Configurer Delta Lake pour contrôler la taille du fichier de données
Remarque
Les suggestions de cet article ne s’appliquent pas aux tables managées d’Unity Catalog. Databricks recommande d’utiliser les tables managées d’Unity Catalog avec des paramètres par défaut pour toutes les nouvelles tables Delta.
Dans Databricks Runtime 13.3 et versions ultérieures, nous recommandons d’utiliser le clustering pour la disposition du tableau Delta. Consultez Utilisation des clustering liquides pour les tableaux Delta.
Databricks recommande d’utiliser l’optimisation prédictive afin d’exécuter automatiquement OPTIMIZE et VACUUM pour les tables Delta. Consultez Optimisation prédictive pour les tables managées Unity Catalog.
Dans Databricks Runtime 10.4 LTS et versions ultérieures, le compactage automatique et les écritures optimisées sont toujours activés pour les opérations MERGE, UPDATEet DELETE. Vous ne pouvez pas désactiver cette fonctionnalité.
Delta Lake fournit des options permettant de configurer manuellement ou automatiquement la taille du fichier cible pour les écritures et les opérations OPTIMIZE. Azure Databricks règle automatiquement la plupart de ces paramètres et active des fonctionnalités qui améliorent automatiquement les performances des tables en cherchant à dimensionner correctement les fichiers.
Pour les tables managées Unity Catalog, Databricks règle automatiquement la plupart de ces configurations si vous utilisez un entrepôt SQL ou Databricks Runtime 11.3 LTS ou une version ultérieure.
Si vous mettez à niveau une charge de travail à partir de Databricks Runtime 10.4 LTS ou version antérieure, consultez Mise à niveau vers un compactage automatique en arrière-plan.
Motif de l’exécution de OPTIMIZE
Le compactage automatique et les écritures optimisées réduisent chacun les problèmes de petits fichiers, mais ne sont pas un remplacement complet pour OPTIMIZE. En particulier pour les tables supérieures à 1 To, Databricks recommande d’exécuter OPTIMIZE selon une planification pour consolider davantage les fichiers. Azure Databricks n’exécute pas automatiquement ZORDER sur les tables. Vous devez donc exécuter OPTIMIZE avec ZORDER pour activer le saut de données amélioré. Consultez Saut de données pour Delta Lake.
Qu’est-ce que l’optimisation automatique sur Azure Databricks ?
Le terme optimisation automatique est parfois utilisé pour décrire les fonctionnalités contrôlées par les paramètres delta.autoOptimize.autoCompact et delta.autoOptimize.optimizeWrite. Ce terme a été supprimé au profit de la description de chaque paramètre individuellement. Consultez Compactage automatique pour Delta Lake sur Azure Databricks et Écritures optimisées pour Delta Lake sur Azure Databricks.
Compactage automatique pour Delta Lake sur Azure Databricks
Le compactage automatique combine les petits fichiers dans les partitions de table Delta pour réduire automatiquement les problèmes de petits fichiers. La compression automatique se produit après la réussite d’une écriture dans une table et s’exécute de façon synchrone sur le cluster qui a effectué l’écriture. Le compactage automatique ne compacte que les fichiers qui n’ont pas été compactés précédemment.
Vous pouvez contrôler la taille du fichier de sortie en définissant la configuration Spark spark.databricks.delta.autoCompact.maxFileSize. Databricks recommande d’utiliser la fonctionnalité de réglage automatique en fonction de la taille de la charge de travail ou de la table. Consultez Ajuster automatiquement la taille des fichiers en fonction de la charge de travail et Ajuster automatiquement la taille des fichiers en fonction de la taille de la table.
Le compactage automatique est déclenché uniquement pour les partitions ou les tables qui ont au moins un certain nombre de petits fichiers. Vous pouvez éventuellement modifier le nombre minimal de fichiers requis pour déclencher le compactage automatique en définissant spark.databricks.delta.autoCompact.minNumFiles.
