interface utilisateur Azure Data Factory dans un onglet séparé, sélectionnez Ouvrir dans la mosaïque Ouvrir Azure Data Factory Studio.
Utiliser l’outil Copier les données pour créer un pipeline
Sur la page d’accueil d’Azure Data Factory, sélectionnez la mosaïque Ingérer pour lancer l’outil Copier des données.
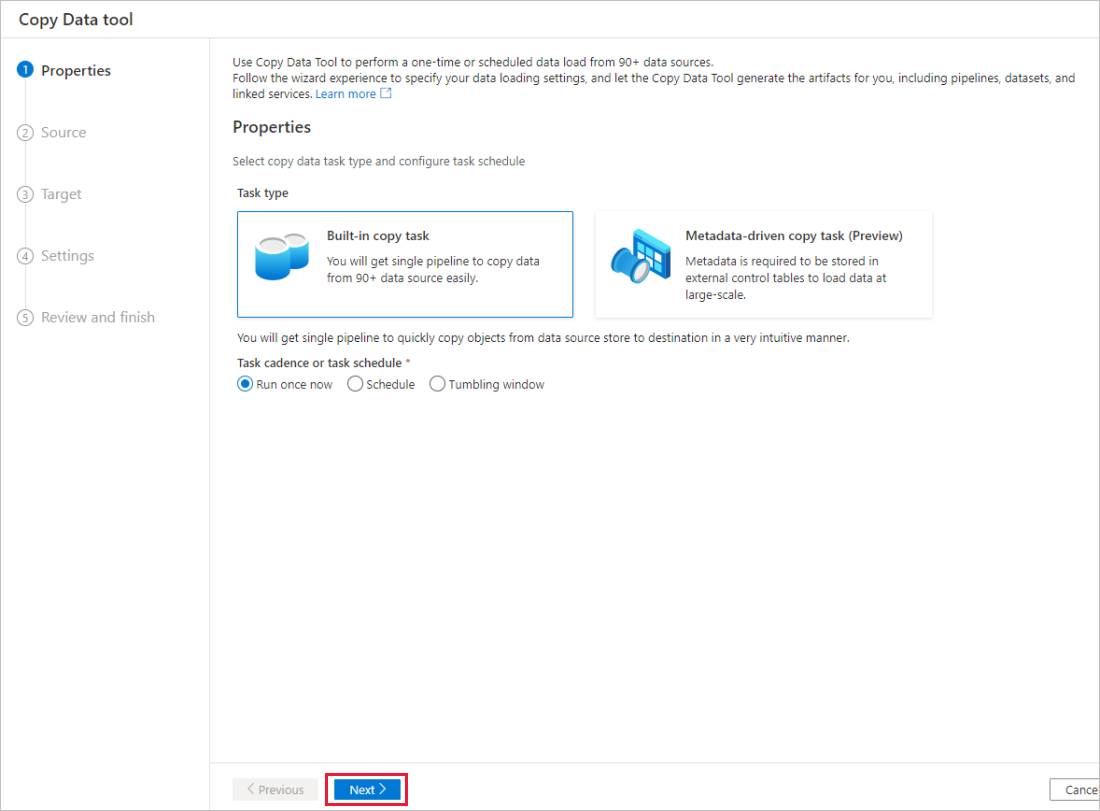
Sur la page Propriétés de l’outil Copier des données, choisissez Tâche de copie intégrée sous Type de tâche, puis Suivant.
Sur la page Banque de données source, procédez comme suit :
a. Sélectionnez + Créer une connexion pour ajouter une connexion.
b. Sélectionnez Stockage Blob Azure à partir de la galerie, puis sélectionnez Continuer.
c. Dans la page Nouvelle connexion (Stockage Blob Azure) , sélectionnez votre abonnement Azure dans la liste Abonnement Azure et votre compte de stockage dans la liste Nom du compte de stockage. Testez la connexion, puis sélectionnez Créer.
d. Sélectionnez le service lié qui vient d’être créé en tant que source dans le bloc Connexion.
e. Dans la section Fichier ou dossier, sélectionnez Parcourir pour accéder au dossier adfv2tutorial, sélectionnez le fichier inputEmp.txt, puis cliquez sur OK.
f. Sélectionnez Suivant pour passer à l’étape suivante.
