Configurer AI Gateway sur les points de terminaison de service de modèle
Dans cet article, vous allez apprendre à configurer Mosaic AI Gateway sur un point de terminaison de service de modèle.
Spécifications
- Un espace de travail Databricks dans une région prise en charge par les modèles externes.
- Effectuez les étapes 1 et 2 de la Création d’un point de terminaison de service de modèle externe.
Configurer la passerelle AI à l’aide de l’interface utilisateur
Cette section montre comment configurer ai Gateway lors de la création d’un point de terminaison à l’aide de l’interface utilisateur de service.
Si vous préférez effectuer cette opération par programme, consultez l’exemple Notebook.
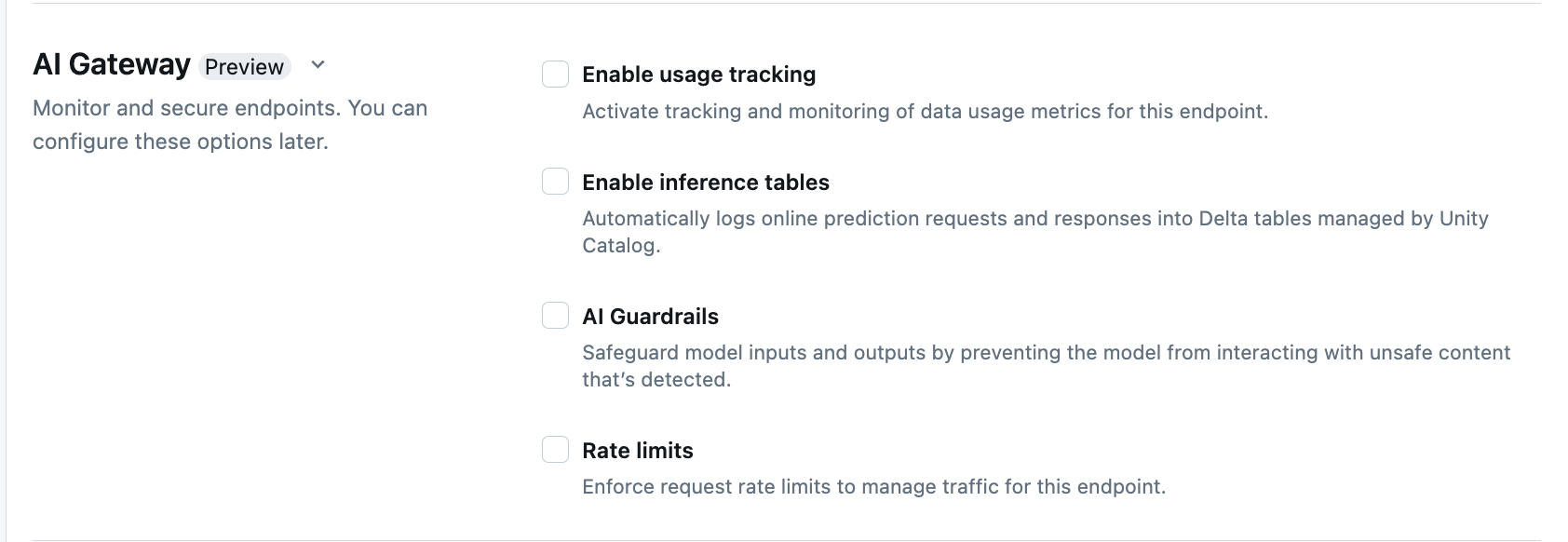
Dans la section AI Gateway de la page de création de point de terminaison, vous pouvez configurer individuellement les fonctionnalités AI Gateway suivantes :
| Fonctionnalité | Comment activer | Détails |
|---|---|---|
| Suivi de l’utilisation | Sélectionnez Activer le suivi de l’utilisation pour activer le suivi et la surveillance des métriques d’utilisation des données. | - Il doit avoir Unity Catalog activé. - Les administrateurs de compte doivent activer le schéma de table système de service avant d’utiliser les tables système : system.serving.endpoint_usage qui capture le nombre de jetons pour chaque requête au point de terminaison et system.serving.served_entities qui stocke les métadonnées pour chaque modèle externe.- Consultez les Schémas de table de suivi de l’utilisation - Seuls les administrateurs de compte ont l’autorisation d’afficher ou d’interroger la table served_entities ou endpoint_usage, même si l’utilisateur qui gère le point de terminaison doit activer le suivi de l’utilisation. Consultez Octroyer un accès aux tables système- Le nombre de jetons d’entrée et de sortie est estimé en tant que ( text_length+1)/4 si le nombre de jetons n’est pas renvoyé par le modèle. |
