Février 2018
Les publications se font par étapes. Votre compte Azure Databricks ne peut pas être mis à jour jusqu’à une semaine après la date de publication initiale.
Le nouveau graphique en courbes prend en charge les données de série chronologique
Du 27 février au 6 mars 2018 : version 2.66
Un nouveau graphique en courbes prend entièrement en charge les données de série chronologique et résout les limitations de notre ancienne option de graphique en courbes. L’ancien graphique en courbes est déconseillé et nous recommandons aux utilisateurs de migrer les visualisations qui utilisent l’ancien graphique en courbes vers le nouveau.
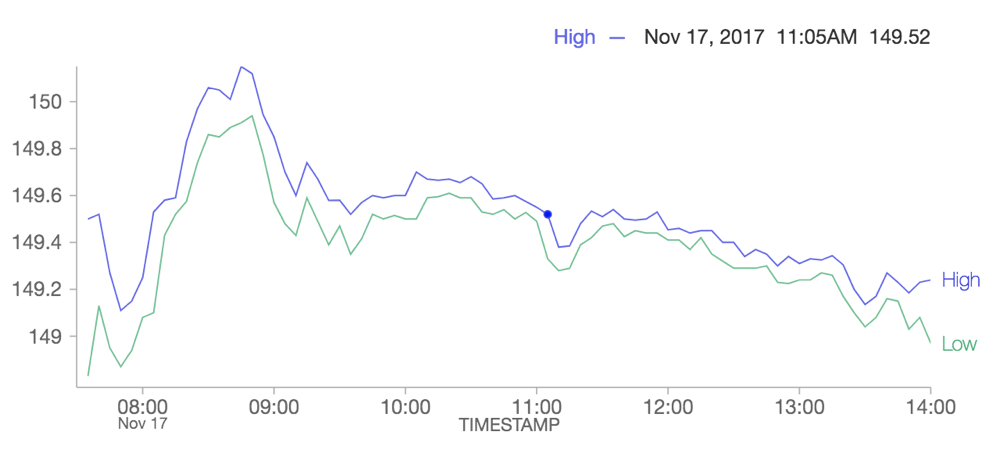
Pour plus d’informations, consultez Migrer des graphiques en courbes hérités.
Autres améliorations apportées aux visualisations
Du 27 février au 6 mars 2018 : version 2.66
Vous pouvez désormais trier les colonnes d’une sortie de table et utiliser plus de 10 éléments de légende dans un graphique.
Supprimer les exécutions de travaux à l’aide de l’API de travail
Du 27 février au 6 mars 2018 : version 2.66
Vous pouvez désormais utiliser l’API Job pour supprimer des exécutions de travaux à l’aide du nouveau point de terminaison jobs/runs/delete.
Pour plus d’informations, consultez Exécutions – Supprimer.
Bibliothèque de rendu mathématique KaTeX mise à jour
Du 27 février au 6 mars 2018 : version 2.66
La version de KatTeX qu’Azure Databricks utilise pour le rendu des équations mathématiques a été mise à jour de 0.5.1 à 0.9.0-beta1.
Cette mise à jour introduit des modifications susceptibles de rompre les expressions écrites dans la version 0.5.1 :
\xLongequalest désormais\xlongequal(#997)- Les couleurs HTML
[text]colordoivent être bien formées. (#827) \llapet\rlapaffichent désormais le contenu en mode mathématique. Utilisez\mathllap(nouveau) et\mathrlap(nouveau) pour obtenir le comportement précédent.\coloret\textcolorse comportent désormais comme dans KaTex (#619)
Pour plus d’informations, consultez les notes de publication KaTeX.
Databricks CLI : version 0.5.0
27 février 2018 : databricks-cli 0.5.0
La CLI Databricks prend désormais en charge des commandes qui ciblent l’API Bibliothèques.
L’interface CLI prend désormais en charge plusieurs profils de connexion. Vous pouvez utiliser des profils de connexion pour configurer l’interface CLI afin qu’elle communique avec plusieurs déploiements Azure Databricks.
Pour plus d’informations, consultez Interface CLI Databricks (héritée).
Bibliothèque d’API DBUtils
Du 13 au 20 février 2018 : version 2.65
Azure Databricks fournit une série d’API utilitaires qui vous permettent de travailler facilement avec le DBFS, des flux de travail de notebook et des widgets. La bibliothèque dbutils-apiaccélère le développement d’applications en vous permettant de compiler et d’exécuter localement des tests unitaires sur ces API utilitaires avant de déployer votre application sur un cluster Azure Databricks.
Pour plus d’informations, consultez Bibliothèque d’API Databricks Utilities.