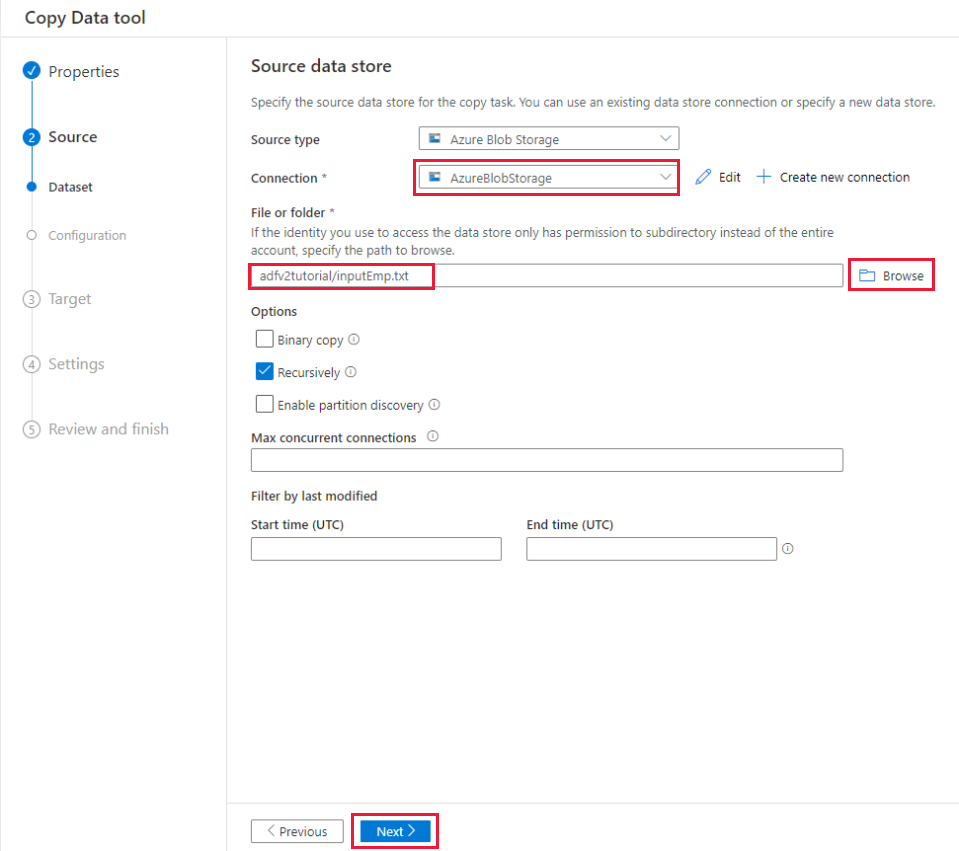
Dans la page Paramètres de format de fichier , cochez la case Première ligne comme en-tête. Notez que l’outil détecte automatiquement les séparateurs de lignes et de colonnes. Vous pouvez également visualiser des données et afficher le schéma des données d’entrée en sélectionnant le bouton Aperçu des données dans cette page. Sélectionnez ensuite Suivant.
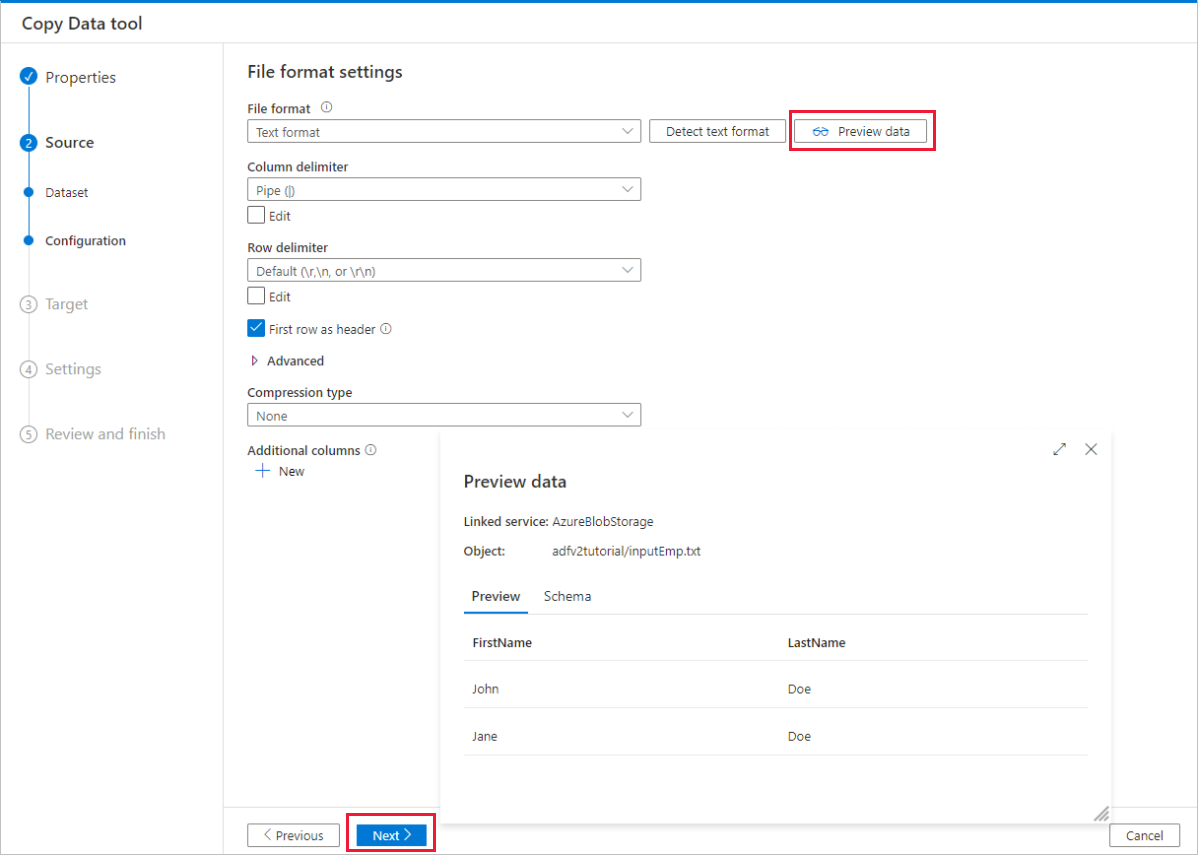
Sur la page Banque de données de destination, procédez comme suit :
a. Sélectionnez + Créer une connexion pour ajouter une connexion.
