Juillet 2020
Ces fonctionnalités et améliorations de la plateforme Azure Databricks ont été publiées en juillet 2020.
Notes
Les publications se font par étapes. Votre compte Azure Databricks peut ne pas être mis à jour jusqu’à une semaine après la date de publication initiale.
Terminal web (préversion publique)
29 juillet - 4 août 2020 : version 3.25
Le terminal Web offre aux utilisateurs disposant de l’autorisation PEUT ATTACHER À sur un cluster un moyen pratique et très interactif d’exécuter des commandes shell, y compris des éditeurs tels que Vim ou Emacs. Les exemples d’utilisation du terminal Web incluent la surveillance de l’utilisation des ressources et l’installation de packages Linux.
Pour plus d’informations, consultez Exécuter des commandes d’interpréteur de commandes dans un terminal web Azure Databricks.
Nouveau framework de script d’initialisation global plus sécurisé (préversion publique)
29 juillet au 4 août 2020 : version 3.25
Le nouveau cadre de script init global apporte des améliorations significatives par rapport aux anciens scripts init globaux :
- Les scripts init sont plus sécurisés, ce qui requiert des autorisations d’administrateur pour créer, afficher et supprimer.
- Les échecs de lancement liés aux scripts sont journalisés.
- Vous pouvez définir l’ordre d’exécution de plusieurs scripts init.
- Les scripts init peuvent faire référence à des variables d’environnement associées au cluster.
- Les scripts d’initialisation peuvent être créés et gérés à l’aide de la page des paramètres d’administration ou de la nouvelle API REST des scripts d’initialisation globaux.
Databricks vous recommande de migrer des scripts init globaux hérités existants vers la nouvelle infrastructure pour tirer parti de ces améliorations.
Pour plus d’informations, consultez Scripts init globaux.
Listes d’accès IP maintenant en disponibilité générale
29 juillet au 4 août 2020 : version 3.25
L’API de liste d’accès IP est désormais généralement disponible.
La version GA comprend une modification, qui consiste à renommer les valeurs list_type :
- Il lance
WHITELISTsurALLOW. - Il lance
BLACKLISTsurBLOCK.
Utilisez l'API Liste d'accès IP pour configurer vos espaces de travail Azure Databricks afin que les utilisateurs se connectent au service uniquement via les réseaux d'entreprise existants avec un périmètre sécurisé. Les administrateurs d'Azure Databricks peuvent utiliser l'API Liste d'accès IP pour définir un ensemble d'adresses IP approuvées, y compris des listes d'autorisation et de blocage. Tout accès entrant à l’application web et aux API REST nécessite que l’utilisateur se connecte à partir d’une adresse IP autorisée, garantissant ainsi que les espaces de travail ne sont pas accessibles à partir d’un réseau public comme un café ou un aéroport, à moins que vos utilisateurs n’utilisent un VPN.
cette fonctionnalité nécessite le plan Premium.
Pour plus d’informations, consultez Configurer des listes d’accès IP pour les espaces de travail.
Nouvelle boîte de dialogue de chargement de fichier
29 juillet au 4 août 2020 : version 3.25
Vous pouvez désormais charger des fichiers de données tabulaires de petite taille (comme les csv) et y accéder à partir d’un notebook en sélectionnant Ajout de données dans le menu Fichier du notebook. Le code généré vous montre comment charger les données dans Pandas ou DataFrames. Les administrateurs peuvent désactiver cette fonctionnalité dans l’onglet avancé de la console d’administration.
Pour plus d’informations, consultez Parcourir les fichiers dans DBFS.
Améliorations du filtre et du tri dans l’API SCIM
29 juillet - 4 août 2020 : version 3.25
L’API SCIM comprend désormais les améliorations de filtrage et de tri suivantes :
- Les administrateurs peuvent filtrer les utilisateurs sur l’attribut
active. - Tous les utilisateurs peuvent trier les résultats en utilisant les paramètres de requête
sortByetsortOrder. Le tri par ID est le tri par défaut.
Ajout de régions Azure Government
25 juillet 2020
Azure Databricks récemment disponible dans les régions US Gov Arizona et US Gov Virginie pour les entités gouvernementales américaines et leurs partenaires.
