Fractionner une collection de projets
Azure DevOps Server 2022 | Azure DevOps Server 2020 | Azure DevOps Server 2019
À mesure que votre entreprise change, vous pouvez fractionner une collection de projets unique en plusieurs collections de projets. Par exemple :
Vous souhaitez que les projets d’un regroupement s’alignent sur les unités commerciales de votre organisation, et les projets de la collection sont maintenant détenus par des unités distinctes.
Vous avez effectué une mise à niveau à partir d’une version antérieure d’Azure DevOps Server, vous n’avez qu’un seul regroupement et vous souhaitez organiser vos projets en regroupements distincts pour des raisons de sécurité ou d’alignement métier.
Vous souhaitez modifier la propriété de certains des projets de la collection vers un bureau distant disposant de son propre déploiement d’Azure DevOps Server. Ce scénario nécessite que vous fractionnez d’abord une collection, puis déplacez l’une des collections obtenues vers le déploiement du bureau à distance.
Remarque
Les procédures décrites dans cet article prennent uniquement en charge le fractionnement d’une collection de projets. Pour déplacer une collection après la fractionner, consultez Déplacer une collection de projets.
Pour fractionner une collection de projets, procédez comme suit :
Préparer le fractionnement de la collection
Fractionner la collection
Configurer les regroupements fractionnés
Avant de commencer
Assurez-vous que vous êtes administrateur sur les serveurs et dans SQL Server et Azure DevOps Server. Si vous n’êtes pas administrateur, ajoutez-en un.
1-a. Détacher la collection
Commencez par détacher la collection du déploiement d’Azure DevOps Server sur lequel elle s’exécute. Le détachement d’une collection arrête tous les travaux et services, ainsi que la base de données de collection elle-même. En outre, le processus de détachement copie les données spécifiques à la collection à partir de la base de données de configuration et les enregistre dans le cadre de la base de données de collecte de projets.
Détacher une collection de projets
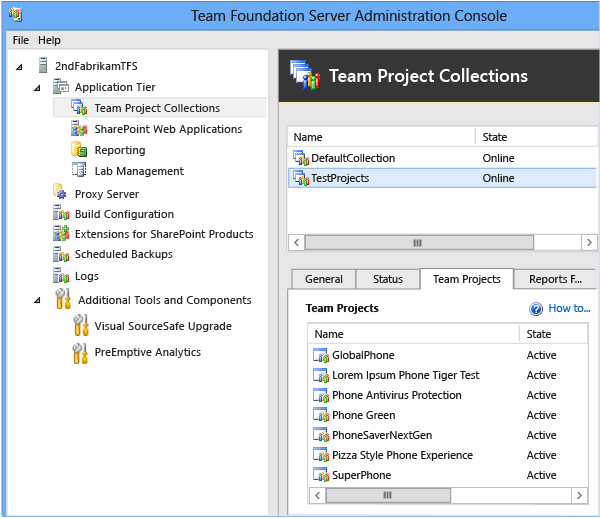
Ouvrez la console d’administration pour Azure DevOps sur le serveur qui héberge la collection à fractionner.
Sélectionnez Regroupements de projets, puis, dans la liste des regroupements, sélectionnez la collection à fractionner.
Dans cet exemple, l’administrateur choisit TestProjects.
Conseil
Le nom par défaut d’une collection de projets est DefaultCollection. Si vous divisez cette base de données, veillez à donner au deuxième regroupement un nom différent, car il s’agit du choix par défaut à la connexion.
Sous l’onglet Général, sélectionnez Arrêter la collection.
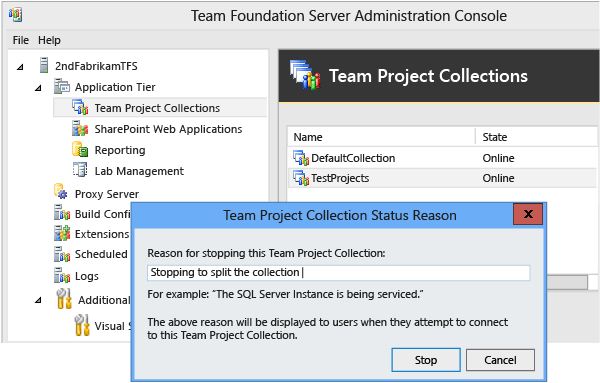
La boîte de dialogue Raison de l’état de la collection de projets s’ouvre. Le texte que vous entrez s’affiche à vos utilisateurs. Sélectionnez Arrêter, puis attendez que la collection s’arrête. Lorsqu’il est arrêté, son état s’affiche en mode Hors connexion.
