Explorer et créer des tables dans DBFS
Important
Cette documentation a été mise hors service et peut ne pas être mise à jour. Les produits, services ou technologies mentionnés dans ce contenu ne sont plus pris en charge. Consultez Télécharger des fichiers vers Azure Databricks, Créer ou modifier une table à l'aide du téléchargement de fichiers, et Qu'est-ce que Catalog Explorer ?.
Accédez à l’interface de création interface utilisateur d’ajout de données. Cliquez sur ![]() Nouveau > Données > DBFS.
Nouveau > Données > DBFS.
Vous pouvez également accéder à l'interface utilisateur à partir des blocs-notes en cliquant sur Fichier > Ajouter des données.
Databricks recommande d'utiliser Catalog Explorer pour une expérience améliorée d'affichage des objets de données et de gestion des ACL, ainsi que de la page Créer ou modifier une table à partir du téléchargement de fichiers pour ingérer facilement de petits fichiers dans Delta Lake.
Remarque
La disponibilité de certains éléments décrits dans cet article varie en fonction des configurations de l’espace de travail. Contactez votre administrateur d’espace de travail ou l’équipe de compte Azure Databricks.
Importer des données
Si vous avez de petits fichiers de données sur votre ordinateur local que vous souhaitez analyser avec Azure Databricks, vous pouvez les importer dans DBFS à l’aide de l’interface utilisateur.
Remarque
Les administrateurs de l’espace de travail peuvent désactiver cette fonctionnalité. Pour plus d’informations, consultez Gérer le chargement de données.
Créez une table
Vous pouvez lancer l'interface utilisateur de création de table DBFS en cliquant sur ![]() Nouveau dans la barre latérale ou sur le bouton DBFS dans l'interface utilisateur d'ajout de données. Vous pouvez remplir un tableau à partir de fichiers dans DBFS ou charger des fichiers.
Nouveau dans la barre latérale ou sur le bouton DBFS dans l'interface utilisateur d'ajout de données. Vous pouvez remplir un tableau à partir de fichiers dans DBFS ou charger des fichiers.
L’interface utilisateur vous permet de créer uniquement des tables externes.
Choisissez une source de données et suivez les étapes décrites dans la section correspondante pour configurer la table.
Si un administrateur d’espace de travail d’Azure Databricks a désactivé l’option Charger un fichier, vous ne pouvez pas charger de fichiers. Vous pouvez créer des tables à l’aide de l’une des autres sources de données.
Instructions pour charger un fichier
- Faites glisser des fichiers vers la zone de dépôt Fichiers ou cliquez sur celle-ci pour parcourir et sélectionner des fichiers. Après le chargement, un chemin d’accès s’affiche pour chaque fichier. Le chemin d’accès ressemblera à
/FileStore/tables/<filename>-<integer>.<file-type>. Vous pouvez utiliser ce chemin d’accès dans un notebook pour lire des données. - Cliquez sur Créer une table avec l’interface utilisateur.
- Dans la liste déroulante Cluster, choisissez un cluster.
Instructions pour DBFS
- Sélectionnez un fichier.
- Cliquez sur Créer une table avec l’interface utilisateur.
- Dans la liste déroulante Cluster, choisissez un cluster.
- Faites glisser des fichiers vers la zone de dépôt Fichiers ou cliquez sur celle-ci pour parcourir et sélectionner des fichiers. Après le chargement, un chemin d’accès s’affiche pour chaque fichier. Le chemin d’accès ressemblera à
Cliquez sur Aperçu de la table pour afficher la table.
Dans le champ Nom de la table, remplacez éventuellement le nom de la table par défaut. Un nom de table ne peut contenir que des caractères alphanumériques minuscules et des traits de soulignement, et doit commencer par une lettre minuscule ou un trait de soulignement.
Dans le champ Créer dans une base de données, remplacez éventuellement la base de données sélectionnée
default.Dans le champ Type de fichier, remplacez éventuellement le type de fichier inféré.
Si le type de fichier est CSV :
- Dans le champ Délimiteur de colonne, indiquez si vous souhaitez remplacer le délimiteur inféré.
- Indiquez si la première ligne doit être utilisée pour créer les titres de colonnes.
- Indiquez s’il faut inférer le schéma.
Si le type de fichier est JSON, indiquez si le fichier est multiligne.
Cliquez sur Créer une table.
Afficher des bases de données et des tables
Remarque
Les espaces de travail avec l'Explorateur de catalogue activé n'ont pas accès au comportement hérité décrit ci-dessous.
