Comment Databricks prend-il en charge CI/CD pour le Machine Learning ?
CI/CD (intégration continue et livraison continue) fait référence à un processus automatisé pour développer, déployer, analyser et maintenir vos applications. En automatisant la génération, le test et le déploiement du code, les équipes de développement sont en mesure de livrer des versions plus fréquemment et de manière plus fiable que les processus manuels qui prévalent encore dans de nombreuses équipes d’engineering données et de science des données. CI/CD pour l’apprentissage automatique rassemble des techniques de MLOps, DataOps, ModelOps et DevOps.
Cet article décrit comment Databricks prend en charge CI/CD pour les solutions d’apprentissage automatique. Dans les applications d’applications, CI/CD est important non seulement pour les ressources de code, mais également pour les pipelines de données, y compris les données d’entrée et les résultats générés par le modèle.
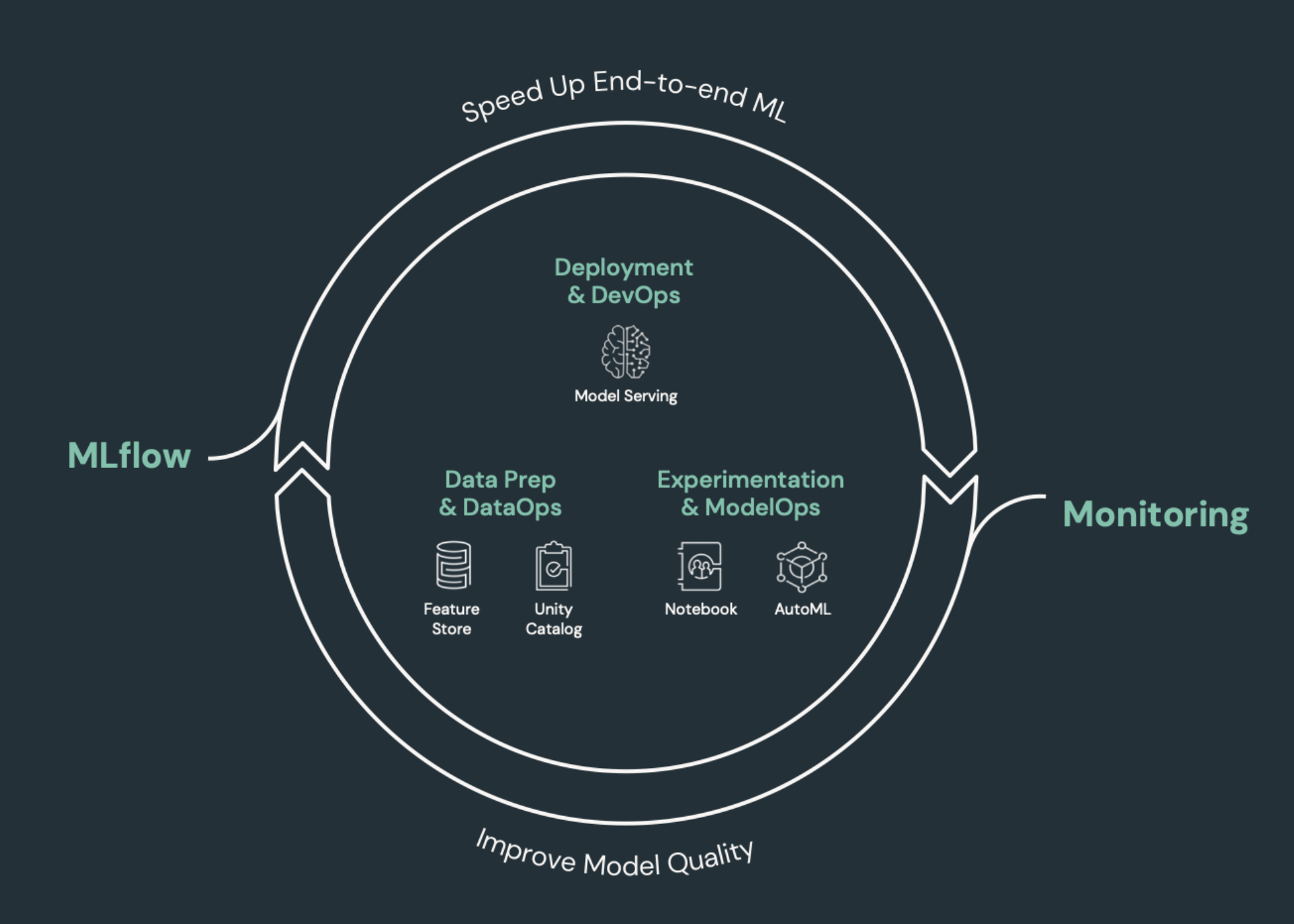
Éléments d’apprentissage automatique ayant besoin de CI/CD
L’un des défis du développement du ML est que différentes équipes sont propriétaires de différentes parties du processus. Les équipes peuvent s’appuyer sur différents outils et avoir des planifications de publication différentes. Azure Databricks fournit une plateforme unique et unifiée de données et de ML avec des outils intégrés pour améliorer l’efficacité des équipes et garantir la cohérence et la répétabilité des pipelines de données et de ML.