b. Sélectionnez Azure SQL Database dans la galerie, puis sélectionnez Continuer.
c. Sur la page Nouvelle connexion (Azure SQL Database) , sélectionnez votre abonnement Azure, le nom du serveur et le nom de la base de données dans la liste déroulante. Sélectionnez ensuite Authentification SQL sous Type d’authentification, spécifiez le nom d’utilisateur et le mot de passe. Testez la connexion et sélectionnez Créer.
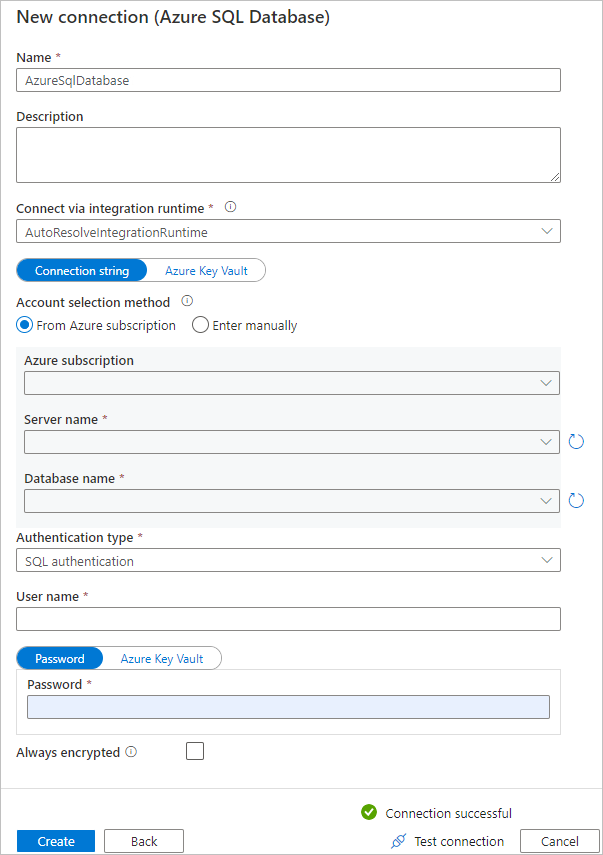
d. Sélectionnez le service lié qui vient d’être créé en tant que récepteur, puis sélectionnez Suivant.