Databricks Runtime 7.1 GA
21 juillet 2020
Databricks Runtime 7.1 apporte de nombreuses fonctionnalités et améliorations supplémentaires par rapport à Databricks Runtime 7.0, notamment :
- Connecteur Google BigQuery
%pipcommandes pour gérer les bibliothèques python installées dans une session de bloc-notes- Koalas installé
- De nombreuses améliorations Delta Lake, notamment :
- Définition des métadonnées de validation définies par l’utilisateur
- Obtention de la version de la dernière validation écrite par le
SparkSessionactuel - Conversion de tables parquet créées par Structured streaming à l’aide du journal des transactions
_spark_metadata MERGE INTOAmélioration des performances
Pour plus d’informations, consultez les notes de publication complètes Databricks Runtime 7.1 (fin de support).
Databricks Runtime 7.1 ML GA
21 juillet 2020
Databricks Runtime 7.1 pour Machine Learning repose sur Databricks Runtime 7.1 et apporte les nouvelles fonctionnalités et modifications de bibliothèque suivantes :
- commandes Magic PIP et Conda activées par défaut
- spark-tensorflow-distributor: 0.1.0
- pillow 7.0.0 -> 7.1.0
- pytorch 1.5.0 -> 1.5.1
- torchvision 0.6.0 -> 0.6.1
- horovod 0.19.1 -> 0.19.5
- mlflow 1.8.0 -> 1.9.1
Pour plus d’informations, consultez les notes de publication complètes Databricks Runtime 7.1 pour ML (fin de support).
Databricks Runtime 7.1 Genomics GA
21 juillet 2020
