Tutoriel : Migrer Oracle WebLogic Server vers Azure Kubernetes Service (AKS) avec géoredondance
Ce tutoriel vous montre une méthode simple et efficace pour mettre en œuvre une stratégie de continuité d’activité et de récupération d’urgence (DR) pour Java en utilisant Oracle WebLogic Server (WLS) sur Azure Kubernetes Service (AKS). La solution illustre comment sauvegarder et restaurer une charge de travail WLS en utilisant une application Jakarta EE simple, pilotée par une base de données et fonctionnant sur AKS. La redondance géographique est un sujet complexe, avec de nombreuses solutions possibles. La meilleure solution dépend de vos exigences spécifiques. Pour d’autres façons de mettre en œuvre la redondance géographique, veuillez consulter les ressources à la fin de cet article.
Dans ce tutoriel, vous allez apprendre à :
- Utilisez les bonnes pratiques optimisées pour Azure afin d’obtenir une haute disponibilité et une récupération d’urgence (HA/DR).
- Configurez un groupe de basculement de base de données SQL Azure dans des régions appairées.
- Configurez et configurez les clusters WLS primaires sur AKS.
- Configurez la géoredondance à l’aide d’Azure Backup.
- Restaurez un cluster WLS dans une région secondaire.
- Configurez un Azure Traffic Manager
- Tester le basculement.
Le schéma suivant illustre l’architecture que vous construisez :

Azure Traffic Manager vérifie la santé de vos régions et dirige le trafic en conséquence vers le niveau d’application. La région principale dispose d’un déploiement complet du cluster WLS. Seule la région principale traite activement les demandes réseau des utilisateurs. La région secondaire restaure le cluster WLS à partir des sauvegardes de la région principale en cas de catastrophe ou d’événement de récupération d’urgence déclaré. La région secondaire est activée pour recevoir du trafic uniquement lorsque la région principale subit une interruption de service.
Azure Traffic Manager utilise la fonctionnalité de vérification d’intégrité de l’Azure Application Gateway et de l’opérateur Kubernetes WebLogic (WKO) pour mettre en œuvre ce routage conditionnel. WKO s’intègre profondément avec les sondes d’intégrité AKS, permettant à Azure Traffic Manager d’avoir un haut niveau de conscience de l’état de santé de votre charge de travail Java. Le cluster WLS principal est en cours d’exécution et le cluster secondaire est arrêté.
L’objectif de temps de récupération (RTO) du basculement géographique du niveau d’application dépend du temps de démarrage d’AKS et de l’exécution du cluster WLS secondaire, ce qui prend généralement moins d’une heure. Les données de l’application sont persistées et répliquées dans le groupe de basculement de la base de données SQL Azure, avec un RTO de quelques minutes ou heures et un objectif de point de récupération (RPO) de quelques minutes ou heures. Dans cette architecture, Azure Backup n’a qu’une seule sauvegarde Vault-standard pour la configuration de WLS chaque jour. Pour plus d’informations, veuillez consulter la section Qu’est-ce qu’Azure Kubernetes Service (AKS) Backup ?.
Le niveau de la base de données se compose d’un groupe de basculement de base de données SQL Azure avec un serveur principal et un serveur secondaire. Le serveur principal est en mode lecture-écriture actif et connecté au cluster WLS principal. Le serveur secondaire est en mode prêt passif uniquement en lecture et connecté au cluster WLS secondaire. Un géobasculement bascule toutes les bases de données secondaires du groupe dans le rôle principal. Pour le RPO et le RTO du basculement géographique de la base de données SQL Azure, veuillez consulter la section Vue d’ensemble de la continuité d’activité.
Cet article a été rédigé en utilisant le service Azure SQL Database car l’article s’appuie sur les fonctionnalités de haute disponibilité (HA) de ce service. D’autres choix de bases de données sont possibles, mais vous devez tenir compte des fonctionnalités de haute disponibilité de la base de données que vous choisissez. Pour plus d’informations, y compris sur la façon d’optimiser la configuration des sources de données pour la réplication, veuillez consulter la section Configuration des sources de données pour un déploiement Oracle Fusion Middleware Active-Passive.
Cet article utilise Azure Backup pour protéger AKS. Pour la disponibilité régionale, les scénarios pris en charge et les limitations, veuillez consulter la section Matrice de prise en charge des sauvegardes d’Azure Kubernetes Service. Actuellement, Azure Backup prend en charge les sauvegardes Vault Tier et la restauration inter-régions, qui sont disponibles en avant-première publique. Pour plus d’informations, veuillez consulter la section Activer les sauvegardes Vault Tier pour AKS et restaurer entre régions à l’aide d’Azure Backup.
Remarque
Dans cet article, vous devez fréquemment créer des identifiants uniques pour diverses ressources. Cet article utilise la convention de <initials><sequence-number> comme préfixe. Par exemple, si votre nom est Emily Juanita Bernal, un identifiant unique serait ejb01. Pour plus de clarté, vous pouvez ajouter la date d’aujourd’hui au format MMDD, par exemple ejb010307.
Prérequis
Un abonnement Azure. Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Assurez-vous d’avoir soit le rôle
Owner, soit les rôlesContributoretUser Access Administratordans l’abonnement. Vous pouvez vérifier l’affectation en suivant les étapes de la section Liste des affectations de rôles Azure en utilisant le portail Azure.Préparez une machine locale avec Windows, Linux ou macOS installé.
Pour exécuter les commandes Azure CLI, installez la version 2.54.0 ou ultérieure de Azure CLI.
Installez et configurez kubectl.
Installez et configurez Git.
Installez une implémentation de Java SE, version 17 ou ultérieure - par exemple, la build Microsoft d’OpenJDK.
Installez Maven, version 3.9.3 ou une version ultérieure.
Disposez des informations d’identification d’un compte d’authentification unique (SSO) Oracle. Pour en créer un, consultez la rubrique Créer votre compte Oracle.
Suivez la procédure suivante pour accepter les conditions de licence pour WLS :
- Accédez à Oracle Container Registry et connectez-vous.
- Si vous disposez d’un droit d’assistance, sélectionnez Intergiciel, puis recherchez et sélectionnez weblogic_cpu.
- Si vous disposez d’un droit d’utilisation support, sélectionnez Intergiciel, puis recherchez et sélectionnez weblogic_cpu.
- Acceptent le contrat de licence.
L’exécution de WLS sur AKS nécessite une compréhension des domaines WLS. Pour plus d’informations sur les domaines WLS, veuillez consulter la section Décider d’utiliser ou non l’offre préconstruite d’Azure Marketplace de la rubrique Migrer les applications WebLogic Server vers Azure Kubernetes Service. Cet article part du principe que vous exécutez WLS sur AKS en utilisant le type de source de domaine model in image, avec des journaux de transactions et des magasins dans une base de données externe, et sans stockage externe.
Configurez un groupe de basculement de base de données SQL Azure dans des régions appairées
Dans cette section, vous créez un groupe de basculement de base de données SQL Azure dans des régions appairées pour une utilisation avec vos clusters WLS et votre application. Dans une section ultérieure, vous configurez WLS pour stocker ses données de session et ses données de journal de transactions (TLOG) dans cette base de données. Cette pratique est conforme à l’architecture de disponibilité maximale (MAA) d’Oracle. Ces conseils fournissent une adaptation pour Azure de la MAA. Pour plus d’informations sur la MAA, veuillez consulter la section Architecture de disponibilité maximale d’Oracle.
Tout d’abord, créez la base de données SQL Azure principale en suivant les étapes du portail Azure dans la section Prise en main rapide : Créer une base de données unique - Azure SQL Database. Suivez les étapes jusqu’à, mais sans inclure, la section « Nettoyer les ressources ». Suivez les instructions suivantes en parcourant l’article, puis revenez à cet article après avoir créé et configuré Azure SQL Database.
Lorsque vous atteignez la section Créer une base de données unique, utilisez les étapes suivantes :
- À l’étape 4 pour la création d’un nouveau groupe de ressources, mettez de côté la valeur Nom du groupe de ressources, par exemple myResourceGroup.
- À l’étape 5 pour le nom de la base de données, mettez de côté la valeur Nom de la base de données, par exemple mySampleDatabase.
- À l’étape 6 pour la création du serveur, utilisez les étapes suivantes :
- Mettez de côté le nom unique du serveur, par exemple sqlserverprimary-ejb120623.
- Pour Emplacement, sélectionnez (États-Unis) USA Est.
- Pour la Méthode d’authentification, sélectionnez Utiliser l’authentification SQL.
- Mettez de côté la valeur Login de l’administrateur du serveur, par exemple azureuser.
- Mettez de côté la valeur Mot de passe.
- À l’étape 8, pour l’Environnement de travail, sélectionnez Développement. Regardez la description et envisagez d’autres options pour votre charge de travail.
- À l’étape 11, pour la Redondance du stockage de sauvegarde, sélectionnez Stockage de sauvegarde localement redondant. Envisagez d’autres options pour vos sauvegardes. Pour plus d’informations, veuillez consulter la section Redondance du stockage de sauvegarde de la rubrique Sauvegardes automatisées dans Azure SQL Database.
- À l’étape 14, dans la configuration des Règles du pare-feu, pour Permettre aux services et ressources Azure d’accéder à ce serveur, sélectionnez Oui.
Lorsque vous atteignez la section Interroger la base de données, utilisez les étapes suivantes :
À l’étape 3, entrez vos informations de connexion d’administrateur du serveur Authentification SQL pour vous connecter.
Remarque
Si la connexion échoue avec un message d’erreur similaire à Client avec l’adresse IP « xx.xx.xx.xx » n’est pas autorisé à accéder au serveur, sélectionnez Autoriser l’IP xx.xx.xx.xx sur le serveur <votre-nom-de-serveur-sql> à la fin du message d’erreur. Attendez que les règles du pare-feu du serveur soient mises à jour, puis sélectionnez de nouveau OK.
