Présentation de RAG dans le développement IA
Cet article est une introduction à la génération augmentée de récupération (RAG) : ce qu’elle est, comment elle fonctionne et les concepts clés.
Qu’est-ce que la génération augmentée de récupération (RAG) ?
RAG est une technique qui permet à un modèle de langage volumineux (LLM) de générer des réponses enrichies en augmentant le prompt d’un utilisateur avec les données de référence récupérées à partir d’une source d’informations externe. En incorporant ces informations récupérées, RAG permet au LLM de générer des réponses plus précises et de meilleure qualité par rapport à la non-augmentation du prompt avec un contexte supplémentaire.
Par exemple, supposons que vous créez un chatbot de question-réponse pour aider les employés à répondre à des questions sur les documents privés de votre entreprise. Un LLM autonome ne pourra pas répondre avec exactitude aux questions sur le contenu de ces documents s’il n’a pas été spécifiquement entraîné à partir de ces mêmes documents. Le LLM peut refuser de répondre en raison d’un manque d’informations ou, pire encore, il peut générer une réponse incorrecte.
RAG résout ce problème en récupérant d’abord les informations pertinentes des documents d’entreprise en fonction de la requête d’un utilisateur, puis en fournissant les informations récupérées au LLM comme contexte supplémentaire. Cela permet au LLM de générer une réponse plus précise d’après des détails spécifiques trouvés dans les documents pertinents. En essence, RAG permet au LLM de « consulter » les informations récupérées pour formuler sa réponse.
Composants principaux d’une application RAG
Une application RAG est un exemple de système IA composé : elle s’étend sur les fonctionnalités de langage du modèle en la combinant avec d’autres outils et procédures.
Lors de l’utilisation d’un LLM autonome, un utilisateur envoie une requête, telle qu’une question, au LLM, et le LLM répond avec une réponse basée uniquement sur ses données d’apprentissage.
Dans sa forme la plus simple, les étapes suivantes se produisent dans une application RAG :
- Récupération : la requête de l’utilisateur est utilisée pour interroger une source d’informations externe. Cela peut signifier l’interrogation d’un magasin de vecteurs, l’exécution d’une recherche par mot clé sur un texte ou l’interrogation d’une base de données SQL. L’objectif de l’étape de récupération est d’obtenir des données de référence qui aident le LLM à fournir une réponse utile.
- Augmentation : les données de référence de l’étape de récupération sont combinées à la requête de l’utilisateur, souvent à l’aide d’un modèle avec une mise en forme et des instructions supplémentaires pour le LLM, pour créer un prompt.
- Génération : le prompt résultant est transmis au LLM, et le LLM génère une réponse à la requête de l’utilisateur.
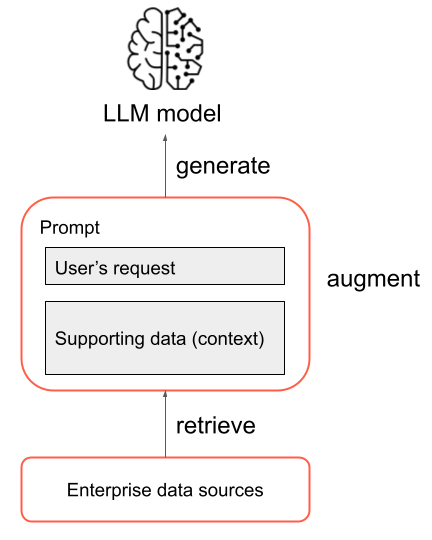
Il s’agit d’une vue d’ensemble simplifiée du processus RAG, mais il est important de noter que l’implémentation d’une application RAG implique de nombreuses tâches complexes. Le prétraitement des données sources pour les rendre adaptées à une utilisation dans RAG, la récupération efficace des données, la mise en forme du prompt augmenté et l'évaluation des réponses générées nécessitent tous une considération et un effort minutieux. Ces rubriques seront abordées plus en détail dans les sections ultérieures de ce guide.
Pourquoi utiliser RAG ?
Le tableau suivant présente les avantages de l’utilisation de RAG par rapport à un LLM autonome :
| Avec un LLM seul | Utilisation de LLM avec RAG |
|---|---|
| Aucune connaissance privée : les modules LLM sont généralement entraînés sur des données accessibles publiquement, de sorte qu’ils ne peuvent pas répondre avec précision aux questions sur les données internes ou privées d’une entreprise. | Les applications RAG peuvent incorporer des données privées : une application RAG peut fournir des documents privés tels que des mémos, des e-mails et des documents de conception à un LLM, ce qui lui permet de répondre à des questions sur ces documents. |
| Les connaissances ne sont pas mises à jour en temps réel : les LLM n’ont pas accès à des informations sur les événements qui se sont produits après leur apprentissage. Par exemple, un LLM autonome ne peut vous renseigner sur les mouvements boursiers du jour. | Les applications RAG peuvent accéder aux données en temps réel : une application RAG peut fournir au LLM des informations en temps opportun à partir d’une source de données mise à jour, ce qui lui permet de fournir des réponses utiles sur les événements antérieurs à la date limite de l’apprentissage. |
| Absence de citations : les LLM ne peuvent pas citer des sources d’informations spécifiques lors de la réponse. De ce fait, l’utilisateur n’est pas en mesure de vérifier si la réponse est factuellement exacte ou s’il s’agit d’une hallucination. | RAG peut citer des sources : lorsqu’il est utilisé dans le cadre d’une application RAG, un LLM peut être invité à citer ses sources. |
| Absence de contrôles d’accès aux données (ACL) : les LLM seuls ne peuvent pas fournir de manière fiable des réponses différentes à différents utilisateurs en fonction des autorisations utilisateur spécifiques. | RAG permet la sécurité des données/ACL : l’étape de récupération peut être conçue pour rechercher uniquement les informations auxquelles l’utilisateur est autorisé à accéder, ce qui permet à une application RAG de récupérer de manière sélective des informations personnelles ou privées. |
Types de RAG
L’architecture RAG peut fonctionner avec deux types de données de référence :
| Données structurées | Les données non structurées | |
|---|---|---|
| Définition | Données tabulaires organisées dans des lignes et des colonnes avec un schéma spécifique, par exemple, des tables dans une base de données. | Données sans structure ou organisation spécifique, par exemple, des documents qui incluent du texte et des images ou du contenu multimédia, tels que l’audio ou les vidéos. |
| Exemple de sources de données | - Enregistrements de clients dans un système BI ou d’entrepôt de données - Données de transaction d’une base de données SQL - Données provenant d’API d’application (telles que SAP, Salesforce, etc.) |
- Enregistrements de clients dans un système BI ou d’entrepôt de données - Données de transaction d’une base de données SQL - Données provenant d’API d’application (telles que SAP, Salesforce, etc.) - Fichiers PDF - Documents Google ou Microsoft Office - Wikis - Images - Vidéos |
Votre choix de données pour RAG dépend de votre cas d’utilisation. Le reste du livre de recettes se concentre sur RAG pour les données non structurées.