| Journalisation des charges utiles | Sélectionnez Activer les tables d’inférence pour journaliser automatiquement les demandes et les réponses de votre point de terminaison dans des tables Delta gérées par Unity Catalog. | - Vous devez activer Unity Catalog et avoir accès à CREATE_TABLE dans le schéma de catalogue spécifié.- Les tables d’inférence activées par ai Gateway ont un schéma différent de celui des tables d’inférence créées pour les points de terminaison de service de modèle qui servent des modèles personnalisés. Consultez Schéma de table d’inférence avec AI Gateway activé. - Les données de journalisation de charge utile remplissent ces tables moins d’une heure après l’interrogation du point de terminaison. - Les charges utiles supérieures à 1 Mo ne sont pas journalisées. - La charge utile de réponse agrège la réponse de tous les segments renvoyés. - La diffusion en continu est prise en charge. Dans les scénarios de diffusion en continu, la charge utile de réponse agrège la réponse des segments renvoyés. |
| Garde-fous d’IA | Consultez Configurer les garde-fous d’IA dans l’interface utilisateur. | - Les garde-fous empêchent le modèle d’interagir avec le contenu non sécurisé et dangereux détecté dans les entrées et sorties de modèle. - Les garde-fous de sortie ne sont pas pris en charge pour les modèles d’incorporation ou pour la diffusion en continu. |
| Limites de débit | Vous pouvez appliquer des limites de débit de requête pour gérer le trafic de votre point de terminaison par utilisateur et par point de terminaison | - Les limites de débit sont définies en requêtes par minute (QPM). - La valeur par défaut est Aucune limite à la fois par utilisateur et par point de terminaison. |
| Routage du trafic | Pour configurer le routage du trafic sur votre point de terminaison, consultez Servir plusieurs modèles externes à un point de terminaison. |
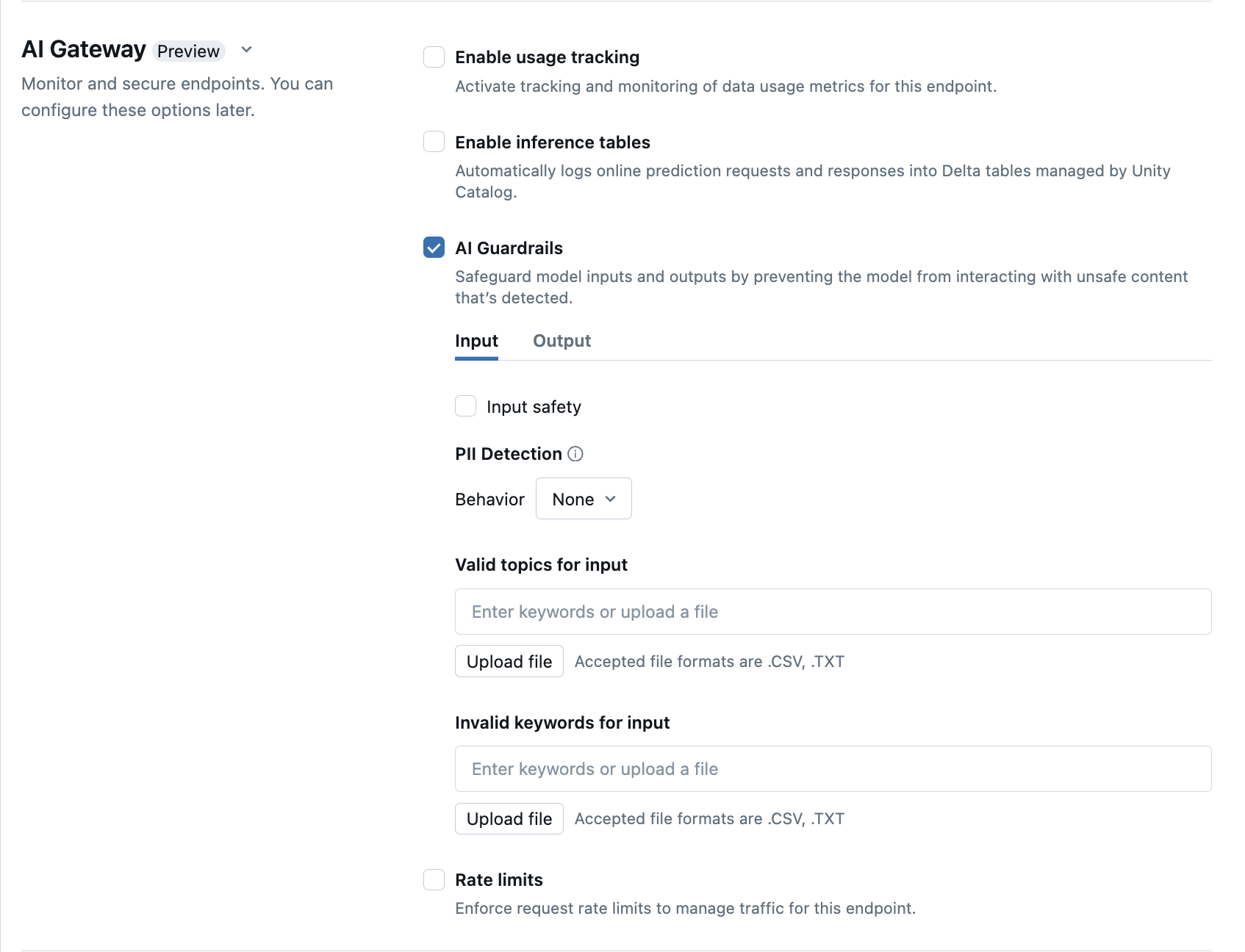
Configurer les garde-fous d’IA dans l’interface utilisateur
Le tableau suivant montre comment configurer les garde-fous pris en charge.
