Résolution de problèmes Apache Spark à l’aide d’Azure HDInsight
Découvrez les principaux problèmes rencontrés lors de l’utilisation de charges utiles Apache Spark dans Apache Ambari et leur résolution.
Comment configurer une application Apache Spark sur des clusters via Apache Ambari ?
Les valeurs de configuration Spark peuvent être paramétrées afin d’éviter l’exception OutofMemoryError de l’application Apache Spark. Les étapes suivantes montrent des valeurs de configuration Spark par défaut dans Azure HDInsight :
Connectez-vous à Ambari sur
https://CLUSTERNAME.azurehdidnsight.netavec les informations d’identification du cluster. L’écran initial affiche un tableau de bord de présentation. Il existe de légères différences de présentation entre HDInsight 4.0.Accédez à Spark2>Configs.
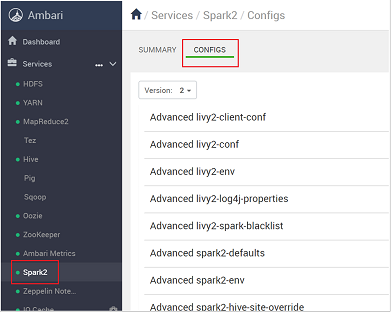
Dans la liste des configurations, sélectionnez et développez Custom-spark2-defaults.
Recherchez le paramètre de valeur que vous avez besoin d’ajuster, par exemple spark.executor.memory. Dans le cas présent, la valeur de 9728m est trop élevée.
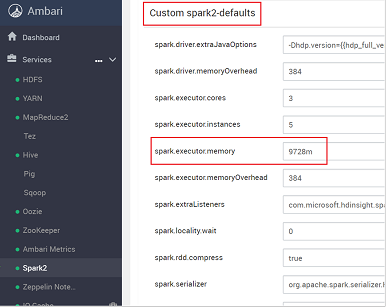
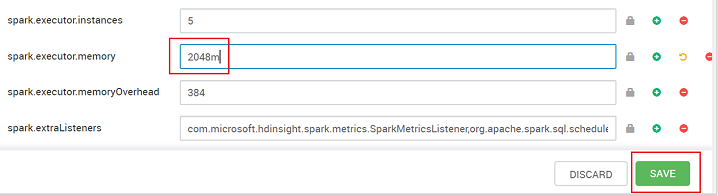
Définissez la valeur sur le paramètre recommandé. La valeur 2048m est recommandée pour ce paramètre.
Enregistrez la valeur, puis la configuration. Cliquez sur Enregistrer.
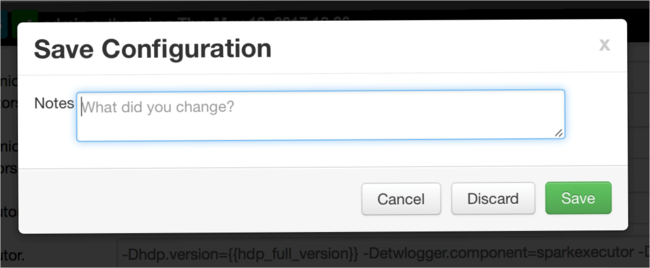
Notez les modifications apportées à la configuration, puis sélectionnez Enregistrer.
Si des configurations requièrent votre attention, un message s’affiche. Notez les éléments, puis sélectionnez Proceed Anyway (Continuer).

Chaque fois que vous enregistrez une configuration, vous êtes invité à redémarrer le service. Sélectionnez Redémarrer.
Confirmez le redémarrage.
Vous pouvez examiner les processus en cours d’exécution.
Vous pouvez ajouter des configurations. Dans la liste des configurations, sélectionnez Custom-spark2-defaults, puis Ajouter une propriété.