Le compactage automatique peut être activé au niveau de la table ou de la session à l’aide des paramètres suivants :
- Propriété de table :
delta.autoOptimize.autoCompact - Paramètre SparkSession :
spark.databricks.delta.autoCompact.enabled
Ces paramètres acceptent les options suivantes :
| Options | Comportement |
|---|---|
auto (recommandé) |
Ajuste la taille du fichier cible tout en respectant d’autres fonctionnalités de réglage automatique. Requiert Databricks Runtime 10.4 LTS ou version ultérieure. |
legacy |
Alias de true. Requiert Databricks Runtime 10.4 LTS ou version ultérieure. |
true |
Utilisez 128 Mo comme taille de fichier cible. Aucun dimensionnement dynamique. |
false |
Désactive le compactage automatique. Peut être défini au niveau de la session pour remplacer le compactage automatique pour toutes les tables Delta modifiées dans la charge de travail. |
Important
Dans Databricks Runtime 9.1 LTS, lorsque d’autres enregistreurs effectuent des opérations telles que DELETE, MERGE, UPDATE ou OPTIMIZE simultanément, le compactage automatique peut entraîner l’échec de ces autres travaux avec un conflit de transaction. Ce n’est pas un problème dans Databricks Runtime 10.4 LTS et versions ultérieures.
Écritures optimisées pour Delta Lake sur Azure Databricks
Les écritures optimisées améliorent la taille du fichier à mesure que les données sont écrites, ce qui profite aux lectures ultérieures sur la table.
Les écritures optimisées sont les plus efficaces pour les tables partitionnées, car elles réduisent le nombre de petits fichiers écrits sur chaque partition. Écrire moins de fichiers volumineux est plus efficace que l’écriture de nombreux petits fichiers, mais vous pouvez toujours voir une augmentation de la latence d’écriture, car les données sont mélangées avant d’être écrites.
L’image suivante montre comment fonctionnent les écritures optimisées :
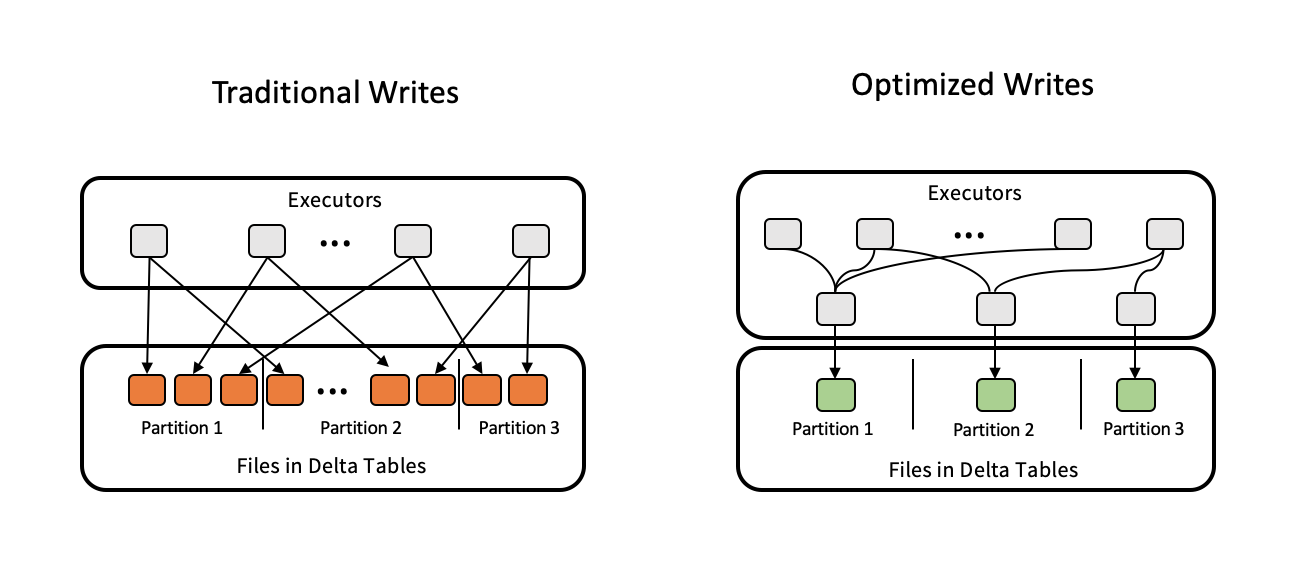
Remarque
Vous avez peut-être du code qui exécute coalesce(n) ou repartition(n) juste avant d’écrire vos données pour contrôler le nombre de fichiers écrits. Les écritures optimisées éliminent la nécessité d’utiliser ce modèle.