| Garde-fou | Comment activer | Détails |
|---|---|---|
| Sécurité | Sélectionnez Sécurité pour activer les garde-fous afin d’empêcher votre modèle d’interagir avec du contenu non sécurisé et dangereux. | |
| Détection d’informations identifiables personnellement (PII) | Sélectionnez la détection des PII pour détecter les données de PII telles que les noms, les adresses et les numéros de carte de crédit. | |
| Sujets valides | Vous pouvez saisir des sujets directement dans ce champ. Si vous avez plusieurs entrées, veillez à appuyer sur Entrée après chaque sujet. Vous pouvez également charger un fichier .csv ou .txt. |
Vous pouvez spécifier un maximum de 50 sujets valides. Chaque sujet ne doit pas dépasser 100 caractères |
| Mots clés non valides | Vous pouvez saisir des sujets directement dans ce champ. Si vous avez plusieurs entrées, veillez à appuyer sur Entrée après chaque sujet. Vous pouvez également charger un fichier .csv ou .txt. |
Un maximum de 50 mots clés non valides peut être spécifié. Chaque mot clé ne doit pas dépasser 100 caractères. |
Schémas de table de suivi de l’utilisation
La table système de suivi de l’utilisation system.serving.served_entities a le schéma suivant :
| Nom de colonne | Description | Type |
|---|---|---|
served_entity_id |
L’ID unique de l’entité servie. | STRING |
account_id |
L’ID de compte client pour Delta Sharing. | STRING |
workspace_id |
L’ID de l’espace de travail client du point de terminaison de service. | STRING |
created_by |
L’ID du créateur. | STRING |
endpoint_name |
Le nom du point de terminaison de service. | STRING |
endpoint_id |
L’ID unique du point de terminaison de service. | STRING |
served_entity_name |
Le nom de l’entité servie. | STRING |
entity_type |
Le type de l’entité qui est servie. Peut être FEATURE_SPEC, EXTERNAL_MODEL, FOUNDATION_MODEL ou CUSTOM_MODEL |
STRING |
entity_name |
Le nom sous-jacent de l’entité. Différent du served_entity_name qui est un nom fourni par l’utilisateur. Par exemple, entity_name est le nom du modèle Unity Catalog. |
STRING |
entity_version |
La version de l’entité servie. | STRING |
endpoint_config_version |
La version de la configuration du point de terminaison. | INT |
task |
Le type de tâche. Peut être llm/v1/chat, llm/v1/completions ou llm/v1/embeddings. |
STRING |
external_model_config |
Configurations pour les modèles externes. Par exemple, {Provider: OpenAI} |
STRUCT |
foundation_model_config |
Configurations pour les modèles de base. Exemple : {min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} |
STRUCT |
custom_model_config |
Configurations pour les modèles personnalisés. Exemple : { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
feature_spec_config |
Configurations pour les spécifications de fonctionnalités. Par exemple, { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
change_time |
Horodatage de modification pour l’entité servie. | TIMESTAMP |
endpoint_delete_time |
Horodatage de la suppression d’entité. Le point de terminaison est le conteneur pour l’entité servie. Une fois le point de terminaison supprimé, l’entité servie est également supprimée. | timestamp |
La table système de suivi de l’utilisation system.serving.endpoint_usage a le schéma suivant :
| Nom de colonne | Description | Type |
|---|---|---|
account_id |
L’ID du compte client. | STRING |
workspace_id |
L’ID de l’espace de travail client du point de terminaison de service. | STRING |
client_request_id |
L’utilisateur a fourni l’identifiant de demande qui peut être spécifié dans le corps de la demande de service de modèle. | STRING |
databricks_request_id |
Identificateur de requête généré par Azure Databricks attaché à toutes les requêtes de mise en service de modèle. | STRING |
requester |
L’ID de l’utilisateur ou du principal de service dont les autorisations sont utilisées pour la demande d’appel du point de terminaison de service. | STRING |
status_code |
Code d’état HTTP retourné par le modèle. | INTEGER |
request_time |
L’horodatage de réception de la demande. | timestamp |
input_token_count |
Le nombre de jetons de l’entrée. | LONG |
output_token_count |
Le nombre de jetons de la sortie. | LONG |
input_character_count |
Le nombre de caractères de la chaîne ou de l’invite d’entrée. | LONG |
