Prérequis : collecter les exigences
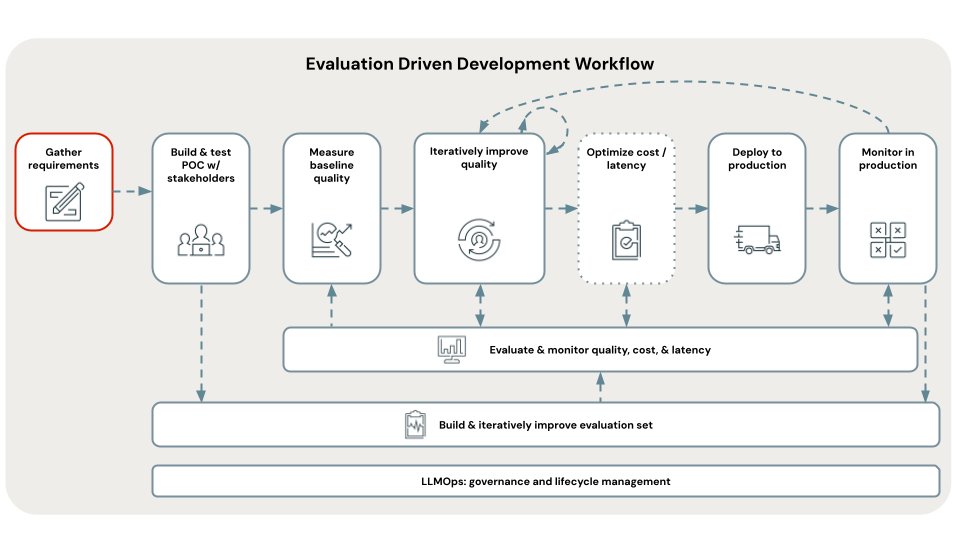
La définition d’exigences de cas d’usage claires et complètes est une première étape essentielle à la réussite du développement d’une application RAG. Ces exigences ont deux objectifs principaux. Tout d’abord, elles aident à déterminer si RAG est l’approche la plus appropriée pour le cas d’usage en question. Si RAG est en effet adapté, ces exigences guident les décisions en matière de conception, d’implémentation et d’évaluation de la solution. Investir du temps au début d’un projet en vue de recueillir les exigences détaillées peut prévenir l’apparition de défis et de revers importants plus tard dans le processus de développement, et permet de garantir que la solution résultante répond aux besoins des utilisateurs finaux et des parties prenantes. Des exigences bien définies constituent la base des phases suivantes du cycle de vie de développement que nous allons parcourir.
Consultez le dépôt GitHub pour obtenir l’exemple de code de cette section. Vous pouvez également utiliser le code du référentiel comme modèle avec lequel créer vos propres applications IA.
Le cas d’usage est-il adapté à RAG ?
La première chose que vous devez établir est de savoir si RAG est une bonne approche pour votre cas d’usage. Compte tenu de la popularité de la RAG, il est tentant de la voir comme une solution possible à tout problème. Toutefois, il existe des nuances susceptibles de révéler si la RAG convient à un cas d’usage donné.
La RAG convient dans les cas suivants :
- Raisonnement sur les informations récupérées (non structurées et structurées) qui ne s’intègrent pas entièrement dans la fenêtre de contexte du LLM
- Synthèse des informations provenant de plusieurs sources (par exemple, génération d’un résumé de points clés provenant de différents articles sur une rubrique)
- Nécessité d’une récupération dynamique basée sur une requête utilisateur (par exemple, en fonction d’une requête utilisateur, déterminer la source de données à partir de laquelle effectuer une récupération)
- Le cas d’usage nécessite de générer du nouveau contenu basé sur des informations récupérées (par exemple, répondre à des questions, fournir des explications, proposer des recommandations)
RAG peut ne pas être la meilleure solution dans les cas suivants :
- La tâche ne nécessite pas de récupération propre à la requête. Par exemple, en cas de génération de synthèse de transcription d’appel ; même si des transcriptions individuelles sont fournies en tant que contexte dans le prompt LLM, les informations récupérées restent les mêmes pour chaque synthèse.