Après avoir exécuté la requête d’exemple à l’étape 5, effacez l’éditeur et créez des tables.
Pour créer le schéma, entrez les requêtes suivantes :
Pour créer le schéma pour le TLOG, entrez la requête suivante :
create table TLOG_msp1_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID)); create table TLOG_msp2_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID)); create table TLOG_msp3_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID)); create table TLOG_msp4_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID)); create table TLOG_msp5_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID)); create table wl_servlet_sessions (wl_id VARCHAR(100) NOT NULL, wl_context_path VARCHAR(100) NOT NULL, wl_is_new CHAR(1), wl_create_time DECIMAL(20), wl_is_valid CHAR(1), wl_session_values VARBINARY(MAX), wl_access_time DECIMAL(20), wl_max_inactive_interval INTEGER, PRIMARY KEY (wl_id, wl_context_path));Après une exécution réussie, vous devriez voir le message
Query succeeded: Affected rows: 0.Ces tables de base de données sont utilisées pour stocker les journaux de transactions (TLOG) et les données de session pour vos clusters WLS et votre application. Pour plus d’informations, veuillez consulter la section Utilisation d’un magasin JDBC TLOG et la rubrique Utilisation d’une base de données pour le stockage persistant (Persistance JDBC).
Pour créer le schéma pour l’application d’exemple, entrez la requête suivante :
CREATE TABLE COFFEE (ID NUMERIC(19) NOT NULL, NAME VARCHAR(255) NULL, PRICE FLOAT(32) NULL, PRIMARY KEY (ID)); CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT NUMERIC(28) NULL, PRIMARY KEY (SEQ_NAME));Après une exécution réussie, vous devriez voir le message
Query succeeded: Affected rows: 0.
Vous avez maintenant terminé l’article « Prise en main rapide : Créer une base de données unique - Azure SQL Database ».
Ensuite, créez un groupe de basculement de base de données SQL Azure en suivant les étapes du portail Azure dans la section Configurer un groupe de basculement pour Azure SQL Database. Vous n’avez besoin que des sections suivantes : Créer un groupe de basculement et Tester le basculement planifié. Utilisez les étapes suivantes pendant que vous suivez l’article, puis revenez à cet article après avoir créé et configuré le groupe de basculement de la base de données SQL Azure :
Lorsque vous atteignez la section Créer un groupe de basculement, procédez comme suit :
- À l’étape 5 pour la création du groupe de basculement, sélectionnez l’option pour créer un nouveau serveur secondaire, puis procédez comme suit :
- Entrez et sauvegardez le nom du groupe de basculement, par exemple failovergroupname-ejb120623.
- Entrez et sauvegardez le nom unique du serveur, par exemple sqlserversecondary-ejb120623.
- Entrez le même administrateur de serveur et mot de passe que pour votre serveur principal.
- Pour Emplacement, sélectionnez une région différente de celle que vous avez utilisée pour la base de données principale.
- Assurez-vous que Autoriser les services Azure à accéder au serveur est sélectionné.
- À l’étape 5 pour la configuration des Bases de données au sein du groupe, sélectionnez la base de données que vous avez créée sur le serveur principal, par exemple mySampleDatabase.
- À l’étape 5 pour la création du groupe de basculement, sélectionnez l’option pour créer un nouveau serveur secondaire, puis procédez comme suit :
Après avoir complété toutes les étapes de la section Tester le basculement planifié, laissez la page du groupe de basculement ouverte et utilisez-la pour le test de basculement des clusters WLS plus tard.
Obtenez la chaîne de connexion JDBC et le nom d’utilisateur administrateur de la base de données pour le groupe de basculement
Les étapes suivantes vous guident pour obtenir la chaîne de connexion JDBC et le nom d’utilisateur de la base de données pour la base de données au sein du groupe de basculement. Ces valeurs sont différentes des valeurs correspondantes pour la base de données principale.
Dans le portail Azure, trouvez le groupe de ressources dans lequel vous avez déployé la base de données principale.
Dans la liste des ressources, sélectionnez la base de données principale de type SQL database.
Sous Paramètres, sélectionnez Chaînes de connexion.
Sélectionnez JDBC.
Dans la zone de texte sous JDBC (SQL authentication), sélectionnez l’icône de copie pour mettre la valeur de la chaîne de connexion JDBC dans le presse-papiers.
Dans un éditeur de texte, collez la valeur. Vous l’éditerez à une autre étape.
Retournez au groupe de ressources.
Sélectionnez la ressource de type SQL Server qui contient la base de données que vous venez de consulter dans les étapes précédentes.
Sous Gestion des données, sélectionnez Groupes de basculement.
Dans le tableau au milieu de la page, sélectionnez le groupe de basculement.
Dans la zone de texte sous point de terminaison de l’écouteur en lecture/écriture, sélectionnez l’icône de copie pour mettre la valeur de la chaîne de connexion JDBC dans le presse-papiers.
Collez la valeur sur une nouvelle ligne dans votre éditeur de texte. Votre éditeur de texte devrait maintenant avoir des lignes similaires à l’exemple suivant :
jdbc:sqlserver://ejb010307db.database.windows.net:1433;database=ejb010307db;user=azureuser@ejb010307db;password={your_password_here};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30; ejb010307failover.database.windows.netCréez une nouvelle ligne en utilisant les modifications suivantes :
Copiez toute la première ligne.
Changez la partie du nom d’hôte de l’URL pour utiliser le nom d’hôte de la ligne de point de terminaison de l’écouteur en lecture-écriture.
Supprimez tout après la paire
name=valuepourdatabase. En d’autres termes, supprimez tout ce qui suit et y compris le;immédiatement aprèsdatabase=ejb010307db.Une fois que vous avez terminé, la chaîne devrait ressembler à l’exemple suivant :
jdbc:sqlserver://ejb010307failover.database.windows.net:1433;database=ejb010307dbCette valeur est la chaîne de connexion JDBC.
Dans le même éditeur de texte, dérivez le nom d’utilisateur de la base de données en obtenant la valeur du paramètre
userde la chaîne de connexion JDBC d’origine et en remplaçant le nom de la base de données par la première partie de la ligne point de terminaison de l’écouteur en lecture/écriture. En continuant avec l’exemple précédent, la valeur seraitazureuser@ejb010307failover. Cette valeur est le nom d’utilisateur administrateur de la base de données.
Configurez et mettez en place les clusters WLS primaires sur AKS
Dans cette section, vous créez un cluster WLS sur AKS en utilisant l’offre Oracle WebLogic Server sur AKS. Le cluster dans USA Est est le principal et est configuré comme cluster actif.
Remarque
Vous pouvez trouver plus d’informations sur l’offre Oracle WebLogic Server sur AKS dans les articles suivants :
Préparez une application d’exemple
Dans cette section, vous construisez et packagez une application CRUD Java/JakartaEE d’exemple que vous déploierez et exécuterez plus tard sur les clusters WLS pour le test de basculement.
L’application utilise la persistance de session JDBC de WebLogic Server pour stocker les données de session HTTP. La source de données jdbc/WebLogicCafeDB stocke les données de session pour permettre le basculement et l’équilibrage de charge entre les clusters de serveurs WebLogic. Elle configure un schéma de persistance pour persister les données de l’application coffee dans la même source de données jdbc/WebLogicCafeDB.
Utilisez les étapes suivantes pour construire et package l’exemple :
Utilisez les commandes suivantes pour cloner le référentiel d’exemples et vérifier la balise correspondante à cet article :
git clone https://github.com/Azure-Samples/azure-cafe.git cd azure-cafe git checkout 20231206Si vous voyez un message concernant
Detached HEAD, il est sans danger de l’ignorer.Utilisez les commandes suivantes pour naviguer jusqu’au répertoire d’exemples, puis compilez et packagez l’exemple :
cd weblogic-cafe mvn clean package
Lorsque le package est généré avec succès, vous pouvez le trouver à l’emplacement <parent-path-to-your-local-clone>/azure-cafe/weblogic-cafe/target/weblogic-cafe.war. Si vous ne voyez pas le package, veuillez résoudre le problème avant de continuer.
Créer un compte de stockage et un conteneur de stockage pour contenir l’exemple d’application
Utilisez les étapes suivantes pour créer un compte et un conteneur de stockage. Certaines de ces étapes vous renvoient à d’autres guides. Une fois les étapes terminées, vous pouvez télécharger un exemple d’application à déployer sur WLS.
Connectez-vous au portail Azure.
Créez un compte de stockage en suivant les étapes décrites dans la section Créer un compte de stockage. Utilisez les spécialisations suivantes pour les valeurs dans l’article :
- Créez un nouveau groupe de ressources pour le compte de stockage.
- Pour Région, sélectionnez USA Est.
- Pour Nom du compte de stockage, utilisez la même valeur que le nom du groupe de ressources.
- Pour Performances, sélectionnez Standard.
- Pour assurer la Redondance, sélectionnez Stockage localement redondant (LRS).
- Les autres onglets n’ont pas besoin de spécialisations.
Passez à la validation et à la création du compte, puis revenez à cet article.
Créez un conteneur de stockage dans le compte en suivant les étapes de la section Créer un conteneur de la rubrique Prise en main rapide : rapide : Charger, télécharger et répertorier des objets blob avec le Portail Azure.
En utilisant le même article, téléchargez le package azure-cafe/weblogic-cafe/target/weblogic-cafe.war que vous avez précédemment construit en suivant les étapes de la section Charger un objet blob de blocs. Ensuite, revenez à cet article.
Déployer WLS sur AKS
Utilisez les étapes suivantes pour déployer WLS sur AKS :
Ouvrez l’offre Oracle WebLogic Server sur AKS dans votre navigateur et sélectionnez Créer. Vous devriez voir le volet Informations de base de l’offre.

Utilisez les étapes suivantes pour remplir le volet Informations de base :
Assurez-vous que la valeur affichée pour Abonnement est la même que celle qui contient les rôles listés dans la section des prérequis.