Sous l’onglet Général, sélectionnez Détacher la collection.
L’Assistant Détacher la collection de projets s’ouvre.
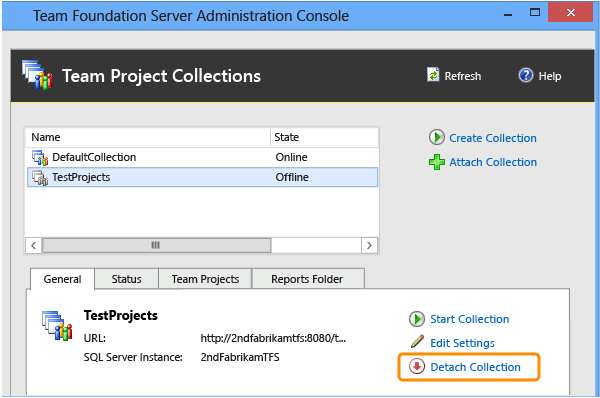
(Facultatif) Dans la page Fournir un message de maintenance pour la page collection de projets, dans Message de maintenance, fournissez un message aux utilisateurs susceptibles de tenter de se connecter à des projets de cette collection.
Dans les paramètres de révision qui seront utilisés pour détacher la page de collection de projets, passez en revue les détails. Pour modifier les paramètres, sélectionnez Précédent. S’ils sont corrects, sélectionnez Vérifier.
Une fois toutes les vérifications de préparation terminées, sélectionnez Détacher.
Dans la page Surveiller la progression de la collection de projets, lorsque tous les processus sont terminés, sélectionnez Suivant.
(Facultatif) Dans les informations supplémentaires de révision de cette page de collection de projets, sélectionnez ou notez l’emplacement du fichier journal, puis fermez l’Assistant.
La collection de projets n’apparaît plus dans la liste des regroupements dans la console d’administration.
1-b. Sauvegarder la base de données de collection
Une fois que vous avez détaché la collection, vous devez sauvegarder sa base de données avant de pouvoir restaurer une copie sur le serveur avec un autre nom. Cette copie deviendra la base de données pour la partie de la collection d’origine que vous souhaitez fractionner en une autre collection. Pour effectuer cette tâche, utilisez les outils fournis avec SQL Server.
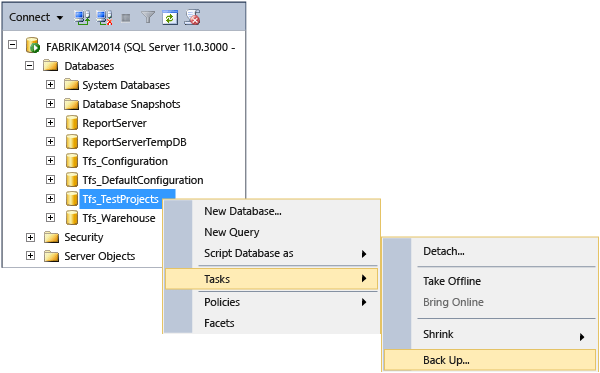
Sauvegarder une base de données de collection
Pour plus d’informations sur la façon de sauvegarder et restaurer manuellement des bases de données individuelles, consultez Sauvegarde et restauration de bases de données dans SQL Server et créer une planification et un plan de sauvegarde. Veillez à sélectionner la version de SQL Server qui correspond à votre déploiement.
Important
Si votre déploiement d’origine a utilisé les éditions Enterprise ou Datacenter de SQL Server et que vous souhaitez restaurer la base de données que vous souhaitez fractionner sur un serveur exécutant l’édition Standard, vous devez utiliser un jeu de sauvegarde créé avec la compression SQL Server désactivée. Sauf si vous désactivez la compression des données, vous ne pourrez pas restaurer correctement les bases de données d’édition Entreprise ou Datacenter sur un serveur exécutant l’édition Standard. Pour désactiver la compression, suivez les étapes décrites dans Désactiver la compression des données SQL Server dans les bases de données Azure DevOps.
2 a. Restaurer la base de données de collection
Lorsque vous fractionnez un regroupement, vous devez restaurer la sauvegarde de la base de données de collecte sur une instance de SQL Server configurée pour prendre en charge le déploiement d’Azure DevOps Server. Lorsque vous restaurez la base de données, vous devez lui attribuer un nom différent du nom de la base de données de collection d’origine.
