Transformer des données dans le concepteur Azure Machine Learning
Dans cet article, vous apprenez à transformer et enregistrer des jeux de données dans le concepteur Azure Machine Learning pour préparer vos propres données pour l’apprentissage automatique.
Vous allez utiliser l’exemple de jeu de données Adult Census Income Binary Classification pour préparer deux jeux de données : l’un contenant des informations de recensement d’adultes natifs des USA, et l’autre contenant des informations de recensement d’adultes non natifs des USA.
Dans cet article, vous allez apprendre à :
- Transformer un jeu de données pour le préparer en vue d’un apprentissage.
- Exporter les jeux de données obtenus vers un magasin de données.
- Affichez les résultats.
Nous vous recommandons de lire cet article avant l’article sur le recyclage de modèles de concepteur. Cet article explique comment utiliser les jeux de données transformés pour effectuer l’apprentissage de plusieurs modèles avec des paramètres de pipeline.
Important
Si vous n’observez pas certains éléments graphiques mentionnés dans ce document, comme des boutons dans Studio ou le concepteur, vous ne disposez peut-être pas du bon niveau d’autorisations pour l’espace de travail. Contactez votre administrateur d’abonnement Azure pour vérifier que le niveau d’accès est correct. Pour plus d’informations, rendez-vous sur Gestion des utilisateurs et des rôles.
Transformer un jeu de données
Cette section explique comment importer l’exemple de jeu de données et fractionner les données en deux jeux de données, US et non-US. Rendez-vous sur Comment importer des données pour plus d’informations sur l’importation de vos propres données dans le concepteur.
Importer des données
Procédez comme suit pour importer l’exemple de jeu de données :
Connectez-vous à Azure Machine Learning studio, puis sélectionnez l’espace de travail que vous souhaitez utiliser
Accédez au concepteur. Sélectionnez Créer un pipeline à l’aide de composants pré-intégrés classiques pour créer un nouveau pipeline
