Utiliser un conteneur personnalisé pour déployer un modèle sur un point de terminaison en ligne
S’APPLIQUE À : Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Découvrez comment utiliser un conteneur personnalisé pour déployer un modèle sur un point de terminaison en ligne dans Azure Machine Learning.
Les déploiements de conteneurs personnalisés peuvent utiliser des serveurs web autres que le serveur Flask Python par défaut utilisé par Azure Machine Learning. Les utilisateurs de ces déploiements peuvent toujours tirer parti de la surveillance, de la mise à l’échelle, des alertes et de l’authentification intégrées d’Azure Machine Learning.
Le tableau suivant répertorie différents exemples de déploiement qui utilisent des conteneurs personnalisés tels que TensorFlow Serving, TorchServe, Triton Inference Server, le package Plumber R et l’image Minimale d’inférence Azure Machine Learning.
| Exemple | Script (CLI) | Description |
|---|---|---|
| minimal/multimodel | deploy-custom-container-minimal-multimodel | Déployez plusieurs modèles sur un déploiement unique en étendant l’image Minimale d’inférence Azure Machine Learning. |
| minimal/single-model | deploy-custom-container-minimal-single-model | Déployez un modèle unique en étendant l’image Minimale d’inférence Azure Machine Learning. |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | Déployez deux modèles MLFlow avec des exigences Python différentes sur deux déploiements distincts derrière un point de terminaison unique à l’aide de l’image minimale d’inférence Azure Machine Learning. |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | Déployer trois modèles de régression sur un point de terminaison à l’aide du package Plumber R |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | Déployez un modèle Half Plus Two à l’aide d’un conteneur personnalisé TensorFlow Serving avec le processus d’inscription de modèle standard. |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | Déployez un modèle Half Plus Two à l’aide d’un conteneur personnalisé TensorFlow Serving avec le modèle intégré à l’image. |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | Déployez un modèle unique à l’aide d’un conteneur personnalisé TorchServe. |
| triton/single-model | deploy-custom-container-triton-single-model | Déployer un modèle Triton à l’aide d’un conteneur personnalisé |
Cet article se concentre sur la mise en service d’un modèle TensorFlow (TF) avec TensorFlow Serving.
Avertissement
Microsoft risque de ne pas pouvoir vous aider à résoudre les problèmes dus à une image personnalisée. Si vous rencontrez des problèmes, vous devrez sans doute utiliser l’image par défaut ou l’une des images fournies par Microsoft pour voir si le problème est spécifique à votre image.
Prérequis
Avant de suivre les étapes décrites dans cet article, vérifiez que vous disposez des composants requis suivants :
Un espace de travail Azure Machine Learning. Si vous n’en avez pas, procédez comme suit dans le Guide de démarrage rapide : Créer des ressources d’espace de travail pour en créer un.
Azure CLI et l’extension
mlou le Kit de développement logiciel (SDK) Python Azure Machine Learning v2 :Pour installer Azure CLI et l’extension, consultez Installer, configurer et utiliser l’interface CLI (v2).
Important
Les exemples CLI de cet article supposent que vous utilisez l’interpréteur de commandes Bash (ou compatible). Par exemple, à partir d’un système Linux ou d’un sous-système Windows pour Linux.
Pour installer le kit SDK Python v2, utilisez la commande suivante :
pip install azure-ai-ml azure-identityPour mettre à jour une installation existante du Kit de développement logiciel (SDK) vers la version la plus récente, utilisez la commande suivante :
pip install --upgrade azure-ai-ml azure-identityPour plus d’informations, consultez Installer le kit SDK Python v2 pour Azure Machine Learning.
Vous ou le principal de service que vous utilisez devez avoir l’accès Contributeur au groupe de ressources Azure qui contient votre espace de travail. Vous disposez d’un tel groupe de ressources si vous avez configuré votre espace de travail à l’aide de l’article de démarrage rapide.
Pour déployer localement, vous devez exécuté le moteur Docker localement. Cette étape est fortement recommandée. Cela vous aide à déboguer des problèmes.