Dans le champ Groupe de ressources, sélectionnez Créer nouveau et remplissez une valeur unique pour le groupe de ressources, par exemple wlsaks-eastus-20240109.
Sous Détails de l’instance, pour Région, sélectionnez USA Est.
Sous Credentials WebLogic, fournissez respectivement un mot de passe pour WebLogic Administrator et WebLogic Model encryption. Sauvegardez le nom d’utilisateur et le mot de passe pour WebLogic Administrator.
Sous Configuration de base facultative, pour Accepter les valeurs par défaut pour la configuration facultative ?, sélectionnez Non. La configuration optionnelle s’affiche.
Pour Nommer le préfixe pour le Nom du serveur managé, renseignez msp. Vous configurez la table TLOG de WLS avec le préfixe
TLOG_${serverName}_plus tard. Cet article crée une table TLOG avec le nomTLOG_msp${index}_WLStore. Si vous souhaitez un préfixe de nom de serveur géré différent, assurez-vous que la valeur correspond aux conventions de nommage des tables de Microsoft SQL Server et aux vrais noms de tables.Laissez les valeurs par défaut pour les autres champs.
Sélectionnez Suivant pour passer au volet AKS.
Sous Sélection d’image, fournissez les informations suivantes :
- Pour Authentification par nom d’utilisateur pour l’authentification unique Oracle, renseignez votre nom d’utilisateur Oracle SSO à partir des prérequis.
- Pour Mot de passe pour le nom d’utilisateur pour l’authentification unique Oracle, renseignez vos identifiants Oracle SSO à partir des prérequis.
Sous Application, utilisez les étapes suivantes :
- Dans la section Application , en regard de Déployer une application ?, sélectionnez Oui.
- À côté de Package d’application (.war, .ear, .jar), sélectionnez Parcourir.
- Commencez à saisir le nom du compte de stockage de la section précédente. Lorsque le compte de stockage souhaité s’affiche, sélectionnez-le.
- Sélectionnez le conteneur de stockage de la section précédente.
- Cochez la case à côté de weblogic-cafe.war, que vous avez téléchargé dans la section précédente. Sélectionnez Sélectionner.
- Laissez les valeurs par défaut pour les autres champs.
Cliquez sur Suivant.
Laissez les valeurs par défaut dans le volet Configuration TLS/SSL, puis sélectionnez Suivant pour passer au volet Équilibrage de charge.
Dans le volet Équilibrage de charge, à côté de Créer une entre pour la console d’administration Console. Vérifiez qu’aucune application avec le chemin /console*, elle provoque un conflit avec le chemin de la console d’administration, sélectionnez Oui.
Laissez les valeurs par défaut pour les autres champs et sélectionnez Suivant.
Laissez les valeurs par défaut dans le volet DNS et sélectionnez Suivant pour passer au volet Base de données.
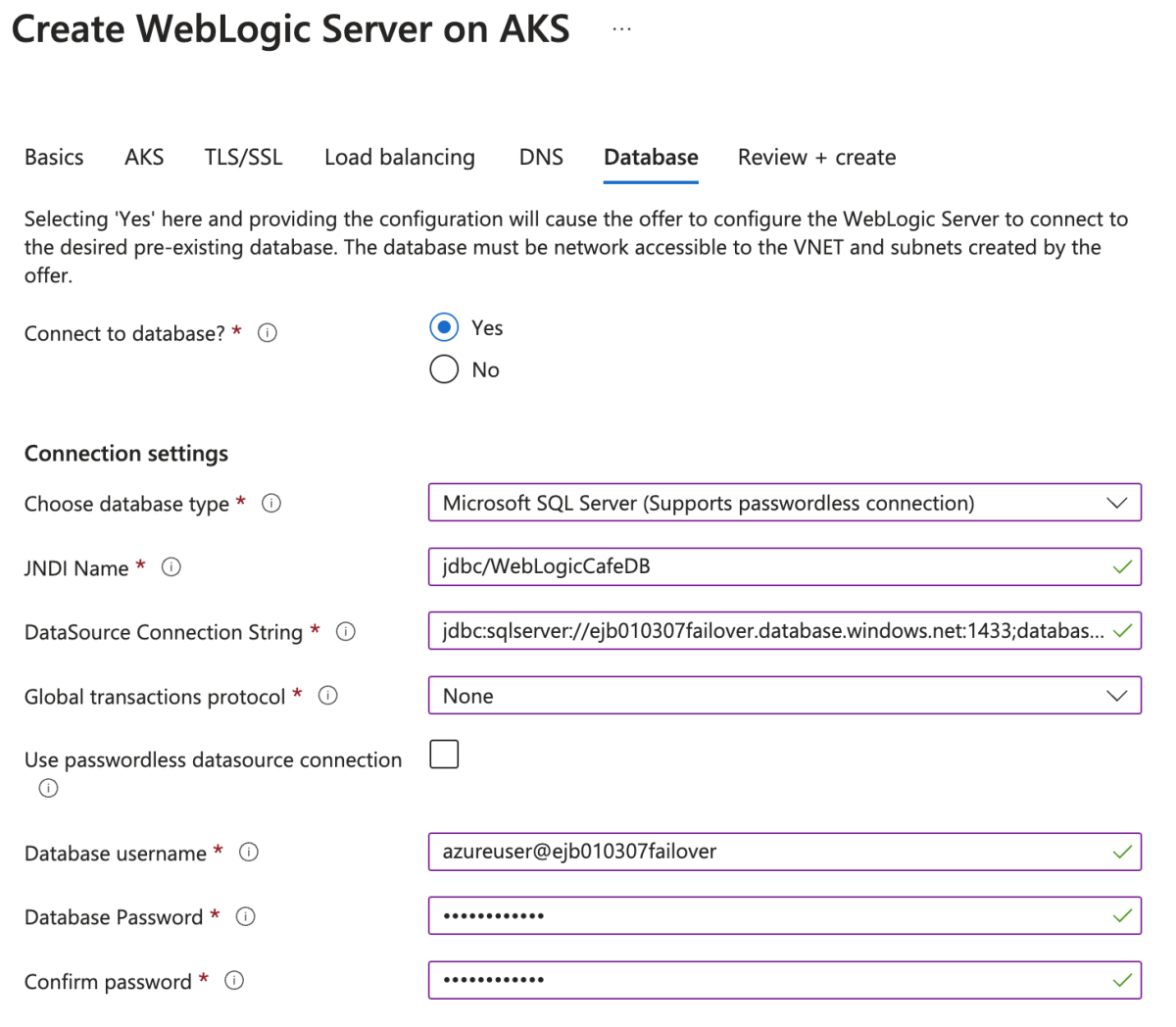
Entrez les valeurs suivantes dans le volet Base de données:
- Pour Se connecter à la base de données, sélectionnez Oui.
- Pour choisir le type de base de données, sélectionnez Microsoft SQL Server (prend en charge la connexion sans mot de passe).
- Pour JNDI Name, entrez jdbc/WebLogicCafeDB.
- Pour la chaîne de connexion DataSource, collez la valeur que vous avez sauvegardée pour chaîne de connexion JDBC dans la section Obtenir le nom d’utilisateur de l’administrateur de base de données et du chaîne de connexion JDBC pour la section groupe de basculement.
- Pour Protocole de transaction global, sélectionnez Aucun.
- Pour Nom d’utilisateur de la base de données, collez la valeur que vous avez sauvegardée pour Nom d’utilisateur administrateur de la base de données dans la section Obtenez la chaîne de connexion JDBC et le nom d’utilisateur administrateur de la base de données pour le groupe de basculement.
- Entrez le mot de passe de connexion de l’administrateur du serveur de base de données que vous avez enregistré précédemment pour Mot de passe de la base de données. Entrez la même valeur pour Confirmer le mot de passe.
- Laissez les valeurs par défaut pour les autres champs.
Sélectionnez Revoir + créer.
Attendez que Exécution de la validation finale... soit terminée avec succès, puis sélectionnez Créer. Après un moment, vous devriez voir la page Déploiement où Le déploiement est en cours est affiché.






Remarque
Si vous rencontrez des problèmes lors de l’exécution de la validation finale..., corrigez-les et essayez à nouveau.
En fonction des conditions réseau et de l’activité dans votre région sélectionnée, le déploiement peut prendre jusqu’à 70 minutes pour se terminer. Après cela, le texte Votre déploiement a été effectué doit s’afficher dans la page de déploiement.
Configurer le stockage des données TLOG
Dans cette section, vous configurez le stockage des données TLOG en remplaçant le modèle d’image WLS par un ConfigMap. Pour plus d’informations sur le ConfigMap, veuillez consulter la section ConfigMap du modèle WebLogic Deploy Tooling.
Cette section nécessite un terminal Bash avec l’interface CLI Azure et kubectl installés. Utilisez les étapes suivantes pour dériver le YAML nécessaire et configurer le stockage des données TLOG :
Utilisez les étapes suivantes pour vous connecter à votre cluster AKS :
- Ouvrez le portail Azure et accédez au groupe de ressources que vous avez approvisionné dans la section Déployer WLS sur AKS.
- Sélectionnez le cluster AKS dans la liste des ressources, puis sélectionnez Se connecter pour vous connecter au cluster AKS.
- Sélectionnez Azure CLI et suivez les étapes pour vous connecter au cluster AKS dans votre terminal local.
Utilisez les étapes suivantes pour obtenir l’entrée
topology:à partir du YAML du modèle d’image WLS :- Ouvrez le portail Azure et accédez au groupe de ressources que vous avez approvisionné dans la section Déployer WLS sur AKS.
- Sélectionnez Paramètres>Déploiements. Sélectionnez le premier déploiement dont le nom commence par oracle.20210620-wls-on-aks.
- Sélectionnez Sorties. Copiez la valeur shellCmdtoOutputWlsImageModelYaml dans le presse-papiers. La valeur est une commande shell qui décode la chaîne base64 du fichier modèle et enregistre le contenu dans un fichier nommé model.yaml.