Conseil
Les étapes ci-dessous donnent une vue d’ensemble générale de la restauration d’une base de données de collection de projets dans SQL Server 2012 à l’aide de SQL Server Management Studio. Pour plus d’informations sur la façon de sauvegarder et restaurer manuellement des bases de données individuelles, consultez Sauvegarde et restauration de bases de données dans SQL Server. Veillez à sélectionner la version de SQL Server qui correspond à votre déploiement.
Restaurer la base de données de collection avec un nouveau nom
Ouvrez SQL Server Management Studio et connectez-vous à l’instance qui héberge la base de données de la collection de projets à fractionner.
Dans l’Explorateur d’objets, développez Bases de données, ouvrez le sous-menu de la base de données à fractionner, puis sélectionnez Tâches, Restaurer, puis sélectionnez Base de données.
La fenêtre Restaurer la base de données s’ouvre sur la page Général .
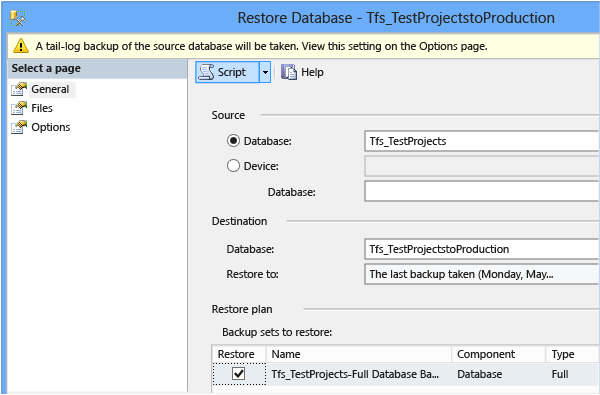
Dans Source, vérifiez que la base de données de collection de projets est choisie. Dans Destination, indiquez un nom pour la copie de la base de données. Conservez le préfixe Tfs_ et ajoutez un nom distinct. En règle générale, ce nom est le nom de la collection de projets fractionnée. Dans le plan de restauration, assurez-vous que les jeux de sauvegarde à restaurer sont ceux sur lesquelles vous souhaitez effectuer la restauration. Pour vous assurer que ces jeux sont valides, sélectionnez Vérifier le support de sauvegarde, puis, dans Sélectionner une page, sélectionnez Options.
Dans les options de restauration, laissez toutes les cases à cocher vides. Vérifiez que l’état de récupération est défini sur RESTORE WITH RECOVERY. Dans Tail-Log Backup, désactivez la case à cocher Quitter la base de données source dans la case à cocher Restaurer l’état , puis sélectionnez OK.
Conseil
Si l’opération de restauration échoue avec un message d’erreur indiquant que la base de données est en cours d’utilisation et ne peut pas être remplacée, vous devrez peut-être configurer manuellement tous les noms de fichiers logiques pour refléter le nouveau nom de la base de données. Dans Sélectionner une page, sélectionnez Fichiers, sélectionnez le bouton de sélection en regard de chaque fichier en cours de restauration et assurez-vous que les noms des fichiers reflètent le nouveau nom de la base de données, et non l’ancien. Réessayez ensuite l’opération de restauration.
2-b. Attacher la base de données de collection d’origine
Après avoir restauré la base de données avec un autre nom, rattachez la base de données de collection d’origine au déploiement d’Azure DevOps Server.
Attacher la collection
Ouvrez la console d’administration pour Azure DevOps.
Sélectionnez Regroupements de projets, puis attachez la collection.
L’Assistant Attacher la collection de projets s’ouvre.
Dans la page Sélectionner la base de données de collection de projets à joindre , dans SQL Server Instance, indiquez le nom du serveur et l’instance qui héberge la base de données de collection, si elle n’est pas déjà répertoriée.
Dans la liste Bases de données , sélectionnez la base de données de collection à attacher.
