Janvier 2019
Ces fonctionnalités et améliorations de la plateforme Azure Databricks ont été publiées en janvier 2019.
Notes
Les publications se font par étapes. Votre compte Azure Databricks peut ne pas être mis à jour jusqu’à une semaine après la date de publication initiale.
Changement à venir : Python 3 va devenir la version par défaut lors de la création de clusters
29 janvier 2019
Lors des publications de la version 2.91 de la plateforme Databricks en mi-février, la version Python par défaut des nouveaux clusters passera de Python 2 à Python 3. Évidemment, les clusters existants ne modifieront pas leurs versions Python. Toutefois, si vous avez pris l’habitude d’utiliser la version par défaut Python 2 quand vous créez des clusters, vous devez commencer à faire attention au choix de votre version Python.
Version (Beta) 5.2 de Databricks Runtime pour Machine Learning
24 janvier 2019
Databricks Runtime 5.2 ML s’appuie sur Databricks Runtime 5.2 (fin de support). Il contient de nombreuses bibliothèques de Machine Learning courantes, notamment TensorFlow, PyTorch, Keras et XGBoost, et fournit une formation TensorFlow distribuée à l’aide de Horovod. Outre les mises à jour de bibliothèque depuis Databricks Runtime 5.1, Databricks Runtime 5.2 ML comprend les nouvelles fonctionnalités suivantes :
- GraphFrames prend désormais en charge l’API Pregel (Python) avec les optimisations de performances de Databricks.
- HorovodRunner ajoute :
- Sur un cluster GPU, les processus de formation sont mappés à des GPU plutôt qu’à des nœuds Worker afin de simplifier la prise en charge des types d’instance à plusieurs GPU. Cette prise en charge intégrée vous permet de distribuer à tous les GPU d’une machine à plusieurs GPU sans code personnalisé.
HorovodRunner.run()renvoie désormais la valeur renvoyée du premier processus de formation.
Consultez les notes de publication complètes sur Databricks Runtime 5.2 ML. d
Version 5.2 de Databricks Runtime
24 janvier 2019
Databricks Runtime 5.2 est désormais disponible. Databricks Runtime 5.2 comprend Apache Spark 2.4.0, de nouvelles fonctionnalités et mises à niveau de Delta Lake et Structured Streaming, ainsi que des bibliothèques Python, R, Java et Scala mises à niveau. Pour plus d’informations, consultez Databricks Runtime 5.2 (fin de support).
Vue du JSON de configuration d’un cluster
15-22 janvier 2019
La page de configuration du cluster prend désormais en charge une vue JSON :
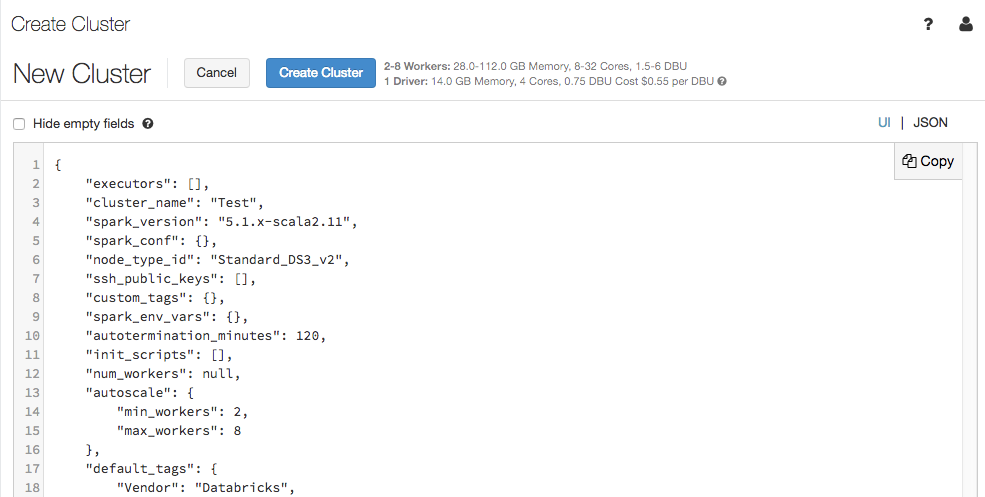
La vue JSON est en lecture seule. Toutefois, vous pouvez copier le JSON et l’utiliser pour créer et mettre à jour des clusters avec l'API Clusters.
IU du cluster
15-22 janvier 2019 : Version 2.89
La page de création du cluster a été nettoyée et réorganisée pour une utilisation plus facile, et intègre une nouvelle option Options avancées.