À gauche du canevas du pipeline, dans l’onglet Composant (Component), développez le nœud Exemples de données
Glissez-déposez le jeu de données Adult Census Income Binary classification sur le canevas
Sélectionnez avec un clic droit le composant du jeu de données Adult Census Income et sélectionnez Aperçu des données
Utilisez la fenêtre d’aperçu des données pour explorer le jeu de données. Notez en particulier les valeurs de la colonne « native-country »
Fractionner les données
Dans cette section, vous allez utiliser le composant Fractionner les données (Split Data) pour identifier et fractionner les lignes contenant « United-States » dans la colonne « native-country »
Dans l’onglet des composants à gauche du canevas, développez la section Transformation des données (Data Transformation) et recherchez le composant Fractionner les données
Faites glisser le composant Fractionner les données sur le canevas et déposez ce composant sous le composant du jeu de données
Connectez le composant du jeu de données au composant Fractionner les données
Sélectionnez le composant Fractionner les données pour ouvrir le volet Fractionner les données
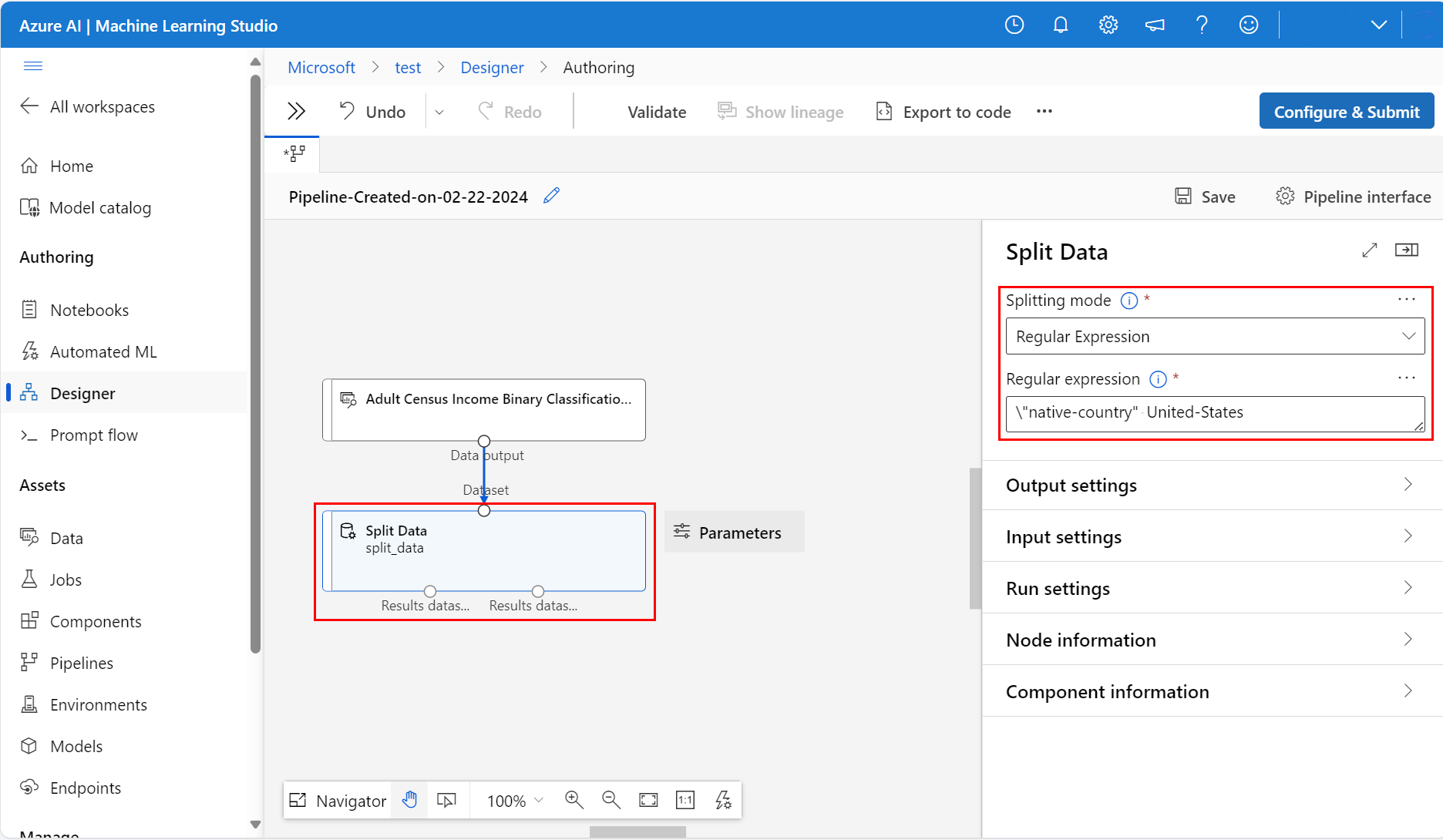
À droite du canevas, dans l’icône Paramètres (Parameters), définissez Mode de fractionnement (Splitting mode) sur Expression régulière (Regular Expression)
Entrez l’Expression régulière :
\"native-country" United-StatesLe mode Regular expression (Expression régulière) teste une seule colonne pour une valeur. Consultez la page de référence des composants d’algorithme associée pour plus d’informations sur le composant Fractionner les données
Votre pipeline doit ressembler à cette capture d’écran :
Enregistrer les jeux de données
Maintenant que votre pipeline est configuré pour fractionner les données, vous devez spécifier où conserver les jeux de données. Pour cet exemple, utilisez le composant Export Data (Exporter des données) pour enregistrer votre jeu de données dans un magasin de données. Pour plus d’informations sur les magasins de données, rendez-vous sur Se connecter aux services de stockage Azure.