Sur la page Magasin de données de destination, sélectionnez Utiliser une table existante et sélectionnez la table
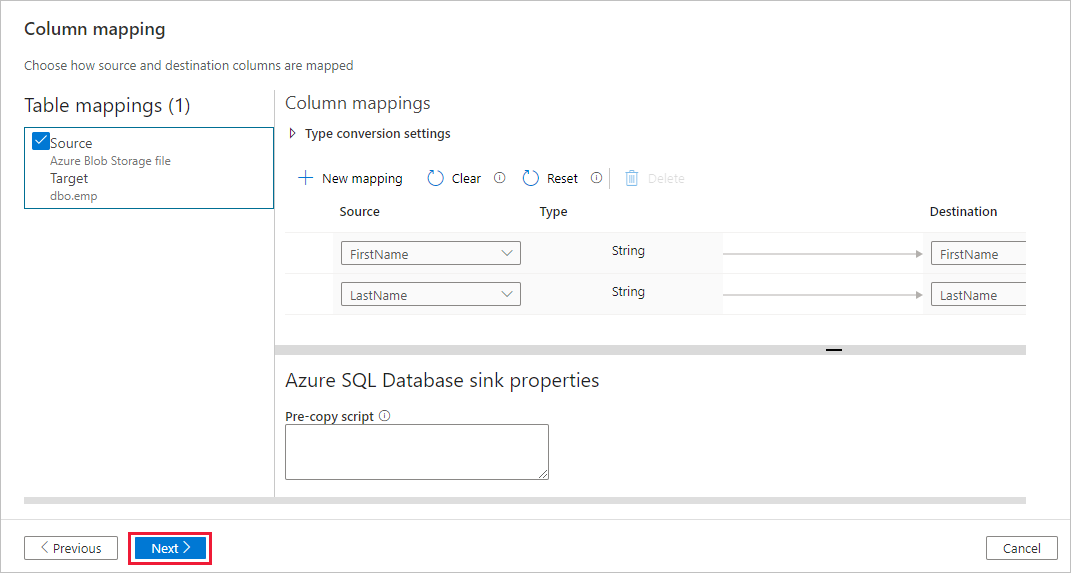
dbo.emp. Sélectionnez ensuite Suivant.Dans la page Mappage de colonne, notez que les deuxième et troisième colonnes du fichier d’entrée sont mappées aux colonnes FirstName et LastName de la table emp. Ajustez le mappage pour vérifier qu’il n’y a pas d’erreur, puis sélectionnez Suivant.
Sur la page Paramètres, sous Nom de la tâche, saisissez CopyFromBlobToSqlPipeline et sélectionnez Suivant.
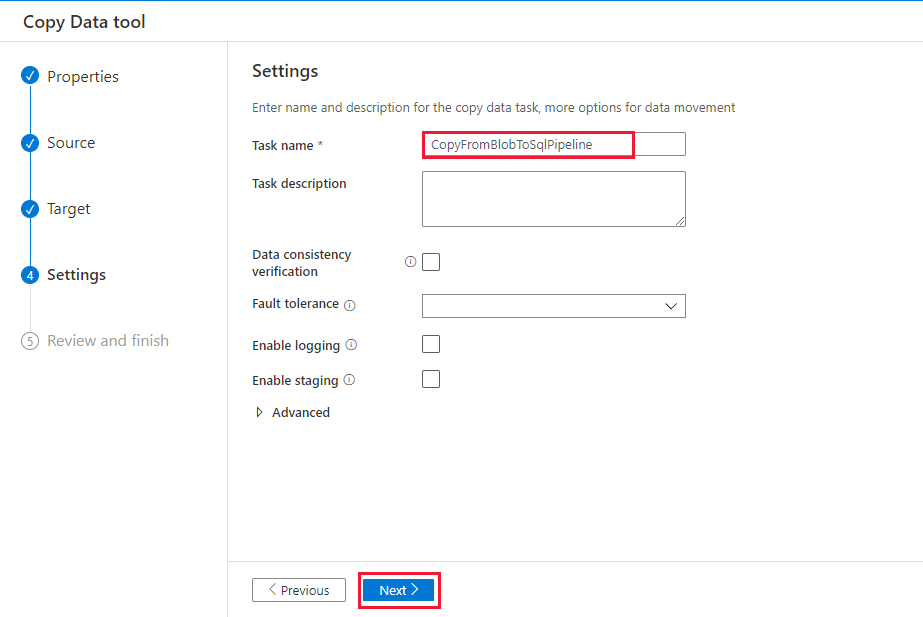
Sur la page Résumé, vérifiez les paramètres, puis sélectionnez Suivant.