- Collez la valeur dans votre terminal Bash et exécutez la commande pour produire le fichier model.yaml.
- Éditez le fichier pour supprimer tout le contenu sauf l’entrée de niveau supérieur
topology:. Il ne devrait y avoir aucune entrée de niveau supérieur dans votre fichier, sauftopology:. - Enregistrez le fichier.
Utilisez la procédure suivante pour obtenir le nom et le nom de l’espace de noms
ConfigMapà partir du YAML du modèle de domaine WLS :Ouvrez le portail Azure et accédez au groupe de ressources qui a été approvisionné dans la section Déployer WLS sur AKS.
Sélectionnez Paramètres>Déploiements. Sélectionnez le premier déploiement dont le nom commence par oracle.20210620-wls-on-aks.
Sélectionnez Sorties. Copiez la valeur de shellCmdtoOutputWlsDomainYaml dans le presse-papiers. La valeur est une commande shell pour décoder la chaîne base64 du fichier modèle et enregistrer le contenu dans model.yaml.
Collez la valeur dans votre terminal et vous obtiendrez un fichier nommé domain.yaml.
Recherchez les valeurs suivantes dans le fichier domain.yaml.
spec.configuration.model.configMap. Si vous avez accepté les paramètres par défaut, cette valeur estsample-domain1-wdt-config-map.metadata.namespace. Si vous avez accepté les paramètres par défaut, cette valeur estsample-domain1-ns.
Par commodité, vous pouvez utiliser la commande suivante pour enregistrer ces valeurs en tant que variables shell :
export CONFIG_MAP_NAME=sample-domain1-wdt-config-map export WLS_NS=sample-domain1-ns
Utilisez la commande suivante pour obtenir le YAML
ConfigMap:kubectl get configmap ${CONFIG_MAP_NAME} -n ${WLS_NS} -o yaml > configMap.yamlUtilisez les étapes suivantes pour créer le fichier tlog-db-model.yaml :
Dans un éditeur de texte, créez un fichier vide appelé tlog-db-model.yaml.
Insérez le contenu de votre model.yaml, ajoutez une ligne vide, puis insérez le contenu de votre fichier configMap.yaml.
Dans votre fichier tlog-db-model.yaml, localisez la ligne se terminant par
ListenPort: 8001. Ajoutez ce texte à la ligne suivante, en prenant soin queTransactionLogJDBCStoresoit exactement sousListenPortet que les lignes restantes dans l’extrait suivant soient indentées de deux, comme montré dans l’exemple suivant :TransactionLogJDBCStore: Enabled: true DataSource: jdbc/WebLogicCafeDB PrefixName: TLOG_${serverName}_Le fichier tlog-db-model.yaml complété devrait ressembler de près à l’exemple suivant :
topology: Name: "@@ENV:CUSTOM_DOMAIN_NAME@@" ProductionModeEnabled: true AdminServerName: "admin-server" Cluster: "cluster-1": DynamicServers: ServerTemplate: "cluster-1-template" ServerNamePrefix: "@@ENV:MANAGED_SERVER_PREFIX@@" DynamicClusterSize: "@@PROP:CLUSTER_SIZE@@" MaxDynamicClusterSize: "@@PROP:CLUSTER_SIZE@@" MinDynamicClusterSize: "0" CalculatedListenPorts: false Server: "admin-server": ListenPort: 7001 ServerTemplate: "cluster-1-template": Cluster: "cluster-1" ListenPort: 8001 TransactionLogJDBCStore: Enabled: true DataSource: jdbc/WebLogicCafeDB PrefixName: TLOG_${serverName}_ SecurityConfiguration: NodeManagerUsername: "@@SECRET:__weblogic-credentials__:username@@" NodeManagerPasswordEncrypted: "@@SECRET:__weblogic-credentials__:password@@" resources: JDBCSystemResource: jdbc/WebLogicCafeDB: Target: 'cluster-1' JdbcResource: JDBCDataSourceParams: JNDIName: [ jdbc/WebLogicCafeDB ] GlobalTransactionsProtocol: None JDBCDriverParams: DriverName: com.microsoft.sqlserver.jdbc.SQLServerDriver URL: '@@SECRET:ds-secret-sqlserver-1709938597:url@@' PasswordEncrypted: '@@SECRET:ds-secret-sqlserver-1709938597:password@@' Properties: user: Value: '@@SECRET:ds-secret-sqlserver-1709938597:user@@' JDBCConnectionPoolParams: TestTableName: SQL SELECT 1 TestConnectionsOnReserve: trueRemplacez le modèle WLS par le
ConfigMap. Pour remplacer le modèle WLS, remplacez l’existantConfigMappar le nouveau modèle. Pour plus d’informations, consultez la section Mise à jour d’un modèle existant dans la documentation Oracle. Exécutez les commandes suivantes pour recréer leConfigMap:export CM_NAME_FOR_MODEL=sample-domain1-wdt-config-map kubectl -n sample-domain1-ns delete configmap ${CM_NAME_FOR_MODEL} # replace path of tlog-db-model.yaml kubectl -n sample-domain1-ns create configmap ${CM_NAME_FOR_MODEL} \ --from-file=tlog-db-model.yaml kubectl -n sample-domain1-ns label configmap ${CM_NAME_FOR_MODEL} \ weblogic.domainUID=sample-domain1Redémarrez le cluster WLS en utilisant les commandes suivantes. Vous devez provoquer une mise à jour progressive pour que le nouveau modèle fonctionne.
export RESTART_VERSION=$(kubectl -n sample-domain1-ns get domain sample-domain1 '-o=jsonpath={.spec.restartVersion}') # increase restart version export RESTART_VERSION=$((RESTART_VERSION + 1)) kubectl -n sample-domain1-ns patch domain sample-domain1 \ --type=json \ '-p=[{"op": "replace", "path": "/spec/restartVersion", "value": "'${RESTART_VERSION}'" }]'
Assurez-vous que les pods WLS sont en cours d’exécution avant de continuer. Vous pouvez utiliser la commande suivante pour surveiller le statut des pods :
kubectl get pod -n sample-domain1-ns -w
Remarque
Dans cet article, les modèles WLS sont inclus dans l’image du conteneur de l’application, qui a été créée par l’offre WLS sur AKS. TLOG est configuré en remplaçant le modèle existant par le ConfigMap WDT qui contient le fichier modèle et utilise le champ CRD du domaine configuration.model.configMap pour référencer la carte. Dans les scénarios de production, les images auxiliaires sont l’approche recommandée pour inclure les fichiers du modèle dans l’image, les fichiers d’archive d’application et l’installation de WebLogic Deploy Tooling, dans vos pods. Cette fonctionnalité élimine le besoin de fournir ces fichiers dans l’image spécifiée dans domain.spec.image.
Configurez la géoredondance à l’aide d’Azure Backup.
Dans cette section, vous utilisez Azure Backup pour sauvegarder des clusters AKS en utilisant l’extension de sauvegarde, qui doit être installée dans le cluster.
Utilisez les étapes suivantes pour configurer la géo-redondance :
Créez un nouveau conteneur de stockage pour l’extension de sauvegarde AKS dans le compte de stockage que vous avez créé dans la section Créer un compte de stockage et un conteneur de stockage pour contenir l’application d’exemple.
Utilisez les commandes suivantes pour installer l’extension de sauvegarde AKS et activer les pilotes CSI et les instantanés pour votre cluster :
#replace with your resource group name. export RG_NAME=wlsaks-eastus-20240109 export AKS_NAME=$(az aks list \ --resource-group ${RG_NAME} \ --query "[0].name" \ --output tsv) az aks update \ --resource-group ${RG_NAME} \ --name ${AKS_NAME} \ --enable-disk-driver \ --enable-file-driver \ --enable-blob-driver \ --enable-snapshot-controller --yesL’activation des pilotes prend environ 5 minutes. Assurez-vous que les commandes se terminent sans erreur avant de continuer.
Ouvrez le groupe de ressources où AKS est déployé. Sélectionnez le cluster AKS dans la liste des ressources.
Sur la page d’accueil AKS, sélectionnez Paramètres>Sauvegarder>Installer l’extension.
Sur la page Installer l’extension AKS Backup, sélectionnez Suivant. Sélectionnez le compte de stockage et le conteneur Blob créés dans les étapes précédentes. Sélectionnez Suivant, puis Créer. Compléter cette étape prend environ cinq minutes.
Ouvrez le portail Azure, dans la barre de recherche en haut, recherchez Coffres de sauvegarde. Vous devriez le voir répertorié sous Services. Sélectionnez-le.
Pour activer la sauvegarde AKS, suivez les étapes de la section Sauvegarder Azure Kubernetes Service à l’aide d’Azure Backup jusqu’à, mais sans inclure, la section « Utiliser des hooks pendant la sauvegarde AKS ». Apportez les ajustements indiqués dans les étapes suivantes.
Lorsque vous atteignez la section « Créer un coffre de sauvegarde », faites les ajustements suivants :
Pour l’étape 1, sous Régions, sélectionnez USA Est. Sous Redondance du stockage de sauvegarde, utilisez Globally-Redundant.

Pour l’étape 2, activez Restauration interrégionale.
Lorsque vous atteignez la section « Créer une politique de sauvegarde », apportez les ajustements suivants lorsqu’il vous est demandé de créer une politique de rétention :
Ajoutez une règle de rétention où Vault-standard est sélectionné.
