Octobre 2019
Ces fonctionnalités et améliorations de la plateforme Azure Databricks ont été publiées en octobre 2019.
Notes
Les publications se font par étapes. Votre compte Azure Databricks peut ne pas être mis à jour jusqu’à une semaine après la date de publication initiale.
Les métriques de capacité de prise en charge ont été déplacées vers Azure Event Hubs
22-29 octobre 2019
Les métriques de prise en charge qui permettent à Azure Databricks de surveiller l’intégrité du cluster ont été migrées depuis le stockage Blob Azure vers des points de terminaison Event Hubs. Cela permet à Azure Databricks de fournir des réponses de latence réduite pour résoudre les incidents des clients. Pour les espaces de travail d'injection de réseau virtuel, nous avons ajouté une règle supplémentaire au groupe de sécurité réseau pour le point de terminaison de service EventHub. Les détails sont disponibles dans le tableau Règles de groupe de sécurité réseau. Aucune action n’est requise pour la disponibilité continue des services.
Pour obtenir la liste des métriques des points de terminaison Event Hubs d’Azure Databricks par région, consultez Metastore, stockage Blob d’artefacts, stockage de tables système, stockage Blob de journaux, et adresses IP des points de terminaison Event Hubs.
Le passage d’informations d’identification Azure Data Lake Storage sur les clusters standard et Scala est en disponibilité générale
22-29 octobre 2019 : Version 3.5
Relais d’informations d’identification pour Python, SQL et Scala sur des clusters standard exécutant Databricks Runtime 5.5 et versions ultérieures, ainsi que SparkR sur Databricks Runtime 6.0 et versions ultérieures si elles sont en disponibilité générale. Consultez Activer le relais d’informations d’identification Azure Data Lake Storage pour un cluster Standard.
Databricks Runtime 6.1 pour la génomique (disponibilité générale)
22 octobre 2019
Databricks Runtime 6.1 pour Genomics est généralement disponible.
Databricks Runtime 6.1 pour le machine learning (disponibilité générale)
22 octobre 2019
Databricks Runtime 6.1 est désormais en disponibilité générale. Il prend en charge les clusters et mises à niveau GPU vers les bibliothèques de Machine Learning suivantes :
- TensorFlow à 1.14.0
- PyTorch à 1.2.0
- Torchvision à 0.4.0
- MLflow à 1.3.0
Pour obtenir plus d’informations, consultez les notes de publication complètes Databricks Runtime 6.1 pour ML (fin de support).
Les appels de l’API MLflow sont désormais à fréquence limitée
22-29 octobre 2019 : Version 3.5
Pour garantir une qualité de service élevée en cas de forte charge, Azure Databricks applique maintenant des limites de débit d’API pour tous les appel d'API MLflow. Les limites sont définies par compte pour garantir une utilisation équitable et une haute disponibilité pour toutes les organisations qui partagent un espace de travail.
Les clients MLflow peuvent utiliser les nouvelles tentatives automatiques disponibles dans MLflow 1.3.0 et se trouvent dans Databricks Runtime 6.1 pour ML (fin de support). Nous conseillons à tous les clients de basculer vers la dernière version de MLflow.
Pour plus d’informations, consultez API Expériences.
Disponibilité générale de pools d’instances pour un lancement rapide du cluster
22-29 octobre 2019 : Version 3.5
La fonctionnalité d’Azure Databricks qui prend en charge l’attachement d’un cluster à un pool prédéfini d’instances inactives est désormais mise à la disposition générale.
Azure Databricks ne facture pas de DBU durant le temps d’inactivité des instances dans le pool. La facturation du fournisseur d’instances s’applique par contre. Consultez les tarifs.
Pour plus de détails, consultez Informations de référence sur la configuration de pool.
Databricks Runtime 6.1 (disponibilité générale)
16 octobre 2019
Databricks Runtime 6.1 apporte plusieurs améliorations à Delta Lake :
- Conversion facile des tables au format Delta Lake
- API Python pour les tables Delta (préversion publique)
- Nettoyage de fichier dynamique (DFP) activé par défaut
Databricks Runtime 6.1 supprime également plusieurs restrictions dans le relais d’informations d’identification.
Notes
À partir de la version 6.1, Databricks Runtime prend uniquement en charge les clusters UC. Si vous souhaitez utiliser des clusters GPU, vous devez utiliser Databricks Runtime ML.
Pour obtenir plus d’informations, consultez les notes de publication complètes Databricks Runtime 6.1 (fin de support).
