Composant Exécuter le script Python
Cet article décrit le composant Exécuter un script Python dans le concepteur Azure Machine Learning.
Utilisez ce composant pour exécuter le code Python. Pour plus d’informations sur les principes de conception et d’architecture de Python, consultez Exécuter du code python dans le concepteur Azure Machine Learning.
Python vous permet d’exécuter des tâches qui ne sont pas prises en charge par les composants existants, telles que :
- Visualisation des données à l’aide de
matplotlib. - Utilisation des bibliothèques Python pour énumérer les jeux de données et les modèles de votre espace de travail.
- La lecture, le chargement et la manipulation de données à partir de sources que le composant Importer des données ne prend pas en charge.
- Exécution de votre propre code de deep learning.
Packages Python pris en charge
Azure Machine Learning utilise la distribution Anaconda de Python, qui inclut de nombreux utilitaires courants pour le traitement des données. La version d’Anaconda est mise à jour automatiquement. La version actuelle est :
- distribution Anaconda 4.5+ pour Python 3.6
Pour obtenir la liste complète, consultez la section Packages Python préinstallés.
Pour installer des packages qui ne figurent pas dans la liste des packages préinstallés (par exemple, scikit-misc), ajoutez le code suivant à votre script :
import os
os.system(f"pip install scikit-misc")
Utilisez le code suivant pour installer des packages pour de meilleures performances, en particulier pour l’inférence :
import importlib.util
package_name = 'scikit-misc'
spec = importlib.util.find_spec(package_name)
if spec is None:
import os
os.system(f"pip install scikit-misc")
Notes
Si votre pipeline contient plusieurs composants Exécuter un script Python et que vous avez besoin de packages qui ne figurent pas dans la liste préinstallée, installez les packages dans chaque composant.
Avertissement
Le composant Exécuter un script Python ne prend pas en charge l’installation de packages qui dépendent de bibliothèques natives supplémentaires avec une commande comme « apt-get », telles que Java, PyODBC, etc. Cela est dû au fait que ce composant est exécuté dans un environnement simple avec Python préinstallé uniquement et avec une autorisation non administrateur.
Accès à l’espace de travail actuel et aux jeux de données inscrits
Vous pouvez vous référer à l’exemple de code suivant pour accéder aux jeux de données inscrits dans votre espace de travail :
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from azureml.core import Run
run = Run.get_context(allow_offline=True)
#access to current workspace
ws = run.experiment.workspace
#access to registered dataset of current workspace
from azureml.core import Dataset
dataset = Dataset.get_by_name(ws, name='test-register-tabular-in-designer')
dataframe1 = dataset.to_pandas_dataframe()
# If a zip file is connected to the third input port,
# it is unzipped under "./Script Bundle". This directory is added
# to sys.path. Therefore, if your zip file contains a Python file
# mymodule.py you can import it using:
# import mymodule
# Return value must be of a sequence of pandas.DataFrame
# E.g.
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Charger des fichiers
Le composant Exécuter un script Python prend en charge le chargement de fichiers à l’aide du kit SDK Azure Machine Learning Python.
L’exemple suivant montre comment charger un fichier image dans le composant Exécuter un script Python :
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Imports up here can be used to
import pandas as pd
# The entry point function must have two input arguments:
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
plt.savefig(img_file)
from azureml.core import Run
run = Run.get_context(allow_offline=True)
run.upload_file(f"graphics/{img_file}", img_file)
# Return value must be of a sequence of pandas.DataFrame
# For example:
# - Single return value: return dataframe1,
# - Two return values: return dataframe1, dataframe2
return dataframe1,
Une fois l’exécution du pipeline terminée, vous pouvez voir un aperçu de l’image dans le panneau droit du composant.