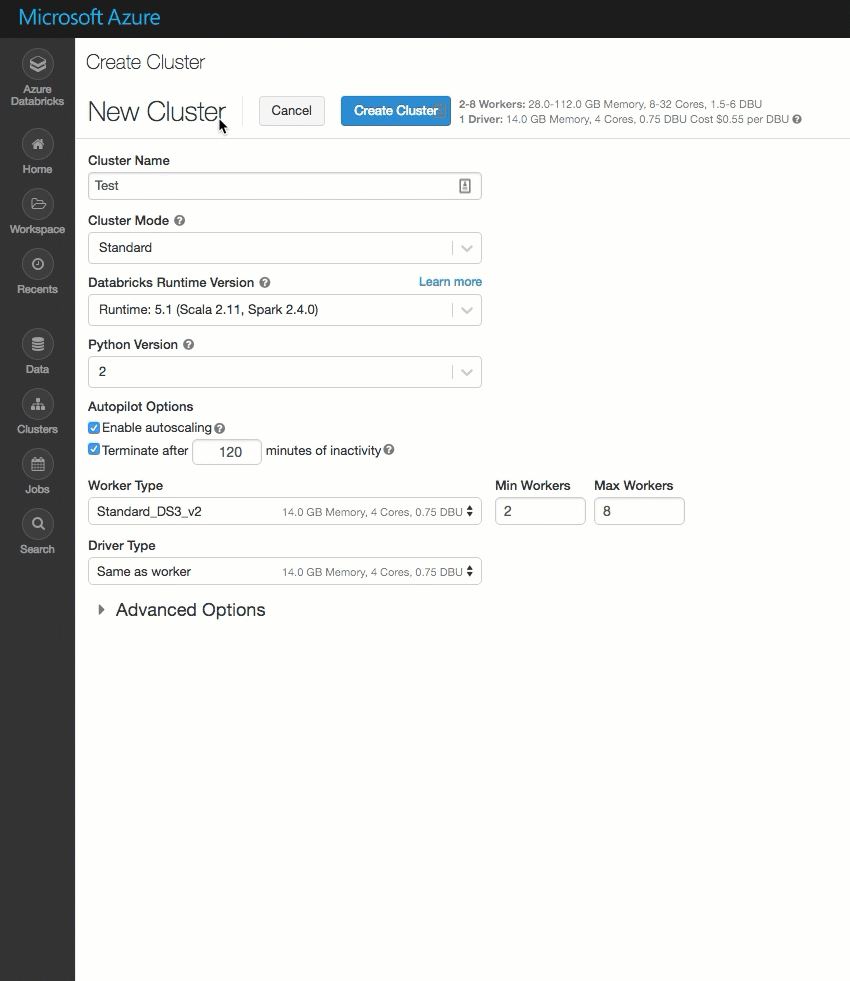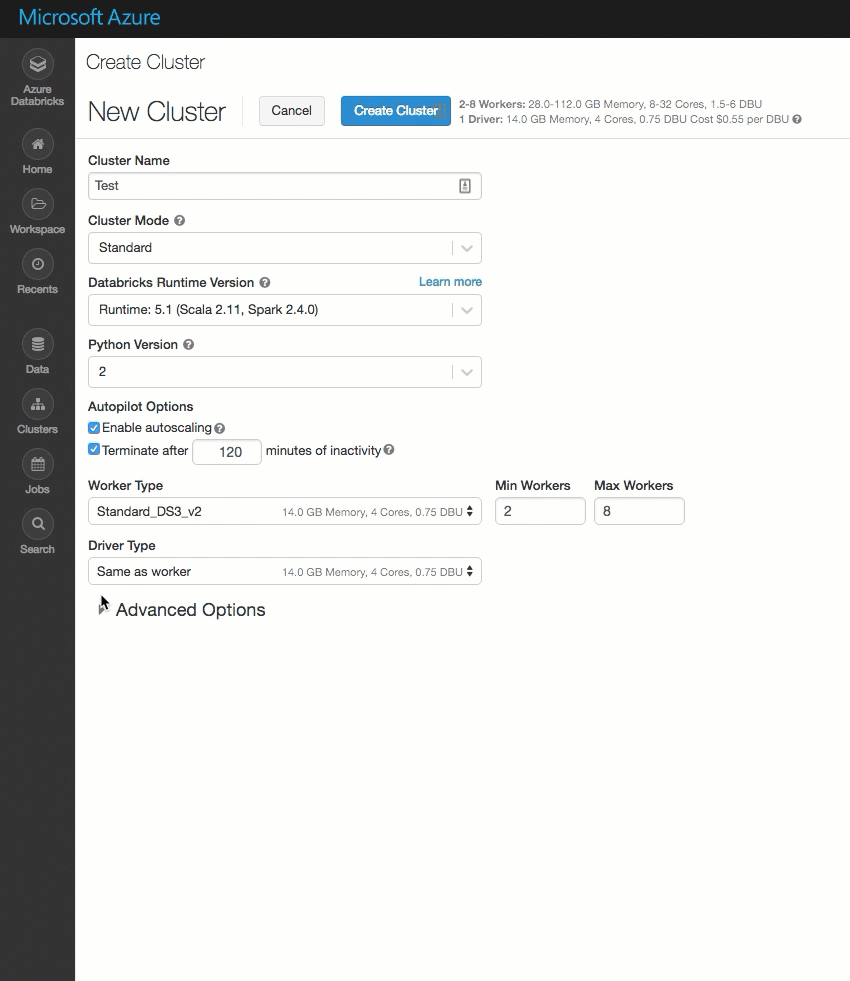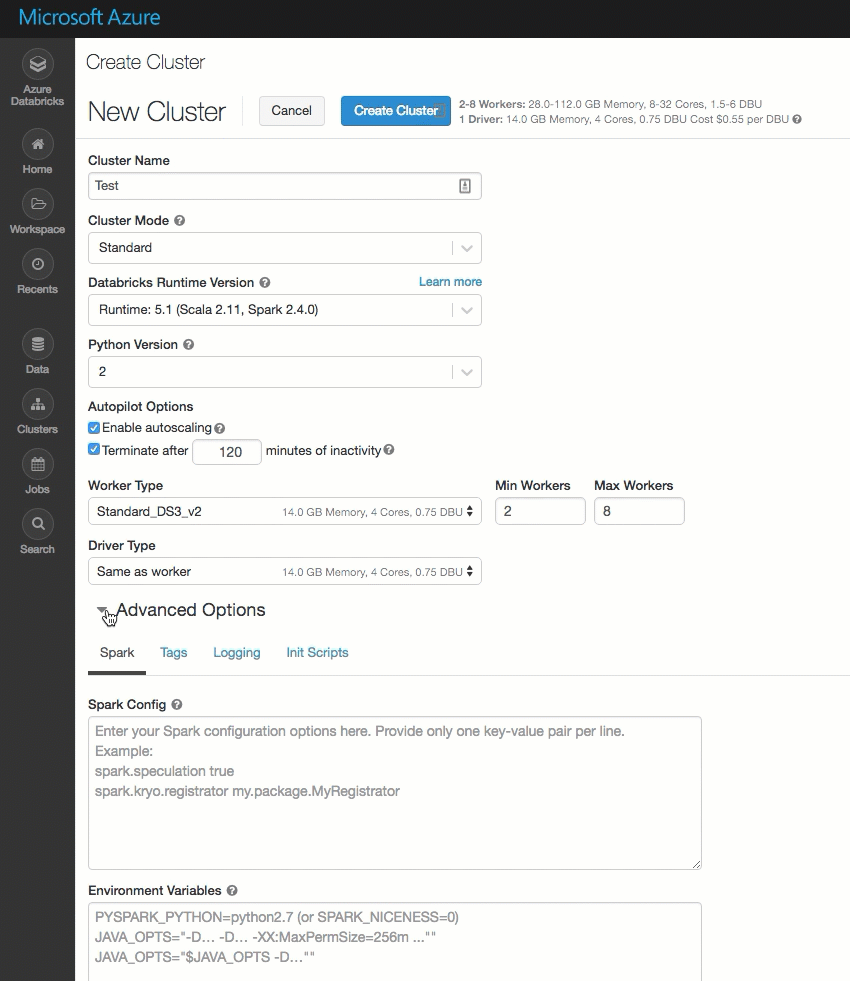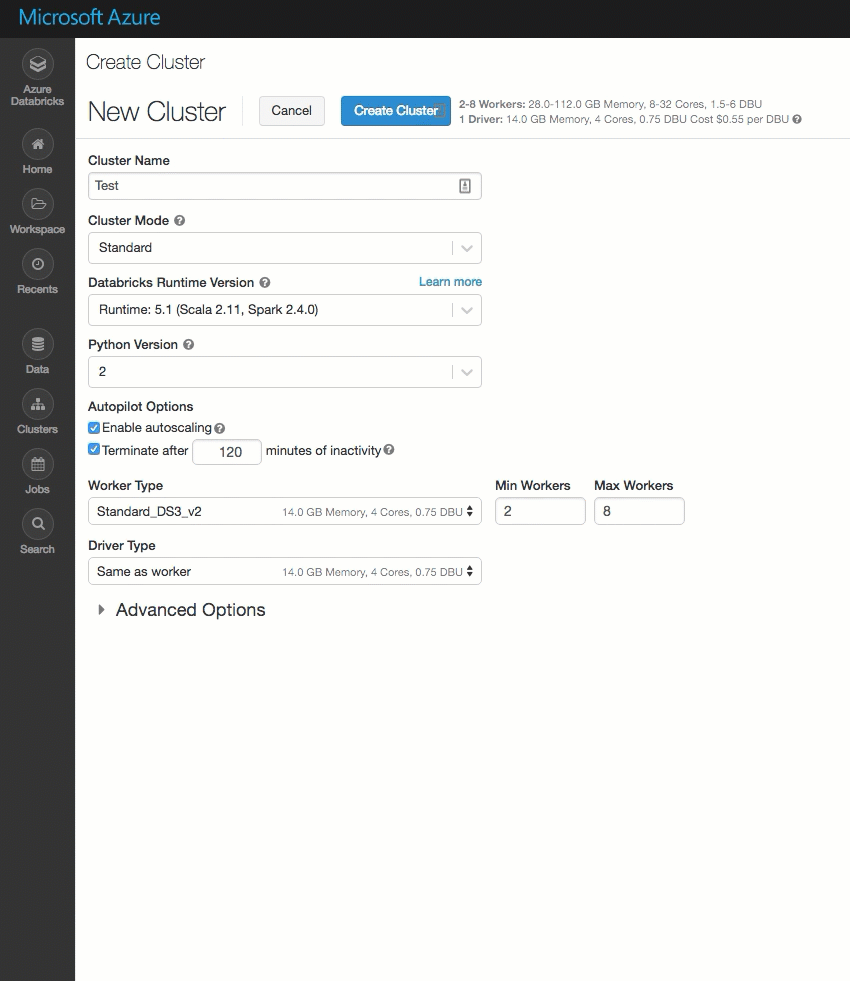
Déployer Azure Databricks dans votre propre réseau virtuel Azure (injection de réseau virtuel)
10 janvier 2019
Important
Cette fonctionnalité est disponible en préversion publique.
Le déploiement par défaut d’Azure Databricks est un service complètement managé sur Azure : toutes les ressources de plan de calcul, notamment un réseau virtuel (VNet) auquel tous les clusters sont associés, sont déployées sur un groupe de ressources verrouillé. Cependant, si vous devez personnaliser votre réseau, vous pouvez désormais déployer Azure Databricks dans votre propre réseau virtuel (ce qui parfois est appelé l’injection dans le réseau virtuel). Vous pouvez ainsi :