Databricks Runtime 6.0 pour la génomique (disponibilité générale)
16 octobre 2019
Databricks Runtime pour Genomics (Databricks Runtime Genomics) est une variante de Databricks Runtime optimisée pour l’utilisation de données génomiques et biomédicales. Depuis la version 6.0, Databricks Runtime pour Genomics est mis à la disposition générale.
La possibilité de déployer un espace de travail Azure Databricks sur votre réseau virtuel, opération également appelée injection de réseau virtuel, est mise à la disposition générale.
9 octobre 2019
Nous sommes heureux d’annoncer la disponibilité générale de la capacité à déployer un espace de travail Azure Databricks sur votre propre réseau virtuel, également appelé injection de réseau virtuel. Cette option est destinée aux personnes qui nécessitent une personnalisation du réseau et qui, par conséquent, ne souhaitent pas utiliser le réseau virtuel par défaut qui est créé lorsque vous déployez un espace de travail Azure Databricks de manière standard. Avec l’injection de réseau virtuel, vous pouvez :
- Connecter Azure Databricks à d’autres services Azure (par exemple, Stockage Azure) de manière plus sécurisée à l’aide de points de terminaison de service.
- Vous connecter à des données sources locales pour les utiliser avec Azure Databricks, en tirant parti des routes définies par l’utilisateur.
- Connecter Azure Databricks à une appliance de réseau virtuel pour inspecter tout le trafic sortant et prendre des mesures appropriées pour autoriser et refuser des règles.
- configurer Azure Databricks pour utiliser un DNS personnalisé ;
- Configurer des règles de groupe de sécurité réseau (NSG) pour spécifier des restrictions sur le trafic de sortie.
- déployer des clusters Azure Databricks dans votre réseau virtuel existant.
Le déploiement d’Azure Databricks vers votre propre réseau virtuel vous permet également de tirer parti des plages d’adresses CIDR flexibles (n’importe où entre /16-/24 pour le réseau virtuel et jusqu’à /26 pour les sous-réseaux).
La configuration à l’aide de l’interface utilisateur du portail Azure est simple et rapide : lorsque vous créez un espace de travail, sélectionnez Déployer un espace de travail Azure Databricks dans votre Réseau virtuel, sélectionnez votre réseau virtuel et fournissez des plages CIDR pour deux sous-réseaux. Azure Databricks met à jour le réseau virtuel avec les deux nouveaux sous-réseaux et des groupes de sécurité réseau, permet l’accès au trafic de sous-réseau entrant et sortant,et déploie l’espace de travail sur le réseau virtuel mis à jour.
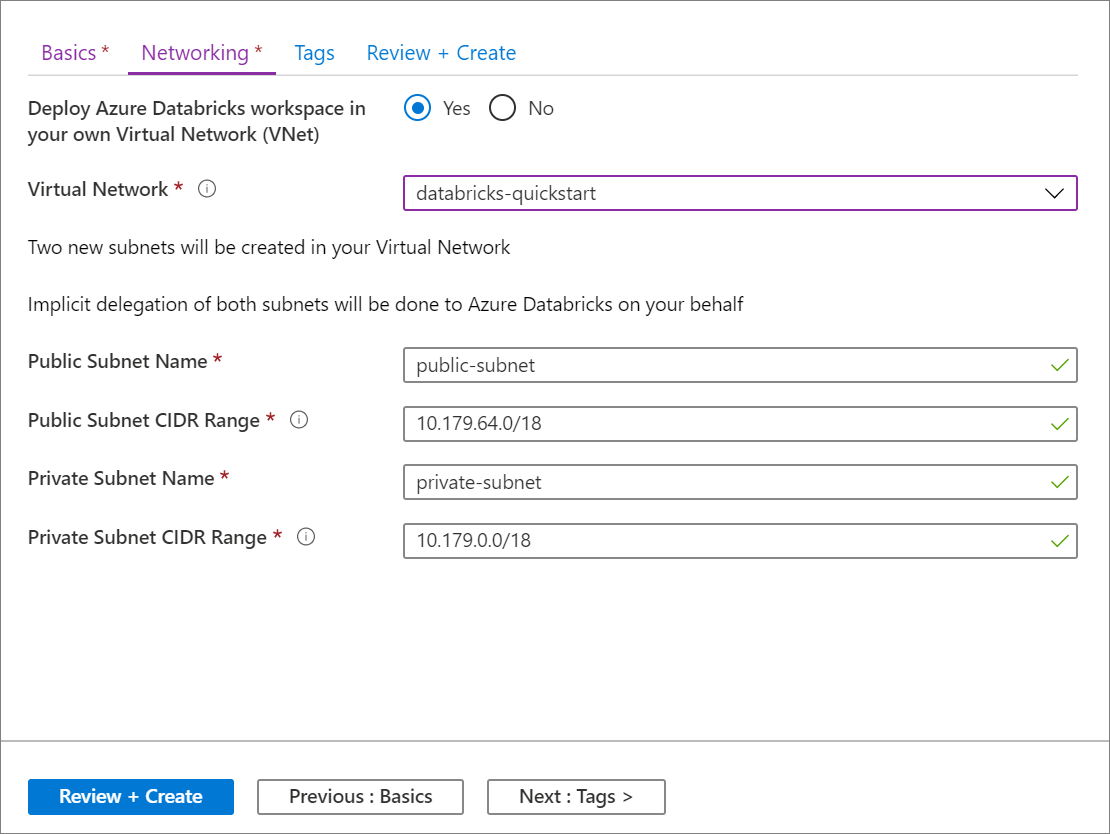
Si vous préférez configurer le réseau virtuel pour l’injection dans le réseau virtuel (par exemple, si vous souhaitez utiliser des sous-réseaux existants, utiliser des groupes de sécurité réseau existants ou créer vos propres règles de sécurité), vous pouvez utiliser des modèles ARM fournis avec Azure-Databricks au lieu de l’interface utilisateur du portail.
