Utiliser des transformations dbt dans un travail Azure Databricks
Vous pouvez exécuter vos projets dbt Core en tant que tâche dans un travail Azure Databricks. En exécutant votre projet dbt Core en tant que tâche de travail, vous pouvez tirer parti des fonctionnalités des travaux Azure Databricks suivantes :
- Automatisez vos tâches dbt et planifiez des workflows incluant des tâches dbt.
- Surveillez vos transformations dbt et envoyez des notifications sur l’état des transformations.
- Incluez votre projet dbt dans un workflow avec d’autres tâches. Par exemple, votre workflow peut ingérer des données avec Auto Loader, transformer les données avec dbt et analyser les données avec une tâche de notebook.
- Archivage automatique des artefacts à partir des exécutions de travaux, incluant les journaux, les résultats, les manifestes et la configuration.
Pour en savoir plus sur dbt Core, consultez la documentation dbt.
Workflow de développement et de production
Databricks recommande de développer vos projets dbt sur un entrepôt SQL Databricks. À l’aide d’un entrepôt SQL Databricks, vous pouvez tester le SQL généré par dbt et utiliser l’historique des requêtes d’entrepôt SQL pour déboguer les requêtes générées par dbt.
Pour exécuter vos transformations dbt en production, Databricks recommande d’utiliser la tâche dbt dans un travail Databricks. Par défaut, la tâche dbt exécute le processus Python dbt en utilisant un calcul Azure Databricks et le SQL généré par dbt sur l’entrepôt SQL sélectionné.
Vous pouvez exécuter des transformations dbt sur un entrepôt SQL serverless ou un entrepôt SQL pro, un calcul Azure Databricks ou tout autre entrepôt pris en charge par dbt. Cet article présente les deux premières options avec des exemples.
Si votre espace de travail est compatible avec Unity Catalog et que Travaux serverless est activé, par défaut, le travail s’exécute par défaut sur le calcul Serverless.
Remarque
Le développement de modèles dbt sur un entrepôt SQL et leur exécution en production sur un calcul Azure Databricks peut entraîner des différences subtiles en termes de performances et de prise en charge du langage SQL. Databricks recommande d’utiliser la même version de Databricks Runtime pour le calcul et pour l’entrepôt SQL.
Spécifications
Pour savoir comment utiliser dbt Core et le package
dbt-databricksafin de créer et d’exécuter des projets dbt dans votre environnement de développement, consultez Se connecter à dbt Core.Databricks recommande le package dbt-databricks, et non le package dbt-spark. Le package dbt-databricks est une duplication (fork) de dbt-spark optimisé pour Databricks.
Pour utiliser des projets dbt dans un travail Azure Databricks, vous devez configurer l’intégration de Git pour des dossiers Git Databricks. Vous ne pouvez pas exécuter un projet dbt à partir de DBFS.
Vous devez activer des entrepôts SQL serverless ou pro.
Vous devez disposer du droit SQL Databricks.
Créer et exécuter votre premier travail dbt
L’exemple suivant utilise le projet jaffle_shop, un exemple de projet illustrant les concepts de base dbt. Pour créer un travail qui exécute le projet de magasin jaffle, suivez les étapes décrites dans la procédure ci-dessous.
Accédez à votre page d’accueil Azure Databricks et effectuez l’une des opérations suivantes :
- Dans la barre latérale, cliquez sur
 Workflows, puis sur
Workflows, puis sur  .
. - Dans la barre latérale, cliquez sur
 Nouveau, puis sélectionnez Travail.
Nouveau, puis sélectionnez Travail.
- Dans la barre latérale, cliquez sur
Dans la zone de texte de la tâche sous l’onglet Tâches, remplacez Ajouter un nom pour votre travail... par le nom de votre travail.
Pour Nom de la tâche, entrez un nom pour la tâche.
Dans Type, sélectionnez le type de tâche dbt.
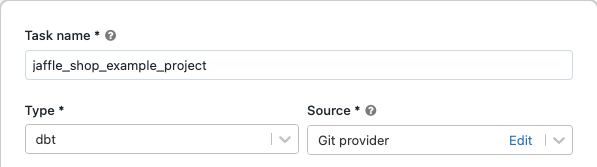
Dans le menu déroulant Source, vous pouvez sélectionner Espace de travail pour utiliser un projet dbt qui se trouve dans un dossier de l’espace de travail Azure Databricks ou un Fournisseur Git pour un projet qui se trouve dans un dépôt Git distant. Comme cet exemple utilise le projet Jaffle Shop qui se trouve dans un dépôt Git, sélectionnez Fournisseur Git, cliquez sur Modifier, puis entrez les détails pour le dépôt GitHub de Jaffle Shop.