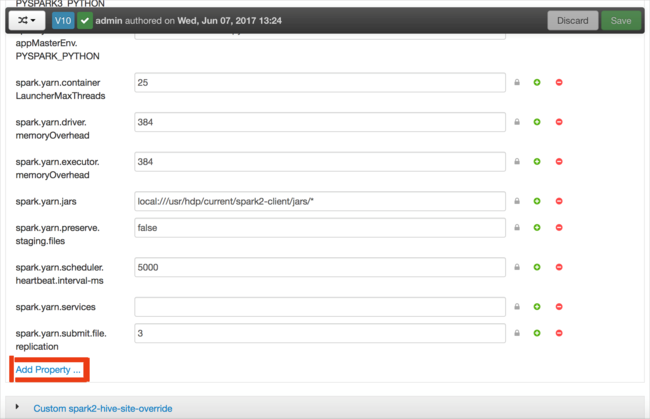
Définissez une nouvelle propriété. Vous pouvez définir une propriété unique via une boîte de dialogue de paramètres spécifiques tels que le type de données. Vous pouvez également définir plusieurs propriétés en utilisant une définition par ligne.
Dans cet exemple, la propriété spark.driver.memory est définie avec une valeur de 4g.
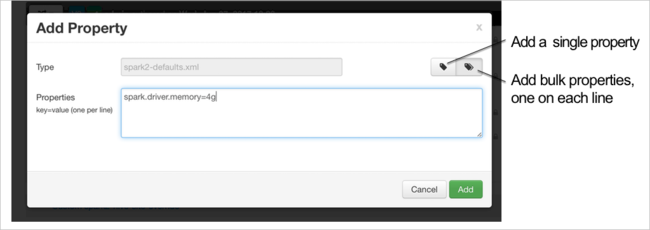
Enregistrez la configuration et redémarrez le service en suivant la procédure décrite aux étapes 6 et 7.
Ces modifications s’appliquent à l’ensemble du cluster, mais elles peuvent être remplacées au moment de l’envoi du travail Spark.
Comment configurer une application Apache Spark sur des clusters avec un notebook Jupyter ?
Dans la première cellule du notebook Jupyter, spécifiez, après la directive %%configure, les configurations Spark dans un format JSON valide. Modifiez les valeurs si nécessaire :

Comment configurer une application Apache Spark sur des clusters via Apache Livy ?
Soumettez la demande de l’application Spark à Livy à l’aide d’un client REST comme cURL. Utilisez une commande similaire à la suivante. Modifiez les valeurs si nécessaire :
curl -k --user 'username:password' -v -H 'Content-Type: application/json' -X POST -d '{ "file":"wasb://container@storageaccountname.blob.core.windows.net/example/jars/sparkapplication.jar", "className":"com.microsoft.spark.application", "numExecutors":4, "executorMemory":"4g", "executorCores":2, "driverMemory":"8g", "driverCores":4}'
Comment configurer une application Apache Spark sur des clusters via spark-submit ?
Lancez spark-shell à l’aide d’une commande semblable à la suivante. Modifiez la valeur des configurations selon les besoins :
spark-submit --master yarn-cluster --class com.microsoft.spark.application --num-executors 4 --executor-memory 4g --executor-cores 2 --driver-memory 8g --driver-cores 4 /home/user/spark/sparkapplication.jar
Lecture supplémentaire
Apache Spark job submission on HDInsight clusters (Envoi de travaux Spark sur des clusters HDInsight)
Étapes suivantes
Si votre problème ne figure pas dans cet article ou si vous ne parvenez pas à le résoudre, utilisez un des canaux suivants pour obtenir de l’aide :
Débogage d’une application Spark sur des clusters HDInsight.
Obtenez des réponses de la part d’experts Azure en faisant appel au Support de la communauté Azure.
Connectez-vous à @AzureSupport, le compte Microsoft Azure officiel pour améliorer l’expérience client. Connexion de la communauté Azure aux ressources appropriées : réponses, support technique et experts.
Si vous avez besoin d’une aide supplémentaire, vous pouvez envoyer une requête de support à partir du Portail Microsoft Azure. Sélectionnez Support dans la barre de menus, ou ouvrez le hub Aide + Support. Pour plus d’informations, consultez Création d’une demande de support Azure. L’accès au support relatif à la gestion et à la facturation des abonnements est inclus avec votre abonnement Microsoft Azure. En outre, le support technique est fourni avec l’un des plans de support Azure.