En général, pour les tâches d’apprentissage automatique, les éléments suivants doivent être suivis dans un flux de travail CI/CD automatisé :
- Données de formation, notamment la qualité des données, les modifications de schéma et les modifications de distribution.
- Pipelines de données d’entrée.
- Code pour la formation, la validation et le service du modèle.
- Prédictions et niveau de performance de modèle.
Intégrer Databricks à vos processus CI/CD
MLOps, DataOps, ModelOps et DevOps font référence à l’intégration des processus de développement avec des « opérations » : rendre les processus et l’infrastructure prévisibles et fiables. Cet ensemble d’articles explique comment intégrer les principes d’opérations (« ops ») dans vos flux de travail ML sur la plateforme Databricks.
Databricks intègre tous les composants requis pour le cycle de vie ML, y compris les outils permettant de créer une « configuration en tant que code » afin de garantir la reproductibilité et une « infrastructure en tant que code » pour automatiser l’approvisionnement des services cloud. Elle inclut également des services de journalisation et d’alerte pour vous aider à détecter et résoudre les problèmes lorsqu’ils se produisent.
DataOps : données fiables et sécurisées
Les bons modèles ML dépendent de pipelines de données et d’une infrastructure fiables. Avec la plateforme Databricks Data Intelligence, l’ensemble du pipeline de données, des l’ingestion de données aux sorties du modèle servi, se trouve sur une plateforme unique et utilise le même ensemble d’outils, ce qui facilite la productivité, la reproductibilité, le partage et la résolution des problèmes.

Tâches et outils DataOps dans Databricks
Le tableau liste les tâches et outils DataOps courants dans Databricks :
| Tâche DataOps | Outil dans Databricks |
|---|---|
| Ingérer et transformer des données | Chargeur automatique et Apache Spark |
| Suivre les modifications apportées aux données, y compris le contrôle de version et la traçabilité | Tables Delta |
| Générer, gérer et analyser des pipelines de traitement des données | Delta Live Tables |
| Garantir la sécurité et la gouvernance des données | Unity Catalog |
| Analyse exploratoire des données et tableaux de bord | Databricks SQL, tableaux de bord et notebooks Databricks |
| Codage général | Notebooks Databricks SQL et Databricks |
| Planifier des pipelines de données | Travaux Databricks |
| Automatiser les flux de travail généraux | Travaux Databricks |
| Créer, stocker, gérer et découvrir des fonctionnalités pour la formation de modèle | Magasin de caractéristiques Databricks |
| Analyse des données | Lakehouse Monitoring |
ModelOps : développement et cycle de vie des modèles
Développer un modèle nécessite une série d’expériences et un moyen de suivre et de comparer les conditions et les résultats de ces expériences. La plateforme Databricks Data Intelligence inclut MLflow pour le suivi du développement de modèles et le registre de modèles MLflow pour gérer le cycle de vie du modèle, notamment la mise en lots, le service et le stockage des artefacts de modèle.
Une fois qu’un modèle est publié en production, de nombreuses choses peuvent changer qui peuvent affecter son niveau de performance. En plus d’analyser le niveau de performance de prédiction du modèle, vous devez également analyser les données d’entrée à la recherche de modifications apportées à la qualité ou aux caractéristiques statistiques susceptibles de nécessiter une reformation du modèle.
