Créer une exécution d’apprentissage avec l’API Mosaic AI Model Training
Important
Cette fonctionnalité est disponible en préversion publique dans les régions suivantes : centralus, eastus, eastus2, northcentralus et westus.
Cet article illustre la façon de créer et de configurer une exécution d’apprentissage en utilisant l’API Mosaic AI Model Training (anciennement Foundation Model Training) et décrit tous les paramètres utilisés dans un appel d’API. Vous pouvez également créer une exécution en utilisant l’interface utilisateur. Pour obtenir les instructions correspondantes, consultez l’article Créer une exécution d’apprentissage en utilisant l’interface utilisateur Mosaic AI Model Training.
Exigences
Consultez Spécifications.
Créer une exécution d’apprentissage
Pour créer des exécutions d’apprentissage de manière programmatique, utilisez la fonction create(). Cette fonction effectue l’apprentissage d’un modèle sur le jeu de données fourni et transforme le point de contrôle Composer en point de contrôle au format Hugging Face pour l’inférence.
Les entrées souhaitées sont le modèle que vous souhaitez entraîner, l’emplacement de votre jeu de données d’apprentissage et l’emplacement d’enregistrement de votre modèle. Il existe également des paramètres facultatifs qui vous permettent d’effectuer l’évaluation et de modifier les hyperparamètres de votre exécution.
Ensuite, l’exécution terminée et les points de contrôle sont enregistrés, le modèle est cloné et ce clone est inscrit dans Unity Catalog comme une version du modèle pour l’inférence.
Le modèle issu de l’exécution terminée, et non la version clonée du modèle dans Unity Catalog, et ses points de contrôle Composer et Hugging Face sont enregistrés dans MLflow. Les points de contrôle Composer peuvent être utilisés pour les tâches d’optimisation continues.
Consultez Configurer une exécution d’apprentissage afin d’obtenir des informations sur les arguments pour la fonction create().
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-2-7b-chat-hf',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
Configurer une exécution d’apprentissage
Le tableau suivant récapitule les paramètres de la create() fonction.
| Paramètre | Obligatoire | Type | Description |
|---|---|---|---|
model |
x | str | Nom du modèle à utiliser. Consultez Modèles pris en charge. |
train_data_path |
x | str | L’emplacement de vos données d’apprentissage. Il peut s’agir d’un emplacement dans Unity Catalog (<catalog>.<schema>.<table> ou dbfs:/Volumes/<catalog>/<schema>/<volume>/<dataset>.jsonl), ou d’un jeu de données HuggingFace.Pour INSTRUCTION_FINETUNE, les données doivent être mises en forme avec chaque ligne contenant un champ prompt et response.Pour CONTINUED_PRETRAIN, c’est un dossier de fichiers .txt. Consultez l’article Préparer des données pour Foundation Model Training pour connaître les formats de données acceptés et la section Taille recommandée des données pour l’apprentissage d’un modèle pour découvrir les recommandations relatives à la taille des données. |
register_to |
x | str | Le schéma et le catalogue Unity Catalog (<catalog>.<schema> ou <catalog>.<schema>.<custom-name>) dans lesquels le modèle est enregistré après l’apprentissage pour faciliter le déploiement. Si custom-name n’est pas fourni, le nom d’exécution constitue sa valeur par défaut. |
data_prep_cluster_id |
str | L’ID de cluster du cluster à utiliser pour le traitement de données Spark. Il est requis pour des tâches d’apprentissage supervisées où les données d’apprentissage sont dans une table Delta. Pour plus d’informations sur la recherche de l’ID de cluster, consultez Obtenir l’ID de cluster. | |
experiment_path |
str | Le chemin d’accès vers l’expérience MLflow où le résultat d’exécution d’apprentissage (mesures et points de contrôle) est enregistré. Prend la valeur par défaut du nom d’exécution dans l’espace de travail personnel de l’utilisateur (c’est-à-dire /Users/<username>/<run_name>). |
|
task_type |
str | Type de tâche à exécuter. Il peut s’agir de INSTRUCTION_FINETUNE (par défaut), de CHAT_COMPLETION ou de CONTINUED_PRETRAIN. |
|
eval_data_path |
str | L’emplacement distant de vos données d’évaluation (le cas échéant). Il doit respecter le même format que train_data_path. |
|
eval_prompts |
List[str] | Une liste de chaîne d’invites pour générer des réponses pendant une évaluation. La valeur par défaut est None (ne génère aucune invite). Les résultats sont journalisés dans l’expérience chaque fois que le modèle fait l’objet d’un point de contrôle. Les générations se produisent lors de chaque point de contrôle de modèle avec les paramètres de génération suivants : max_new_tokens: 100, temperature: 1, top_k: 50, top_p: 0.95, do_sample: true. |