Téléchargement du code source
Pour suivre ce tutoriel, clonez le code source depuis GitHub.
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Initialiser des variables d’environnement
Définissez des variables d’environnement :
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
Télécharger un modèle TensorFlow
Téléchargez et décompressez un modèle qui divise une entrée en deux et ajoute « 2 » au résultat :
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
Exécuter une image TF Serving localement pour tester son fonctionnement
Utilisez Docker pour exécuter votre image localement à des fins de test :
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
Vérifier que vous pouvez envoyer des requêtes liveness et scoring à l’image
Tout d’abord, vérifiez que le conteneur est vivant, c’est-à-dire que le processus à l’intérieur du conteneur est toujours en cours d’exécution. Vous devez obtenir une réponse 200 (OK).
curl -v http://localhost:8501/v1/models/$MODEL_NAME
Ensuite, vérifiez que vous pouvez obtenir des prédictions sur les données sans étiquette :
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
Arrêter l’image
Maintenant que vous avez effectué un test local, arrêtez l’image :
docker stop tfserving-test
Déployer votre point de terminaison en ligne dans Azure
Ensuite, déployez votre point de terminaison en ligne dans Azure.
Créer un fichier YAML pour votre point de terminaison et votre déploiement
Vous pouvez configurer votre déploiement cloud à l’aide de YAML. Jetez un coup d’œil à l’échantillon YAML pour cet exemple :
tfserving-endpoint.yml
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
tfserving-deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: {{MODEL_VERSION}}
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/{{MODEL_VERSION}}
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
Voici quelques concepts importants à noter dans ce paramètre YAML/Python :
Image de base
L’image de base est spécifiée en tant que paramètre dans l’environnement, et docker.io/tensorflow/serving:latest est utilisé dans cet exemple. Quand vous inspectez le conteneur, vous pouvez constater que ce serveur utilise ENTRYPOINT pour démarrer un script de point d’entrée, qui accepte les variables d’environnement telles que MODEL_BASE_PATH et MODEL_NAME, et expose les ports tels que 8501. Ces détails sont tous des informations spécifiques au serveur choisi. Vous pouvez utiliser cette compréhension du serveur pour déterminer comment définir le déploiement. Par exemple, si vous définissez des variables d’environnement pour MODEL_BASE_PATH et MODEL_NAME dans la définition de déploiement, le serveur (dans le cas présent, TF Serving) accepte les valeurs permettant de lancer le serveur. De même, si vous affectez la valeur 8501 au port des routes dans la définition de déploiement, la requête de l’utilisateur correspondant à ces routes est correctement routée vers le serveur TF Serving.
Notez que cet exemple spécifique est basé sur le cas de TF Serving. Toutefois, vous pouvez utiliser tous les conteneurs qui restent actifs et répondent aux requêtes relatives aux routes liveness (détection d’activité), readiness (vérification de disponibilité) et scoring. Vous pouvez faire référence à d’autres exemples, et voir comment le Dockerfile est formé (par exemple en utilisant CMD à la place de ENTRYPOINT) pour créer les conteneurs.
Configuration d’inférence
La configuration d’inférence est un paramètre de l’environnement. Elle spécifie le port et le chemin d’accès de 3 types de routes : la route liveness, la route readiness et la route scoring. La configuration d’inférence est nécessaire si vous souhaitez exécuter votre propre conteneur avec un point de terminaison en ligne géré.
Route readiness et route liveness
Le serveur d’API que vous choisissez peut fournir un moyen de vérifier l’état du serveur. Il existe deux types de routes que vous pouvez spécifier : liveness et readiness. Un itinéraire liveness est utilisé pour vérifier si le serveur est en cours d’exécution. Un itinéraire readiness est utilisé pour vérifier si le serveur est prêt à effectuer le travail. Dans le contexte de l’inférence en Machine Learning, un serveur peut répondre 200 OK à une requête liveness avant de charger un modèle, et peut répondre 200 OK à une requête readiness uniquement une fois le modèle chargé en mémoire.