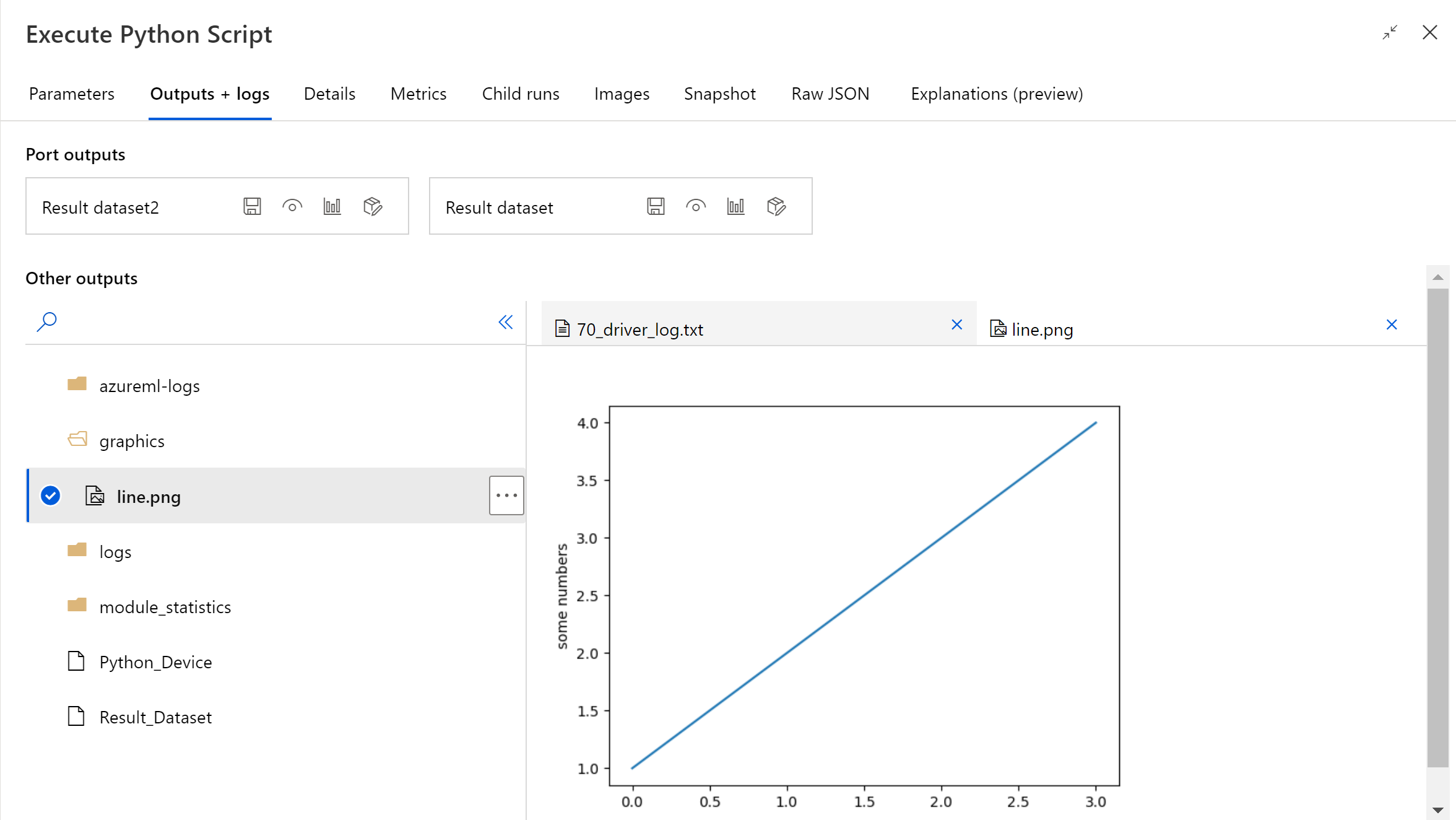
Vous pouvez également charger le fichier dans n’importe quel magasin de données à l’aide du code suivant. Vous pouvez uniquement afficher un aperçu du fichier dans votre compte de stockage.
import pandas as pd
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
# Execution logic goes here
print(f'Input pandas.DataFrame #1: {dataframe1}')
from matplotlib import pyplot as plt
import os
plt.plot([1, 2, 3, 4])
plt.ylabel('some numbers')
img_file = "line.png"
# Set path
path = "./img_folder"
os.mkdir(path)
plt.savefig(os.path.join(path,img_file))
# Get current workspace
from azureml.core import Run
run = Run.get_context(allow_offline=True)
ws = run.experiment.workspace
# Get a named datastore from the current workspace and upload to specified path
from azureml.core import Datastore
datastore = Datastore.get(ws, datastore_name='workspacefilestore')
datastore.upload(path)
return dataframe1,
Comment configurer le module Exécuter un script Python
Le composant Exécuter un script Python contient un exemple de code Python que vous pouvez utiliser comme point de départ. Pour configurer le composant Exécuter un script Python, fournissez un ensemble d’entrées et de code Python à exécuter dans la zone de texte Script Python.
Ajoutez le composant Exécuter un script Python à votre pipeline.
À partir du concepteur, ajoutez et connectez dans Jeu de données 1 tous les jeux de données que vous souhaitez utiliser pour l’entrée. Référencez ce jeu de données dans votre script Python sous le nom DataFrame1.
L’utilisation d’un jeu de données est facultative. Utilisez-en un si vous souhaitez générer des données à l’aide de Python ou utiliser du code Python pour importer les données directement dans le composant.
Ce composant prend en charge l’ajout d’un second jeu de données, Dataset2. Référencez ce second jeu de données dans votre script Python sous le nom DataFrame2.
Les jeux de données stockés dans Azure Machine Learning sont automatiquement convertis en trames de données pandas lorsqu’ils sont chargés avec ce composant.