output_character_count |
Le nombre de caractères de la chaîne de sortie de la réponse. | LONG |
usage_context |
La carte fournie par l’utilisateur contenant des identifiants de l’utilisateur final ou de l’application client qui effectue l’appel au point de terminaison. Voir Définir davantage l’utilisation avec usage_context. | MAP |
request_streaming |
Indique si la demande est en mode flux. | BOOLEAN |
served_entity_id |
L’ID unique utilisé pour associer à la table de dimension system.serving.served_entities afin de rechercher des informations sur le point de terminaison et l’entité servie. |
STRING |
Définir davantage l’utilisation avec usage_context
Lorsque vous interrogez un modèle externe avec le suivi de l’utilisation activé, vous pouvez fournir le paramètre usage_context avec le type Map[String, String]. Le mappage de contexte d’utilisation s’affiche dans la table de suivi de l’utilisation dans la colonne usage_context. La usage_context taille de la carte ne peut pas dépasser 10 Kib.
Les administrateurs de compte peuvent agréger différentes lignes en fonction du contexte d’utilisation pour obtenir des informations utiles et joindre ces informations aux informations de la table de journalisation de charge utile. Par exemple, vous pouvez ajouter end_user_to_charge à usage_context pour l’attribution des coûts de suivi pour les utilisateurs finaux.
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
Schéma de table d’inférence avec AI Gateway activé
Les tables d’inférence activées à l’aide d’AI Gateway ont le schéma suivant :
| Nom de colonne | Description | Type |
|---|---|---|
request_date |
Date UTC de réception de la requête de mise en service de modèle. | DATE |
databricks_request_id |
Identificateur de requête généré par Azure Databricks attaché à toutes les requêtes de mise en service de modèle. | STRING |
client_request_id |
Identificateur de requête généré par un client facultatif qui peut être spécifié dans le corps de la requête de mise en service de modèle. | STRING |
request_time |
L’horodatage de réception de la demande. | timestamp |
status_code |
Code d’état HTTP retourné par le modèle. | INT |
sampling_fraction |
Fraction d’échantillonnage utilisée dans l’événement où la requête a été échantillonnée. Cette valeur est comprise entre 0 et 1, où 1 indique que 100 % des requêtes entrantes ont été incluses. | DOUBLE |
execution_duration_ms |
La durée en millisecondes de la réalisation de l’inférence par le modèle. Cela n’inclut pas les latences réseau de surcharge et représente uniquement le temps nécessaire pour que le modèle génère des prédictions. | BIGINT |
request |
Corps JSON de la requête brute qui a été envoyée au point de terminaison de mise en service de modèle. | STRING |
response |
Corps JSON de réponse brute retourné par le point de terminaison de mise en service de modèle. | STRING |
served_entity_id |
L’ID unique de l’entité servie. | STRING |
logging_error_codes |
ARRAY | |
requester |
L’ID de l’utilisateur ou du principal de service dont les autorisations sont utilisées pour la demande d’appel du point de terminaison de service. | STRING |
Mise à jour des fonctionnalités d’AI Gateway sur les points de terminaison
Vous pouvez mettre à jour les fonctionnalités d’AI Gateway sur les points de terminaison de service de modèle qui les avaient précédemment activées et les points de terminaison qui ne les avaient pas activées. Les mises à jour des configurations d’AI Gateway prennent environ 20 à 40 secondes, mais les mises à jour de limitation de débit peuvent prendre jusqu’à 60 secondes.
La rubrique suivante indique comment mettre à jour les fonctionnalités d’AI Gateway sur un point de terminaison de service de modèle à l’aide de l’interface utilisateur de service.
Dans la section Gateway page de point de terminaison, vous pouvez voir quelles fonctionnalités sont activées. Pour mettre à jour ces fonctionnalités, cliquez sur Modifier AI Gateway.

Exemple de Bloc-notes
Le bloc-notes suivant montre comment activer et utiliser par programmation les fonctionnalités de la Databricks Mosaic AI Gateway pour gérer et régir des modèles provenant de fournisseurs. Pour plus d’informations sur l’API REST, consultez les rubriques suivantes :