Pour plus d’informations sur les probes liveness et readiness en général, consultez la documentation Kubernetes.
Les routes liveness et readiness sont déterminées par le serveur d’API de votre choix, tel que vous l’avez identifié quand vous avez testé le conteneur localement à l’étape précédente. Notez que l’exemple de déploiement de cet article utilise le même chemin d’accès pour les routes liveness et readiness, car TF Serving définit uniquement une route liveness. Consultez d’autres exemples pour connaître les différents modèles permettant de définir les routes.
Routes scoring
Le serveur d’API que vous choisissez permet de recevoir la charge utile sur laquelle travailler. Dans le contexte de l’inférence en Machine Learning, un serveur reçoit les données d’entrée via une route spécifique. Identifiez cette route pour votre serveur d’API quand vous testez le conteneur localement à l’étape précédente, puis spécifiez-la quand vous définissez le déploiement à créer.
Notez que la création réussie du déploiement entraîne également la mise à jour du paramètre scoring_uri du point de terminaison, ce que vous pouvez vérifier avec az ml online-endpoint show -n <name> --query scoring_uri.
Localisation du modèle monté
Lorsque vous déployez un modèle en tant que point de terminaison en ligne, Azure Machine Learning monte votre modèle sur votre point de terminaison. Le montage du modèle vous permet de déployer de nouvelles versions du modèle sans avoir à créer de nouvelle image Docker. Par défaut, un modèle inscrit avec le nom foo et la version 1 se trouve sous le chemin suivant à l’intérieur de votre conteneur déployé : /var/azureml-app/azureml-models/foo/1
Par exemple, si vous avez une structure de répertoires /azureml-examples/cli/endpoints/online/custom-container sur votre ordinateur local, où le modèle est nommé half_plus_two :
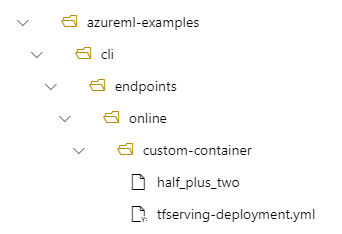
Et tfserving-deployment.yml contient :
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
Alors, votre modèle se trouvera sous /var/azureml-app/azureml-models/tfserving-deployment/1 dans votre déploiement :
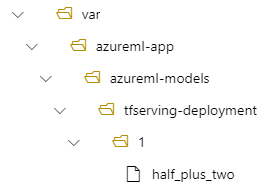
Vous pouvez éventuellement configurer votre model_mount_path. Cela vous permet de modifier le chemin d’accès où le modèle est monté.
Important
Le model_mount_path doit être un chemin d’accès absolu valide dans Linux (le système d’exploitation de l’image conteneur).
Par exemple, vous pouvez avoir le paramètre model_mount_path dans votre tfserving-deployment.yml :
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
.....
Alors, votre modèle se trouve à l’emplacement /var/tfserving-model-mount/tfserving-deployment/1 dans votre déploiement. Notez qu’il ne figure plus dans le chemin d’accès azureml-app/azureml-models, mais dans le chemin de montage que vous avez spécifié :
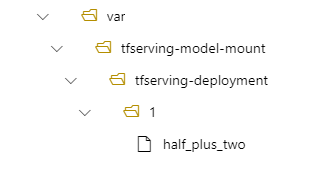
Créer votre point de terminaison et votre déploiement
Maintenant que vous comprenez comment le YAML a été construit, créez votre point de terminaison.
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving-endpoint.yml
La création d’un déploiement peut prendre quelques minutes.
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving-deployment.yml --all-traffic
Appeler le point de terminaison
Une fois votre déploiement terminé, vérifiez si vous pouvez effectuer une requête scoring sur le point de terminaison déployé.
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
Supprimer le point de terminaison
Maintenant que vous avez réussi à établir un score de votre point de terminaison, vous pouvez le supprimer :
az ml online-endpoint delete --name tfserving-endpoint