|
custom_weights_path |
str | L’emplacement distant d’un point de contrôle personnalisé de modèle pour l’apprentissage. La valeur par défaut est None, ce qui signifie que l’exécution démarre à partir des pondérations préentraînées d’origine du modèle choisi. Si des pondérations personnalisées sont fournies, elles sont utilisées au lieu des pondérations préentraînées d’origine du modèle. Ces pondérations doivent être un point de contrôle Composer et doivent correspondre à l’architecture du point de model contrôle spécifié. Voir Générer sur des pondérations de modèle personnalisées |
|
training_duration |
str | Durée totale de votre exécution. La valeur par défaut est une époque ou 1ep. Peut être spécifié en époques (10ep) ou en jetons (1000000tok). |
|
learning_rate |
str | Taux d’apprentissage pour l’apprentissage du modèle. Pour tous les modèles autres que Llama 3.1 405B Instruct, le taux d’apprentissage par défaut est 5e-7. Pour Llama 3.1 405B Instruct, le taux d’apprentissage par défaut est 1.0e-5. L’optimiseur est DecoupledLionW avec des bêtas de 0,99 et 0,95 et aucune perte de pondération. Le planificateur de taux d’apprentissage est LinearWithWarmupSchedule avec un préchauffage de 2 % de la durée total d’apprentissage et un multiplicateur de taux d’apprentissage final de 0. |
|
context_length |
str | Longueur maximale de séquence d’un exemple de données. Elle est utilisée pour tronquer des données trop longues ou pour empaqueter ensemble des séquences plus courtes pour davantage d’efficacité. La valeur par défaut est 8192 jetons ou la longueur maximale du contexte pour le modèle fourni (selon la valeur inférieure). Vous pouvez utiliser ce paramètre pour configurer la longueur du contexte, mais une configuration au-delà de la longueur maximale de chaque modèle n’est pas prise en charge. Consultez les Modèles pris en charge pour la longueur de contexte maximale prise en charge de chaque modèle. |
|
validate_inputs |
Boolean | Indique s’il faut valider l’accès aux chemins d’accès d’entrée avant de soumettre le travail d’apprentissage. La valeur par défaut est True. |
Générer à partir de pondérations de modèle personnalisé
Mosaïque AI Model Training prend en charge l’ajout de poids personnalisés à l’aide du paramètre custom_weights_path facultatif pour entraîner et personnaliser un modèle.
Pour commencer, définissez custom_weights_path le chemin du point de contrôle Composer à partir d’une exécution d’entraînement précédente. Les chemins de point de contrôle se trouvent sous l’onglet Artefacts d’une exécution MLflow précédente. Le nom du dossier de point de contrôle correspond au lot et à l’époque d’un instantané particulier, tel que ep29-ba30/.

- Pour fournir le dernier point de contrôle à partir d’une exécution précédente, définissez
custom_weights_pathle point de contrôle Composer. Par exemple :custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/latest-sharded-rank0.symlink. - Pour fournir un point de contrôle antérieur, définissez
custom_weights_pathsur un chemin d’accès à un dossier contenant des.distcpfichiers correspondant au point de contrôle souhaité, tel quecustom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/ep#-ba#.
Ensuite, mettez à jour le model paramètre pour qu’il corresponde au modèle de base du point de contrôle que vous avez passé à custom_weights_path.
Dans l’exemple ift-meta-llama-3-1-70b-instruct-ohugkq suivant, il s’agit d’une exécution précédente qui fine-tunes meta-llama/Meta-Llama-3.1-70B. Pour affiner le dernier point de contrôle à partir de ift-meta-llama-3-1-70b-instruct-ohugkq, définissez les variables et custom_weights_path les model variables comme suit :
from databricks.model_training import foundation_model as fm
run = fm.create(
model = 'meta-llama/Meta-Llama-3.1-70B'
custom_weights_path = 'dbfs:/databricks/mlflow-tracking/2948323364469837/d4cd1fcac71b4fb4ae42878cb81d8def/artifacts/ift-meta-llama-3-1-70b-instruct-ohugkq/checkpoints/latest-sharded-rank0.symlink'
... ## other parameters for your fine-tuning run
)
Consultez Configurer une exécution d’entraînement pour configurer d’autres paramètres dans votre exécution de réglage précis.
Obtenir l’ID de cluster
Pour récupérer l’ID de cluster :
Dans la barre de navigation gauche de l’espace de travail Databricks, cliquez sur Calcul.