- Connecter Azure Databricks à d’autres services Azure (par exemple, Stockage Azure) de manière plus sécurisée à l’aide de points de terminaison de service.
- Vous connecter à des données sources locales pour les utiliser avec Azure Databricks, en tirant parti des routes définies par l’utilisateur.
- Connecter Azure Databricks à une appliance de réseau virtuel pour inspecter tout le trafic sortant et prendre des mesures appropriées pour autoriser et refuser des règles.
- configurer Azure Databricks pour utiliser un DNS personnalisé ;
- Configurer des règles de groupe de sécurité réseau (NSG) pour spécifier des restrictions sur le trafic de sortie.
- déployer des clusters Azure Databricks dans votre réseau virtuel existant.
Le déploiement d’Azure Databricks vers votre propre réseau virtuel vous permet également de tirer parti des plages d’adresses CIDR flexibles (n’importe où entre /16-/24 pour le réseau virtuel et entre /18-/26 pour les sous-réseaux).
La configuration à l’aide de l’interface utilisateur du portail Azure est simple et rapide : lorsque vous créez un espace de travail, sélectionnez Déployer un espace de travail Azure Databricks dans votre Réseau virtuel, sélectionnez votre réseau virtuel et fournissez des plages CIDR pour deux sous-réseaux. Azure Databricks met à jour le réseau virtuel avec deux nouveaux sous-réseaux et des groupes de sécurité réseau à l’aide de plages d’adresses CIDR que vous fournissez, vous permet d’accéder au trafic de sous-réseau entrant et sortant, puis déploie l’espace de travail sur le réseau virtuel mis à jour.