Dans la barre latérale, cliquez sur ![]() Catalogue. Azure Databricks sélectionne un cluster en cours d’exécution auquel vous avez accès. Le dossier Bases de données affiche la liste des bases de données avec la base de données
Catalogue. Azure Databricks sélectionne un cluster en cours d’exécution auquel vous avez accès. Le dossier Bases de données affiche la liste des bases de données avec la base de données default sélectionnée. Le dossier Tables affiche la liste des tables dans la base de données default.
Vous pouvez modifier le cluster à partir du menu Bases de données, de l’interface utilisateur de création de table ou de l’interface utilisateur d’affichage de table. Par exemple, dans le menu Bases de données :
Cliquez sur la
 flèche vers le bas en haut du dossier Bases de données.
flèche vers le bas en haut du dossier Bases de données.Sélectionnez un cluster.
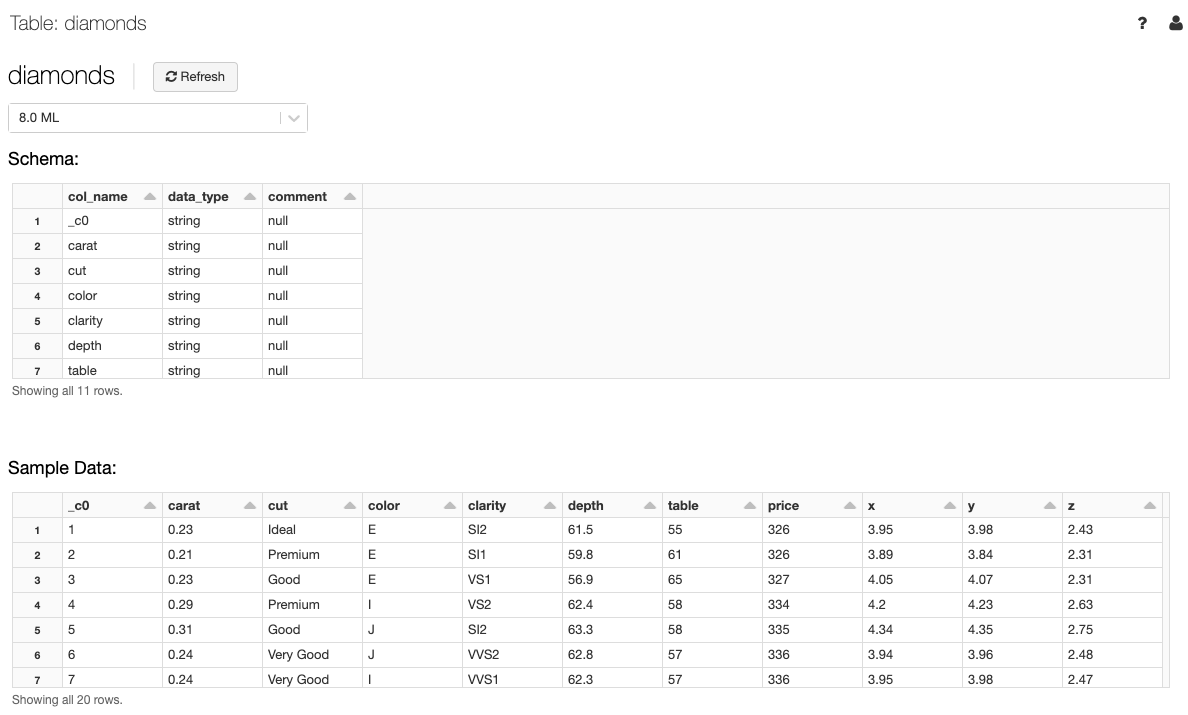
Afficher les détails de la table
L’affichage des détails de la table présente le schéma de la table et un échantillon de données.
Dans la barre latérale, cliquez sur
 Catalogue.
Catalogue.Dans le dossier Bases de données, cliquez sur une base de données.
Dans le dossier Tables, cliquez sur le nom de la table.
Dans la liste déroulante cluster, sélectionnez éventuellement un autre cluster pour afficher l’aperçu de la table.
Remarque
Pour afficher l’aperçu de la table, une requête Spark SQL s’exécute sur le cluster sélectionné dans la liste déroulante Cluster. Si une charge de travail est déjà en cours d’exécution sur le cluster, le chargement de l’aperçu de la table peut prendre plus de temps.
Supprimer une table à l’aide de l’interface utilisateur
- Dans la barre latérale, cliquez sur Catalogue.
- Cliquez sur
 à côté du nom de la table et sélectionnez Supprimer.
à côté du nom de la table et sélectionnez Supprimer.