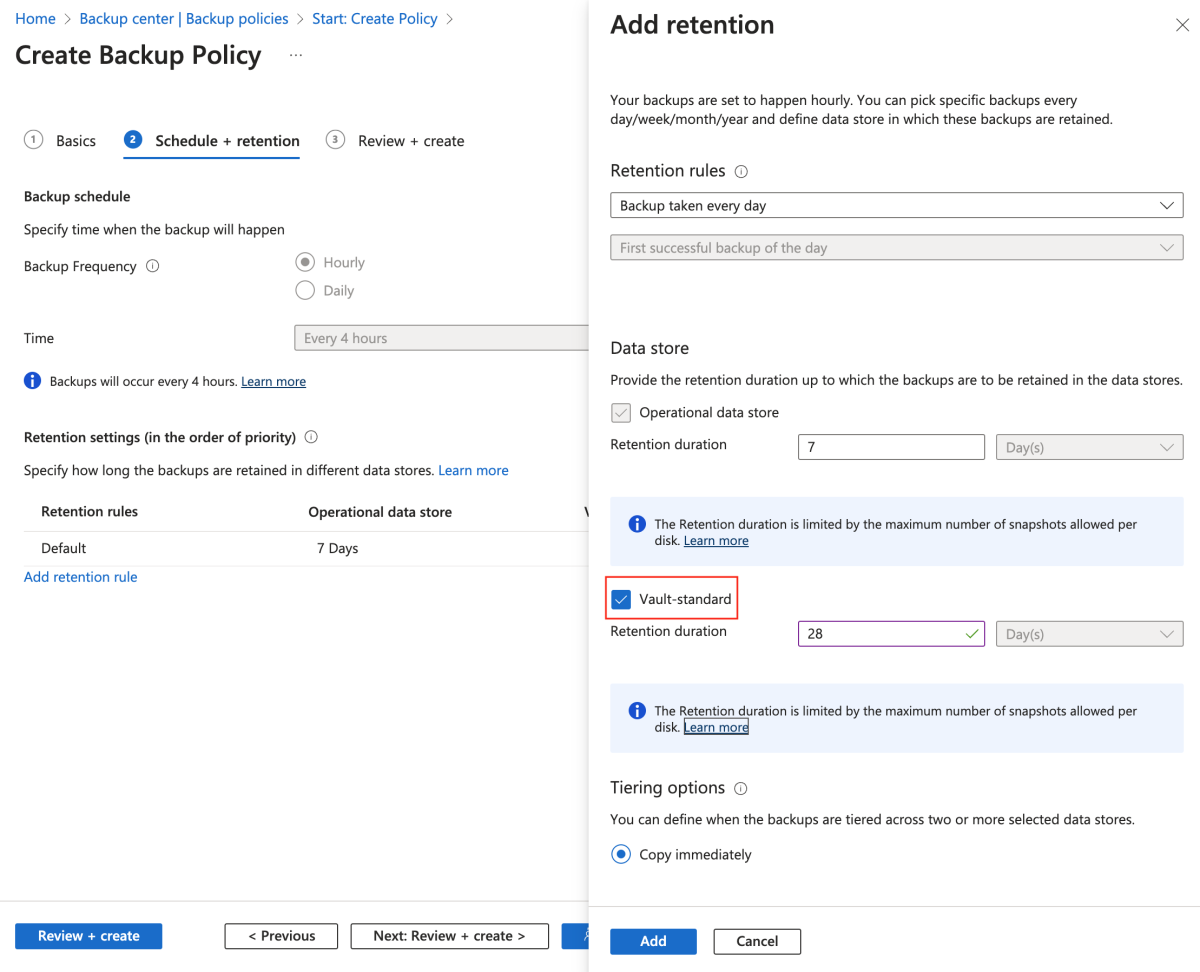
Sélectionnez Ajouter.
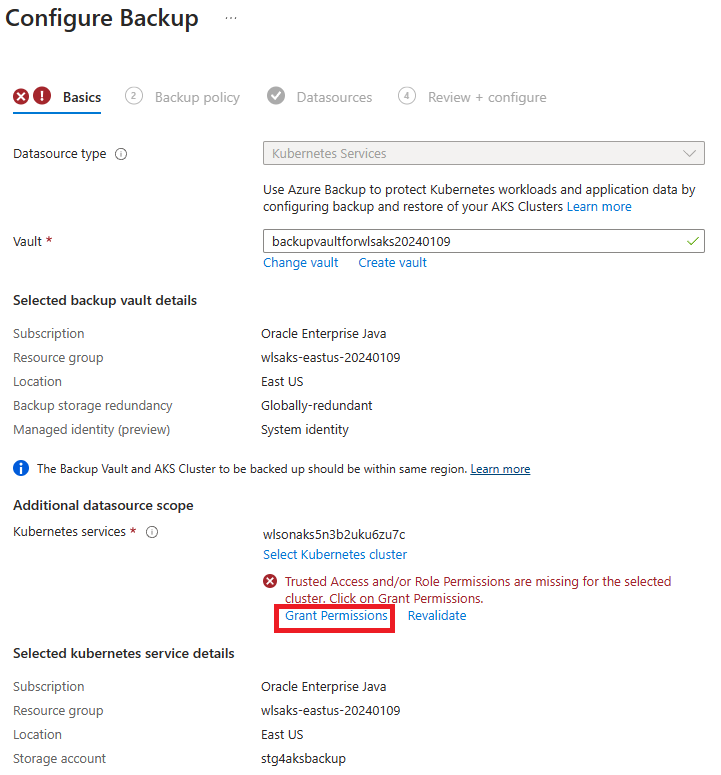
Lorsque vous atteignez la section « Configurer les sauvegardes », apportez les ajustements suivants. Les étapes 1 à 5 concernent l’installation de l’extension AKS. Ignorez les étapes 1 à 5 et commencez à l’étape 6.
Pour l’étape 7, vous rencontrez des erreurs de permission. Sélectionnez Accorder la permission pour continuer. Après la fin du déploiement des permissions, si l’erreur persiste, sélectionnez Revalider pour actualiser les affectations de rôle.
Pour l’étape 10, trouvez Sélectionner les ressources à sauvegarder, et apportez les ajustements suivants :
- Pour Nom de l’instance de sauvegarde, remplissez un nom unique.
- Pour Espaces de noms, sélectionnez les espaces de noms pour WebLogic Operator et WebLogic Server. Dans cet article, sélectionnez weblogic-operator-ns et sample-domain1-ns.
- Pour Autres options, sélectionnez toutes les options. Assurez-vous que Inclure les secrets est sélectionné.
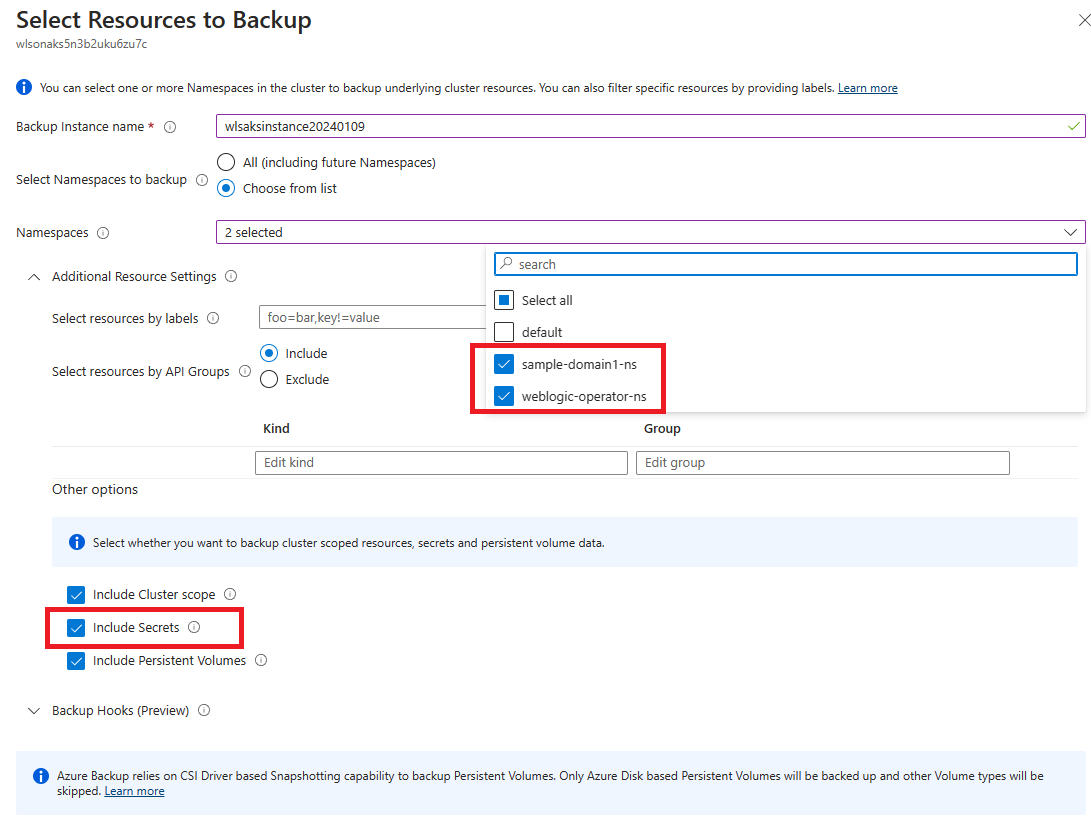
Pour l’étape 11, vous rencontrez une erreur d’affectation de rôle. Sélectionnez votre source de données dans la liste et sélectionnez Attribuer les rôles manquants pour corriger l’erreur.