Databricks Runtime 7.1 pour Genomics s’appuie sur Databricks Runtime 7.1 et comprend les nouvelles fonctionnalités suivantes :
- Transformation LOCO
- Fonction de remodelage de sortie GloWGR
- RNASeq renvoie les alignements non appariés
Databricks Connect 7.1 (préversion publique)
17 juillet 2020
Databricks Connecter 7.1 est désormais en version préliminaire publique.
Mises à jour de l’API Liste d’accès IP
15 au 21 juillet 2020 : version 3.24
Les propriétés suivantes de l' API de liste d’accès IP ont changé :
- Il lance
updator_user_idsurupdated_by. - Il lance
creator_user_idsurcreated_by.
Les notebooks Python prennent désormais en charge plusieurs sorties par cellule
15 au 21 juillet 2020 : version 3.24
Les notebooks Python prennent désormais en charge plusieurs sorties par cellule. Cela signifie que vous pouvez avoir un nombre illimité d'instructions d'affichage, d'affichage HTML ou d'impression dans une cellule. Tirez parti de la possibilité d’afficher les données brutes et le tracé dans la même cellule, ou toutes les sorties qui ont réussi avant que vous n’ayez rencontré une erreur.
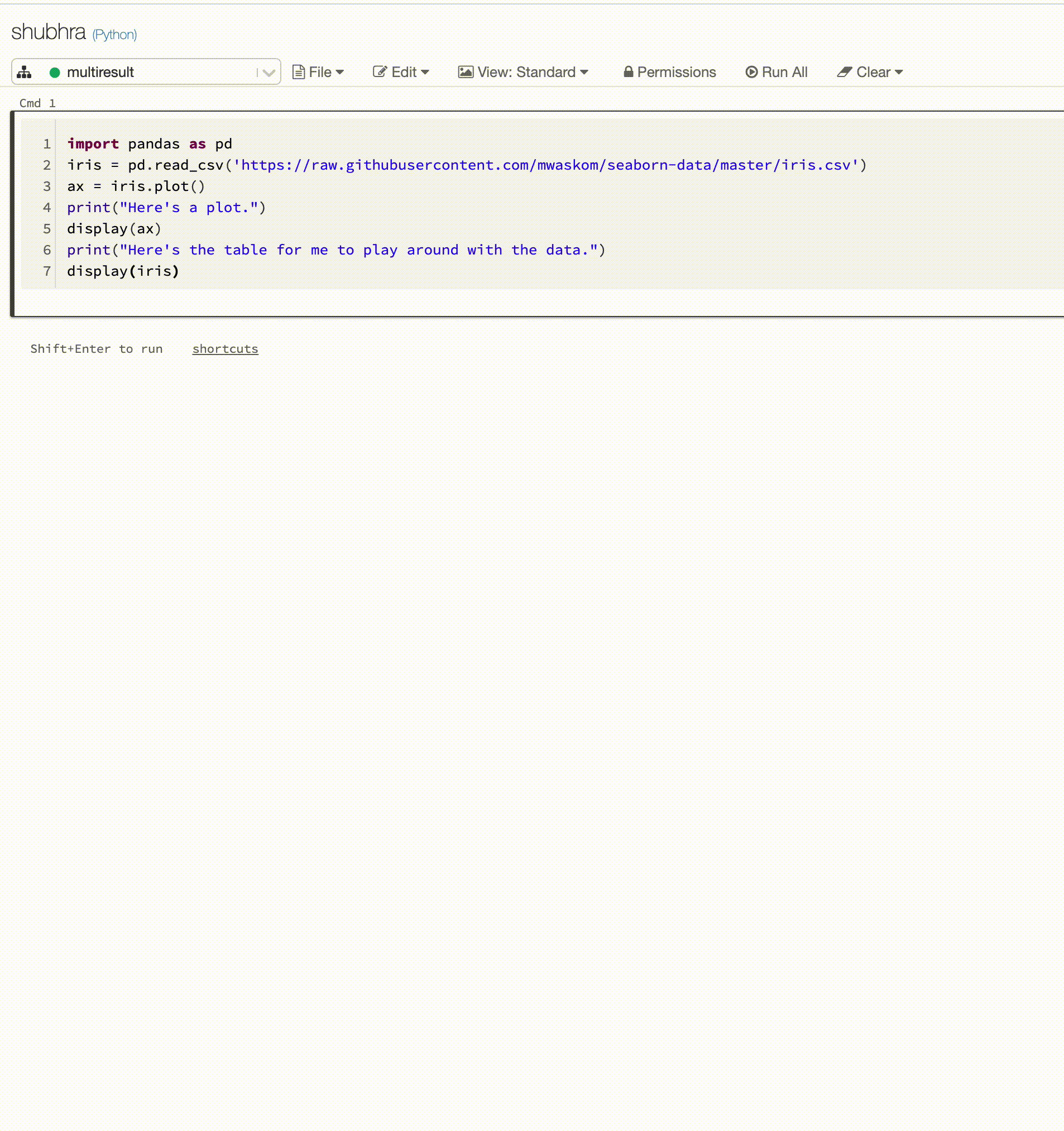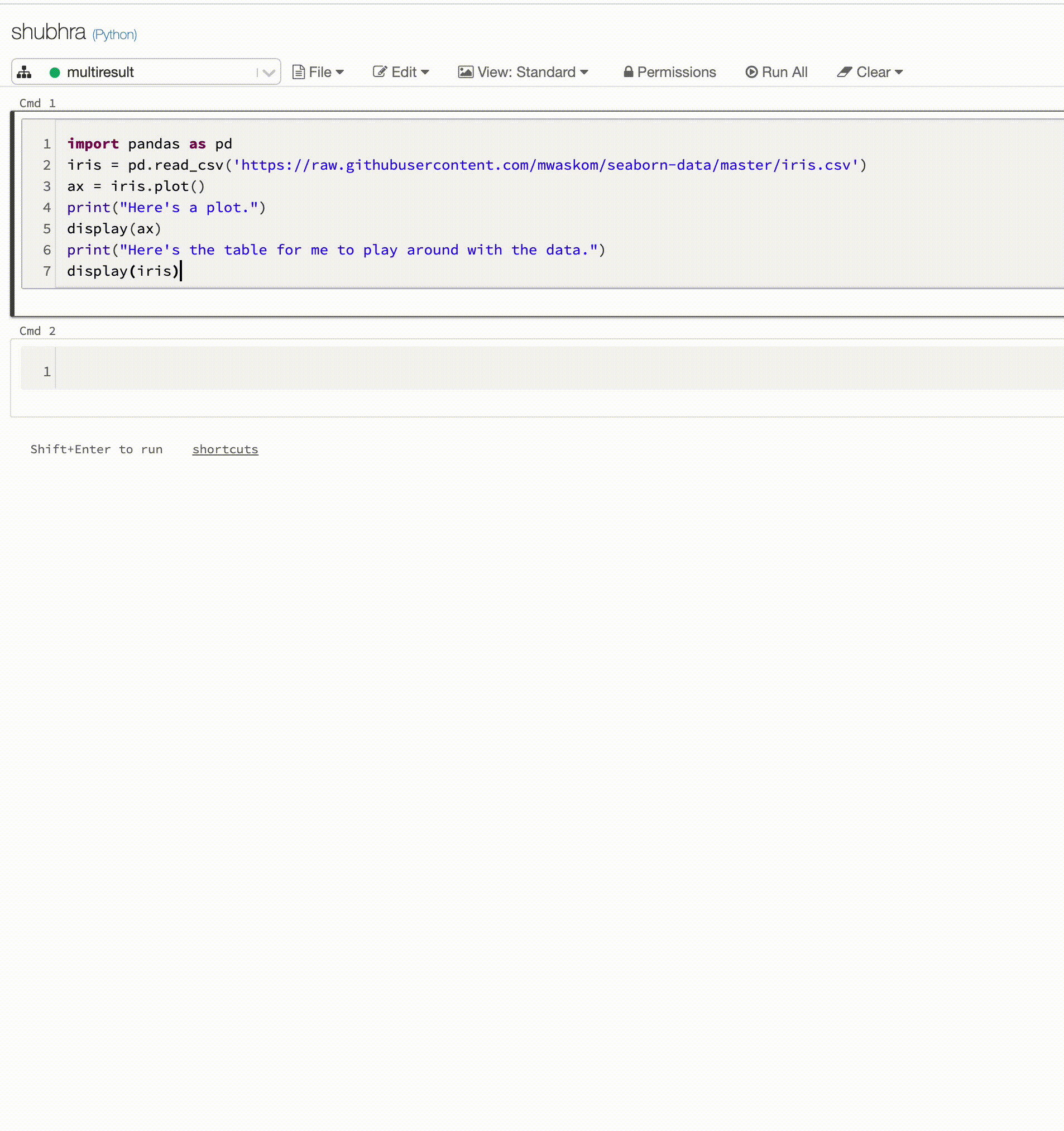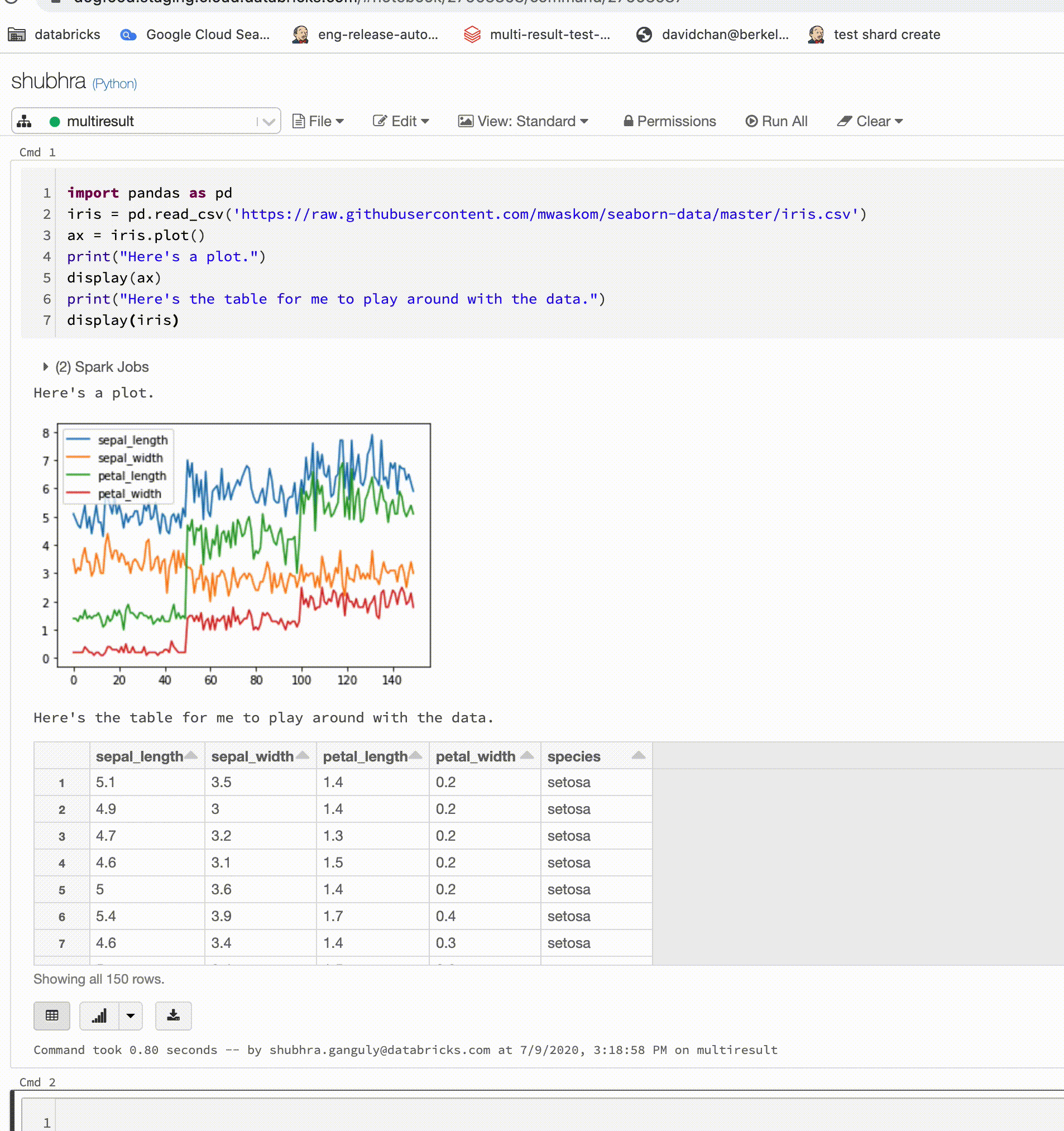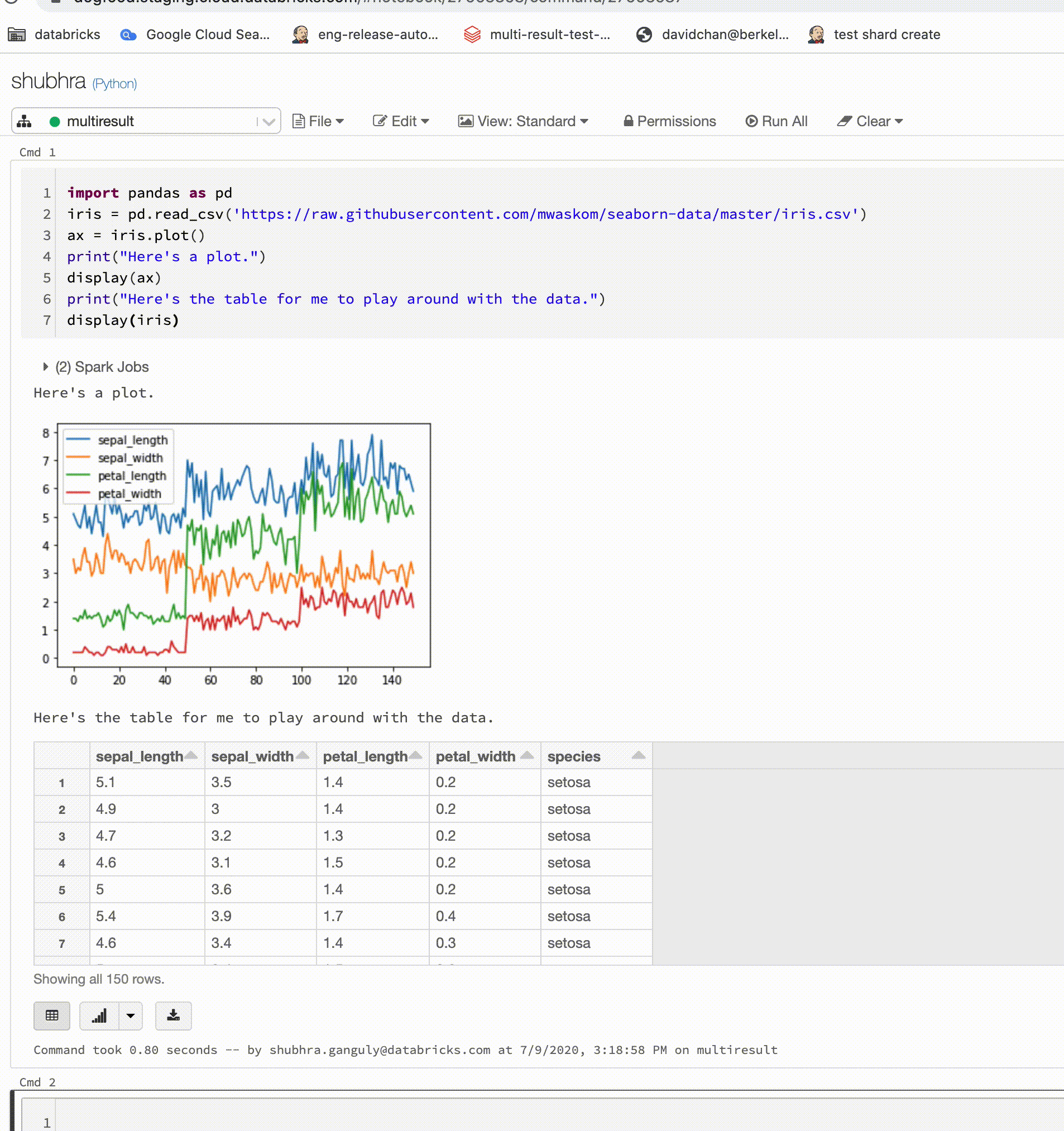
Cette fonctionnalité requiert Databricks Runtime 7.1 ou version ultérieure et est désactivée par défaut dans Databricks Runtime 7.1. Activez-le en définissant spark.databricks.workspace.multipleResults.enabled true.