- L’ensemble complet des informations à récupérer peut s’adapter à la fenêtre de contexte du LLM
- Des réponses à très faible latence sont requises (par exemple, lorsque des réponses sont requises en quelques millisecondes)
- Des réponses simples basées sur des règles ou sur des modèles sont suffisantes (par exemple, un chatbot de support client qui fournit des réponses prédéfinies basées sur des mots clés)
Exigences à découvrir
Une fois que vous avez établi que RAG convenait à votre cas d’usage, posez-vous les questions suivantes afin de capturer les exigences concrètes. Les exigences sont classées par ordre de priorité comme suit :
🟢 P0 : Vous devez définir cette exigence avant de commencer votre POC.
🟡 P1 : Vous devez définir cette exigence avant de basculer en production, mais vous pouvez l’affiner de façon itérative pendant la POC.
⚪ P2 : Définir cette exigence peut être bénéfique.
Cette liste de questions n’est pas exhaustive. Toutefois, elle doit fournir une base solide pour capturer les exigences clés de votre solution RAG.
Expérience utilisateur
Définissez comment les utilisateurs interagiront avec le système RAG et quel est le type de réponse attendu.
🟢 [P0] À quoi ressemblera une demande classique à la chaîne RAG ? Demandez aux parties prenantes de fournir des exemples de requêtes utilisateur potentielles.
🟢 [P0] Quel type de réponse les utilisateurs attendront-ils (réponses courtes, explications longues, une combinaison des deux, ou autre chose) ?
🟡 [P1] Comment les utilisateurs interagiront-ils avec le système ? Par le biais d’une interface de conversation, d’une barre de recherche ou d’une autre modalité ?
🟡 [P1] Quel doit être le ton ou le style des réponses générées ? (Formel, conversationnel, technique ?)
🟡 [P1] Comment l’application doit-elle gérer les requêtes ambiguës, incomplètes ou non pertinentes ? Faut-il fournir des commentaires ou des instructions dans de tels cas ?
⚪ [P2] Existe-t-il des exigences spécifiques en matière de mise en forme ou de présentation pour la sortie générée ? La sortie doit-elle inclure des métadonnées en plus de la réponse de la chaîne ?
Données
Déterminez la nature, les sources et la qualité des données qui seront utilisées dans la solution RAG.
🟢 [P0] Quelles sont les sources disponibles et utilisables ?
Pour chaque source de données :
- 🟢 [P0] Les données sont-elles structurées ou non structurées ?
- 🟢 [P0] Quel est le format source des données de récupération (par exemple, fichiers PDF, documentation avec images/tables, réponses d’API structurées) ?
- 🟢 [P0] Où résident ces données ?
- 🟢 [P0] Quelle est la quantité de données disponible ?
- 🟡 [P1] À quelle fréquence les données sont-elles mises à jour ? Comment ces mises à jour doivent-elles être gérées ?
- 🟡 [P1] Existe-t-il des problèmes ou des incohérences de qualité des données connus pour chaque source de données ?
Envisagez de créer une table d’inventaire pour consolider ces informations, par exemple :
| Source de données | Source | Type(s) de fichiers | Taille | Fréquence de mise à jour |
|---|---|---|---|---|
| Source de données 1 | Volume Unity Catalog | JSON | 10 Go | Journalier |
| Source de données 2 | API publique | XML | N/A (API) | Temps réel |
| Source de données 3 | SharePoint | PDF, .docx | 500 Mo | Mensuelle |
Contraintes de performances
Capturez les exigences en matière de performances et de ressources pour l’application RAG.
🟡 [P1] Quelle est la latence maximale acceptable pour générer les réponses ?
🟡 [P1] Quelle est la durée maximale acceptable pour le premier jeton ?
🟡 [P1] Si la sortie est diffusée en streaming, une latence totale plus élevée est-elle acceptable ?
🟡 [P1] Existe-t-il des limitations de coût sur les ressources de calcul disponibles pour l’inférence ?
🟡 [P1] Quels sont les modèles d’utilisation et les pics de charge attendus ?
🟡 [P1] Combien d’utilisateurs ou de demandes simultanés le système doit-il être en mesure de gérer ? Databricks gère en mode natif ces exigences de scalabilité, grâce à la capacité de mise à l’échelle automatiquement offerte par Model Serving.
Évaluation
Établissez comment la solution RAG sera évaluée et améliorée au fil du temps.
🟢 [P0] Quel est l’objectif métier / indicateur de performance clé que vous souhaitez impacter ? Quelle est la valeur de base de référence, et quelle est la cible ?
🟢 [P0] Quels utilisateurs ou parties prenantes fourniront des commentaires initiaux et continus ?
