Présentation des objets de l’espace de travail
Cet article fournit une introduction générale aux objets de l’espace de travail Azure Databricks. Vous pouvez créer, afficher et organiser les objets de l’espace de travail dans le navigateur d’espace de travail à travers des personnages.
Remarque sur l’affectation de noms aux ressources d’espace de travail
Le nom complet d’une ressource d’espace de travail se compose de son nom de base et de son extension de fichier. Par exemple, l’extension de fichier d’un notebook peut être .py, .sql, .scala, .r et .ipynb en fonction de la langue et du format du notebook.
Lorsque vous créez une ressource de notebook, son nom de base et son nom complet (le nom de base concaténé avec l’extension de fichier) doit être unique dans un dossier d’espace de travail. Lorsque vous nommez une ressource, Databricks vérifie s’il répond à ces critères en y ajoutant l’extension de fichier. Si le nom complet correspond à un fichier existant dans le dossier, ce nom n’est pas autorisé et vous devez choisir un nouveau nom de bloc-notes. Par exemple, si vous essayez de créer un notebook Python (au format source Python) nommé test dans le même dossier qu’un fichier Python nommé test.py, il ne sera pas autorisé.
Clusters
Les clusters Azure Databricks Science des données et Ingénierie et les clusters Databricks Mosaic AI fournissent une plateforme unifiée pour différents cas d’usage tels que l’exécution de pipelines ETL de production, l’analyse de la diffusion en continu, l’analyse ad hoc et le Machine Learning. Un cluster est un type de ressource de calcul Azure Databricks. Les autres types de ressources de calcul incluent les entrepôts SQL Azure Databricks.
Si vous souhaitez obtenir plus d’informations sur la gestion et l’utilisation des clusters, consultez Compute.
Notebooks
Un notebook est une interface web pour les documents contenant une série de cellules exécutables (commandes) qui opèrent sur des fichiers et des tables, des visualisations et du texte narratif. Les commandes peuvent être exécutées en séquence, en faisant référence à la sortie d’une ou plusieurs commandes exécutées précédemment.
Les notebooks sont un mécanisme permettant d’exécuter du code dans Azure Databricks. L’autre mécanisme réside dans les travaux.
Pour plus d’informations sur la gestion et l’utilisation des notebooks, consultez Présentation des notebooks Databricks.
Travaux
Les travaux sont un mécanisme permettant d’exécuter du code dans Azure Databricks. L’autre mécanisme réside dans les notebooks.
Pour plus d’informations sur la gestion et l’utilisation des travaux, consultez Planifier et orchestrer des workflows.
Bibliothèques
Une bibliothèque rend le code créé par un tiers ou localement disponible pour les ordinateurs portables et les travaux en cours d’exécution sur vos clusters.
Pour plus d’informations sur la gestion et l’utilisation des bibliothèques, consultez Bibliothèques.
Données
Vous pouvez importer des données dans un système de fichiers distribué monté dans un espace de travail Azure Databricks et l’utiliser dans des notebooks et des clusters Azure Databricks. De même, vous pouvez utiliser un large éventail de sources de données Apache Spark pour accéder aux données.
Pour plus d’informations sur le chargement des données, consultez l’article Ingérer des données dans un lakehouse Databricks.
Fichiers
Important
Cette fonctionnalité est disponible en préversion publique.
Dans Databricks Runtime 11.3 LTS (et les versions ultérieures), vous pouvez créer et utiliser des fichiers arbitraires dans l’espace de travail Databricks. Les fichiers peuvent être de n’importe quel type. Voici quelques exemples courants de types de fichiers :
- Fichiers
.pyutilisés dans des modules personnalisés. - Fichiers
.md, commeREADME.md. - Fichiers
.csvou d’autres petits fichiers de données. .txtfichiers.- Fichiers journaux.
Pour plus d’informations sur l’utilisation des fichiers, consultez Interagir avec des fichiers sur Azure Databricks. Pour plus d’informations sur l’utilisation de fichiers pour modulariser votre code à mesure que vous développez avec des notebooks Databricks, consultez Partagez du code entre des notebooks Databricks
Dossiers Git
Les dossiers Git sont des dossiers Azure Databricks dont le contenu est co-versionné en le synchronisant avec un référentiel Git distant. Avec des dossiers Git Azure Databricks, vous pouvez développer des notebooks dans Azure Databricks et utiliser un référentiel Git distant pour la collaboration et la gestion de version.
Pour plus d’informations sur l’utilisation des référentiels, consultez Intégration de Git pour des dossiers Git Databricks.
Modèles
Un modèle fait référence à un modèle inscrit dans le registre de modèles MLflow. Le registre de modèles est un magasin de modèles centralisé qui vous permet de gérer le cycle de vie complet des modèles MLflow. Il fournit une traçabilité du modèle chronologique, le contrôle de version du modèle, des transitions d’étape et des annotations et descriptions de modèle et de version de modèle.
Pour plus d’informations sur la gestion et l’utilisation de modèles, consultez l’article Gérer le cycle de vie des modèles dans Unity Catalog.