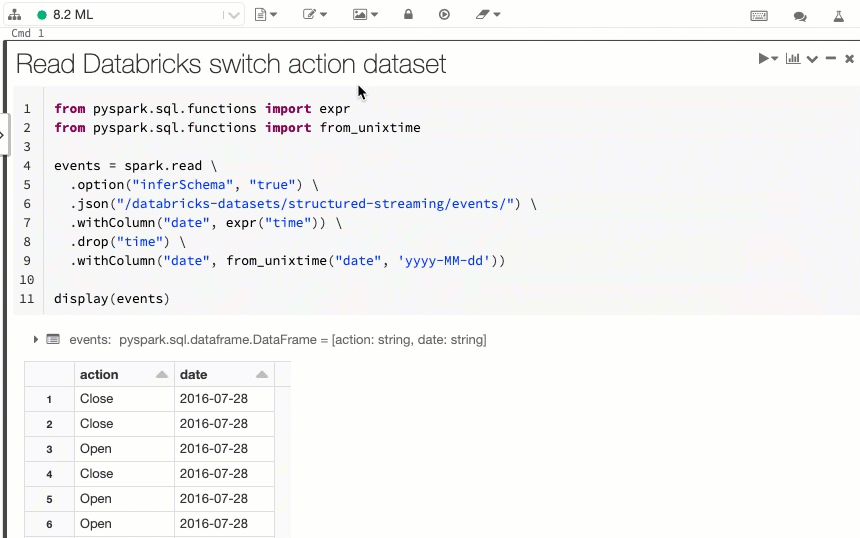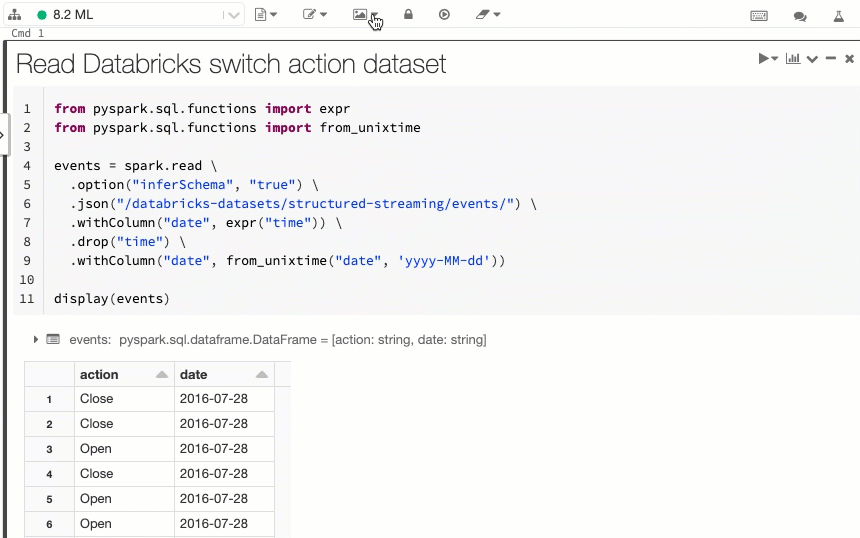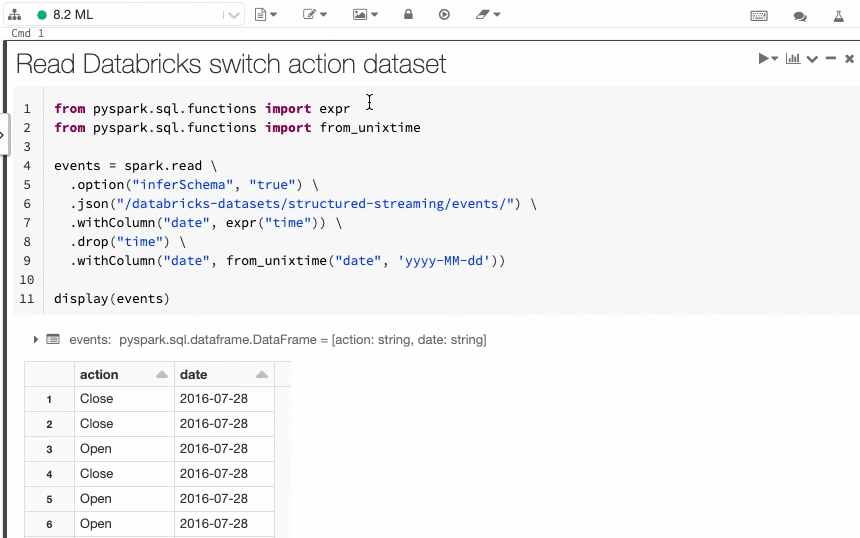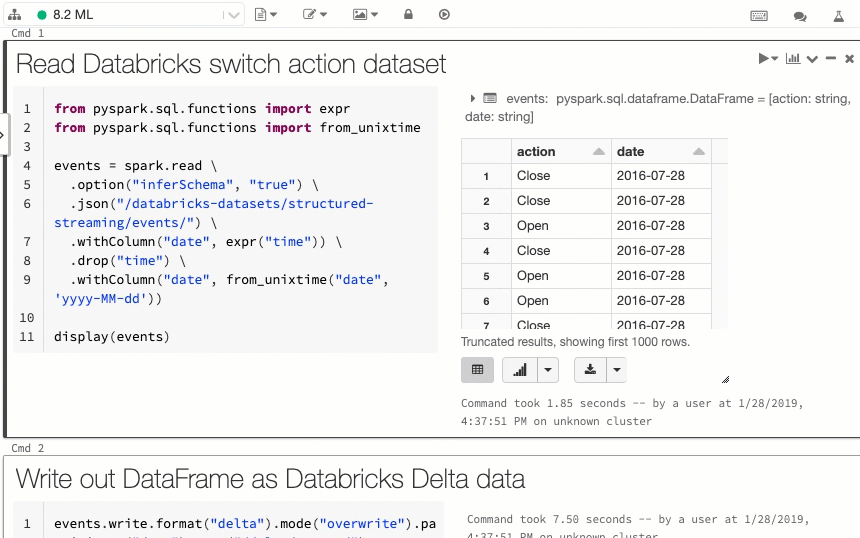
Afficher les cellules de code et de résultats des notebooks côte à côte
15 au 21 juillet 2020 : version 3.24
La nouvelle option d’affichage de bloc-notes côte à côte vous permet d’afficher le code et les résultats les uns à côté des autres. Cette option d’affichage joint l’option « standard » (anciennement « code ») et l’option « résultats uniquement ».
Mettre en pause les planifications de travaux
15 au 21 juillet 2020 : version 3.24
Les planifications de travaux disposent désormais de boutonsPause et pause, ce qui facilite l’interruption et la reprise des tâches. Vous pouvez désormais apporter des modifications à une planification de travail sans exécution de travaux supplémentaires à partir du moment où vous effectuez les modifications. Les exécutions ou les exécutions en cours déclenchées par exécuter maintenant ne sont pas affectées. Pour plus d’informations, consultez suspendre et reprendre des déclencheurs de travail.
Les points de terminaison des API de travaux valident l’ID d’exécution
15 au 21 juillet 2020 : version 3.24
Les points de terminaison de l' API jobs/runs/cancel et jobs/runs/output vérifient désormais que le paramètre run_id est valide. Pour les paramètres non valides, ces points de terminaison d’API renvoient désormais le code d’état HTTP 400 au lieu du code 500.