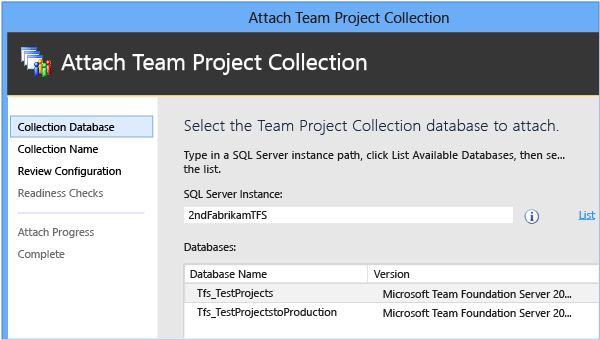
Dans la page Entrer les informations de collection de projets, indiquez un nom pour la collection dans Name si celle-ci n’est pas déjà présente. Étant donné qu’il s’agit de la collection d’origine, vous pouvez choisir de laisser le nom identique à celui qu’il avait précédemment. Dans Description, indiquez éventuellement une description de la collection.
Dans les paramètres de révision qui seront utilisés pour joindre la page de collecte de projets, passez en revue les informations.
Pour modifier les paramètres, sélectionnez Précédent. Si tous les paramètres sont corrects, sélectionnez Vérifier.
Une fois toutes les vérifications de préparation terminées, sélectionnez Attacher.
Dans la page Surveiller la progression de la collection de projets, lorsque tous les processus sont terminés, sélectionnez Suivant.
(Facultatif) Dans les informations supplémentaires de révision de cette page de collection de projets, sélectionnez ou notez l’emplacement du fichier journal, puis fermez l’Assistant.
La collection de projets apparaît dans la liste des regroupements dans la console d’administration. Si l’état de la collection est répertorié en ligne, vous devez l’arrêter avant de continuer. Sélectionnez la collection dans la liste, puis, sous l’onglet Général , sélectionnez Arrêter la collection.
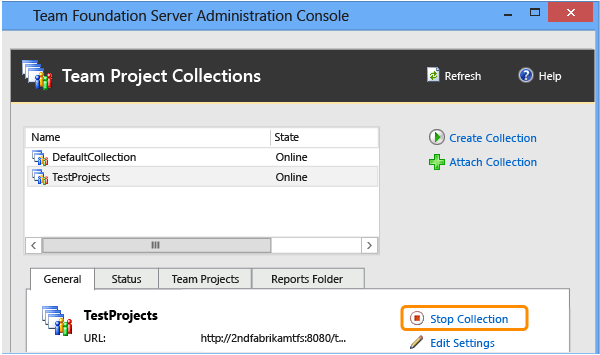
2-c. Attacher la base de données de collection renommée
Après avoir attaché la base de données de collection d’origine, vous devez attacher la collection renommée au déploiement d’Azure DevOps Server. Lorsque cette collection est attachée, elle reste arrêtée. Vous ne pourrez pas le démarrer tant que tous les projets en double n’ont pas été supprimés.
Attacher la base de données de collection renommée
Ouvrez la console d’administration pour Azure DevOps.
Sélectionnez Regroupements de projets, puis attachez la collection pour ouvrir l’Assistant.
Dans la base de données Sélectionner la collection de projets à joindre , dans SQL Server Instance, indiquez le nom du serveur et l’instance qui héberge la base de données de collection renommée, si elle n’est pas déjà répertoriée.
Dans la liste Bases de données , sélectionnez la base de données de collection renommée.
Dans la page Entrer les informations de collection de projets, entrez un nom pour la collection renommée dans Name qui diffère du nom du nom d’origine de la collection. Cela doit correspondre au nom que vous avez donné à la base de données renommée, sans le préfixe Tfs_.
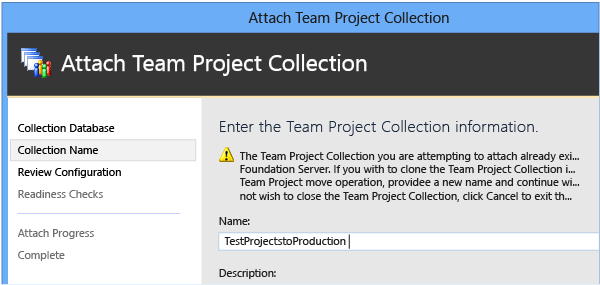
(Facultatif) Dans Description, entrez une description de la collection.
Dans les paramètres de révision qui seront utilisés pour joindre la page de collecte de projets, passez en revue les informations. Pour modifier les paramètres, sélectionnez Précédent. Si tous les paramètres sont corrects, sélectionnez Vérifier.
Une fois toutes les vérifications de préparation terminées, sélectionnez Attacher.
Dans la page Surveiller la progression de la collection de projets, lorsque tous les processus sont terminés, sélectionnez Suivant.
