Calcul serverless pour les notebooks
Cet article explique comment utiliser le calcul serverless pour les notebooks. Pour plus d’informations sur l’utilisation du calcul serverless pour les travaux, consultez Exécuter votre travail Azure Databricks avec un calcul serverless pour les flux de travail.
Pour plus d’informations, consultez les tarifs de Databricks.
Spécifications
- Vous devez activer votre espace de travail pour Unity Catalog.
- Votre espace de travail doit se trouver dans une région prise en charge. Voir les régions Azure Databricks.
- Votre compte doit être activé pour le calcul serverless. Voir Activer le calcul serverless.
Attacher un notebook à un calcul serverless
Si votre espace de travail est configuré pour prendre en charge le calcul serverless interactif, toutes les personnes qui l’utilisent ont accès au calcul serverless pour les notebooks. Aucune autorisation supplémentaire n’est nécessaire.
Pour effectuer un attachement au calcul serverless, cliquez sur le menu déroulant Se connecter dans le notebook, puis sélectionnez Serverless. Pour les nouveaux notebooks, le calcul attaché passe automatiquement par défaut au mode serverless au moment de l’exécution du code, si aucune autre ressource n’a été sélectionnée.
Sélectionner une stratégie de budget pour votre utilisation serverless
Important
Cette fonctionnalité est disponible en préversion publique.
Les stratégies budgétaires permettent à votre organisation d’appliquer des étiquettes personnalisées sur l’utilisation serverless pour une attribution granulaire de facturation.
Si votre espace de travail utilise des stratégies budgétaires pour attribuer l’utilisation serverless, vous pouvez sélectionner la stratégie de budget que vous souhaitez appliquer au notebook. Si elle n’est affectée qu’à une seule stratégie budgétaire, cette stratégie sera sélectionnée par défaut.
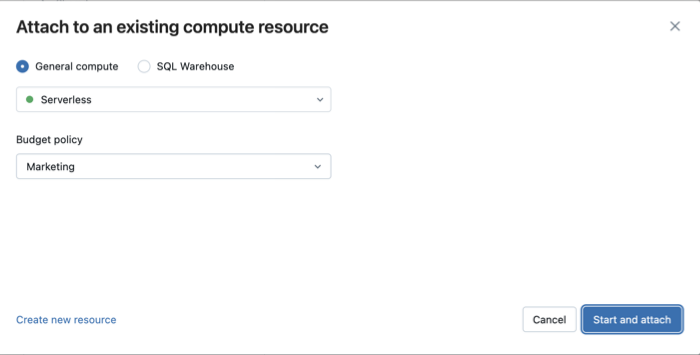
Pour sélectionner la stratégie de budget avant de vous connecter au calcul serverless :
- Dans l’interface utilisateur du bloc-notes, cliquez sur la liste déroulante Se connecter .
- Cliquez sur Plus...
- Sélectionnez Serverless , puis sélectionnez la stratégie Budget.
- Cliquez sur Démarrer et attacher.
Vous pouvez sélectionner la stratégie de budget une fois que votre bloc-notes est connecté au calcul serverless à l’aide du panneau latéral Environnement :
- Dans l’interface utilisateur du bloc-notes, cliquez sur le panneau
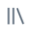 latéral Environnement .
latéral Environnement . - Sous Stratégie budgétaire , sélectionnez la stratégie budgétaire que vous souhaitez appliquer à votre bloc-notes.
- Cliquez sur Appliquer.
À partir de ce stade, toutes les utilisations de votre bloc-notes héritent des balises personnalisées de la stratégie budgétaire.
Remarque
Si votre bloc-notes provient d’un référentiel Git ou n’a pas de stratégie de budget affectée, il est défini par défaut sur votre dernière stratégie de budget choisie la prochaine fois qu’elle est attachée au calcul serverless.
Voir les insights de requête
Le calcul serverless pour les notebooks et les travaux utilise des insights de requête pour évaluer les performances d’exécution de Spark. Après avoir exécuté une cellule dans un notebook, vous pouvez voir les insights liés aux requêtes SQL et Python en cliquant sur le lien Voir les performances.
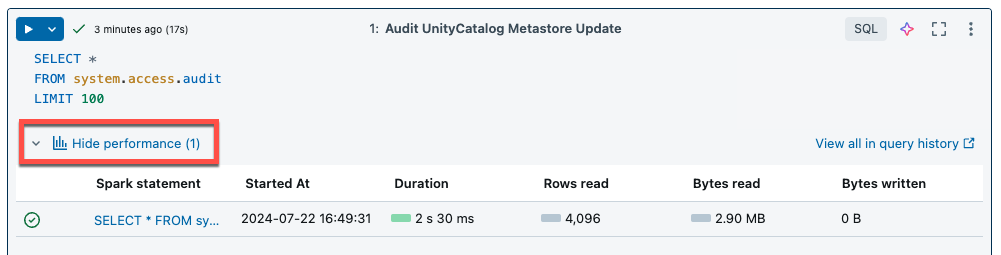
Vous pouvez cliquer sur l’une des instructions Spark pour voir les métriques de requête. Vous pouvez ensuite cliquer sur Voir le profil de requête pour visualiser l’exécution de la requête. Pour plus d’informations sur les profils de requête, consultez Profil de requête.
Remarque
Pour afficher les insights sur les performances de vos exécutions de travail, consultez Afficher les insights de requête d’exécution de travail.
Historique des requêtes
Toutes les requêtes exécutées dans le cadre du calcul serverless sont également enregistrées dans la page d’historique des requêtes de votre espace de travail. Pour plus d’informations sur l’historique des requêtes, consultez Historique des requêtes.
Limitations des insights de requête
- Le profil de requête est disponible uniquement à la fin de l’exécution de la requête.
- Les métriques sont mises à jour en temps réel, même si le profil de requête ne s’affiche pas durant l’exécution.
- Seuls les états de requête suivants sont couverts : RUNNING, CANCELED, FAILED, FINISHED.
- Les requêtes en cours d’exécution ne peuvent pas être annulées à partir de la page d’historique des requêtes. Elles peuvent être annulées dans les notebooks ou les travaux.
- Les métriques détaillées ne sont pas disponibles.
- Le téléchargement du profil de requête n’est pas disponible.
- L’accès à l’IU de Spark n’est pas disponible.
- Le texte de l’instruction contient uniquement la dernière ligne exécutée. Toutefois, plusieurs lignes précédant cette ligne ont peut-être été exécutées dans le cadre de la même instruction.