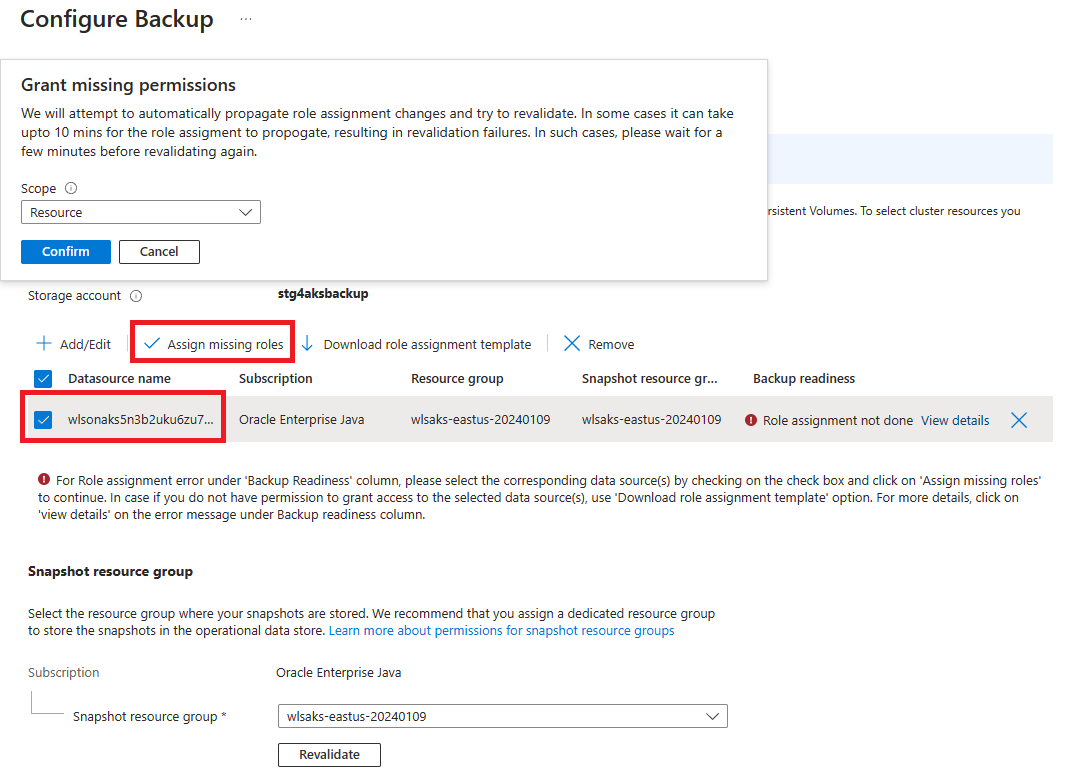





Préparez-vous à restaurer le cluster WLS dans une région secondaire
Dans cette section, vous vous préparez à restaurer le cluster WLS dans la région secondaire. Ici, la région secondaire est USA Ouest 2. Avant la restauration, vous devez avoir un cluster AKS avec l'extension de sauvegarde AKS installée dans la région Ouest US 2.
Configurer Azure Container Registry pour la géoréplication
Utilisez les étapes suivantes pour configurer Azure Container Registry (ACR) pour la géoréplication, qui contient l’image WLS que vous avez créée dans la section Déployer WLS sur AKS. Pour activer la réplication ACR, vous devez la mettre à niveau vers le plan tarifaire Premium. Pour plus d’informations, consultez Géoréplication dans Azure Container Registry.
- Ouvrez le groupe de ressources que vous avez approvisionné dans la section Déployer WLS sur AKS. Dans la liste des ressources, sélectionnez l’ACR dont le nom commence par wlsaksacr.
- Sur la page d’accueil ACR, sélectionnez Paramètres>Propriétés. Pour Plan tarifaire, sélectionnez Premium, puis sélectionnez Enregistrer.
- Dans le volet de navigation, sélectionnez Services>Géoréplications. Sélectionnez Ajouter pour ajouter une région de réplication sur la page.
- Dans la page Créer une réplication, pour Emplacement, sélectionnez USA Ouest 2, puis sélectionnez Créer.
Une fois le déploiement terminé, l’ACR est activé pour la géoréplication.
Créer un compte de stockage dans une région secondaire
Pour activer l’extension AKS Backup, vous devez fournir un compte de stockage avec un conteneur vide dans la même région.
Pour restaurer la sauvegarde interrégionale, vous devez fournir un emplacement de mise en scène où les données de sauvegarde sont hydratées. Cet emplacement de mise en scène comprend un groupe de ressources et un compte de stockage dans la même région et le même abonnement que le cluster cible pour la restauration.
Utilisez les étapes suivantes pour créer un compte et un conteneur de stockage. Certaines de ces étapes vous renvoient à d’autres guides.
- Connectez-vous au portail Azure.
- Créez un compte de stockage en suivant les étapes décrites dans la section Créer un compte de stockage. Il n’est pas nécessaire de suivre toutes les étapes de l’article. Remplissez les champs indiqués sur le volet Informations de base. Pour Région, sélectionnez USA Ouest 2, puis sélectionnez Vérifier + créer pour accepter les options par défaut. Passez à la validation et à la création du compte, puis revenez à cet article.
- Créez un conteneur de stockage pour l’extension AKS Backup en suivant les étapes de la section Créer un conteneur de Démarrage rapide : Uploader, télécharger et lister des blobs avec le portail Azure.
- Créez un conteneur de stockage comme emplacement de mise en scène à utiliser pendant la restauration.
Préparer un cluster AKS dans une région secondaire
Les sections suivantes montrent comment créer un cluster AKS dans une région secondaire.
Créer un cluster AKS
Cet article expose une application WLS à l’aide d’Application Gateway Ingress Controller. Dans cette section, vous créez un nouveau cluster AKS dans la région Ouest US 2. Ensuite, vous activez l’add-on du contrôleur d’entrée avec une nouvelle instance de passerelle d’application. Pour plus d’informations, consultez la section Activer l’add-on du contrôleur d’entrée pour un nouveau cluster AKS avec une nouvelle instance de passerelle d’application.
Utilisez les étapes suivantes pour créer le cluster AKS :
Utilisez les commandes suivantes pour créer un groupe de ressources dans la région secondaire :
export RG_NAME_WESTUS=wlsaks-westus-20240109 az group create --name ${RG_NAME_WESTUS} --location westusUtilisez les commandes suivantes pour déployer un cluster AKS avec l’add-on activé :
export AKS_NAME_WESTUS=${RG_NAME_WESTUS}aks export GATEWAY_NAME_WESTUS=${RG_NAME_WESTUS}gw az aks create \ --resource-group ${RG_NAME_WESTUS} \ --name ${AKS_NAME_WESTUS} \ --network-plugin azure \ --enable-managed-identity \ --enable-addons ingress-appgw \ --appgw-name ${GATEWAY_NAME_WESTUS} \ --appgw-subnet-cidr "10.225.0.0/16" \ --generate-ssh-keysCette commande crée automatiquement une instance de
Standard_v2 SKUpasserelle d’application avec le nom${RG_NAME_WESTUS}gwdans le groupe de ressources de nœuds AKS. Le groupe de ressources de nœuds est nomméMC_resource-group-name_cluster-name_locationpar défaut.Remarque
Le cluster AKS que vous avez approvisionné dans la section Déployer WLS sur AKS fonctionne sur trois zones de disponibilité dans la région USA Est. Les zones de disponibilité ne sont pas prises en charge dans la région USA Ouest 2. Le cluster AKS dans USA Ouest 2 n’est pas redondant par zone. Si votre environnement de production nécessite une redondance de zone, assurez-vous que votre région jumelée prend en charge les zones de disponibilité. Pour plus d’informations, consultez la section Vue d’ensemble des zones de disponibilité pour les clusters AKS de Créer un cluster Azure Kubernetes Service (AKS) qui utilise des zones de disponibilité.
Utilisez les commandes suivantes pour obtenir l’adresse IP publique de l’instance de passerelle d’application. Enregistrez l’adresse IP, que vous utiliserez plus tard dans cet article.
export APPGW_ID=$(az aks show \ --resource-group ${RG_NAME_WESTUS} \ --name ${AKS_NAME_WESTUS} \ --query 'addonProfiles.ingressApplicationGateway.config.effectiveApplicationGatewayId' \ --output tsv) echo ${APPGW_ID} export APPGW_IP_ID=$(az network application-gateway show \ --id ${APPGW_ID} \ --query frontendIPConfigurations\[0\].publicIPAddress.id \ --output tsv) echo ${APPGW_IP_ID} export APPGW_IP_ADDRESS=$(az network public-ip show \ --id ${APPGW_IP_ID} \ --query ipAddress \ --output tsv) echo "App Gateway public IP address: ${APPGW_IP_ADDRESS}"Utilisez la commande suivante pour attacher une étiquette de nom de service de nom de domaine (DNS) à la ressource d’adresse IP publique. Remplacez
<your-chosen-DNS-name>par une valeur appropriée commeejb010316.az network public-ip update --ids ${APPGW_IP_ID} --dns-name <your-chosen-DNS-name>Vous pouvez vérifier le nom de domaine complet (FQDN) de l’IP publique avec
az network public-ip show. L’exemple suivant montre un FQDN avec une étiquette DNSejb010316:az network public-ip show \ --id ${APPGW_IP_ID} \ --query dnsSettings.fqdn \ --output tsvCette commande produit une sortie semblable à celle de l’exemple suivant :
ejb010316.westus.cloudapp.azure.com
Remarque
Si vous travaillez avec un cluster AKS existant, complétez les deux actions suivantes avant de continuer :
- Activez l’add-on du contrôleur d’entrée en suivant les étapes de la section Activer l’add-on du contrôleur d’entrée de passerelle d’application pour un cluster AKS existant.
- Si vous avez WLS en cours d’exécution dans l’espace de noms cible, pour éviter les conflits, nettoyez les ressources WLS dans l’espace de noms WebLogic Operator et l’espace de noms WebLogic Server. Dans cet article, l’offre WLS sur AKS a approvisionné le WebLogic Operator dans l’espace de noms
weblogic-operator-nset le WebLogic Server dans l’espace de nomssample-domain1-ns. Exécutezkubectl delete namespace weblogic-operator-ns sample-domain1-nspour supprimer les deux espaces de noms.
