Septembre 2019
Ces fonctionnalités et améliorations de la plateforme Azure Databricks ont été publiées en septembre 2019.
Notes
Les publications se font par étapes. Votre compte Azure Databricks peut ne pas être mis à jour jusqu’à une semaine après la date de publication initiale.
Fin du support de Databricks Runtime 5.2
30 septembre 2019
La prise en charge de Databricks Runtime 5.2 a pris fin le 30 septembre. Consultez Cycles de vie du support de Databricks.
Lancer des clusters automatisés reposant sur un pool qui utilisent Databricks Light (préversion publique)
26 septembre - 1e octobre 2019 : Version 3.3
Lorsque nous avons présenté les Informations de référence sur la configuration de pool en juillet, vous ne pouviez pas sélectionner Databricks Light comme version du runtime lorsque configuriez un cluster reposant sur un pool pour une tâche automatisée. Vous pouvez désormais avoir des temps de démarrage de cluster rapides et des clusters rentables.
Les adresses IP de la passerelle Azure SQL Database ont changé le 14 octobre 2019
Le 14 octobre, Microsoft opérera la migration du trafic vers de nouvelles passerelles dans ces régions. Si votre espace de travail se trouve dans l’une de ces régions et que vous avez configuré des itinéraires définis par l’utilisateur (UDR) pour le metastore consolidé à partir de votre propre réseau virtuel Azure Databricks (à l’aide d’une « injection dans le réseau virtuel »), il se peut que vous deviez mettre à jour l’adresse IP du metastore lorsque ces adresses IP changent. Consultez la table des adresses IP de passerelle Azure SQL Database pour obtenir la liste la plus récente des adresses IP de votre région.
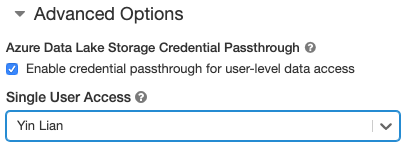
Le passage des informations d’identification à Azure Data Lake Storage est désormais pris en charge sur les clusters standard et Scala (préversion publique)
12-17 septembre 2019 : Version 3.2
Vous pouvez désormais utiliser un relais d’informations d’identification avec Python, SQL et Scala sur des clusters standard exécutant Databricks Runtime 5.5 et versions ultérieures, ainsi que SparkR sur Databricks Runtime 6.0 version bêta. Jusqu’à présent, le relais de données d’identification nécessitait des clusters à forte concurrence qui ne prennent pas en charge Scala.
Quand un cluster est activé pour le relais d’informations d’identification Azure AD Lake Storage, les commandes exécutées sur ce cluster peuvent lire et écrire des données dans Azure Data Lake Storage sans que les utilisateurs doivent configurer les informations d’identification du principal de service pour accéder au stockage. Les informations d’identification sont définies automatiquement à partir de l’utilisateur à l’origine de l’action.
Par souci de sécurité, un seul utilisateur peut exécuter des commandes sur un cluster standard sur lequel le relais d’informations d’identification est activé. L’utilisateur unique est défini au moment de la création et peut être modifié par toute personne disposant d’autorisations de gestion sur le cluster. Les administrateurs doivent s’assurer que l’utilisateur unique dispose au moins de l’autorisation d’attacher sur le cluster.
Les DataFrames pandas s’affichent désormais dans les notebooks sans mise à l’échelle
12-17 septembre 2019 : Version 3.2
Dans les notebooks Azure Databricks, le displayHTML mettait à l’échelle du contenu HTML encadré pour l’adapter à la largeur disponible du notebook rendu. Si ce comportement était souhaitable pour les images, le rendu de trames de données Pandas était médiocre. Mais ce n’est plus le cas !
L’affichage du sélecteur de version Python est maintenant dynamique
12-17 septembre 2019 : Version 3.2
Lorsque vous sélectionnez un runtime Databricks qui ne prend pas en charge Python 2 (comme Databricks 6.0), la page de création de cluster masque le sélecteur de version Python.
Databricks Runtime 6.0 bêta
12 septembre 2019
Databricks Runtime 6.0 (bêta) apporte de nombreuses mises à niveau de bibliothèque et nouvelles fonctionnalités, à savoir :
- Nouvelles API Scala et Java pour les commandes DML de Delta Lake, ainsi que les commandes d’utilitaire de nettoyage et d’historique.
- Client DBFS FUSE v2 amélioré pour des lectures et écritures plus rapides et fiables pendant l’apprentissage du modèle.
- Prise en charge de plusieurs tracés matplotlib par cellule de notebook.
- Mise à jour vers Python 3.7, ainsi que mise à jour de numpy, pandas, matplotlib et d’autres bibliothèques.
- Crépuscule du support pour Python 2.
Pour obtenir plus d’informations, consultez les notes de publication complètes Databricks Runtime 6.0 (fin de support).