Expériences
Une expérience MLflow est l’unité principale de l’organisation et du contrôle d’accès pour les exécutions d’entraînement de modèles de machine learning MLflow. Toutes les exécutions MLflow appartiennent à une expérience. Chaque expérience vous permet de visualiser, de rechercher et de comparer des exécutions, de télécharger et d’exécuter des artefacts ou des métadonnées pour l’analyse dans d’autres outils.
Pour plus d’informations sur la gestion et l’utilisation des expériences, consultez Organiser des exécutions d’entraînement avec des expériences MLflow.
Requêtes
Les requêtes sont des instructions SQL qui vous permettent d’interagir avec vos données. Pour obtenir plus d’informations, consultez Accéder et gérer des requêtes enregistrées.
Tableaux de bord
Les tableaux de bord sont des présentations de visualisations de requêtes et de commentaires. Consultez Tableaux de bord ou Tableaux de bord hérités.
Alertes
Les alertes sont des notifications indiquant qu’un champ retourné par une requête a atteint un seuil. Pour plus d’informations, consultez Que sont les alertes Databricks SQL ?.
Références à des objets de l’espace de travail
Historiquement, les utilisateurs devaient inclure le préfixe de chemin d’accès /Workspace pour certaines API Databricks (%sh), mais pas pour d’autres (%run, les entrées de l’API REST).
Les utilisateurs peuvent utiliser partout des chemins d’accès d’espace de travail avec le préfixe /Workspace. Les anciennes références aux chemins d’accès sans le préfixe /Workspace sont redirigées et continuent de fonctionner. Nous recommandons que tous les chemins d’accès d’espace de travail aient le préfixe /Workspace pour les différencier des chemins d’accès de volume et DBFS.
Le prérequis pour un comportement cohérent des préfixes de chemin d’accès /Workspace est le suivant : il ne peut pas y avoir de dossier /Workspace au niveau racine de l’espace de travail. Si vous avez un dossier /Workspace au niveau racine et souhaitez activer cette amélioration de l’expérience utilisateur, supprimez ou renommez le dossier /Workspace que vous avez créé et contactez l’équipe de votre compte Azure Databricks.
Partager un fichier, un dossier ou une URL de notebook
Dans votre espace de travail Azure Databricks, les URL des fichiers, notebooks et dossiers de l’espace de travail se trouvent dans les formats suivants :
URL de fichier d’espace de travail
https://<databricks-instance>/?o=<16-digit-workspace-ID>#files/<16-digit-object-ID>
URL de notebook
https://<databricks-instance>/?o=<16-digit-workspace-ID>#notebook/<16-digit-object-ID>/command/<16-digit-command-ID>
URL de dossier (espace de travail et Git)
https://<databricks-instance>/browse/folders/<16-digit-ID>?o=<16-digit-workspace-ID>
Ces liens peuvent être rompus si un dossier, un fichier ou un notebook dans le chemin actuel est mis à jour avec une commande d’extraction Git, ou est supprimé et recréé avec le même nom. Toutefois, vous pouvez construire un lien basé sur le chemin d’accès de l’espace de travail à partager avec d’autres utilisateurs Databricks avec des niveaux d’accès appropriés en le remplaçant par un lien au format suivant :
https://<databricks-instance>/?o=<16-digit-workspace-ID>#workspace/<full-workspace-path-to-file-or-folder>
Les liens vers les dossiers, les notebooks et les fichiers peuvent être partagés en remplaçant tout ce qui se trouve dans l’URL après ?o=<16-digit-workspace-ID> par le chemin d’accès au fichier, au dossier ou au notebook à partir de la racine de l’espace de travail. Si vous partagez une URL vers un dossier, supprimez également /browse/folders/<16-digit-ID> de l’URL d’origine.
Pour obtenir le chemin du fichier, ouvrez le menu contextuel en cliquant avec le bouton droit sur le dossier, le notebook ou le fichier dans votre espace de travail que vous souhaitez partager, puis sélectionnez Copier l’URL/le chemin d’accès>Chemin d’accès complet. Ajoutez #workspace au chemin d’accès du fichier que vous venez de copier, puis ajoutez la chaîne résultante après le ?o=<16-digit-workspace-ID> afin qu’elle corresponde au format d’URL ci-dessus.