🟢 [P0] Quelles sont les métriques qui doivent être utilisées pour évaluer la qualité des réponses générées ? Mosaic AI Agent Evaluation fournit un ensemble recommandé de métriques à utiliser.
🟡 [P1] Quel est l’ensemble de questions sur lequel l’application RAG doit être performante pour pouvoir basculer en production ?
🟡 [P1] Existe-t-il un [jeu d’évaluation] ? Est-il possible d’obtenir un jeu d’évaluation de requêtes utilisateur, ainsi que des réponses basées sur des références et (éventuellement) les documents de prise en charge corrects qui doivent être récupérés ?
🟡 [P1] Comment les commentaires des utilisateurs seront-ils collectés et incorporés dans le système ?
Sécurité
Identifiez les considérations relatives à la sécurité et à la confidentialité.
🟢 [P0] Existe-t-il des données sensibles/confidentielles qui doivent être gérées avec soin ?
🟡 [P1] Des contrôles d’accès doivent-ils être implémentés dans la solution (par exemple, un utilisateur donné ne peut récupérer qu’à partir d’un ensemble restreint de documents) ?
Déploiement
Comprendre comment la solution RAG sera intégrée, déployée et tenue à jour.
🟡 Comment la solution RAG doit-elle s’intégrer aux systèmes et workflows existants ?
🟡 Comment le modèle doit-il être déployé, mis à l’échelle et versionné ? Ce tutoriel explique comment le cycle de vie de bout en bout peut être géré sur Databricks à l’aide de MLflow, de Unity Catalog, du SDK Agent et de Model Serving.
Exemple
Par exemple, tenez compte de la façon dont ces questions s’appliquent à cet exemple d’application RAG utilisée par une équipe de support technique Databricks :
| Zone | À propos de l’installation | Spécifications |
|---|---|---|
| Expérience utilisateur | - Modalité d’interaction. - Exemples de requêtes utilisateur classiques. - Format et style de réponse attendus. - Gestion des requêtes ambiguës ou non pertinentes. |
- Interface de conversation intégrée à Slack. - Exemples de requêtes : « Comment faire pour réduire le temps de démarrage du cluster ? » « De quel type de plan de support est-ce que je dispose ? » - Réponses claires et techniques avec des extraits de code et des liens vers la documentation pertinente le cas échéant. - Fournissez des suggestions contextuelles, et procédez à une escalade aux ingénieurs du support si nécessaire. |
| Données | - Nombre et type de sources de données. - Format et emplacement des données. - Taille des données et fréquence de mise à jour. - Qualité et cohérence des données. |
- Trois sources de données. - Documentation de l’entreprise (HTML, PDF). - Tickets de support résolus (JSON). - Publications du forum communautaire (table Delta). - Données stockées dans Unity Catalog et mises à jour chaque semaine. - Taille totale des données : 5 Go. - Qualité et structure des données cohérentes gérées par des équipes de support et de documentation dédiées. |
| Performances | - Latence maximale acceptable. - Contraintes de coût. - Utilisation attendue et concurrence. |
- Exigence de latence maximale. - Contraintes de coût. - Pic de charge attendu. |
| Évaluation | - Disponibilité du jeu de données d’évaluation. - Métriques de qualité. - Collecte de commentaires utilisateur. |
- Les experts techniques de chaque zone de produit aident à passer en revue les sorties et à ajuster les réponses incorrectes afin de créer le jeu de données d’évaluation. - Indicateurs de performance clés métier. - Augmentation du taux de résolution des tickets de support. - Diminution du temps utilisateur par ticket de support. - Métriques de qualité. - Pertinence et exactitude de la réponse jugée par le LLM. - Précision de récupération jugée par le LLM. - Vote positif ou négatif de l’utilisateur. - Collecte de commentaires. - Slack sera instrumenté pour fournir une approbation ou un rejet. |
| Sécurité | - Gestion des données sensibles. - Exigences de contrôle d’accès. |
- Aucune donnée client sensible ne doit se trouver dans la source de récupération. - Authentification utilisateur via l’authentification unique Databricks Community. |
| Déploiement | - Intégration avec les systèmes existants. - Déploiement et contrôle de version. |
- Intégration avec le système de ticket de support. - Chaîne déployée en tant que point de terminaison Databricks Model Serving. |
Étape suivante
Découvrez comment bien démarrer avec l’Étape 1. Cloner le dépôt de code et créer un calcul.
< Précédent : Développement piloté par l’évaluation
Suivant : Étape 1. Cloner le référentiel & créer un calcul >