Activer l’extension AKS Backup
Avant de continuer, utilisez les étapes suivantes pour installer l’extension AKS Backup dans le cluster de la région secondaire :
Utilisez la commande suivante pour vous connecter au cluster AKS dans la région West US 2 :
az aks get-credentials \ --resource-group ${RG_NAME_WESTUS} \ --name ${AKS_NAME_WESTUS}Utilisez la commande suivante pour activer les pilotes CSI et les instantanés pour votre cluster :
az aks update \ --resource-group ${RG_NAME_WESTUS} \ --name ${AKS_NAME_WESTUS} \ --enable-disk-driver \ --enable-file-driver \ --enable-blob-driver \ --enable-snapshot-controller --yes
Ouvrez le groupe de ressources où AKS est déployé. Sélectionnez le cluster AKS dans la liste des ressources.
Sur la page d’accueil AKS, sélectionnez Paramètres>Sauvegarder>Installer l’extension.
Sur la page Installer l’extension AKS Backup, sélectionnez Suivant. Sélectionnez le compte de stockage et le conteneur Blob créés dans les étapes précédentes. Sélectionnez Suivant, puis Créer. Compléter cette étape prend environ cinq minutes.
Remarque
Pour réduire les coûts, vous pouvez arrêter le cluster AKS dans la région secondaire en suivant les étapes de la section Arrêter et démarrer un cluster Azure Kubernetes Service (AKS). Démarrez-le avant de restaurer le cluster WLS.
Attendez qu’une sauvegarde Vault-standard ait lieu
Dans AKS, la catégorie Vault-standard est la seule catégorie qui prend en charge la Géoredondance et la restauration interrégionale. Comme indiqué dans Quelle catégorie de stockage de sauvegarde prend en charge la sauvegarde AKS ?, « Un seul point de récupération programmé par jour est déplacé vers la catégorie Vault ». Vous devez attendre qu’une sauvegarde Vault-standard ait lieu. Un bon minimum est d’attendre 24 heures après avoir terminé l’étape précédente avant de continuer.
Arrêter le cluster principal
Le cluster WLS principal et le cluster WLS secondaire sont configurés avec la même base de données TLOG. Un seul cluster peut posséder la base de données à la fois. Pour vous assurer que le cluster secondaire fonctionne correctement, arrêtez le cluster WLS principal. Dans cet article, arrêtez le cluster AKS pour désactiver le cluster WLS en utilisant les étapes suivantes :
- Ouvrez le portail Azure et accédez au groupe de ressources que vous avez approvisionné dans la section Déployer WLS sur AKS.
- Ouvrez le cluster AKS répertorié dans le groupe de ressources.
- Sélectionnez Arrêter pour arrêter le cluster AKS. Assurez-vous que le déploiement se termine avant de continuer.
Restaurer le cluster WLS
La sauvegarde AKS prend en charge les sauvegardes de niveau Opérationnel et Coffre. Seules les sauvegardes stockées dans un niveau Coffre peuvent être utilisées pour effectuer une restauration vers le cluster d’une région différente (région Azure jumelée). Conformément aux règles de rétention définies dans la politique de sauvegarde, la première sauvegarde réussie d’une journée est déplacée vers le conteneur Blob interrégional. Pour plus d’informations, consultez la section Quelle catégorie de stockage de sauvegarde prend en charge la sauvegarde AKS ? dans Qu’est-ce que la sauvegarde Azure Kubernetes Service ?
Après avoir configuré la géo-redondance dans la section Configurer la géoredondance à l’aide d’Azure Backup, il faut au moins une journée pour que les sauvegardes de la catégorie Vault soient disponibles pour la restauration.
Utilisez les étapes suivantes pour restaurer le cluster WLS :
Ouvrez le portail Azure et recherchez Centre de sauvegarde. Sélectionnez Centre de sauvegarde sous Services.
Sous Gérer, sélectionnez Instances de sauvegarde. Filtrez sur le type de source de données Services Kubernetes pour trouver l’instance de sauvegarde que vous avez créée dans la section précédente.
Sélectionnez l’instance de sauvegarde pour voir la liste des points de restauration. Dans cet article, le nom de l’instance est une chaîne similaire à
wlsonaks*\wlsaksinstance20240109.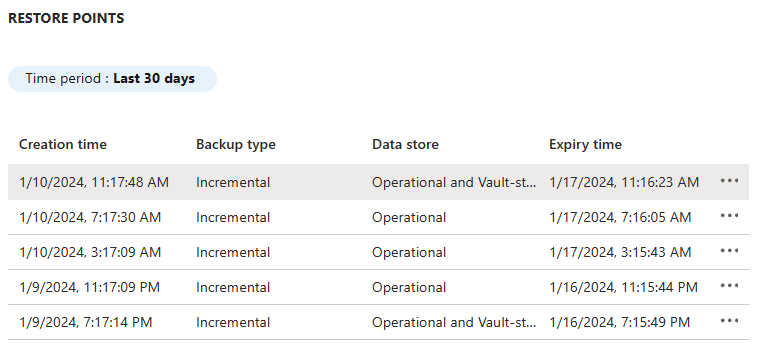
Sélectionnez la dernière sauvegarde Opérationnelle et Vault-standard, puis sélectionnez Plus d’options. Sélectionnez Restaurer pour démarrer le processus de restauration.
Sur la page Restaurer, le volet par défaut est Point de restauration. Sélectionnez Précédent pour passer au volet Informations de base. Pour Région de restauration, sélectionnez Région secondaire, puis sélectionnez Suivant : Point de restauration.
Sur le volet Point de restauration, pour Sélectionner la catégorie à restaurer, sélectionnez Vault Store, puis sélectionnez Suivant : Paramètres de restauration.
Sur le volet Paramètres de restauration, procédez comme suit :
Pour Sélectionner le cluster cible, sélectionnez le cluster AKS que vous avez créé dans la région West US 2 Vous rencontrez un problème de permission comme le montre la capture d’écran suivante. Sélectionnez Accorder la permission pour corriger les erreurs.
Pour Emplacement de mise en scène de la sauvegarde, sélectionnez le compte de stockage que vous avez créé dans USA Ouest 2. Vous rencontrez un problème de permission comme le montre la capture d’écran suivante. Sélectionnez Attribuer les rôles manquants pour corriger les erreurs.
Si les erreurs persistent après la fin de l’attribution des rôles, sélectionnez Revalider pour actualiser les permissions.
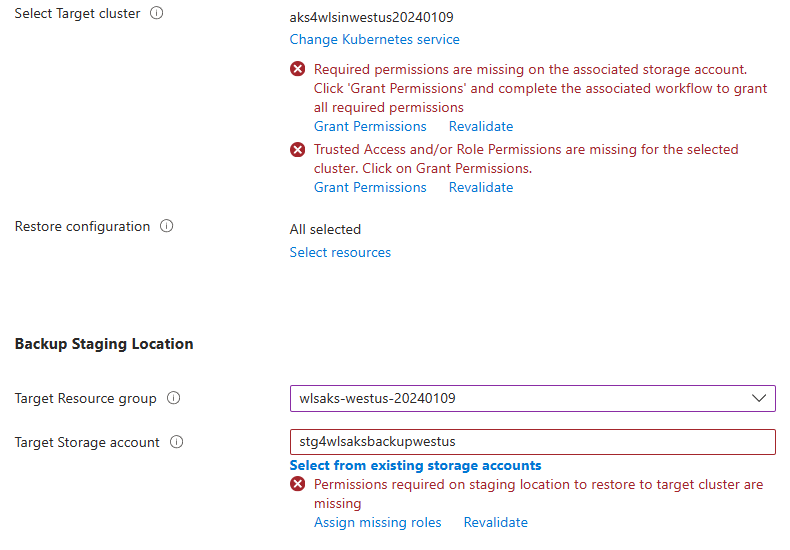
Lors de l’octroi des permissions manquantes, si vous êtes invité à spécifier une Étendue, acceptez la valeur par défaut.
Sélectionnez Valider. Vous devriez voir le message Validation réussie. Sinon, identifiez et résolvez le problème avant de continuer.
Sélectionnez Suivant : Vérification + restauration, puis sélectionnez Restaurer. Il faut environ 10 minutes pour restaurer le cluster WLS.
Vous pouvez surveiller le processus de restauration à partir de Centre de sauvegarde>Surveillance + rapports>Tâches de sauvegarde, comme indiqué dans la capture d’écran suivante :

Sélectionnez Actualiser pour voir les dernières avancées.
Après que le processus est terminé sans erreur, arrêtez le cluster AKS de sauvegarde. Si vous ne le faites pas, cela entraînera des conflits de propriété lorsque vous accéderez à la base de données TLOG dans les étapes suivantes.
Démarrez le cluster principal.





Configurez un Azure Traffic Manager
Dans cette section, vous créez un Azure Traffic Manager pour distribuer le trafic vers vos applications publiques à travers les régions Azure mondiales. Le point de terminaison principal pointe vers la passerelle d’application Azure dans le cluster WLS principal, et le point de terminaison secondaire pointe vers la passerelle d’application Azure dans le cluster WLS secondaire.
Créez un profil Azure Traffic Manager en suivant les étapes de la section Prise en main rapide : Créer un profil Traffic Manager à l’aide du portail Azure. Ignorez la section « Prérequis ». Vous avez seulement besoin des sections suivantes : Créer un profil Traffic Manager, Ajouter des points de terminaison Traffic Manager, et Tester le profil Traffic Manager. Procédez comme suit pendant ces sections, puis revenez à cet article après avoir créé et configuré le Traffic Manager Azure :
Lorsque vous atteignez la section Créer un profil Traffic Manager, à l’étape 2 Créer un profil Traffic Manager, procédez comme suit :
- Enregistrez le nom unique du profil Traffic Manager pour Nom : par exemple, tmprofile-ejb120623.
- Enregistrez le nom du nouveau groupe de ressources pour Groupe de ressources : par exemple, myResourceGroupTM1.
Lorsque vous atteignez la section Ajouter des points de terminaison Traffic Manager, procédez comme suit :
- Après l’étape Sélectionner le profil dans les résultats de la recherche, procédez comme suit :
- Sous Paramètres, sélectionnez Configuration.