Jetons Microsoft Entra ID pour accorder des autorisations sur l’API REST Databricks Disponibilité générale
15 au 21 juillet 2020 : version 3.24
L’utilisation de jetons Microsoft Entra ID pour l’authentification sur l’API Espace de travail est désormais en disponibilité générale. Les jetons Microsoft Entra ID vous permettent d’automatiser la création et la configuration de nouveaux espaces de travail. Les principaux de service sont des objets d'application dans Microsoft Entra ID. Vous pouvez également utiliser des principes de service dans vos espaces de travail Azure Databricks pour automatiser les flux de travail. Pour plus d’informations, consultez Authentifier l’accès aux ressources Azure Databricks.
Mettre automatiquement en forme le SQL dans les notebooks
15 au 21 juillet 2020 : version 3.24
vous pouvez désormais mettre en forme SQL cellules du bloc-notes à partir d’un raccourci clavier, du menu contextuel de commande et du menu édition du bloc-notes (sélectionnez modifier > le format SQL cellules). SQL la mise en forme facilite la lecture et la maintenance du code avec un minimum d’effort. il fonctionne pour les blocs-notes SQL et les cellules %sql.

Ordre d’installation reproductible pour les bibliothèques Maven et CRAN
1 au 9 juillet 2020 : version 3.23
Azure Databricks traite désormais les bibliothèques Maven et CRAN dans l’ordre dans lequel elles ont été installées sur le cluster.
Prendre le contrôle des jetons d’accès personnels de vos utilisateurs avec l’API de gestion des jetons (préversion publique)
1 au 9 juillet 2020 : version 3.23
Les administrateurs Azure Databricks peuvent utiliser l’API de gestion des jetons et la console d’administration pour gérer les jetons d’accès personnels Azure Databricks des utilisateurs.
- Superviser et révoquer les jetons d’accès personnels des utilisateurs.
- Contrôler la durée de vie des futurs jetons dans votre espace de travail.
- Gérer les utilisateurs qui peuvent créer ou utiliser des jetons.
Consultez Surveiller et révoquer des jetons d’accès personnels.
Restaurer les cellules de notebook coupées
1 au 9 juillet 2020 : version 3.23
Vous pouvez maintenant restaurer les cellules du cahier qui ont été coupées, soit en utilisant le raccourci clavier (Z), soit en sélectionnant Modifier> Annuler les cellules coupées. Cette fonctionnalité est analogue à celle de l’inversion des cellules supprimées.
Affecter l’autorisation PEUT GÉRER sur des travaux aux utilisateurs non-administrateurs
1 au 9 juillet 2020 : version 3.23
Vous pouvez désormais assigner à des utilisateurs et des groupes non-administrateurs l’autorisation PEUT GÉRER sur les travaux. Ce niveau d’autorisation permet aux utilisateurs de gérer tous les paramètres du travail, y compris l’attribution d’autorisations, la modification du propriétaire et la modification de la configuration du cluster (par exemple, l’ajout de bibliothèques et la modification de la spécification du cluster). Voir Contrôler l’accès à un travail.
Les utilisateurs Azure Databricks non-administrateurs peuvent afficher et filtrer par nom d’utilisateur avec l’API SCIM
1 au 9 juillet 2020 : version 3.23
Les utilisateurs non administrateurs peuvent désormais afficher les noms d'utilisateur et filtrer les utilisateurs par nom d'utilisateur à l'aide du point de terminaison SCIM /Users.
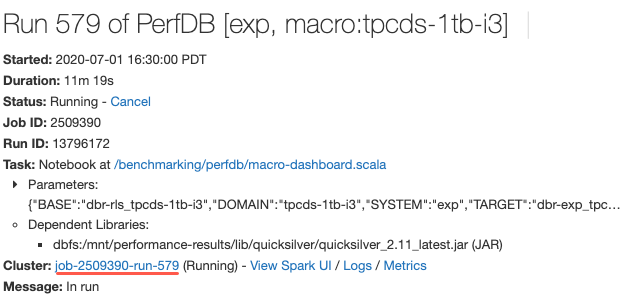
Lien pour afficher la spécification du cluster lorsque vous consultez les détails de l’exécution du travail
1 au 9 juillet 2020 : version 3.23
Désormais, lorsque vous affichez les détails d’une exécution de travail, vous pouvez cliquer sur un lien vers la page Configuration du cluster pour afficher la spécification du cluster. Auparavant, vous deviez copier l’ID de tâche à partir de l’URL et accéder à la liste de clusters pour le Rechercher.