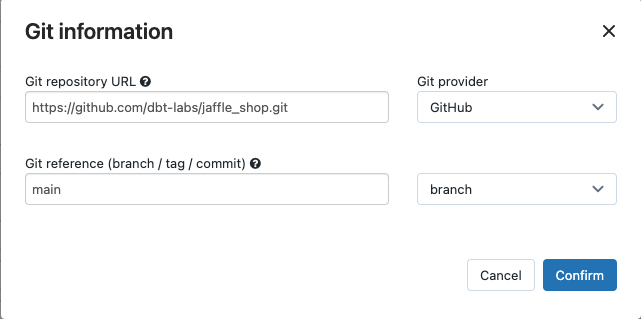
- Dans URL du référentiel Git, entrez l’URL du projet « jaffle shop ».
- Pour Référence Git (branche / balise / commit), entrez
main. Vous pouvez également utiliser une balise ou SHA.
Cliquez sur Confirmer.
Dans les zones de texte des commandes dbt, spécifiez les commandes dbt à exécuter (deps, seed et run). Vous devez préfixer chaque commande avec
dbt. Les commandes sont exécutées dans l’ordre spécifié.
Dans Entrepôt SQL, sélectionnez un entrepôt SQL pour exécuter le SQL généré par dbt. Le menu déroulant Entrepôt SQL affiche uniquement les entrepôts SQL serverless et pro.
(Facultatif) Vous pouvez spécifier un schéma pour la sortie de tâche. Par défaut, le schéma
defaultest utilisé.(Facultatif) Si vous souhaitez modifier la configuration du calcul qui exécute dbt Core, cliquez sur Calcul dbt CLI.
(Facultatif) Vous pouvez spécifier une version dbt-databricks pour la tâche. Par exemple, pour épingler votre tâche dbt à une version spécifique pour le développement et la production :
- Sous Bibliothèques dépendantes, cliquez sur
 en regard de la version dbt-databricks actuelle.
en regard de la version dbt-databricks actuelle. - Cliquez sur Add.
- Dans la boîte de dialogue Ajouter une bibliothèque dépendante, cliquez sur l’onglet PyPI et entrez la version du package dbt dans la zone de texte Package (par exemple,
dbt-databricks==1.6.0). - Cliquez sur Add.

Notes
Databricks vous conseille d’épingler vos tâches dbt à une version spécifique du package dbt-databricks pour vous assurer que la même version soit utilisée pour les exécutions de développement et de production. Databricks recommande le package dbt-databricks 1.6.0 ou une version ultérieure.
- Sous Bibliothèques dépendantes, cliquez sur
Cliquez sur Créer.
Pour exécuter dès à présent le travail, cliquez sur
 .
.
Afficher les résultats de votre tâche de travail dbt
Une fois le travail terminé, vous pouvez tester les résultats en exécutant des requêtes SQL à partir d’un notebook ou en exécutant des requêtes dans votre entrepôt Databricks. Par exemple, consultez les exemples de requêtes suivants :
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
Remplacez <schema> par le nom de schéma configuré dans la configuration de la tâche.
Exemple d’API
Vous pouvez également utiliser l’API Travaux pour créer et gérer des travaux incluant des tâches dbt. L’exemple suivant crée un travail avec une seule tâche dbt :
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main"
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": [
"dbt deps",
"dbt seed",
"dbt run"
],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
(Avancé) Exécuter dbt avec un profil personnalisé
Pour exécuter votre tâche dbt avec un entrepôt SQL (recommandé) ou un calcul à usage général, utilisez un fichier profiles.yml personnalisé définissant l’entrepôt ou le calcul Azure Databricks auquel se connecter. Pour créer un travail qui exécute le projet de magasin de jaffles avec un entrepôt ou un calcul à usage général, effectuez les étapes suivantes.
Remarque
Seul un entrepôt SQL ou un calcul à usage général peut être utilisé comme cible pour une tâche dbt. Vous ne pouvez pas utiliser le calcul d’un travail comme cible pour dbt.
Créez une duplication (fork) du référentiel jaffle_shop.