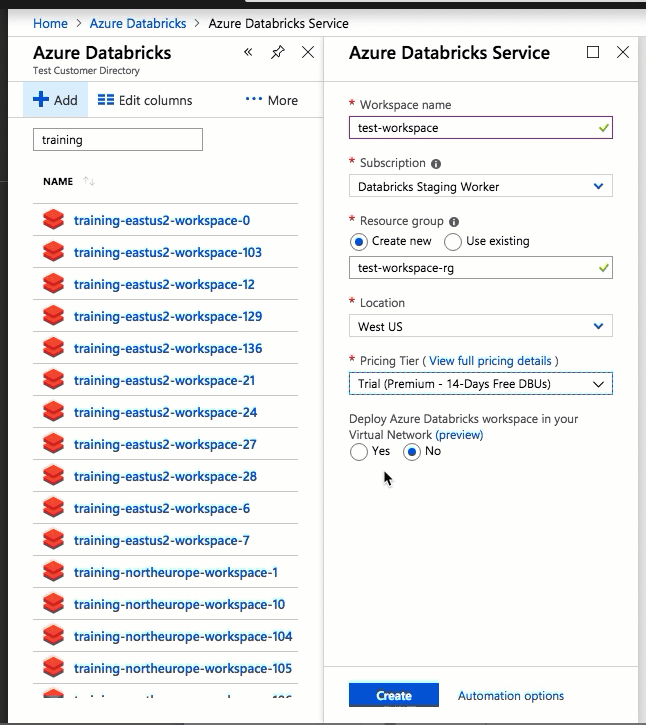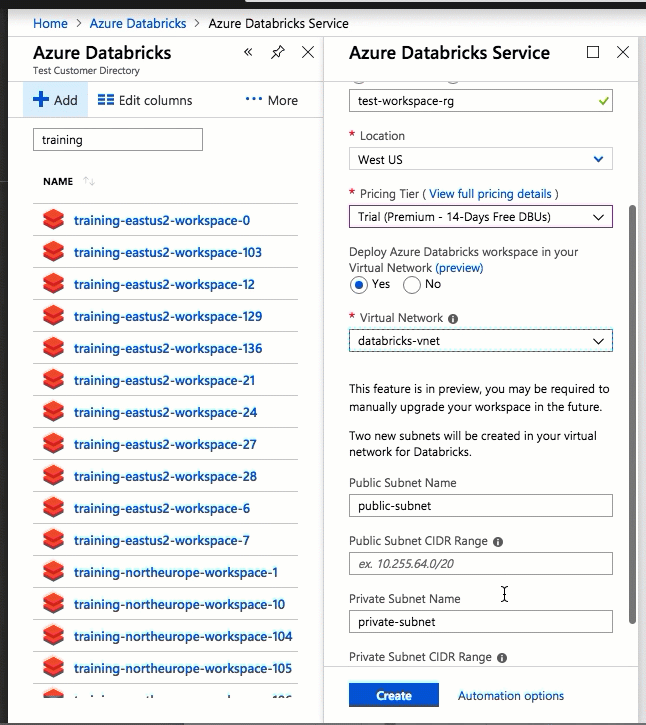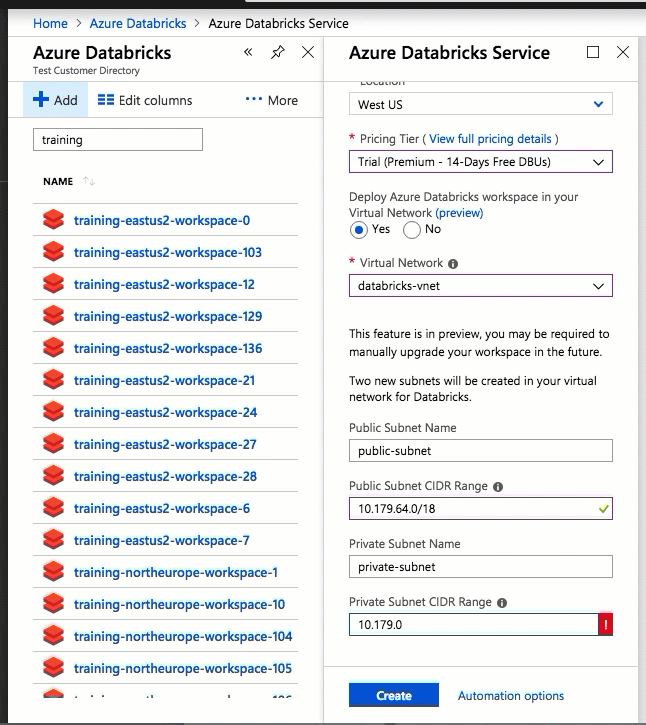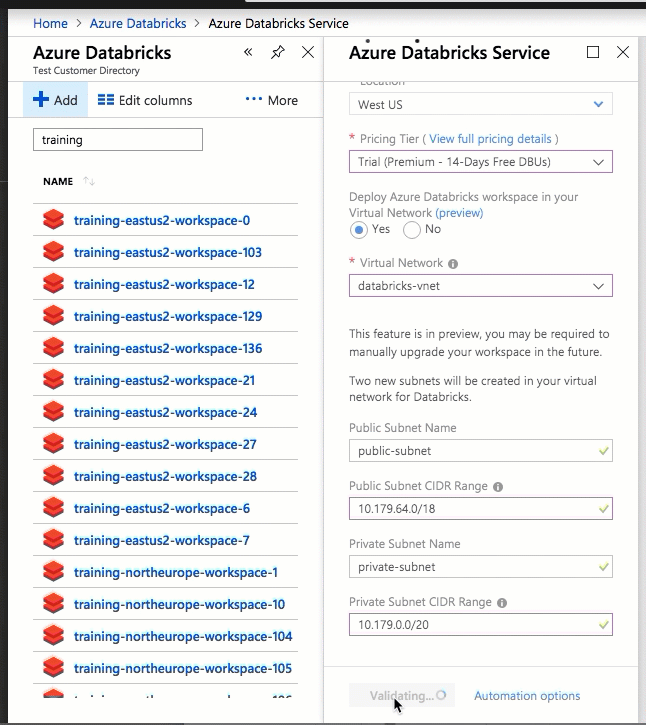
Si vous préférez configurer le réseau virtuel pour l’injection dans le réseau virtuel (par exemple, si vous souhaitez utiliser des sous-réseaux existants, utiliser des groupes de sécurité réseau existants ou créer vos propres règles de sécurité), vous pouvez utiliser des modèles ARM fournis avec Azure-Databricks au lieu de l’interface utilisateur du portail.
Notes
Cette fonctionnalité était précédemment disponible uniquement en vous inscrivant. Elle reste en préversion, mais elle est désormais entièrement en libre-service.
Pour plus d’informations, consultez Déployer Azure Databricks dans votre réseau virtuel Azure (injection dans le réseau virtuel) et Connecter votre espace de travail Azure Databricks à votre réseau local.
IU de la bibliothèque
2-9 janvier 2019 : Version 2.88
Les améliorations de l’interface utilisateur de la bibliothèque initialement publiées en novembre 2018 et rétablies peu après ont été republiées. Ces mises à jour facilitent le chargement, l’installation et la gestion des bibliothèques pour vos clusters Azure Databricks.