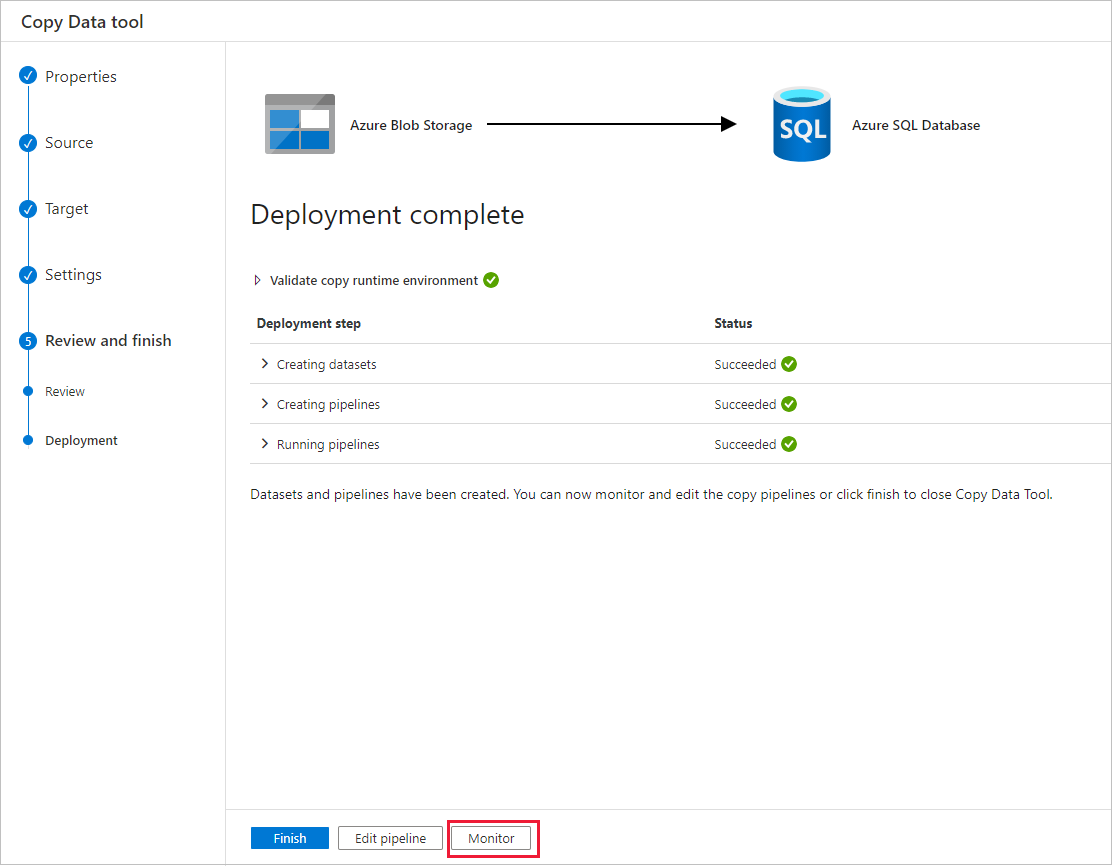
Sur la page Déploiement, sélectionnez Analyse pour analyser le pipeline (tâche).
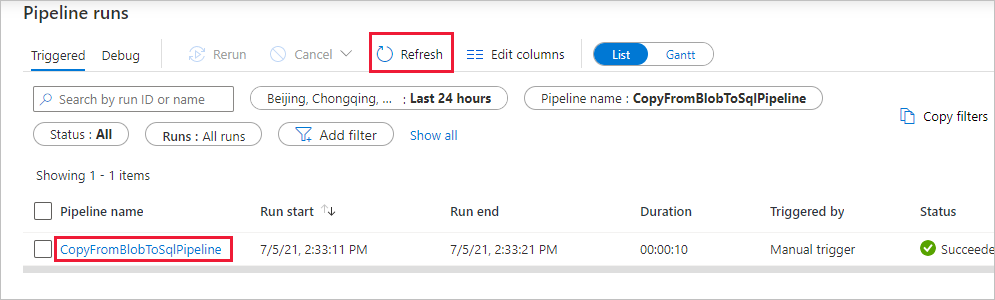
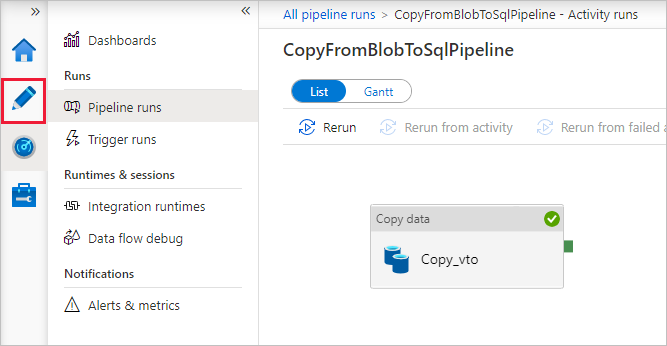
Dans la page Exécutions de pipeline, sélectionnez Actualiser pour actualiser la liste. Sélectionnez le lien situé sous Nom du pipeline pour afficher les détails de l’exécution d’activité ou réexécuter le pipeline.