Clonez le référentiel dupliqué (fork) sur votre bureau. Par exemple, vous pouvez exécuter une commande telle que la suivante :
git clone https://github.com/<username>/jaffle_shop.gitRemplacez
<username>par votre descripteur GitHub.Créez un fichier appelé
profiles.ymldans le répertoirejaffle_shopavec le contenu suivant :jaffle_shop: target: databricks_job outputs: databricks_job: type: databricks method: http schema: "<schema>" host: "<http-host>" http_path: "<http-path>" token: "{{ env_var('DBT_ACCESS_TOKEN') }}"- Remplacez
<schema>par un nom de schéma pour les tables de projet. - Pour exécuter votre tâche dbt avec un entrepôt SQL, remplacez
<http-host>par la valeur du Nom d’hôte du serveur indiquée sous l’onglet Détails de connexion de votre entrepôt SQL. Pour exécuter votre tâche dbt avec un calcul à usage général, remplacez<http-host>par la valeur du Nom d’hôte du serveur qui se trouve sous l’onglet Options avancées, JDBC/ODBC de votre calcul Azure Databricks. - Pour exécuter votre tâche dbt avec un entrepôt SQL, remplacez
<http-path>par la valeur du Chemin HTTP indiquée sous l’onglet Détails de connexion de votre entrepôt SQL. Pour exécuter votre tâche dbt avec un calcul à usage général, remplacez<http-path>par la valeur du Chemin d’accès HTTP qui se trouve sous l’onglet Options avancées, JDBC/ODBC de votre calcul Azure Databricks.
Vous ne spécifiez pas de secrets, comme des jetons d’accès, dans le fichier, car vous allez placer ce fichier dans le contrôle de code source. Au lieu de cela, ce fichier utilise la fonctionnalité de création de modèles dbt pour insérer dynamiquement des informations d’identification au moment de l’exécution.
Notes
Les informations d’identification générées sont valides pendant la durée de l’exécution, jusqu’à un maximum de 30 jours, et sont automatiquement révoquées une fois l’exécution terminée.
- Remplacez
Vérifiez ce fichier dans Git et envoyez-le (push) à votre référentiel dupliqué (fork). Par exemple, vous pouvez exécuter l’une des commandes suivantes :
git add profiles.yml git commit -m "adding profiles.yml for my Databricks job" git pushCliquez sur
Workflows dans la barre latérale de l’interface utilisateur Databricks.Sélectionnez le travail dbt, puis cliquez sur l’onglet Tâches.
Dans Source, cliquez sur Modifier et entrez les détails du référentiel GitHub « jaffle shop » dupliqué (fork).
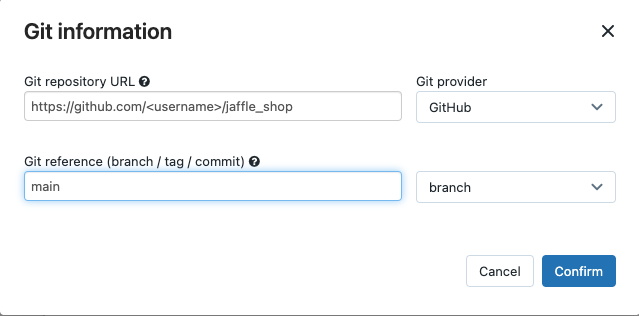
Dans Entrepôt SQL, sélectionnez Aucun (Manuel).
Dans Répertoire des profils, entrez le chemin relatif du répertoire contenant le fichier
profiles.yml. Laissez la valeur de chemin vide pour utiliser la valeur par défaut de la racine du référentiel.
(Avancé) Utiliser des modèles Python dbt dans un flux de travail
Notes
La prise en charge de dbt pour les modèles Python est en version bêta et nécessite dbt 1.3 ou une version ultérieure.
dbt prend désormais en charge les modèles Python sur des entrepôts de données spécifiques, notamment Databricks. Avec des modèles Python dbt, vous pouvez utiliser des outils de l’écosystème Python pour implémenter des transformations difficiles à implémenter avec SQL. Vous pouvez créer un travail Azure Databricks pour exécuter une tâche unique avec votre modèle Python dbt, ou intégrer la tâche dbt à un flux de travail qui comprend plusieurs tâches.
Vous ne pouvez pas exécuter de modèles Python dans une tâche dbt en utilisant un entrepôt SQL. Pour plus d’informations sur l’utilisation de modèles dbt Python avec Azure Databricks, consultez les entrepôts de données spécifiques dans la documentation dbt.
Erreurs et résolution des problèmes
Erreur Le fichier de profil n’existe pas
Message d’erreur :
dbt looked for a profiles.yml file in /tmp/.../profiles.yml but did not find one.
Causes possibles :
Le fichier profiles.yml est introuvable dans le $PATH spécifié. Vérifiez que la racine de votre projet dbt contient le fichier profiles.yml.