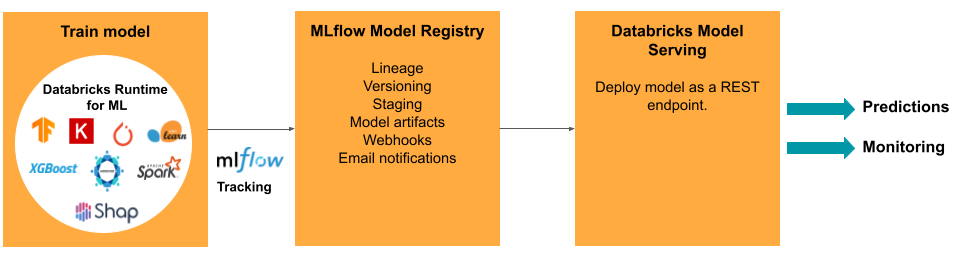
Tâches et outils ModelOps dans Databricks
Le tableau liste les tâches et outils ModelOps courants fournis par Databricks :
| Tâche ModelOps | Outil dans Databricks |
|---|---|
| Suivre le développement d’un modèle | Suivi de modèle MLflow |
| Gérer le cycle de vie du modèle | Modèles dans Unity Catalog |
| Contrôle de version et partage du code de modèle | Dossiers Databricks Git |
| Développement de modèles no-code | AutoML |
| Surveillance des modèles | Lakehouse Monitoring |
DevOps : production et automatisation
La plateforme Databricks prend en charge les modèles ML en production avec les éléments suivants :
- Traçabilité des données et des modèles de bout en bout : des modèles en production à la source de données brute, sur la même plateforme.
- Service de modèle au niveau de la production : effectue automatiquement un scale-up ou un scale-down en fonction des besoins de votre entreprise.
- Travaux : automatise les travaux et crée des flux de travail d’apprentissage automatique planifiés.
- Dossiers Git : le contrôle de version et le partage du code à partir de l’espace de travail aident également les équipes à suivre les meilleures pratiques en matière de génie logiciel.
- Fournisseur Databricks Terraform : automatise l’infrastructure de déploiement entre les clouds pour les travaux d’inférence ML, le service des points de terminaison et les travaux de caractérisation.
Mise en service de modèles
Pour le déploiement de modèles en production, MLflow simplifie considérablement le processus, en offrant un déploiement en un clic unique en tant que tâche de traitement par lots pour de grandes quantités de données, ou en tant que point de terminaison REST sur un cluster en mise à l’échelle automatique. L’intégration de Databricks Feature Store à MLflow garantit également la cohérence des fonctionnalités pour la formation et le service. En outre, les modèles MLflow peuvent rechercher automatiquement des fonctionnalités depuis le Feature Store, même pour un service en ligne à faible latence.
La plateforme Databricks prend en charge de nombreuses options de modèle de déploiement :
- Code et conteneurs.
- Traitement par lots.
- Service en ligne à faible latence.
- Service à l’appareil ou à la périphérie.
- Multicloud, par exemple, former le modèle sur un cloud et le déployer sur un autre.
Pour plus d’informations, consultez Service de modèles Mosaic AI.
Tâches
Les Travaux Databricks vous permettent d’automatiser et de planifier tout type de charge de travail, de l’ETL au ML. Databricks prend également en charge les intégrations avec des orchestrateurs tiers populaires comme Airflow.
Dossiers Git
La plateforme Databricks inclut la prise en charge de Git dans l’espace de travail pour aider les équipes à suivre les meilleures pratiques en matière de génie logiciel en effectuant des opérations Git via l’interface utilisateur. Les administrateurs et les ingénieurs DevOps peuvent utiliser des API pour configurer l’automatisation avec leurs outils CI/CD favoris. Databricks prend en charge tout type de déploiement Git, y compris les réseaux privés.
Pour plus d’informations sur les meilleures pratiques de développement de code avec des dossiers Databricks Git, consultez Workflows CI/CD avec l’intégration Git et les dossiers Databricks Git et Utiliser CI/CD. Ces techniques, associés à l’API REST Databricks, vous permettent de créer des processus de déploiement automatisés avec des GitHub Actions, des pipelines Azure DevOps ou des travaux Jenkins.
Unity Catalog pour la gouvernance et la sécurité
La plateforme Databricks inclut Unity Catalog, qui permet aux administrateurs de configurer un contrôle d’accès précis, des stratégies de sécurité et une gouvernance de toutes les ressources de données et d’IA dans Databricks.