Chaîne RAG pour l’inférence
Cet article décrit le processus qui se produit lorsque l’utilisateur envoie une demande à l’application RAG dans un paramètre en ligne. Une fois que les données ont été traitées par le pipeline de données, elles peuvent être utilisées dans l’application RAG. La série ou la chaîne d’étapes appelées au moment de l’inférence est communément appelée chaîne RAG.
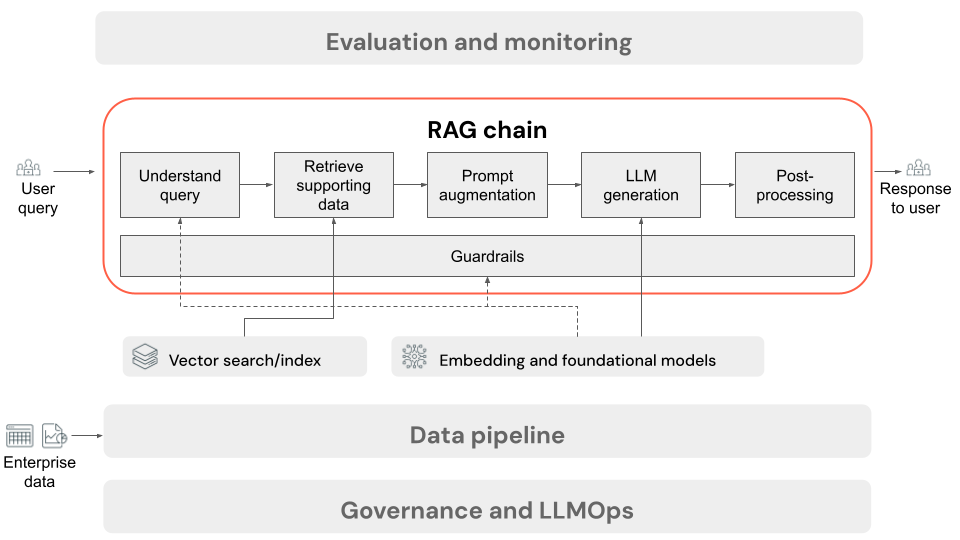
- (Facultatif) Prétraitement des requêtes utilisateur : dans certains cas, la requête de l’utilisateur est prétraitée pour la rendre plus adaptée à l’interrogation de la base de données vectorielle. Cela peut impliquer la mise en forme de la requête au sein d’un modèle, l’utilisation d’un autre modèle pour réécrire la requête ou l’extraction de mots clés pour faciliter la récupération. La sortie de cette étape est une requête de récupération qui sera utilisée dans l’étape de récupération suivante.
- Récupération : pour récupérer les informations de prise en charge de la base de données vectorielle, la requête de récupération est traduite en incorporation à l’aide du même modèle d’incorporation utilisé pour incorporer les blocs de document pendant la préparation des données. Ces incorporations permettent de comparer la similarité sémantique entre la requête de récupération et les blocs de texte non structurés, à l’aide de mesures telles que la similarité cosinus. Ensuite, les blocs sont récupérés à partir de la base de données vectorielle et classés en fonction de la façon dont ils sont similaires à la requête incorporée. Les résultats principaux (les plus similaires) sont retournés.
- Augmentation de l’invite : l’invite qui sera envoyée au LLM est formée en augmentant la requête de l’utilisateur avec le contexte récupéré, dans un modèle qui indique au modèle comment utiliser chaque composant, souvent avec des instructions supplémentaires pour contrôler le format de réponse. Le processus d’itération sur le modèle d’invite approprié à utiliser est appelé ingénierie rapide.
- Génération LLM : LLM prend l’invite augmentée, qui inclut la requête de l’utilisateur et les données de prise en charge récupérées, comme entrée. Il génère ensuite une réponse qui est fondée sur le contexte supplémentaire.
- (Facultatif) Post-traitement : la réponse des LLM peut être traitée pour appliquer une logique professionnelle supplémentaire, ajouter des citations ou affiner le texte généré sur la base de règles ou de contraintes prédéfinies
Comme avec le pipeline de données d’application RAG, il existe de nombreuses décisions d’ingénierie qui peuvent affecter la qualité de la chaîne RAG. Par exemple, déterminer le nombre de blocs à récupérer à l’étape 2 et comment les combiner avec la requête de l’utilisateur à l’étape 3 peut avoir un impact significatif sur la capacité du modèle à générer des réponses de qualité.
Tout au long de la chaîne, des différents garde-fous peuvent être appliqués tout au long de ce processus pour garantir la conformité aux stratégies d’entreprise. Il peut s’agir de filtrer les requêtes appropriées, de vérifier les autorisations des utilisateurs avant d’accéder aux sources de données et d’appliquer des techniques de modération du contenu pour les réponses générées.