(Facultatif) Dans les informations supplémentaires de révision de cette page de collection de projets, sélectionnez ou notez l’emplacement du fichier journal, puis fermez l’Assistant.
Le nom de la collection apparaît dans la liste des regroupements dans la console d’administration, et son état doit s’afficher en mode hors connexion.
Pour vous assurer que les deux collections ont été attachées avec des ID uniques, dans la console d’administration, accédez aux journaux d’événements et ouvrez les fichiers journaux pour les deux opérations d’attachement de collection. Les GUID pour CollectionProperties ne doivent pas correspondre.
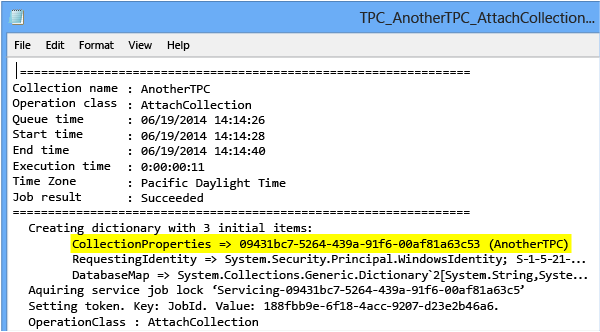
Dans le cas peu probable où les GUID CollectionProperties correspondent, remplacez l’ID par un ID unique avant de continuer en exécutant la commande TFSConfig Collection sur la deuxième collection avec le paramètre /clone.
2d. Supprimer des projets sur les collections fractionnées
Maintenant que vous avez deux copies de la collection attachée à Azure DevOps Server, vous devez supprimer chaque projet de la collection d’origine ou de la collection renommée afin qu’aucun projet ne reste dans les deux collections.
Important
Un projet ne peut pas exister dans plusieurs collections. Tant que vous n’avez pas supprimé tous les projets dupliqués entre les collections fractionnées, vous ne pourrez pas démarrer la collection renommée.
Supprimer des projets des collections
Ouvrez la console d’administration pour Azure DevOps.
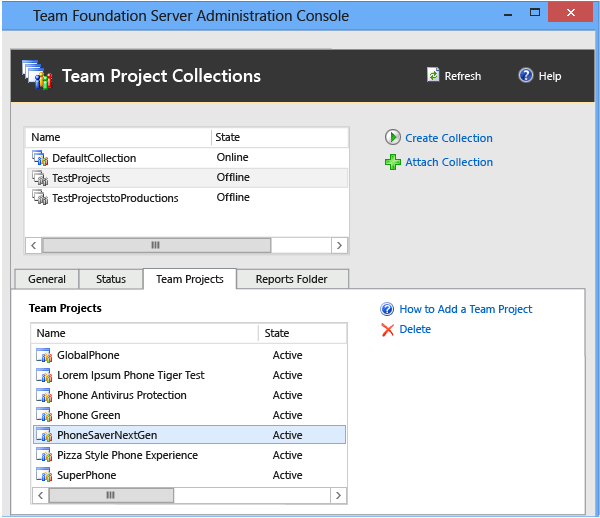
Sélectionnez Regroupements de projets, puis, dans la liste des regroupements, sélectionnez la collection de projets d’origine que vous avez arrêtée pour la fractionner.
Sous l’onglet Projets , dans la liste des projets, sélectionnez un projet à supprimer de la collection, puis sélectionnez Supprimer.
Conseil
Vous pouvez sélectionner plusieurs projets à supprimer à la fois.
Cochez la case Supprimer les données de l’espace de travail, cochez la case Supprimer les artefacts externes, puis sélectionnez Supprimer.
Si la case à cocher Supprimer les artefacts externes n’est pas désactivée et que votre projet est configuré pour utiliser la gestion de labo, les machines virtuelles et les modèles associés au projet sont supprimés de System Center Virtual Machine Manager. Ils ne seront plus disponibles pour le projet dans la collection renommée. (Notez que la gestion des laboratoires a été déconseillée pour TFS 2017 et versions ultérieures.)
Lorsque vous avez terminé de supprimer les projets que vous ne souhaitez pas héberger dans la collection de projets d’origine, sélectionnez la collection de projets renommée dans la liste des regroupements. Ensuite, sous l’onglet Projets , supprimez les projets indésirables de la nouvelle collection.
Répétez les étapes de cette section jusqu’à ce que les deux collections contiennent un ensemble de projets uniques.
