Créer un agent IA
Important
Cette fonctionnalité est disponible en préversion publique.
Cet article vous montre comment créer un agent IA appelant des outils à l’aide de l’infrastructure de l’agent d’ia mosaïque.
Découvrez comment donner à un agent des outils et commencer à discuter avec eux pour tester et prototyper l’agent. Une fois que vous avez terminé le prototypage de l’agent, exportez le code Python qui définit l’agent pour itérer et déployer votre agent IA.
Spécifications
- Comprendre les concepts des agents et des outils d’IA, tels que décrits dans Qu’est-ce que le système IA composé et les agents IA ?
- Databricks recommande d’installer la dernière version du client MLflow Python lors du développement d’agents. Pour des d’informations sur les exigences de version de
mlflow, consultez Authentification pour les ressources dépendantes.
Créer des outils d’agent IA
La première étape consiste à créer un outil à donner à votre agent. Les agents utilisent des outils pour effectuer des actions en plus de la génération de langage, par exemple pour récupérer des données structurées ou non structurées, exécuter du code ou communiquer avec des services distants (par exemple, envoyer un e-mail ou un message Slack).
Pour en savoir plus sur la création d’outils d’agent, consultez Créer des outils d’agent IA.
Pour ce guide, créez une fonction de catalogue Unity qui exécute du code Python. Un agent peut utiliser cet outil pour exécuter Python donné par un utilisateur ou écrit par l’agent lui-même.
Exécutez le code suivant dans une cellule notebook. Il utilise la commande magique %sql de notebook pour créer une fonction Unity Catalog appelée python_exec.
%sql
CREATE OR REPLACE FUNCTION
main.default.python_exec (
code STRING COMMENT 'Python code to execute. Remember to print the final result to stdout.'
)
RETURNS STRING
LANGUAGE PYTHON
DETERMINISTIC
COMMENT 'Executes Python code in the sandboxed environment and returns its stdout. The runtime is stateless and you can not read output of the previous tool executions. i.e. No such variables "rows", "observation" defined. Calling another tool inside a Python code is NOT allowed. Use standard python libraries only.'
AS $$
import sys
from io import StringIO
sys_stdout = sys.stdout
redirected_output = StringIO()
sys.stdout = redirected_output
exec(code)
sys.stdout = sys_stdout
return redirected_output.getvalue()
$$
Prototypage d’agents appelant des outils dans AI Playground
Après avoir créé la fonction Catalogue Unity, utilisez ai Playground pour donner à l’outil un LLM et tester l’agent. AI Playground fournit un bac à sable pour prototyper des agents appelant des outils.
Une fois que vous êtes satisfait de l’agent IA, vous pouvez l’exporter pour le développer davantage en Python ou le déployer tel quel en tant que point de terminaison Model Serving.
Remarque
Unity Catalog et le calcul serverless, Mosaic AI Agent Framework, et soit les modèles de fondation avec paiement par jeton ou les modèles externes doivent être disponibles dans l’espace de travail actuel pour prototyper des agents dans AI Playground.
Pour prototyper un point de terminaison appelant des outils.
Dans Playground, sélectionnez un modèle avec l’étiquette Outils activée .