Les écritures optimisées sont activées par défaut pour les opérations suivantes dans Databricks Runtime 9.1 LTS et versions ultérieures :
MERGEUPDATEavec des sous-requêtesDELETEavec des sous-requêtes
Les écritures optimisées sont également activées pour les instructions CTAS et les opérations INSERT lors de l’utilisation d’entrepôts SQL. Dans Databricks Runtime 13.3 LTS et versions ultérieures, toutes les tables Delta enregistrées dans Unity Catalog ont des écritures optimisées activées pour les instructions CTAS et les opérations INSERT pour les tables partitionnées.
Les écritures optimisées peuvent être activées au niveau de la table ou de la session à l’aide des paramètres suivants :
- Paramètre de table :
delta.autoOptimize.optimizeWrite - Paramètre SparkSession :
spark.databricks.delta.optimizeWrite.enabled
Ces paramètres acceptent les options suivantes :
| Options | Comportement |
|---|---|
true |
Utilisez 128 Mo comme taille de fichier cible. |
false |
Désactive les écritures optimisées. Peut être défini au niveau de la session pour remplacer le compactage automatique pour toutes les tables Delta modifiées dans la charge de travail. |
Définir la taille d’un fichier cible
Si vous souhaitez ajuster la taille des fichiers dans votre table Delta, définissez la propriété de table delta.targetFileSize sur la taille souhaitée. Si cette propriété est définie, toutes les opérations d’optimisation de la disposition des données feront de leur mieux pour générer des fichiers de la taille spécifiée. Les exemples incluent l’optimisation ou l’ordre de plan, le compactage automatique et les écritures optimisées.
Notes
Lorsque vous utilisez des tables managées Unity Catalog et des entrepôts SQL ou Databricks Runtime 11.3 LTS et versions ultérieures, seules les commandes OPTIMIZE respectent le paramètre targetFileSize.
| Propriété de tablea |
|---|
| delta.targetFileSize Type : taille en octets ou unités supérieures. Taille du fichier cible. Par exemple, 104857600 (octets) ou 100mb.Valeur par défaut : aucune |
pour les tables existantes, vous pouvez définir et annuler des propriétés à l’aide de la commande SQL ALTER TABLE SET TBL PROPERTIES. Vous pouvez également définir ces propriétés automatiquement lors de la création de tables à l’aide de configurations de session Spark. Pour plus d’informations, consultez Référence sur les propriétés de table Delta.
Dimensionner automatiquement la taille du fichier en fonction de la charge de travail
Databricks recommande de définir la propriété de table delta.tuneFileSizesForRewrites sur true pour toutes les tables ciblées par de nombreuses opérations MERGE ou DML, indépendamment de Databricks Runtime, Unity Catalog ou d’autres optimisations. Lorsque la valeur est définie sur true, la taille de fichier cible de la table est définie sur un seuil beaucoup plus bas, ce qui accélère les opérations nécessitant beaucoup d’écriture.
S’il n’est pas défini explicitement, Azure Databricks détecte automatiquement si 9 des 10 dernières opérations précédentes sur une table Delta étaient des opérations MERGE et définit cette propriété de table sur true. Vous devez définir explicitement cette propriété sur false pour éviter ce comportement.
| Propriété de tablea |
|---|
| delta.tuneFileSizesForRewrites Entrez : BooleanIndique si les tailles de fichier doivent être ajustées pour l’optimisation de la disposition des données. Valeur par défaut : aucune |
pour les tables existantes, vous pouvez définir et annuler des propriétés à l’aide de la commande SQL ALTER TABLE SET TBL PROPERTIES. Vous pouvez également définir ces propriétés automatiquement lors de la création de tables à l’aide de configurations de session Spark. Pour plus d’informations, consultez Référence sur les propriétés de table Delta.