Filtrer uniquement vos travaux
Du 13 au 20 février 2018 : version 2.65
De nouveaux filtres sur la liste Travaux vous permettent d’afficher uniquement les travaux dont vous êtes propriétaire et auxquels vous avez accès.
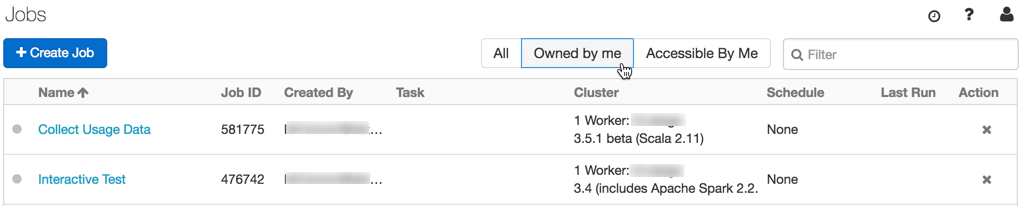
Pour plus d’informations, consultez Planifier et orchestrer des flux de travail.
Paramètres spark-submit à partir de la page de création de travail
Du 13 au 20 février 2018 : version 2.65
Vous pouvez désormais configurer des paramètres spark-submit à partir de la page Créer un travail, ainsi que via l’API REST ou l’interface CLI.

Pour plus d’informations, consultez Planifier et orchestrer des flux de travail.
Sélectionner Python 3 dans la page de création de cluster
Du 13 au 20 février 2018 : version 2.65
Vous pouvez désormais spécifier Python version 2 ou 3 dans la nouvelle liste déroulante des versions de Python quand vous créez un cluster. Si vous n’opérez pas de sélection, Python 2 est la valeur par défaut. Vous pouvez également, comme précédemment, créer des clusters Python 3 à l’aide de l’API REST.
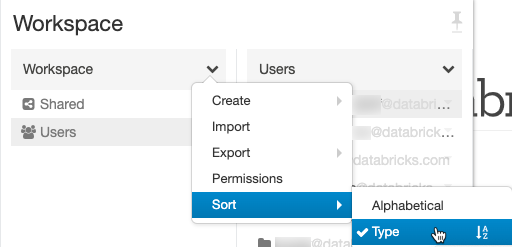
Améliorations apportées à l’interface utilisateur de l’espace de travail
Du 13 au 20 février 2018 : version 2.65
Nous avons ajouté la possibilité de trier les fichiers par type (dossiers, notebooks, bibliothèques) dans l’Explorateur de fichiers de l’espace de travail, et le dossier de base apparaît toujours en haut de la liste Utilisateurs.
Autocomplétion des commandes SQL et des noms de base de données
Du 13 au 20 février 2018 : version 2.65
Des cellules SQL dans les notebooks alimentent désormais la saisie semi-automatique des noms de commandes et de bases de données SQL.
Les pools serverless prennent désormais en charge R
Du 1e au 8 février 2018 : version 2.64
Vous pouvez désormais utiliser R dans des Pools serverless.
XGBoost disponible en tant que package Spark
Du 1e au 8 février 2018 : version 2.64
La bibliothèque d’intégration Spark de XGBoost peut désormais être installée sur Azure Databricks en tant que package Spark à partir de l’interface utilisateur Bibliothèque ou de l’API REST. Auparavant, XGBoost devait être installé à partir de la source via des scripts init et, par conséquent, le démarrage du cluster prenait plus de temps. Pour plus d’informations, consultez Utiliser XGBoost sur Azure Databricks.
Contrôle d’accès aux tables pour SQL et Python (bêta)
Du 1e au 8 février 2018 : version 2.64
L’année dernière, nous avons introduit le contrôle d’accès aux objets de données pour les utilisateurs SQL. Aujourd’hui, nous sommes heureux d’annoncer la version bêta publique du contrôle d’accès aux tables (listes de contrôle d’accès des tables) pour les utilisateurs tant de SQL que de Python. Le contrôle d’accès aux tables vous permet de restreindre l’accès à des objets sécurisables tels que des tables, des bases de données, des affichages ou des fonctions. Vous pouvez également fournir un contrôle d’accès précis (par exemple, à des lignes et colonnes correspondant à des conditions spécifiques) en définissant des autorisations sur des affichages dérivés contenant des requêtes arbitraires.
Notes
- Cette fonctionnalité est disponible en version bêta publique
- Cette fonctionnalité requiert Databricks Runtime 3.5+.
Pour plus d’informations, consultez Privilèges de metastore Hive et objets sécurisables (hérités).