Dans la table, cliquez sur le nom de votre cluster.
Cliquez sur
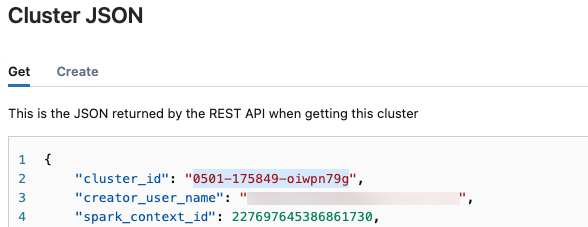
 dans l’angle supérieur droit, puis sélectionnez Afficher le fichier JSON dans la liste déroulante.
dans l’angle supérieur droit, puis sélectionnez Afficher le fichier JSON dans la liste déroulante.Le fichier JSON Cluster s’affiche. Copiez l’ID de cluster, qui est la première ligne dans le fichier.
Obtenir l’état d’une exécution
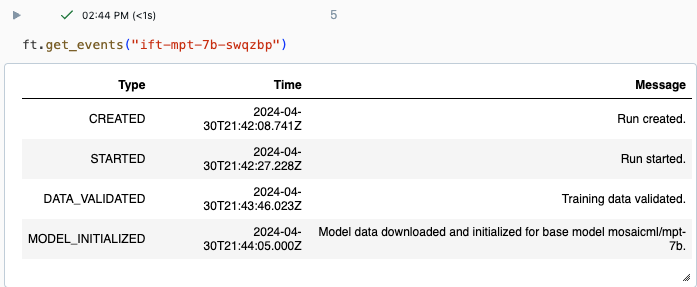
Vous pouvez suivre la progression d’une exécution en utilisant la page Expérience dans l’interface utilisateur Databricks ou à l’aide de la commande d’API get_events(). Pour obtenir des détails, consultez l’article Afficher, gérer et analyser les exécutions Mosaic AI Model Training.
Exemple de sortie à partir de get_events() :
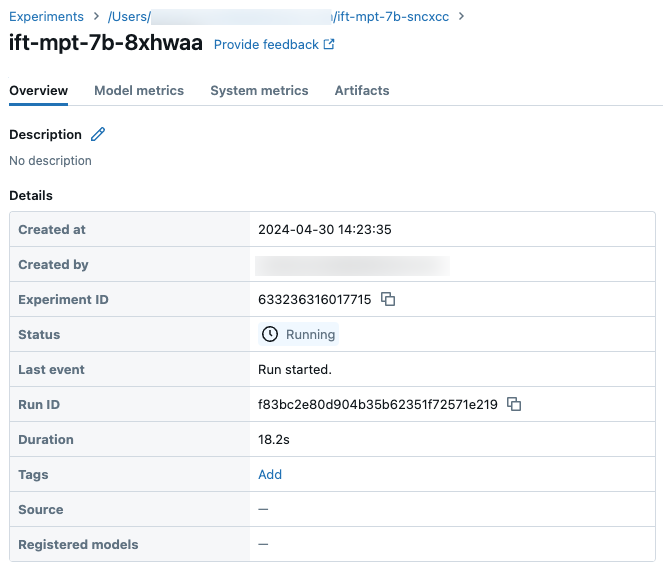
Exemple des détails d’une exécution sur la page Expérience :
Étapes suivantes
Une fois votre exécution d’apprentissage terminée, vous pouvez passer en revue les mesures dans MLflow et déployer votre modèle pour l’inférence. Consultez les étapes 5 à 7 du tutoriel Créer et déployer une exécution Mosaic AI Model Training.
Consultez le notebook de démonstration Optimisation des instructions : Reconnaissance d’entité nommée pour obtenir un exemple d’optimisation des instructions qui décrit la préparation des données, l’optimisation de la configuration d’exécution de formation et le déploiement.
Exemple de Bloc-notes
Le bloc-notes suivant montre un exemple de génération de données synthétiques à l’aide du modèle Meta-Llama-3.1 405B Instruct et d’utiliser ces données pour ajuster un modèle :
Générer des données synthétiques à l’aide du bloc-notes Llama-3.1 405B Instruct
Ressources supplémentaires
- Mosaic AI Model Training pour les modèles de base
- Tutoriel : Créer et déployer une exécution Mosaic AI Model Training
- Créer une exécution d’apprentissage avec l’interface utilisateur de Mosaic AI Model Training
- Afficher, gérer et analyser les exécutions Mosaic AI Model Training
- Préparer des données pour Mosaic AI Model Training