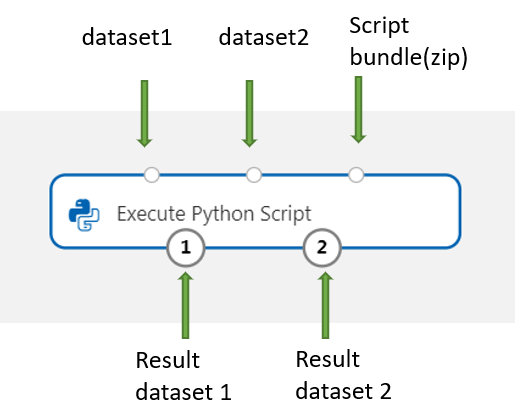
Pour inclure du code ou de nouveaux packages Python, connectez le fichier compressé qui contient ces ressources personnalisées au port Script bundle. Si la taille de votre script est supérieure à 16 Ko, vous pouvez également utiliser le port Script Bundle pour éviter des erreurs comme La ligne de commande dépasse la limite de 16597 caractères.
- Regroupez le script et d'autres ressources personnalisées dans un fichier zip.
- Chargez le fichier zip en tant que jeu de données dans Studio.
- Faites glisser le composant du jeu de données de la liste Jeux de données vers le volet de composant de gauche sur la page de création du concepteur.
- Connectez le composant de jeu de données au port Script Bundle du composant Exécuter le script Python.
Tous les fichiers qui figurent dans l’archive zip chargée sont utilisables lors de l’exécution du pipeline. Si l’archive est contenue dans une structure de répertoires, la structure est conservée.
Important
Utilisez un nom unique et explicite pour les fichiers du lot de scripts, car certains mots courants (comme
test,app, etc.) sont réservés aux services intégrés.Voici un exemple de regroupement de scripts, qui contient un fichier de script Python et un fichier txt :
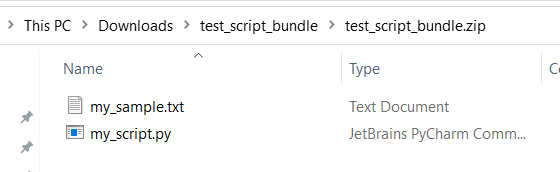
Voici le contenu de
my_script.py:def my_func(dataframe1): return dataframe1Voici un exemple de code montrant comment utiliser les fichiers dans le regroupement de scripts :
import pandas as pd from my_script import my_func def azureml_main(dataframe1 = None, dataframe2 = None): # Execution logic goes here print(f'Input pandas.DataFrame #1: {dataframe1}') # Test the custom defined Python function dataframe1 = my_func(dataframe1) # Test to read custom uploaded files by relative path with open('./Script Bundle/my_sample.txt', 'r') as text_file: sample = text_file.read() return dataframe1, pd.DataFrame(columns=["Sample"], data=[[sample]])Dans la zone de texte Script Python, saisissez ou collez un script Python valide.
Notes
Faites preuve de prudence lors de l’écriture de votre script. Assurez-vous qu’il n’existe pas d’erreurs de syntaxe, comme l’utilisation de variables non déclarées ou de composants ou fonctions non importés. Portez une attention particulière à la liste des composants préinstallés. Pour importer des composants qui ne sont pas listés, installez les packages correspondants dans votre script, tels que :
import os os.system(f"pip install scikit-misc")La zone de texte Script Python est préremplie avec certaines instructions en commentaires, ainsi qu’avec un exemple de code pour l’accès aux données et la sortie. Vous devez modifier ou remplacer ce code. Suivez les conventions Python concernant la mise en retrait et la casse :
- Le script doit contenir une fonction nommée
azureml_maincomme point d’entrée pour ce composant. - La fonction de point d’entrée doit avoir deux arguments d’entrée,
Param<dataframe1>etParam<dataframe2>, même lorsque ces arguments ne sont pas utilisés dans votre script. - Les fichiers compressés connectés au troisième port d’entrée sont décompressés et stockés dans le répertoire
.\Script Bundle, qui est également ajouté à l’élémentsys.pathPython.
Si votre fichier .zip contient
mymodule.py, importez-le à l’aide deimport mymodule.Deux jeux de données peuvent être renvoyés au concepteur, ce qui doit constituer une séquence de type
pandas.DataFrame. Vous pouvez créer d’autres sorties dans votre code Python et les écrire directement dans le service Stockage Azure.Avertissement
Il n’est pas recommandé de se connecter à une base de données ou à d’autres stockages externes dans le composant Exécuter un script Python. Vous pouvez utiliser le composant Importer des données et le composant Exporter les données
- Le script doit contenir une fonction nommée
Envoyez le pipeline.
Si le composant est terminé, vérifiez si la sortie correspond à ce qui est attendu.