Dimensionner automatiquement la taille du fichier en fonction de la taille de la table
Pour réduire le besoin de paramétrage manuel, Azure Databricks ajuste automatiquement la taille de fichier des tables différentielles en fonction de la taille de la table. Azure Databricks utilisera des fichiers de plus petite taille pour les tables plus petites et des tailles de fichier supérieures pour les tables plus volumineuses afin que le nombre de fichiers dans la table ne devienne pas trop important. Azure Databricks n’autotune pas les tables que vous avez paramétrées avec une taille cible spécifique ou sur la base d’une charge de travail avec des réécritures fréquentes.
La taille du fichier cible est basée sur la taille actuelle de la table Delta. Pour les tables inférieures à 2,56 To, la taille du fichier cible réglé automatiquement est de 256 Mo. Pour les tables dont la taille est comprise entre 2,56 To et 10 To, la taille cible augmente de façon linéaire de 256 Mo à 1 Go. Pour les tables de plus de 10 To, la taille du fichier cible est de 1 Go.
Notes
Lorsque la taille du fichier cible d’une table augmente, les fichiers existants ne sont pas réoptimisés dans des fichiers plus volumineux par la commande OPTIMIZE. Une table de grande taille peut donc toujours avoir des fichiers dont la taille est inférieure à celle de la cible. S’il est nécessaire d’optimiser ces fichiers plus petits dans des fichiers plus volumineux, vous pouvez configurer une taille de fichier cible fixe pour la table à l’aide de la propriété de table delta.targetFileSize.
Quand une table est écrite de façon incrémentielle, les tailles des fichiers cibles et le nombre de fichiers sont proches des chiffres suivants, en fonction de la taille de la table. Le nombre de fichiers dans ce tableau n’est qu’un exemple. Les résultats réels seront différents en fonction de nombreux facteurs.
| Taille de la table | Taille du fichier cible | Nombre approximatif de fichiers dans la table |
|---|---|---|
| 10 Go | 256 octets | 40 |
| 1 To | 256 octets | 4096 |
| 2,56 To | 256 octets | 10240 |
| 3 To | 307 Mo | 12108 |
| 5 To | 512 MO | 17339 |
| 7 To | 716 Mo | 20784 |
| 10 To | 1 Go | 24437 |
| 20 To | 1 Go | 34437 |
| 50 To | 1 Go | 64437 |
| 100 To | 1 Go | 114437 |
Limiter les lignes écrites dans un fichier de données
Les tables avec des données étroites peuvent parfois rencontrer une erreur lorsque le nombre de lignes dans un fichier de données spécifique dépasse les limites de prise en charge du format Parquet. Pour éviter cette erreur, vous pouvez utiliser la configuration spark.sql.files.maxRecordsPerFile de session SQL pour spécifier le nombre maximal d’enregistrements à écrire dans un fichier unique pour une table Delta Lake. La spécification d’une valeur égale à zéro ou d’une valeur négative représente aucune limite.
Dans Databricks Runtime 11.3 LTS et versions ultérieures, vous pouvez également utiliser l’option maxRecordsPerFile de DataFrameWriter lors de l’utilisation des API DataFrame pour écrire dans une table Delta Lake. Quand maxRecordsPerFile est spécifié, la valeur de la configuration de session SQL spark.sql.files.maxRecordsPerFile est ignorée.
Notes
Databricks ne recommande pas d’utiliser cette option, sauf si cela est nécessaire pour éviter l’erreur ci-dessus. Ce paramètre peut toujours être nécessaire pour certaines tables gérées Unity Catalog avec des données très étroites.
Mise à niveau vers le compactage automatique en arrière-plan
Le compactage automatique en arrière-plan est disponible pour les tables managées du catalogue Unity dans Databricks Runtime 11.3 LTS et versions ultérieures. Lors de la migration d’une charge de travail ou d’une table héritée, procédez ainsi :
- Supprimez le
spark.databricks.delta.autoCompact.enabledde configuration Spark des paramètres de configuration de cluster ou de notebook. - Pour chaque table, exécutez
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)pour supprimer les paramètres de compactage automatique hérités.
Après avoir supprimé ces configurations héritées, vous devriez constater une compaction automatique en arrière-plan déclenchée automatiquement pour toutes les tables managées du catalogue Unity.