À la gauche du canevas, dans la palette de composants , développez la section Entrée et sortie de données (Data Input and Output), puis recherchez le composant Exporter les données (Export Data)
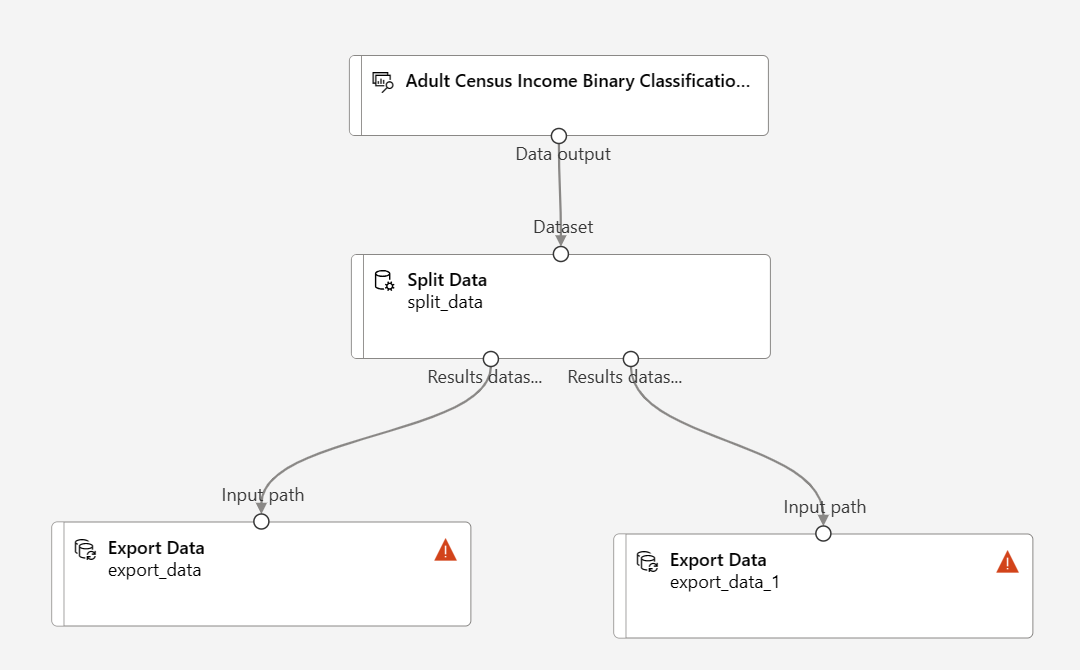
Faites un glisser-déposer deux composants Exporter les données sous le composant Fractionner les données
Connectez chaque port de sortie du composant Fractionner les données à un composant Exporter les données différent
Votre pipeline doit ressembler à ceci :
Sélectionnez le composant Exporter les données connecté au port le plus à gauchedu composant Fractionner les données pour ouvrir le volet de configuration Exporter les données
Pour le composant Fractionner les données, l’ordre des ports de sortie est important. Le premier port de sortie contient les lignes où l’expression régulière a la valeur true. Dans ce cas, le premier port contient des lignes pour les revenus aux USA et le deuxième port contient des lignes pour les revenus hors USA
Dans le volet d’informations du composant à droite du canevas, définissez les options suivantes :
Datastore type (Type de magasin de données) : Stockage Blob Azure
Magasin de données : sélectionnez un magasin de données existant ou sélectionnez « Nouveau magasin de données » pour en créer un
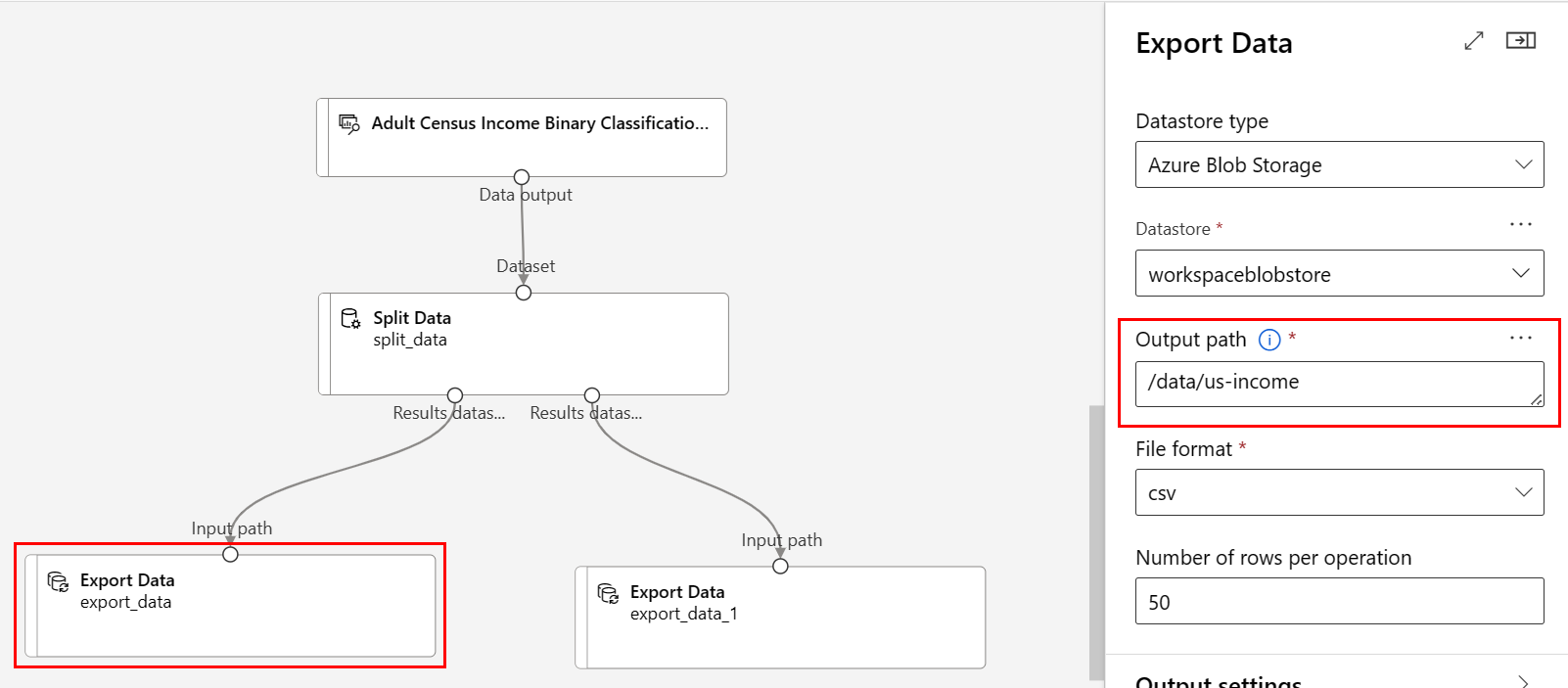
Path (Chemin) :
/data/us-incomeFile format (Format de fichier ) : csv
Notes
Cet article part du principe que vous avez accès à un magasin de données inscrit dans l’espace de travail Azure Machine Learning actuel. Rendez-vous sur Se connecter aux services de stockage Azure pour obtenir des instructions sur la configuration des magasins de données
Si vous n’avez pas de magasin de données, vous pouvez en créer un. À titre d’exemple, cet article enregistre les jeux de données dans le compte de stockage d’objets blob associé à l’espace de travail par défaut. Les jeux de données sont enregistrés dans le conteneur