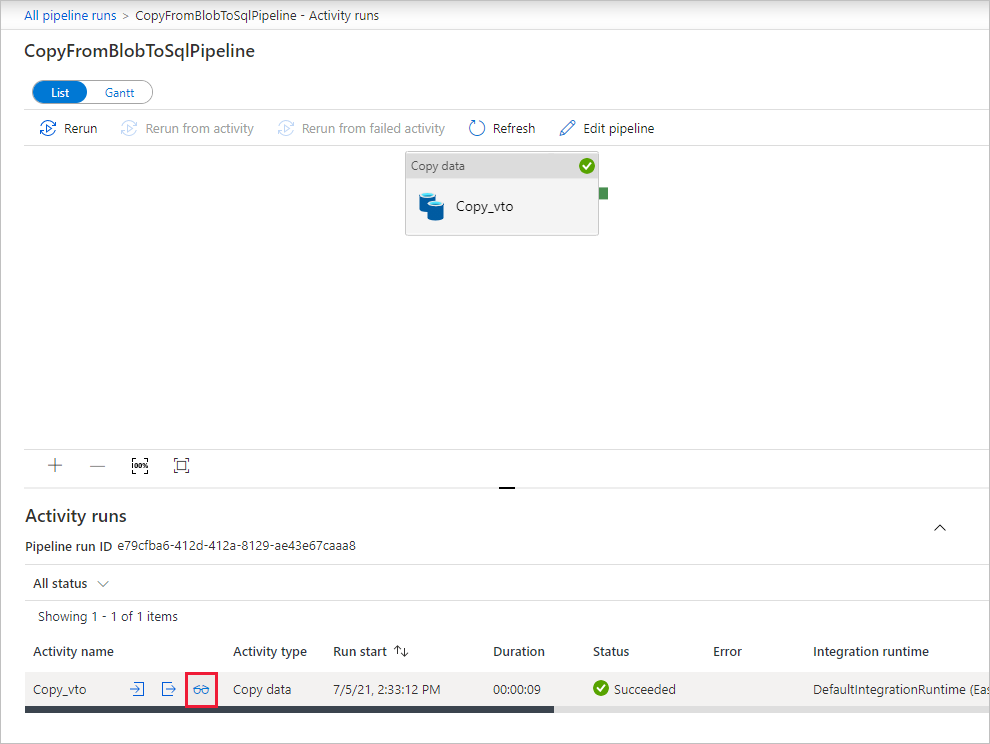
Sur la page « Exécutions des activités », sélectionnez le lien Détails (icône en forme de lunettes) sous la colonne Nom de l’activité pour plus d’informations sur l’opération de copie. Pour revenir à l’affichage « Exécutions de pipeline », sélectionnez le lien Toutes les exécutions de pipeline dans le menu de navigation. Sélectionnez Actualiser pour actualiser l’affichage.
Vérifiez que les données sont insérées dans la table dbo.emp dans votre base de données SQL Database.
Sélectionnez l’onglet Auteur sur la gauche pour basculer en mode éditeur. Vous pouvez mettre à jour les services, jeux de données et pipelines liés créés par l’outil à l’aide de l’éditeur. Pour plus de détails sur la modification de ces entités dans l’interface utilisateur de Data Factory, consultez la version du portail Azure de ce didacticiel.
Contenu connexe
Le pipeline de cet exemple copie des données du stockage Blob vers une base de données SQL Database. Vous avez appris à :
- Créer une fabrique de données.
- Utiliser l’outil Copier les données pour créer un pipeline.
- Surveiller les exécutions de pipeline et d’activité.
Passez au didacticiel suivant pour en savoir plus sur la copie des données locales vers le cloud :