Balayage et sélection des modèles pour la prévision dans AutoML
Cet article explique comment le Machine Learning automatisé (AutoML) dans Azure Machine Learning recherche et sélectionne les modèles de prévision. Si vous souhaitez en savoir plus sur la méthodologie de prévision dans AutoML, consultez Vue d’ensemble des méthodes de prévision dans AutoML. Pour découvrir des exemples de formation aux modèles de prévision dans AutoML, voir Configurer AutoML pour former un modèle de prévision de série chronologique avec un kit de développement logiciel (SDK) et une interface de ligne de commande.
Balayage de modèle dans AutoML
La tâche centrale d’AutoML consiste à effectuer l’apprentissage et à évaluer plusieurs modèles, puis à choisir le meilleur par rapport à la métrique principale donnée. Dans ce cas, le mot « modèle » fait référence à la fois à la classe de modèles, comme ARIMA ou Random Forest, et aux paramètres spécifiques de l’hyperparamètre qui distinguent les modèles au sein d’une classe. ARIMA fait par exemple référence à une classe de modèles qui partagent un modèle mathématique et un ensemble d’hypothèses statistiques. La formation, ou l’ajustement, d’un modèle ARIMA nécessite une liste d’entiers positifs spécifiant la forme mathématique précise du modèle. Ces valeurs sont les hyper-paramètres. Les modèles ARIMA(1, 0, 1) et ARIMA(2, 1, 2) ont la même classe, mais différents hyper-paramètres. Ces définitions peuvent être adaptées séparément aux données de formation et évaluées entre elles. AutoML effectue des recherches, ou balayages, sur différentes classes de modèles et au sein des classes en variant les hyperparamètres.
Méthodes de balayage des hyperparamètres
Le tableau suivant présente les différentes méthodes de balayage des hyperparamètres d’AutoML pour les différentes classes de modèles :
| Groupe de classes de modèle | Type de modèle | Méthode de balayage des hyperparamètres |
|---|---|---|
| Naïf, saisonnier naïf, moyenne, moyenne saisonnière | Série chronologique | Pas de balayage au sein de la classe en raison de la simplicité du modèle |
| Lissage exponentiel, ARIMA(X) | Série chronologique | Recherche par grille pour le balayage au sein de la classe |
| Prophet | régression ; | Pas de balayage au sein de la classe |
| Gradient stochastique linéaire, LARS LASSO, Elastic Net, K plus proches voisins, arbre de décision, forêt d’arbres décisionnels, Extremely Randomized Trees, Gradient Boosted Trees, LightGBM, XGBoost | régression ; | Le service de recommandation de modèles d’AutoML explore dynamiquement les espaces d’hyperparamètres |
| ForecastTCN | régression ; | Liste statique des modèles suivis d’une recherche aléatoire sur la taille du réseau, le taux d’abandon et le taux d’apprentissage |
Pour obtenir une description des différents types de modèles, consultez la section Modèles de prévision dans AutoML de l’article de vue d’ensemble des méthodes de prévision.
Le nombre de balayages par AutoML dépend de la configuration du travail de prévision. Vous pouvez spécifier les critères d’arrêt comme une durée ou un nombre d’essais maximum, ou l’équivalent du nombre de modèles. La logique d’arrêt anticipé peut être utilisée dans les deux cas pour arrêter le balayage si la métrique principale ne s’améliore pas.
Sélection de modèle dans AutoML
AutoML suit un processus en trois étapes pour rechercher et sélectionner des modèles de prévision :
Étape 1 : Effectuez un balayage des modèles de série chronologique et sélectionnez le meilleur modèle de chaque classe à l’aide de méthodes d’estimation du maximum de vraisemblance.
Étape 2 :Effectuez un balayage des modèles de régression et classez-les par ordre de priorité, avec les meilleurs modèles de série chronologique de l’étape 1, en fonction des valeurs de métrique primaires à partir de jeux de validation.
Étape 3 : Créez un modèle d’ensemble à partir des modèles placés en haut du classement, calculez sa métrique de validation et classez-le par ordre de priorité avec les autres modèles.
Le modèle présentant la valeur de métrique en tête du classement à la fin de la phase 3 est désigné comme le meilleur modèle.
Important
Dans l’étape 3, AutoML calcule toujours les métriques sur données hors échantillon qui ne sont pas utilisées pour s’adapter aux modèles. Cette approche offre une protection contre le surajustement.
Configurations de validation
AutoML présente deux configurations de validation : la validation croisée et les données de validation explicites.
Dans le cas de la validation croisée, AutoML utilise la configuration d’entrée pour fractionner les données en replis d’apprentissage et de validation. L’ordre de temps doit être conservé dans ces fractionnements. AutoML utilise la Validation croisée à origine dynamique qui divise la série en données de formation et de validation à l’aide d’un point de temps d’origine. Les échantillons de validation croisée sont générés par glissement de l’origine temporelle. Chaque repli de validation contient l’horizon suivant des observations suivant immédiatement la position de l’origine du repli donné. Cette stratégie permet de préserver l’intégrité des données des séries chronologiques et de réduire le risque de fuite des informations.
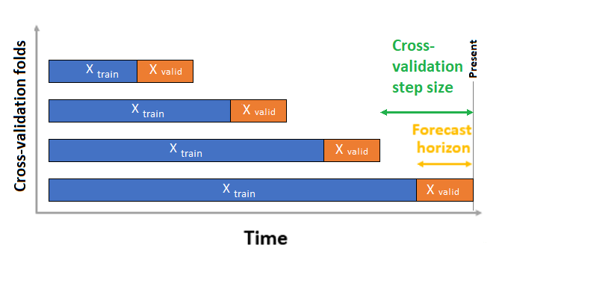
AutoML suit la procédure de validation croisée habituelle, effectuant l’apprentissage d’ modèle distinct sur chaque repli et calculant la moyenne des métriques de validation de tous les plis.
La validation croisée pour les travaux de prévision est configurée en définissant le nombre de replis de validation croisée et, éventuellement, le nombre de périodes entre deux replis de validation croisée consécutifs. Pour plus d’informations et pour avoir un exemple de configuration de la validation croisée pour la prévision, voir Paramètres de validation croisée personnalisés.
Vous pouvez également apporter vos propres données de validation. Pour plus d’informations, voir Configurer les données d’apprentissage, de validation, de validation croisée et de test dans AutoML (SDK v1).