azuremldans un nouveau dossier nommédataSélectionnez le composant Exporter les données connecté au port le plus à droitedu composant Fractionner les données pour ouvrir le volet de configuration Exporter les données
Dans le volet d’informations du composant à droite du canevas, définissez les options suivantes :
Datastore type (Type de magasin de données) : Stockage Blob Azure
Magasin de données : sélectionnez le magasin de données précédent
Path (Chemin) :
/data/non-us-incomeFile format (Format de fichier ) : csv
Vérifiez que le composant Exporter les données connecté au port de gauche de Fractionner les données a le Chemin d’accès
/data/us-incomeVérifiez que le composant Exporter les données connecté au port de droite a le Chemin d’accès
/data/non-us-incomeVotre pipeline et vos paramètres doivent ressembler à ceci :
Envoi du travail
Maintenant que votre pipeline est configuré pour fractionner et exporter les données, envoyez une tâche de pipeline.
Sélectionnez Configurer et Envoyer (Configure & Submit) en haut du canevas
Sélectionnez l’option Créer nouveau (Create new) dans le volet De base du Configurer un travail de pipeline (Set up pipeline job) pour créer une expérience
Les expériences regroupent les tâches de pipeline associées de manière logique. Si vous exécutez ce pipeline à l’avenir, vous devrez utiliser la même expérience à des fins de journalisation et de suivi
Fournissez un nom d’expérience descriptif tel que « fractionnement-données-recensement »
Sélectionnez Vérifier + Envoyer (Review + Submit), puis sélectionnez Envoyer (Submit)
Afficher les résultats
Une fois l’exécution du pipeline terminée, vous pouvez accéder à votre stockage Blob du Portail Azure pour afficher vos résultats. Vous pouvez également afficher les résultats intermédiaires du composant Fractionner les données pour vérifier que vos données ont fractionné correctement.