Si le composant a échoué, vous devez effectuer un dépannage. Sélectionnez le composant, puis ouvrez Sorties + journaux dans le volet droit. Ouvrez 70_driver_log. txt et recherchez in azureml_main pour trouver la ligne à l’origine de l’erreur. Par exemple, "File "/tmp/tmp01_ID/user_script.py", line 17, in azureml_main" indique que l’erreur s’est produite dans la ligne 17 de votre script Python.
Résultats
Les résultats des calculs effectués par le code Python incorporé doivent être fournis en tant que pandas.DataFrame, qui est automatiquement converti au format de jeu de données Azure Machine Learning. Vous pouvez ensuite utiliser ces résultats avec d’autres composants dans le pipeline.
Le composant retourne deux jeux de données :
Jeu de données de résultats 1, défini par la première trame de données pandas renvoyée dans un script Python.
Jeu de données de résultats 2, défini par le second dataframe pandas retourné dans un script Python.
Packages Python préinstallés
Les packages préinstallés sont les suivants :
- adal==1.2.2
- applicationinsights==0.11.9
- attrs==19.3.0
- azure-common==1.1.25
- azure-core==1.3.0
- azure-graphrbac==0.61.1
- azure-identity==1.3.0
- azure-mgmt-authorization==0.60.0
- azure-mgmt-containerregistry==2.8.0
- azure-mgmt-keyvault==2.2.0
- azure-mgmt-resource==8.0.1
- azure-mgmt-storage==8.0.0
- azure-storage-blob==1.5.0
- azure-storage-common==1.4.2
- azureml-core==1.1.5.5
- azureml-dataprep-native==14.1.0
- azureml-dataprep==1.3.5
- azureml-defaults==1.1.5.1
- azureml-designer-classic-modules==0.0.118
- azureml-designer-core==0.0.31
- azureml-designer-internal==0.0.18
- azureml-model-management-sdk==1.0.1b6.post1
- azureml-pipeline-core==1.1.5
- azureml-telemetry==1.1.5.3
- backports.tempfile==1.0
- backports.weakref==1.0.post1
- boto3==1.12.29
- botocore==1.15.29
- cachetools==4.0.0
- certifi==2019.11.28
- cffi==1.12.3
- chardet==3.0.4
- click==7.1.1
- cloudpickle==1.3.0
- configparser==3.7.4
- contextlib2==0.6.0.post1
- cryptography==2.8
- cycler==0.10.0
- dill==0.3.1.1
- distro==1.4.0
- docker==4.2.0
- docutils==0.15.2
- dotnetcore2==2.1.13
- flask==1.0.3
- fusepy==3.0.1
- gensim==3.8.1
- google-api-core==1.16.0
- google-auth==1.12.0
- google-cloud-core==1.3.0
- google-cloud-storage==1.26.0
- google-resumable-media==0.5.0
- googleapis-common-protos==1.51.0
- gunicorn==19.9.0
- idna==2.9
- imbalanced-learn==0.4.3
- isodate==0.6.0
- itsdangerous==1.1.0
- jeepney==0.4.3
- jinja2==2.11.1
- jmespath==0.9.5
- joblib==0.14.0
- json-logging-py==0.2
- jsonpickle==1.3
- jsonschema==3.0.1
- kiwisolver==1.1.0
- liac-arff==2.4.0
- lightgbm==2.2.3
- markupsafe==1.1.1
- matplotlib==3.1.3
- more-itertools==6.0.0
- msal-extensions==0.1.3
- msal==1.1.0
- msrest==0.6.11
- msrestazure==0.6.3
- ndg-httpsclient==0.5.1
- nimbusml==1.6.1
- numpy==1.18.2
- oauthlib==3.1.0
- pandas==0.25.3
- pathspec==0.7.0
- pip==20.0.2
- portalocker==1.6.0
- protobuf==3.11.3
- pyarrow==0.16.0
- pyasn1-modules==0.2.8
- pyasn1==0.4.8
- pycparser==2.20
- pycryptodomex==3.7.3
- pyjwt==1.7.1
- pyopenssl==19.1.0
- pyparsing==2.4.6
- pyrsistent==0.16.0
- python-dateutil==2.8.1
- pytz==2019.3
- requests-oauthlib==1.3.0
- requests==2.23.0
- rsa==4.0
- ruamel.yaml==0.15.89
- s3transfer==0.3.3
- scikit-learn==0.22.2
- scipy==1.4.1
- secretstorage==3.1.2
- setuptools==46.1.1.post20200323
- six==1.14.0
- smart-open==1.10.0
- urllib3==1.25.8
- websocket-client==0.57.0
- werkzeug==0.16.1
- wheel==0.34.2
Étapes suivantes
Consultez les composants disponibles pour Azure Machine Learning.