- Pour Durée de vie du DNS (TTL), entrez 10.
- Sous Paramètres du moniteur de point de terminaison, pour Chemin, entrez /weblogic/ready.
- Sous Paramètres de basculement rapide du point de terminaison, utilisez les valeurs suivantes :
- Pour Intervalle de sondage interne, entrez 10.
- Pour Nombre toléré d’échecs, entrez 3.
- Pour Délai d’expiration du sondage (probe), entrez 5.
- Cliquez sur Enregistrer. Attendez que cela soit terminé.
- À l’étape 4 pour l’ajout du point de terminaison principal
myPrimaryEndpoint, procédez comme suit :- Pour Type de ressource cible, sélectionnez Adresse IP publique.
- Sélectionnez la liste déroulante Choisir une adresse IP publique et entrez l’adresse IP de la passerelle d’application déployée dans le cluster WLS de USA Est que vous avez sauvegardée précédemment. Vous devriez voir une entrée correspondante. Sélectionnez-la pour Adresse IP publique.
- À l’étape 6 pour l’ajout d’un point de terminaison de basculement / secondaire myFailoverEndpoint, procédez comme suit :
- Pour Type de ressource cible, sélectionnez Adresse IP publique.
- Sélectionnez la liste déroulante Choisir une adresse IP publique et entrez l’adresse IP de la passerelle d’application déployée dans le cluster WLS de USA Ouest que vous avez sauvegardée précédemment. Vous devriez voir une entrée correspondante. Sélectionnez-la pour Adresse IP publique.
- Patientez un moment. Sélectionnez Actualiser jusqu’à ce que le Statut du moniteur atteigne les états suivants :
- Le point de terminaison principal est En ligne.
- Le point de terminaison de basculement est Dégradé.
- Après l’étape Sélectionner le profil dans les résultats de la recherche, procédez comme suit :
Lorsque vous atteignez la section Tester le profil Traffic Manager, procédez comme suit :
- Dans la sous-section Vérifier le nom DNS, à l’étape 3, enregistrez le nom DNS de votre profil Traffic Manager, par exemple
http://tmprofile-ejb120623.trafficmanager.net. - Dans la sous-section Voir Traffic Manager en action, procédez comme suit :
- À l’étape 1 et 3, ajoutez /weblogic/ready au nom DNS de votre profil Traffic Manager dans votre navigateur web, par exemple
http://tmprofile-ejb120623.trafficmanager.net/weblogic/ready. Vous devriez voir une page vide sans message d’erreur. - À l’étape 4, vous ne pouvez pas accéder à /weblogic/ready, ce qui est attendu car le cluster secondaire est arrêté.
- Réactivez le point de terminaison principal.
- À l’étape 1 et 3, ajoutez /weblogic/ready au nom DNS de votre profil Traffic Manager dans votre navigateur web, par exemple
- Dans la sous-section Vérifier le nom DNS, à l’étape 3, enregistrez le nom DNS de votre profil Traffic Manager, par exemple
Le point de terminaison principal a maintenant les états Activé et En ligne et le point de terminaison de basculement a les états Activé et Dégradé dans le profil Traffic Manager. Gardez la page ouverte pour surveiller le statut du point de terminaison plus tard.
Testez le basculement du principal au secondaire
Pour tester le basculement, vous basculez manuellement votre serveur de base de données principal et le cluster WLS vers le serveur de base de données secondaire et le cluster WLS dans cette section.
Comme le cluster principal est en ligne, il agit en tant que cluster actif et gère toutes les demandes des utilisateurs routées par votre profil Traffic Manager.
Ouvrez le nom DNS de votre profil Azure Traffic Manager dans un nouvel onglet du navigateur, en ajoutant la racine du contexte /weblogic-cafe de l’application déployée, par exemple http://tmprofile-ejb120623.trafficmanager.net/weblogic-cafe. Créez un nouveau café avec un nom et un prix, par exemple Café 1 avec comme prix 10. Cette entrée est conservée à la fois dans la table des données de l’application et dans la table de session de la base de données. L’interface utilisateur que vous voyez devrait ressembler à la capture d’écran suivante :

Si votre interface utilisateur ne ressemble pas à cela, identifiez et résolvez le problème avant de continuer.
Gardez la page ouverte afin de pouvoir l’utiliser pour tester le basculement plus tard.
Basculer vers le site secondaire
Utilisez les étapes suivantes pour basculer du principal au secondaire.
Tout d’abord, utilisez les étapes suivantes pour arrêter le cluster AKS principal :
- Ouvrez le portail Azure et accédez au groupe de ressources qui a été approvisionné dans la section Déployer WLS sur AKS.
- Ouvrez le cluster AKS répertorié dans le groupe de ressources.
- Sélectionnez Arrêter pour arrêter le cluster AKS. Assurez-vous que le déploiement se termine avant de continuer.
Ensuite, procédez comme suit pour basculer la base de données SQL Azure du serveur principal vers le serveur secondaire.
- Passez à l’onglet du navigateur de votre groupe de basculement Azure SQL Database.
- Sélectionnez Basculement>Oui.
- Attendez que cela soit terminé.
Ensuite, utilisez les étapes suivantes pour démarrer le cluster secondaire.
- Ouvrez le portail Azure et allez dans le groupe de ressources qui a le cluster AKS dans la région secondaire.
- Ouvrez le cluster AKS répertorié dans le groupe de ressources.
- Sélectionnez Démarrer pour démarrer le cluster AKS. Assurez-vous que le déploiement se termine avant de continuer.
Enfin, utilisez les étapes suivantes pour vérifier l’application d’exemple après que le point de terminaison myFailoverEndpoint soit dans l’état En ligne :
Passez à l’onglet du navigateur de votre Traffic Manager, puis actualisez la page jusqu’à ce que vous voyiez que la valeur Statut du moniteur du point de terminaison
myFailoverEndpointentre dans l’état En ligne.Passez à l’onglet du navigateur de l’application d’exemple et actualisez la page. Vous devriez voir les mêmes données conservées dans la table des données de l’application et la table de session affichées dans l’interface utilisateur, comme indiqué dans la capture d’écran suivante :

Si vous n’observez pas ce comportement, cela peut être dû au fait que Traffic Manager prend du temps pour mettre à jour le DNS pour pointer vers le site de basculement. Le problème pourrait également être que votre navigateur a mis en cache le résultat de la résolution DNS qui pointe vers le site en échec. Attendez un moment et actualisez à nouveau la page.
Remarque
Une solution HA/DR prête pour la production tiendrait compte de la copie continue de la configuration WLS du cluster principal vers les clusters secondaires selon un calendrier régulier. Pour savoir comment faire cela, consultez les références à la documentation Oracle à la fin de cet article.
Pour automatiser le basculement, envisagez d’utiliser des alertes sur les métriques de Traffic Manager et Azure Automation. Pour plus d’informations, consultez la section Alertes sur les métriques de Traffic Manager de Métriques et alertes Traffic Manager et Utiliser une alerte pour déclencher un runbook Azure Automation.
Retour au site principal
Pour revenir au site principal, vous devez vous assurer que les deux clusters ont une configuration de sauvegarde en miroir. Vous pouvez atteindre cet état en utilisant les étapes suivantes :
- Activez les sauvegardes du cluster AKS dans la région Ouest US 2 en suivant les étapes de la section Configurer la géo-redondance à l'aide d'Azure Backup, à partir de l'étape 4.
- Restaurez la dernière sauvegarde de la catégorie Vault sur le cluster dans la région Est des États-Unis en suivant les étapes de la section Préparer la restauration du cluster WLS dans une région secondaire. Ignorez les étapes que vous avez déjà effectuées.
- Utilisez des étapes similaires à celles de la section Basculer vers le site secondaire pour revenir au site principal, y compris le serveur de base de données et le cluster.
Nettoyer les ressources
Si vous n’avez pas l’intention de continuer à utiliser les clusters WLS et d’autres composants, utilisez les étapes suivantes pour supprimer les groupes de ressources afin de nettoyer les ressources utilisées dans ce tutoriel :
- Dans la zone de recherche en haut du portail Azure, entrez Coffres de sauvegarde et sélectionnez les coffres de sauvegarde dans les résultats de la recherche.
- Sélectionnez Gérer>Propriétés>Suppression douce>Mettre à jour. À côté de Activer la suppression douce, décochez la case.
- Sélectionnez Gérer>Instances de sauvegarde. Sélectionnez l’instance que vous avez créée et supprimez-la.
- Entrez le nom du groupe de ressources des serveurs Azure SQL Database (par exemple,
myResourceGroup) dans la zone de recherche en haut du portail Azure, et sélectionnez le groupe de ressources correspondant dans les résultats de la recherche. - Sélectionnez Supprimer le groupe de ressources.
- Dans Entrez le nom du groupe de ressources pour confirmer la suppression, entrez le nom du groupe de ressources.
- Sélectionnez Supprimer.
- Répétez les étapes 4 à 7 pour le groupe de ressources du Traffic Manager, par exemple
myResourceGroupTM1. - Répétez les étapes 4 à 7 pour le groupe de ressources du cluster WLS principal, par exemple
wls-aks-eastus-20240109. - Répétez les étapes 4 à 7 pour le groupe de ressources du cluster WLS secondaire, par exemple
wls-aks-westus-20240109.
Étapes suivantes
Dans ce tutoriel, vous avez configuré une solution HA/DR composée d’une couche d’infrastructure applicative active-passive avec une couche de base de données active-passive, et dans laquelle les deux couches s’étendent sur deux sites géographiquement distincts. Sur le premier site, la couche d’infrastructure applicative et la couche de base de données sont toutes deux actives. Sur le deuxième site, le domaine secondaire est arrêté, et la base de données secondaire est en attente.
Continuez à explorer les références suivantes pour plus d’options pour créer des solutions HA/DR et exécuter WLS sur Azure :