Sélectionnez le composant Fractionner les données
Dans le volet d’informations des composants à droite du canevas, sélectionnez Sorties + journaux (Outputs + logs)
Sélectionnez la liste déroulante Afficher les sorties de données (Show data outputs)
Sélectionnez l’icône de visualisation
 en regard de Results dataset1
en regard de Results dataset1Vérifiez que la colonne « native-Country » contient uniquement la valeur « United States »
Sélectionnez l’icône de visualisation
en regard de Results dataset2Vérifiez que la colonne « native-Country » ne contient pas la valeur « United States »
Nettoyer les ressources
Pour continuer avec la deuxième partie de cette procédure ré-entraîner des modèles avec le concepteur Azure Machine Learning, ignorez cette section.
Important
Vous pouvez utiliser les ressources que vous avez créées comme prérequis pour d’autres didacticiels et articles de guides pratiques Azure Machine Learning.
Tout supprimer
Si vous n’avez pas l’intention d’utiliser les éléments que vous avez créés, supprimez l’intégralité du groupe de ressources pour éviter des frais.
Dans le portail Azure, sélectionnez Groupes de ressources sur le côté gauche de la fenêtre.
Dans la liste, sélectionnez le groupe de ressources créé.
Sélectionnez Supprimer le groupe de ressources.
La suppression du groupe de ressources supprime également toutes les ressources créées dans le concepteur.
Supprimer des ressources individuelles
Dans le concepteur où vous avez créé votre expérience, supprimez des ressources individuelles en les sélectionnant, puis en sélectionnant le bouton Supprimer.
La cible de calcul que vous avez créée ici est automatiquement mise à l’échelle sur zéro nœud quand elle n’est pas utilisée. Cette action est effectuée pour réduire les frais. Si vous souhaitez supprimer la cible de calcul, procédez comme suit :
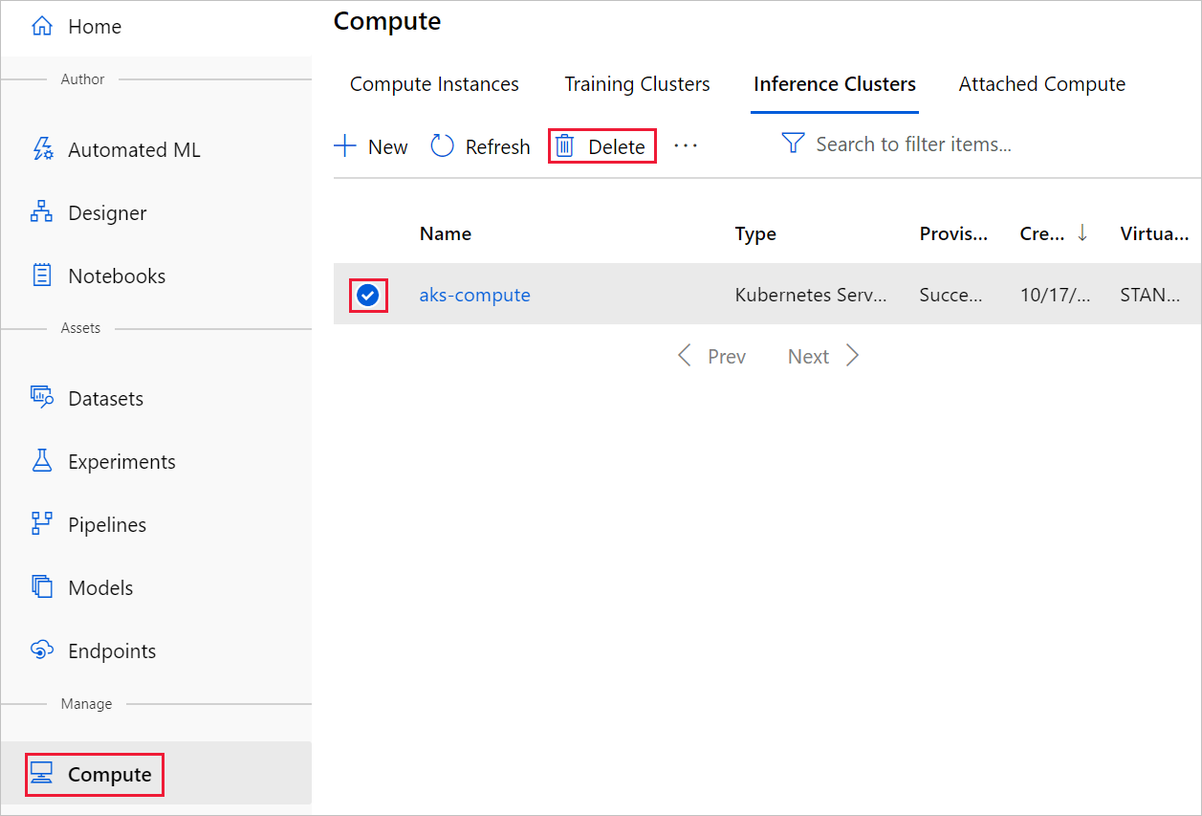
Vous pouvez désinscrire des jeux de données de votre espace de travail en sélectionnant chaque jeu de données, puis Annuler l’enregistrement.
