Asymétrie et déversement
Déversement
La première chose à rechercher dans une phase longue est de savoir s’il y a un déversement.
En haut de la page de l’étape, vous verrez les détails, qui peuvent inclure des statistiques sur le déversement :
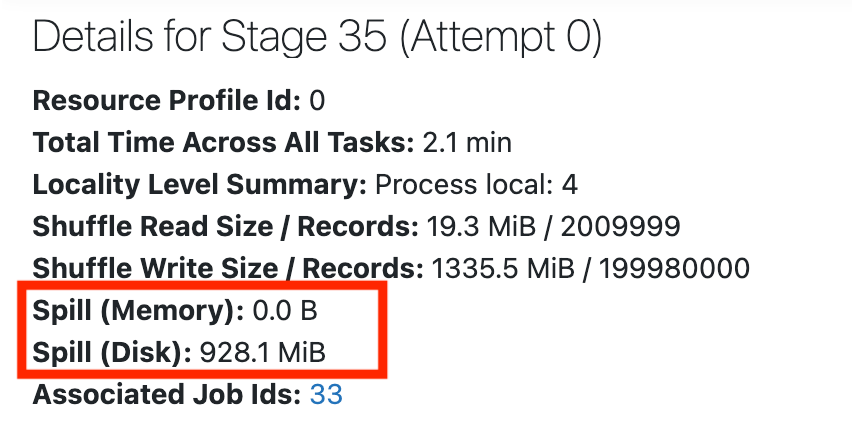
Le déversement est ce qui se passe quand Spark s’exécute faiblement sur la mémoire. Il commence à déplacer des données de la mémoire vers le disque, ce qui peut être assez onéreux. Il est particulièrement courant lors de la lecture aléatoire des données.
Si vous ne voyez aucune statistique pour le déversement, cela signifie que l’étape ne présente pas de déversements. Si l’étape présente un déversement, consultez ce guide sur la façon de gérer le déversement causé par la lecture aléatoire.
Asymétrie
La deuxième chose que nous cherchons à examiner est de savoir s’il y a un asymétrie. L’asymétrie est quand une ou quelques tâches prennent beaucoup plus de temps que le reste. Cela entraîne une mauvaise utilisation du cluster et des tâches plus longues.
Faites défiler jusqu’à Métriques récapitulatives. La principale chose que nous recherchons est une durée maximale beaucoup plus élevée que la durée du 75e centile. La capture d’écran ci-dessous montre une étape saine, dans laquelle le 75e centile correspond à la durée maximale :
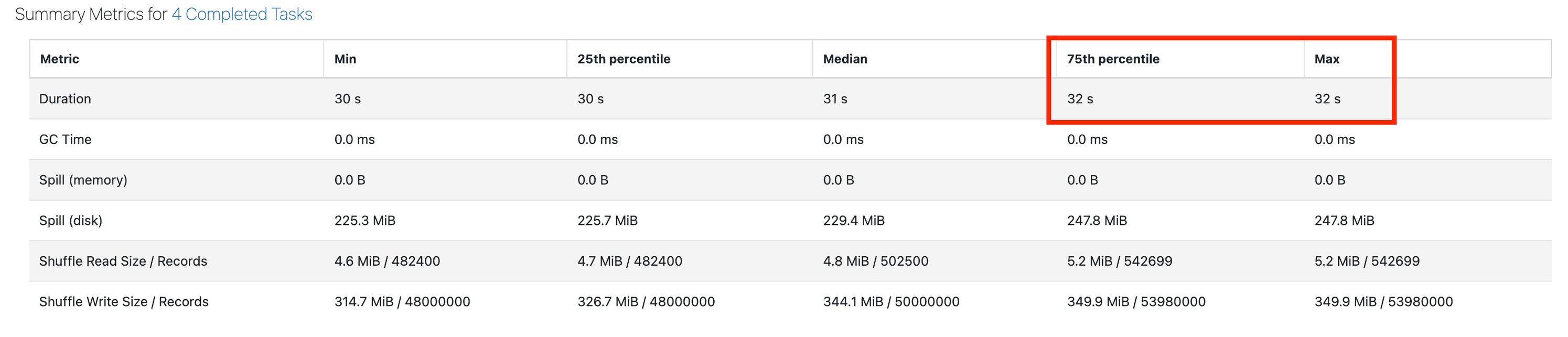
Si la durée maximale est de 50 % supérieure au 75e centile, vous risquez de souffrir d’une asymétrie.
Si vous remarquez une asymétrie, découvrez les étapes de correction d’asymétrie ici.
Pas d’asymétrie ou de déversement
Si vous ne constatez pas d’asymétrie ou de déversement, revenez à la page de travail pour obtenir une vue d’ensemble de ce qui se passe. Faites défiler jusqu’en haut de la page, puis cliquez sur ID de travail associés :

Si l’étape ne présente pas de déversement ou d’asymétrie, consultez Étape Spark E/S élevée pour les étapes suivantes.