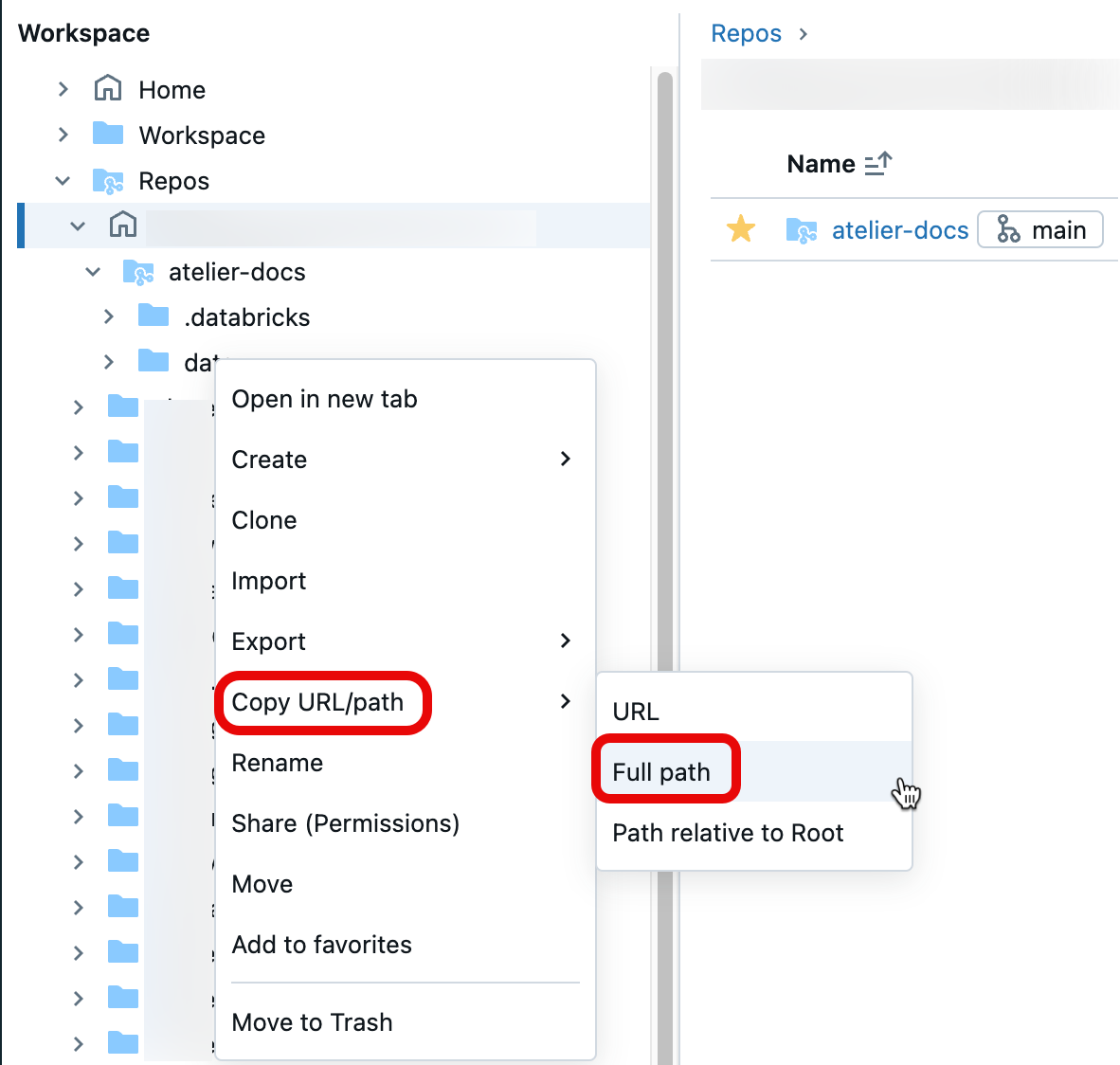
Exemple de formulation d’URL 1 : URL de dossier
Pour partager l’URL du dossier de l’espace de travail https://<databricks-instance>/browse/folders/1111111111111111?o=2222222222222222, supprimez le substring browse/folders/1111111111111111 de l’URL. Ajoutez #workspace suivi du chemin d’accès à l’objet dossier ou espace de travail que vous souhaitez partager.
Dans ce cas, le chemin d’accès de l’espace de travail est vers un dossier, /Workspace/Users/user@example.com/team-git/notebooks. Après avoir copié le chemin d’accès complet à partir de votre espace de travail, vous pouvez maintenant construire le lien partageable :
https://<databricks-instance>/?o=2222222222222222#workspace/Workspace/Users/user@example.com/team-git/notebooks
Exemple de formulation d’URL 2 : URL de notebook
Pour partager l’URL du notebook https://<databricks-instance>/?o=1111111111111111#notebook/2222222222222222/command/3333333333333333, supprimez #notebook/2222222222222222/command/3333333333333333. Ajoutez #workspace suivi du chemin d’accès à l’objet dossier ou espace de travail.
Dans ce cas, le chemin d’accès de l’espace de travail pointe vers un bloc-notes, /Workspace/Users/user@example.com/team-git/notebooks/v1.0/test-notebook. Après avoir copié le chemin d’accès complet à partir de votre espace de travail, vous pouvez maintenant construire le lien partageable :
https://<databricks-instance>/?o=1111111111111111#workspace/Workspace/Users/user@example.com/team-git/notebooks/v1.0/test-notebook
Vous disposez maintenant d’une URL stable pour un fichier, un dossier ou un chemin d’accès au notebook à partager ! Pour plus d’informations sur les URL et les identificateurs, consultez Obtenir des identificateurs pour les objets de l’espace de travail.