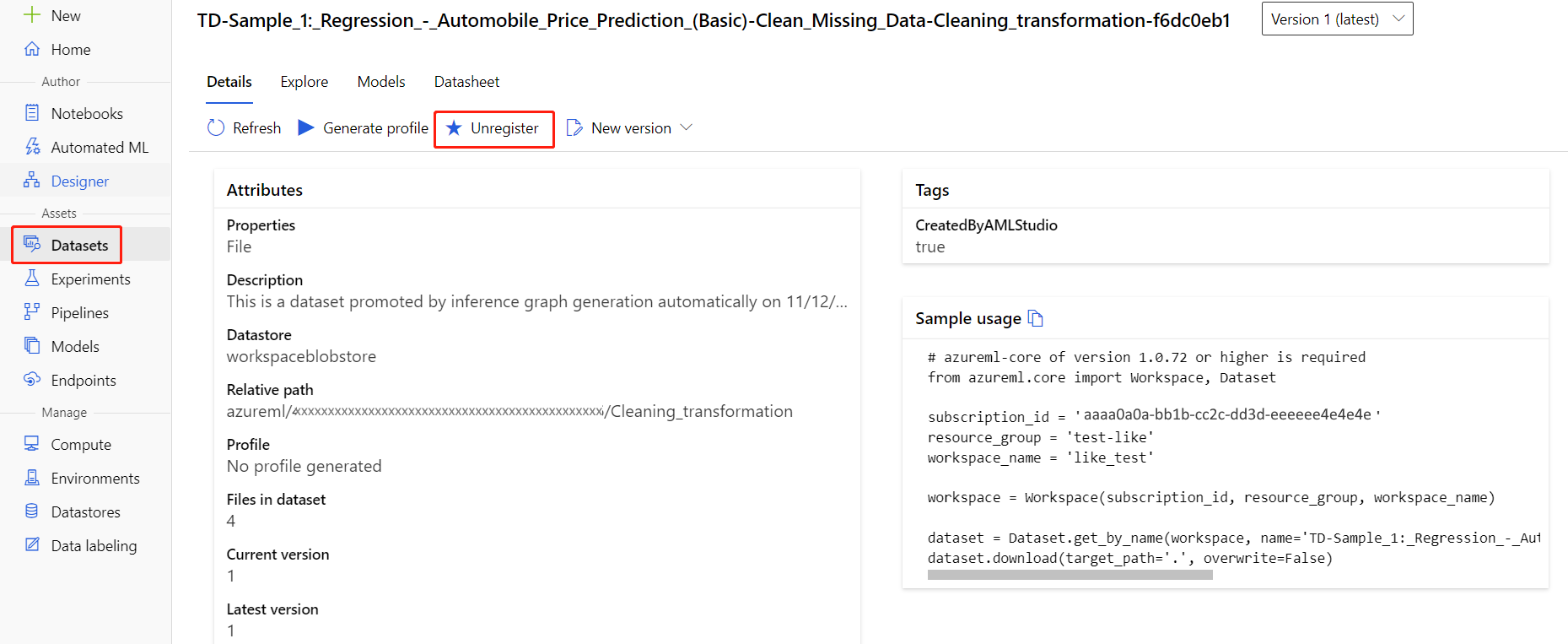
Pour supprimer un jeu de données, accédez au compte de stockage à l’aide du portail Azure ou de l’Explorateur Stockage Azure et supprimez manuellement ces ressources.
Étapes suivantes
Cet article vous a montré comment transformer un jeu de données et l’enregistrer dans un magasin de données créé.
Passez à la partie suivante de cette procédure, Ré-entraîner des modèles avec le concepteur Azure Machine Learning, pour utiliser vos jeux de données transformés et paramètres de pipeline afin d’effectuer l’apprentissage des modèles de Machine Learning.