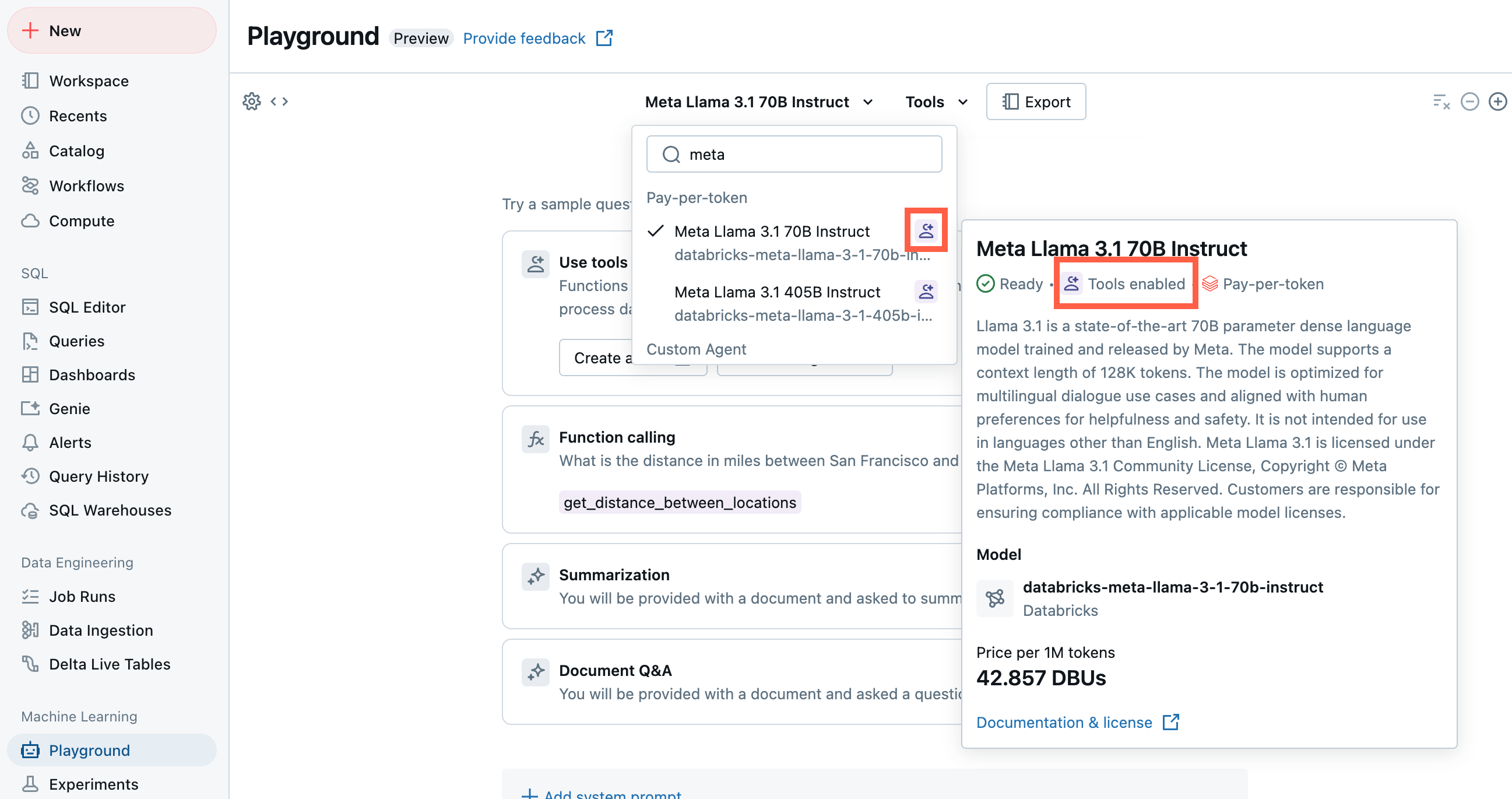
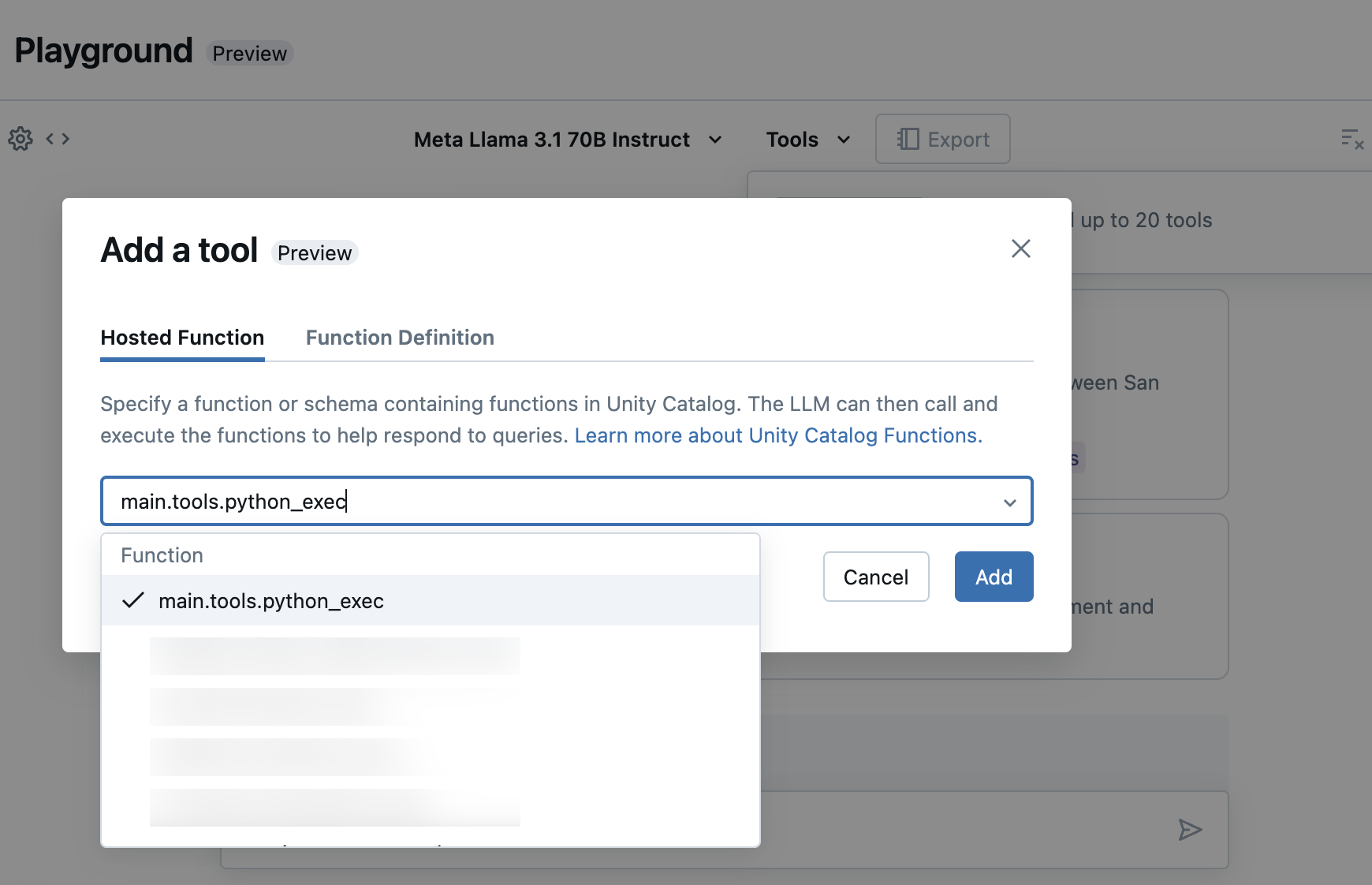
Sélectionnez Outils et spécifiez les noms de votre fonction Unity Catalog dans la liste déroulante :
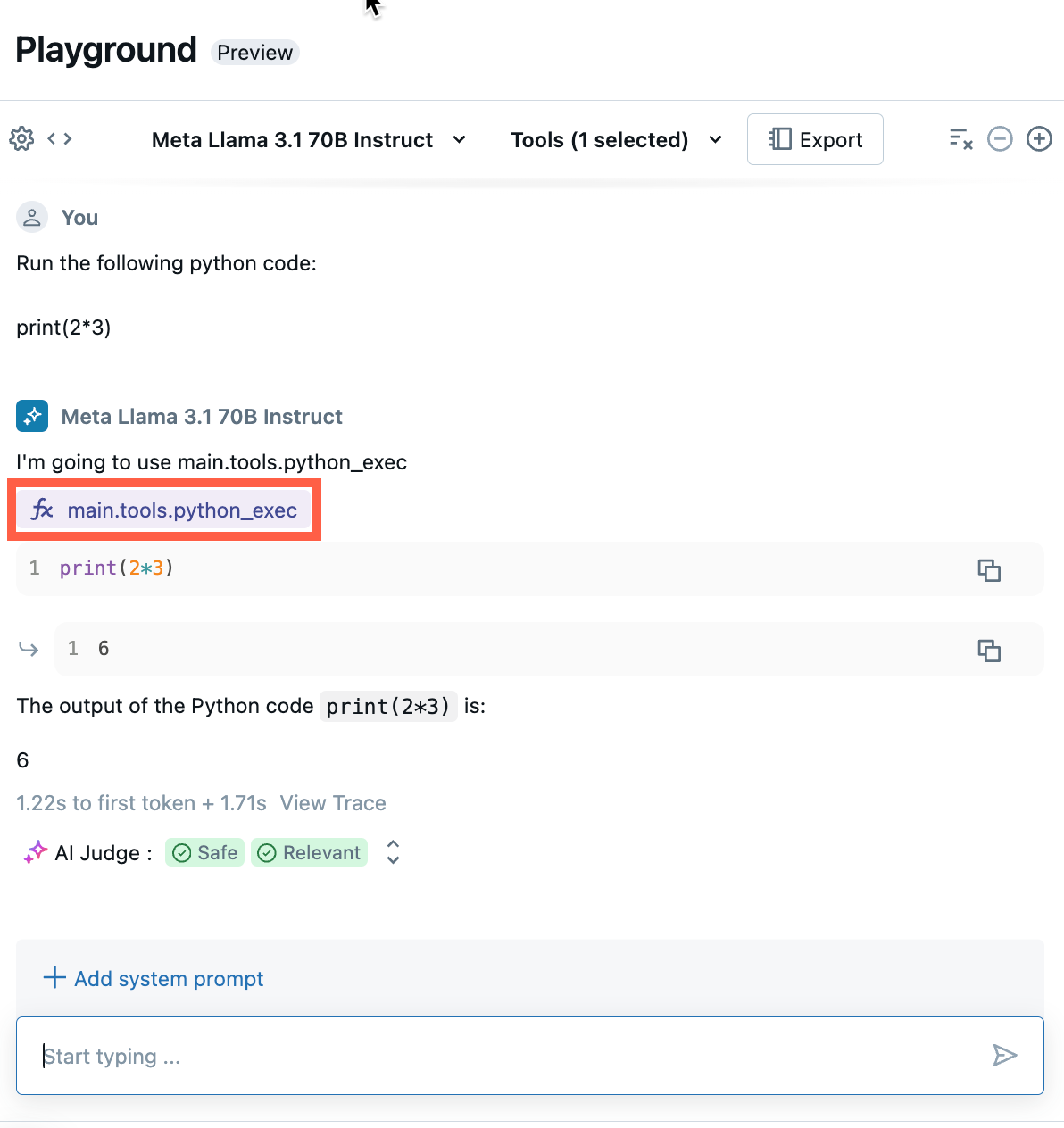
Discutez pour tester la combinaison actuelle de LLM, d’outils et d’invite du système, et essayez des variantes.
Exportez et déployez des agents AI Playground
Après avoir ajouté des outils et testé l’agent, exportez l’agent Playground vers des notebooks Python :
Cliquez sur Exporter pour générer des notebooks Python qui vous aident à développer et déployer l’agent IA.
Après avoir exporté le code de l’agent, vous pouvez constater que trois fichiers sont enregistrés dans votre espace de travail :
agentnotebook : contient du code Python définissant votre agent à l’aide de LangChain.drivernotebook : contient du code Python pour journaliser, suivre, inscrire et déployer l’agent IA à l’aide de Mosaic AI Agent Framework.config.yml: contient des informations de configuration sur votre agent, y compris les définitions d’outils.