L’interface utilisateur d’Azure Databricks prend désormais en charge les bibliothèques d’espace de travail et les bibliothèques installées sur un cluster. Une bibliothèque d’espace de travail existe dans l’Espace de travail et peut être installée sur un ou plusieurs clusters. Une bibliothèque installée sur un cluster est une bibliothèque qui existe uniquement dans le contexte du cluster sur lequel elle est installée. Informations supplémentaires :
- Vous pouvez maintenant créer une bibliothèque à partir d’un fichier chargé dans le stockage d’objets.
- Vous pouvez maintenant installer et désinstaller des bibliothèques depuis la page de détails de la bibliothèque et de l’onglet Bibliothèques d’un cluster.
- Les bibliothèques installées à l’aide de l’API s’affichent désormais sous l’onglet Bibliothèques d’un cluster.
Pour plus d’informations, consultez Bibliothèques.
Événements de cluster
2-9 janvier 2019 : Version 2.88
De nouveaux événements de cluster ont été ajoutés pour refléter l’état du pilote Spark. Pour plus d’informations, consultez l’API Clusters.
Gestion de version des notebooks avec Azure DevOps Services
2-9 janvier 2019 : Version 2.88
Azure Databricks permet désormais d’utiliser facilement Azure DevOps Services (anciennement VSTS) pour contrôler la version de vos notebooks. L’authentification est automatique, le programme d’installation est simple et vous gérez les révisions de votre notebook comme vous le feriez avec notre intégration de GitHub.
Pour plus d’informations, consultez Contrôle de version Git pour les notebooks (hérité).