Notes
Si vous avez participé à la préversion de l’injection de réseau virtuel, vous devez mettre à niveau votre espace de travail en préversion vers la version à disponibilité générale avant le 31 janvier 2020 pour continuer à bénéficier du support.
Pour plus d’informations, consultez Déployer Azure Databricks dans votre réseau virtuel Azure (injection dans le réseau virtuel) et Connecter votre espace de travail Azure Databricks à votre réseau local.
Les utilisateurs d’Azure Databricks non-administrateurs peuvent lire les ID et les noms d’utilisateurs et de groupes à l’aide de l’API SCIM
8-15 octobre 2019 : Version 3.4
Les utilisateurs non-administrateurs peuvent désormais appeler les API Groupes Points de terminaison Get Users et Get Groups pour lire uniquement les noms d’affichage et ID d’un utilisateur et groupe. Toutes les autres opérations de l’API SCIM continuent d’exiger un accès administrateur.
L’API de l’espace de travail retourne les ID d’objet de dossier et de notebook
8-15 octobre 2019 : Version 3.4
Les points de terminaison get-status et list de l’API d’espace de travail retournent désormais les ID des notebooks et des dossiers, ce qui vous donne la possibilité de référencer ces objets dans d’autres appels d’API.
Databricks Runtime 6.0 ML (disponibilité générale)
4 octobre 2019
Databricks Runtime 6.0 ML comprend les mises à jour suivantes :
- MLflow
- Une nouvelle source de données Spark pour les expériences MLflow fournit désormais une API standard pour charger les données d’expérience MLflow.
- Ajout du client MLflow Java
- MLflow est maintenant promu comme bibliothèque de niveau supérieur
- Hyperopt (disponibilité générale) : Les améliorations notables apportées depuis la préversion publique incluent la prise en charge de la journalisation MLflow sur des workers Spark, la gestion correcte des variables de diffusion PySpark, ainsi qu’un nouveau guide sur la sélection de modèle à l’aide d’Hyperopt.
- Mise à niveau des bibliothèques Horovod et MLflow et distribution Anaconda.
Notes
Seuls les clusters UC sont pris en charge dans cette version.
Pour obtenir plus d’informations, consultez les notes de publication complètes Databricks Runtime 6.0 pour ML (fin de support).
Nouvelles régions : Brésil Sud et France Centre
1er octobre 2019
Azure Databricks est désormais disponible au Brésil Sud (État de Sao Paolo) et en France Centre (Paris).
Databricks Runtime 6.0 (disponibilité générale)
1er octobre 2019
Databricks Runtime 6.0 apporte de nombreuses mises à niveau de la bibliothèque et de nouvelles fonctionnalités, notamment :
- Nouvelles API Scala et Java pour les commandes DML de Delta Lake, ainsi que les commandes d’utilitaire de nettoyage et d’historique.
- Client DBFS FUSE amélioré pour des lectures et écritures plus rapides et fiables pendant la formation du modèle.
- Prise en charge de plusieurs tracés matplotlib par cellule de notebook.
- Mise à jour vers Python 3.7, ainsi que mise à jour de numpy, pandas, matplotlib et d’autres bibliothèques.
- Support du Sunset de Python 2.
Notes
Seuls les clusters UC sont pris en charge dans cette version.
Pour obtenir plus d’informations, consultez les notes de publication complètes Databricks Runtime 6.0 (fin de support).