2-e. Démarrer les collections de projets
Après avoir supprimé des projets, redémarrez les deux collections.
Démarrer une collection de projets
Ouvrez la console d’administration pour Azure DevOps.
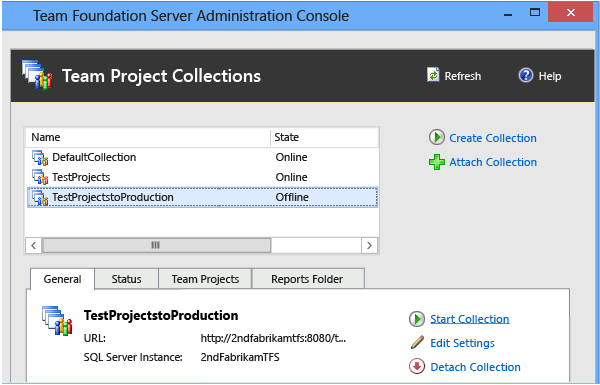
Sélectionnez Collections de projets, puis, dans la liste des regroupements, sélectionnez la collection que vous avez arrêtée pour la fractionner.
Sous l’onglet Général, sélectionnez Démarrer la collection.
Répétez l’étape 2 pour la collection que vous avez attachée avec un nouveau nom.
3 a. Configurer des utilisateurs et des groupes pour les regroupements fractionnés
Vous pouvez ignorer cette procédure si les deux collections fractionnées restent dans le même domaine et que vous souhaitez autoriser l’accès pour les administrateurs de la collection d’origine aux deux collections.
Une fois que vous avez fractionné une collection, vous devez mettre à jour les groupes d’autorisations pour les deux regroupements avec des utilisateurs et des groupes qui administreront ces regroupements. Pour plus d’informations, consultez Définir des autorisations d’administrateur pour les regroupements de projets.
3-b. Configurer des utilisateurs et des groupes pour des projets
Vous pouvez ignorer cette procédure si les collections fractionnées restent dans le même domaine et que vous souhaitez autoriser l’accès pour les utilisateurs de projets de la collection d’origine aux deux collections.
Après avoir configuré les administrateurs pour les deux regroupements, vous ou ces administrateurs devez configurer l’accès pour les utilisateurs et les groupes aux projets de chaque collection. Selon votre déploiement, vous devrez peut-être également configurer des autorisations pour ces utilisateurs dans Reporting Services. Pour plus d’informations, consultez Ajouter des utilisateurs à des projets ou des équipes.
Questions & réponses
Q : Mon déploiement utilise la création de rapports. Existe-t-il des étapes supplémentaires à suivre lors du fractionnement des regroupements ?
R : Oui, vous devez fractionner les rapports une fois les projets supprimés afin que les deux collections aient un ensemble unique de projets. Vous devez également reconstruire votre entrepôt de données.
Après avoir supprimé des projets, déplacez les rapports que la collection fractionnée utilise dans un autre dossier, puis supprimez-les du dossier d’origine.
Important
Les dossiers de rapport existent dans les deux emplacements. Veillez à déplacer correctement tous les rapports avant de supprimer les dossiers de rapports.
Fractionner des rapports en dossiers distincts
- Dans le Gestionnaire de rapports, déplacez les rapports qui prennent en charge la collection fractionnée dans les dossiers appropriés pour cette collection. Pour plus d’informations, consultez La page Déplacer des éléments.
Une fois que vous avez fractionné les rapports et démarré les deux collections, régénérez l’entrepôt pour Azure DevOps et la base de données pour Analysis Services. Vous devez effectuer cette étape pour vous assurer que les rapports et les tableaux de bord fonctionnent correctement pour le déploiement après avoir fractionné la collection et qu’aucun conflit ne se produit avec d’autres regroupements dans le déploiement.
Reconstruire l’entrepôt de données et la base de données Analysis Services
Ouvrez la console d’administration pour Azure DevOps.
Dans la barre de navigation, sélectionnez Création de rapports.
Dans Création de rapports, sélectionnez Démarrer la reconstruction.
Dans la boîte de dialogue Reconstruire les bases de données Warehouse et Analysis Services, sélectionnez OK.
Remarque
Les entrepôts continueront d’être reconstruits et les données continueront d’être renseignées une fois l’action de reconstruction de démarrage terminée. Selon la taille de votre déploiement et la quantité de données, l’ensemble du processus peut prendre plusieurs heures.