Ouvrez le bloc-notes
agentpour voir le code LangChain définissant votre agent, utilisez ce notebook pour tester et itérer sur l’agent par programmation, par exemple définir plus d’outils ou ajuster les paramètres de l’agent.Remarque
Le code exporté peut avoir un comportement différent de votre session de IA Playground. Databricks recommande d’exécuter les notebooks exportés pour itérer et déboguer davantage, évaluer la qualité de l’agent, puis déployer l’agent pour partager avec d’autres personnes.
Une fois que vous êtes satisfait des résultats de l’agent, vous pouvez exécuter le notebook
driverpour journaliser et déployer votre agent sur un point de terminaison Model Serving.
Définir un agent dans le code
En plus de générer du code d’agent à partir d’AI Playground, vous pouvez également définir un agent dans le code vous-même, à l’aide de frameworks tels que LangChain ou du code Python. Pour déployer un agent à l’aide d’Agent Framework, son entrée doit être conforme à l’un des formats d’entrée et de sortie pris en charge.
Utiliser des paramètres pour configurer l’agent
Dans Agent Framework, vous pouvez utiliser des paramètres pour contrôler la façon dont les agents sont exécutés. Cela vous permet d’itérer rapidement en modifiant les caractéristiques de votre agent sans modifier le code. Les paramètres sont des paires clé-valeur que vous définissez dans un dictionnaire Python ou un fichier .yaml.
Pour configurer le code, créez un ModelConfig, un ensemble de paramètres clé-valeur. ModelConfig est un dictionnaire Python ou un fichier .yaml. Par exemple, vous pouvez utiliser un dictionnaire pendant le développement, puis le convertir en fichier .yaml pour le déploiement de production et CI/CD. Pour plus d’informations sur ModelConfig, consultez la documentation MLflow.
Voici un exemple de ModelConfig.
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-dbrx-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
Pour appeler la configuration à partir de votre code, utilisez l’une des options suivantes :
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-dbrx-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
value = model_config.get('sample_param')
Définir le schéma du récupérateur
Les agents IA utilisent souvent des récupérateurs, un type d’outil d’agent qui recherche et retourne des documents pertinents à l’aide d’un index recherche vectorielle. Pour plus d’informations sur les récupérateurs, consultez Créer un outil de récupération de recherche vectorielle.
Pour vous assurer que les récupérateurs sont correctement suivis, appelez mlflow.models.set_retriever_schema lorsque vous définissez votre agent dans le code. Permet set_retriever_schema de mapper les noms de colonnes dans la table retournée aux champs attendus de MLflow tels que primary_key, text_columnet doc_uri.
# Define the retriever's schema by providing your column names
# These strings should be read from a config dictionary
mlflow.models.set_retriever_schema(
name="vector_search",
primary_key="chunk_id",
text_column="text_column",
doc_uri="doc_uri"
# other_columns=["column1", "column2"],
)
Remarque
La doc_uri colonne est particulièrement importante lors de l’évaluation des performances du récupérateur. doc_uri est l’identificateur principal des documents retournés par le récupérateur, ce qui vous permet de les comparer aux jeux d’évaluation de la vérité de base. Consultez les jeux d’évaluation
Vous pouvez également spécifier des colonnes supplémentaires dans le schéma de votre récupérateur en fournissant une liste de noms de colonnes avec le other_columns champ.
Si vous avez plusieurs récupérateurs, vous pouvez définir plusieurs schémas à l’aide de noms uniques pour chaque schéma de récupérateur.
Formats d’entrée et de sortie pris en charge
Agent Framework utilise les signatures de modèle MLflow pour définir des schémas d’entrée et de sortie pour les agents. Les fonctionnalités de Mosaïque AI Agent Framework nécessitent un ensemble minimal de champs d’entrée/sortie pour interagir avec des fonctionnalités telles que l’application de révision et le terrain de jeu IA. Pour plus d’informations, consultez Définir le schéma d’entrée et de sortie d’un agent.
Exemples de notebooks
Ces notebooks créent une chaîne simple « Hello, world » pour illustrer comment créer une application de chaîne dans Databricks. Le premier exemple crée une chaîne simple. Le deuxième exemple de notebook montre comment utiliser des paramètres pour réduire les modifications de code pendant le développement.